mirror of
https://github.com/FEX-Emu/xxHash.git
synced 2024-11-23 14:39:40 +00:00
Let the Great Typo Hunt commence!
Work in progress. - Fix many spelling/grammar issues, primarily in comments - Remove most spaces before punctuation - Update XXH3 comment - Wrap most comments to 80 columns - Unify most comments to use the same style - Use hexadecimal in the xxhash spec - Update help messages to better match POSIX/GNU conventions - Use HTML escapes in README.md to avoid UTF-8 - Mark outdated benchmark/scores
This commit is contained in:
parent
22abeae0eb
commit
9eb91a3b53
101
README.md
101
README.md
@ -1,6 +1,7 @@
|
||||
xxHash - Extremely fast hash algorithm
|
||||
======================================
|
||||
|
||||
<!-- TODO: Update. -->
|
||||
xxHash is an Extremely fast Hash algorithm, running at RAM speed limits.
|
||||
It successfully completes the [SMHasher](http://code.google.com/p/smhasher/wiki/SMHasher) test suite
|
||||
which evaluates collision, dispersion and randomness qualities of hash functions.
|
||||
@ -20,21 +21,21 @@ The benchmark uses SMHasher speed test, compiled with Visual 2010 on a Windows S
|
||||
The reference system uses a Core 2 Duo @3GHz
|
||||
|
||||
|
||||
| Name | Speed | Quality | Author |
|
||||
|---------------|-------------|:-------:|-------------------|
|
||||
| [xxHash] | 5.4 GB/s | 10 | Y.C. |
|
||||
| MurmurHash 3a | 2.7 GB/s | 10 | Austin Appleby |
|
||||
| SBox | 1.4 GB/s | 9 | Bret Mulvey |
|
||||
| Lookup3 | 1.2 GB/s | 9 | Bob Jenkins |
|
||||
| CityHash64 | 1.05 GB/s | 10 | Pike & Alakuijala |
|
||||
| FNV | 0.55 GB/s | 5 | Fowler, Noll, Vo |
|
||||
| CRC32 | 0.43 GB/s † | 9 | |
|
||||
| MD5-32 | 0.33 GB/s | 10 | Ronald L.Rivest |
|
||||
| SHA1-32 | 0.28 GB/s | 10 | |
|
||||
| Name | Speed | Quality | Author |
|
||||
|---------------|--------------------|:-------:|-------------------|
|
||||
| [xxHash] | 5.4 GB/s | 10 | Y.C. |
|
||||
| MurmurHash 3a | 2.7 GB/s | 10 | Austin Appleby |
|
||||
| SBox | 1.4 GB/s | 9 | Bret Mulvey |
|
||||
| Lookup3 | 1.2 GB/s | 9 | Bob Jenkins |
|
||||
| CityHash64 | 1.05 GB/s | 10 | Pike & Alakuijala |
|
||||
| FNV | 0.55 GB/s | 5 | Fowler, Noll, Vo |
|
||||
| CRC32 | 0.43 GB/s † | 9 | |
|
||||
| MD5-32 | 0.33 GB/s | 10 | Ronald L.Rivest |
|
||||
| SHA1-32 | 0.28 GB/s | 10 | |
|
||||
|
||||
[xxHash]: http://www.xxhash.com
|
||||
|
||||
Note †: SMHasher's CRC32 implementation is known to be slow. Faster implementations exist.
|
||||
Note †: SMHasher's CRC32 implementation is known to be slow. Faster implementations exist.
|
||||
|
||||
Q.Score is a measure of quality of the hash function.
|
||||
It depends on successfully passing SMHasher test set.
|
||||
@ -48,13 +49,13 @@ Note however that 32-bit applications will still run faster using the 32-bit ver
|
||||
SMHasher speed test, compiled using GCC 4.8.2, on Linux Mint 64-bit.
|
||||
The reference system uses a Core i5-3340M @2.7GHz
|
||||
|
||||
| Version | Speed on 64-bit | Speed on 32-bit |
|
||||
| Version | Speed on 64-bit | Speed on 32-bit |
|
||||
|------------|------------------|------------------|
|
||||
| XXH64 | 13.8 GB/s | 1.9 GB/s |
|
||||
| XXH32 | 6.8 GB/s | 6.0 GB/s |
|
||||
|
||||
This project also includes a command line utility, named `xxhsum`, offering similar features as `md5sum`,
|
||||
thanks to [Takayuki Matsuoka](https://github.com/t-mat) contributions.
|
||||
This project also includes a command line utility, named `xxhsum`, offering similar features to `md5sum`,
|
||||
thanks to [Takayuki Matsuoka](https://github.com/t-mat)'s contributions.
|
||||
|
||||
|
||||
### License
|
||||
@ -65,61 +66,59 @@ The utility `xxhsum` is GPL licensed.
|
||||
|
||||
### New hash algorithms
|
||||
|
||||
Starting with `v0.7.0`, the library includes a new algorithm, named `XXH3`,
|
||||
able to generate 64 and 128-bits hashes.
|
||||
Starting with `v0.7.0`, the library includes a new algorithm named `XXH3`,
|
||||
which is able to generate 64 and 128-bit hashes.
|
||||
|
||||
The new algorithm is much faster than its predecessors,
|
||||
for both long and small inputs,
|
||||
which can be observed in the following graphs :
|
||||
The new algorithm is much faster than its predecessors for both long and small inputs,
|
||||
which can be observed in the following graphs:
|
||||
|
||||
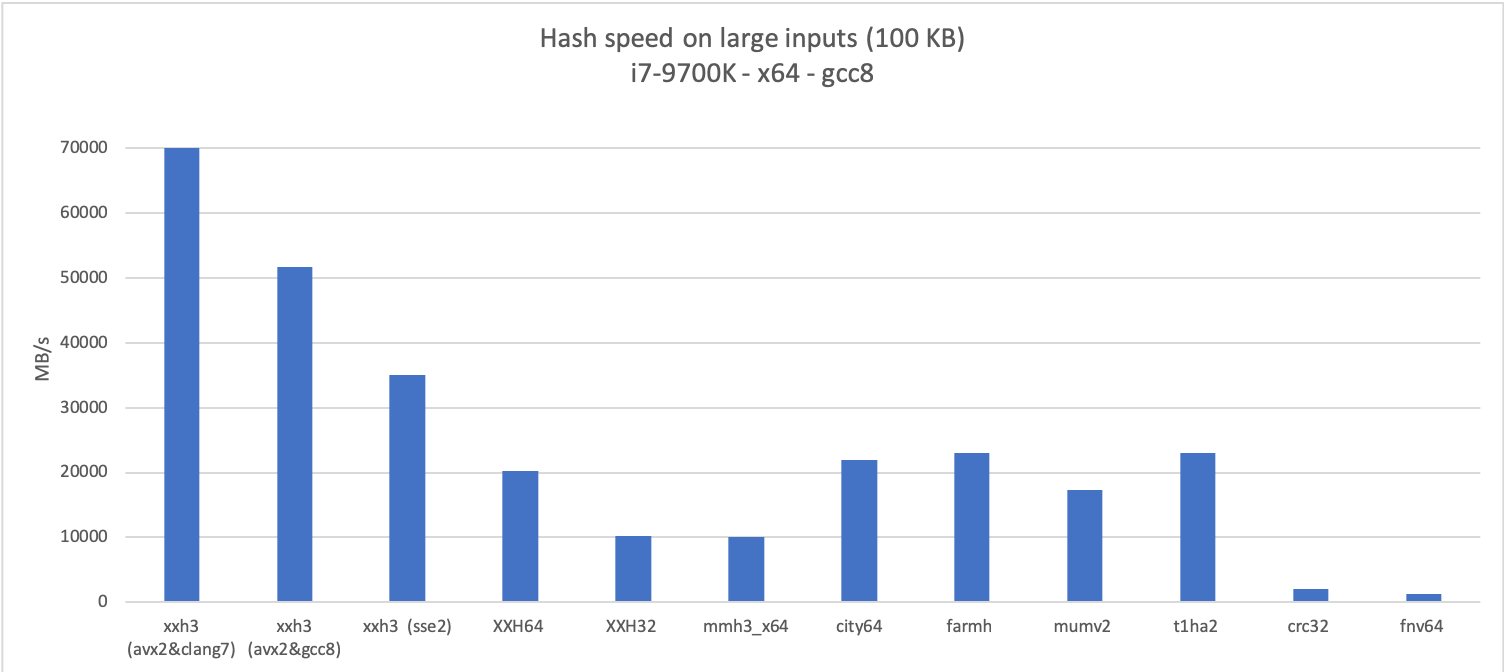
|
||||
|
||||

|
||||
|
||||
To access these new prototypes, one needs to unlock their declaration, using build the macro `XXH_STATIC_LINKING_ONLY`.
|
||||
To access these new prototypes, one needs to unlock their declaration, using the build macro `XXH_STATIC_LINKING_ONLY`.
|
||||
|
||||
The algorithm is currently in development, meaning its return values might still change in future versions.
|
||||
However, the implementation is stable, and can be used in production,
|
||||
typically for ephemeral data (produced and consumed in same session).
|
||||
`XXH3` return values will be finalized on reaching `v0.8.0`.
|
||||
However, the API is stable, and can be used in production, typically for ephemeral
|
||||
data (produced and consumed in same session).
|
||||
|
||||
`XXH3`'s return values will be finalized upon reaching `v0.8.0`.
|
||||
|
||||
|
||||
### Build modifiers
|
||||
|
||||
The following macros can be set at compilation time,
|
||||
they modify libxxhash behavior. They are all disabled by default.
|
||||
The following macros can be set at compilation time to modify libxxhash's behavior. They are all disabled by default.
|
||||
|
||||
- `XXH_INLINE_ALL` : Make all functions `inline`, with bodies directly included within `xxhash.h`.
|
||||
- `XXH_INLINE_ALL` : Make all functions `inline`, with implementations being directly included within `xxhash.h`.
|
||||
Inlining functions is beneficial for speed on small keys.
|
||||
It's _extremely effective_ when key length is expressed as _a compile time constant_,
|
||||
with performance improvements observed in the +200% range .
|
||||
with performance improvements being observed in the +200% range .
|
||||
See [this article](https://fastcompression.blogspot.com/2018/03/xxhash-for-small-keys-impressive-power.html) for details.
|
||||
Note: there is no need to compile an `xxhash.o` object file in this case.
|
||||
- `XXH_NO_INLINE_HINTS` : By default, xxHash uses tricks like `__attribute__((always_inline))` and `__forceinline` to try and improve performance at the cost of code size. Defining this to 1 will mark all internal functions as `static`, allowing the compiler to decide whether to inline a function or not. This is very useful when optimizing for the smallest binary size, and it is automatically defined when compiling with `-O0`, `-Os`, `-Oz`, or `-fno-inline` on GCC and Clang. This may also increase performance depending on the compiler and the architecture.
|
||||
- `XXH_REROLL` : reduce size of generated code. Impact on performance vary, depending on platform and algorithm.
|
||||
- `XXH_NO_INLINE_HINTS`: By default, xxHash uses tricks like `__attribute__((always_inline))` and `__forceinline` to try and improve performance at the cost of code size. Defining this to 1 will mark all internal functions as `static`, allowing the compiler to decide whether to inline a function or not. This is very useful when optimizing for the smallest binary size, and it is automatically defined when compiling with `-O0`, `-Os`, `-Oz`, or `-fno-inline` on GCC and Clang. This may also increase performance depending on the compiler and the architecture.
|
||||
- `XXH_REROLL`: Reduces the size of the generated code by not unrolling some loops. Impact on performance may vary, depending on the platform and the algorithm.
|
||||
- `XXH_ACCEPT_NULL_INPUT_POINTER` : if set to `1`, when input is a `NULL` pointer,
|
||||
xxhash result is the same as a zero-length input
|
||||
xxHash'd result is the same as a zero-length input
|
||||
(instead of a dereference segfault).
|
||||
Adds one branch at the beginning of the hash.
|
||||
- `XXH_FORCE_MEMORY_ACCESS` : default method `0` uses a portable `memcpy()` notation.
|
||||
- `XXH_FORCE_MEMORY_ACCESS` : The default method `0` uses a portable `memcpy()` notation.
|
||||
Method `1` uses a gcc-specific `packed` attribute, which can provide better performance for some targets.
|
||||
Method `2` forces unaligned reads, which is not standard compliant, but might sometimes be the only way to extract better read performance.
|
||||
Method `2` forces unaligned reads, which is not standards compliant, but might sometimes be the only way to extract better read performance.
|
||||
Method `3` uses a byteshift operation, which is best for old compilers which don't inline `memcpy()` or big-endian systems without a byteswap instruction
|
||||
- `XXH_CPU_LITTLE_ENDIAN` : by default, endianess is determined at compile time.
|
||||
It's possible to skip auto-detection and force format to little-endian, by setting this macro to 1.
|
||||
- `XXH_CPU_LITTLE_ENDIAN`: By default, endianess is determined at compile time.
|
||||
It's possible to skip auto-detection and force format to little-endian, by setting this macro to 1.
|
||||
Setting it to 0 forces big-endian.
|
||||
- `XXH_PRIVATE_API` : same impact as `XXH_INLINE_ALL`.
|
||||
Name underlines that XXH_* symbols will not be published.
|
||||
- `XXH_NAMESPACE` : prefix all symbols with the value of `XXH_NAMESPACE`.
|
||||
- `XXH_PRIVATE_API`: same impact as `XXH_INLINE_ALL`.
|
||||
Name underlines that XXH_* symbols will not be exported.
|
||||
- `XXH_NAMESPACE`: Prefixes all symbols with the value of `XXH_NAMESPACE`.
|
||||
Useful to evade symbol naming collisions,
|
||||
in case of multiple inclusions of xxHash source code.
|
||||
Client applications can still use regular function name,
|
||||
symbols are automatically translated through `xxhash.h`.
|
||||
- `XXH_STATIC_LINKING_ONLY` : gives access to state declaration for static allocation.
|
||||
Incompatible with dynamic linking, due to risks of ABI changes.
|
||||
- `XXH_NO_LONG_LONG` : removes support for XXH64,
|
||||
for targets without 64-bit support.
|
||||
- `XXH_IMPORT` : MSVC specific : should only be defined for dynamic linking, it prevents linkage errors.
|
||||
in case of multiple inclusions of xxHash's source code.
|
||||
Client applications can still use the regular function name,
|
||||
as symbols are automatically translated through `xxhash.h`.
|
||||
- `XXH_STATIC_LINKING_ONLY`: gives access to the state declaration for static allocation.
|
||||
Incompatible with dynamic linking, due to risks of ABI changes.
|
||||
- `XXH_NO_LONG_LONG`: removes support for XXH3 and XXH64 for targets without 64-bit support.
|
||||
- `XXH_IMPORT`: MSVC specific: should only be defined for dynamic linking, as it prevents linkage errors.
|
||||
|
||||
|
||||
### Building xxHash - Using vcpkg
|
||||
@ -137,7 +136,7 @@ The xxHash port in vcpkg is kept up to date by Microsoft team members and commun
|
||||
|
||||
### Example
|
||||
|
||||
Calling xxhash 64-bit variant from a C program :
|
||||
Calling xxhash 64-bit variant from a C program:
|
||||
|
||||
```C
|
||||
#include "xxhash.h"
|
||||
@ -147,7 +146,7 @@ Calling xxhash 64-bit variant from a C program :
|
||||
}
|
||||
```
|
||||
|
||||
Using streaming variant is more involved, but makes it possible to provide data incrementally :
|
||||
Using streaming variant is more involved, but makes it possible to provide data incrementally:
|
||||
```C
|
||||
#include "stdlib.h" /* abort() */
|
||||
#include "xxhash.h"
|
||||
@ -190,9 +189,9 @@ XXH64_hash_t calcul_hash_streaming(FileHandler fh)
|
||||
|
||||
### Other programming languages
|
||||
|
||||
Beyond the C reference version,
|
||||
xxHash is also available in many programming languages,
|
||||
thanks to great contributors.
|
||||
Aside from the C reference version,
|
||||
xxHash is also available in many different programming languages,
|
||||
thanks to many great contributors.
|
||||
They are [listed here](http://www.xxhash.com/#other-languages).
|
||||
|
||||
|
||||
|
||||
@ -31,25 +31,25 @@ Table of Contents
|
||||
Introduction
|
||||
----------------
|
||||
|
||||
This document describes the xxHash digest algorithm, for both 32 and 64 variants, named `XXH32` and `XXH64`. The algorithm takes as input a message of arbitrary length and an optional seed value, it then produces an output of 32 or 64-bit as "fingerprint" or "digest".
|
||||
This document describes the xxHash digest algorithm for both 32-bit and 64-bit variants, named `XXH32` and `XXH64`. The algorithm takes an input a message of arbitrary length and an optional seed value, then produces an output of 32 or 64-bit as "fingerprint" or "digest".
|
||||
|
||||
xxHash is primarily designed for speed. It is labelled non-cryptographic, and is not meant to avoid intentional collisions (same digest for 2 different messages), or to prevent producing a message with predefined digest.
|
||||
xxHash is primarily designed for speed. It is labeled non-cryptographic, and is not meant to avoid intentional collisions (same digest for 2 different messages), or to prevent producing a message with a predefined digest.
|
||||
|
||||
XXH32 is designed to be fast on 32-bits machines.
|
||||
XXH64 is designed to be fast on 64-bits machines.
|
||||
XXH32 is designed to be fast on 32-bit machines.
|
||||
XXH64 is designed to be fast on 64-bit machines.
|
||||
Both variants produce different output.
|
||||
However, a given variant shall produce exactly the same output, irrespective of the cpu / os used. In particular, the result remains identical whatever the endianness and width of the cpu.
|
||||
However, a given variant shall produce exactly the same output, irrespective of the cpu / os used. In particular, the result remains identical whatever the endianness and width of the cpu is.
|
||||
|
||||
### Operation notations
|
||||
|
||||
All operations are performed modulo {32,64} bits. Arithmetic overflows are expected.
|
||||
`XXH32` uses 32-bit modular operations. `XXH64` uses 64-bit modular operations.
|
||||
|
||||
- `+` : denote modular addition
|
||||
- `*` : denote modular multiplication
|
||||
- `X <<< s` : denote the value obtained by circularly shifting (rotating) `X` left by `s` bit positions.
|
||||
- `X >> s` : denote the value obtained by shifting `X` right by s bit positions. Upper `s` bits become `0`.
|
||||
- `X xor Y` : denote the bit-wise XOR of `X` and `Y` (same width).
|
||||
- `+`: denotes modular addition
|
||||
- `*`: denotes modular multiplication
|
||||
- `X <<< s`: denotes the value obtained by circularly shifting (rotating) `X` left by `s` bit positions.
|
||||
- `X >> s`: denotes the value obtained by shifting `X` right by s bit positions. Upper `s` bits become `0`.
|
||||
- `X xor Y`: denotes the bit-wise XOR of `X` and `Y` (same width).
|
||||
|
||||
|
||||
XXH32 Algorithm Description
|
||||
@ -61,13 +61,13 @@ We begin by supposing that we have a message of any length `L` as input, and tha
|
||||
|
||||
The algorithm collect and transform input in _stripes_ of 16 bytes. The transforms are stored inside 4 "accumulators", each one storing an unsigned 32-bit value. Each accumulator can be processed independently in parallel, speeding up processing for cpu with multiple execution units.
|
||||
|
||||
The algorithm uses 32-bits addition, multiplication, rotate, shift and xor operations. Many operations require some 32-bits prime number constants, all defined below :
|
||||
The algorithm uses 32-bits addition, multiplication, rotate, shift and xor operations. Many operations require some 32-bits prime number constants, all defined below:
|
||||
|
||||
static const u32 PRIME32_1 = 2654435761U; // 0b10011110001101110111100110110001
|
||||
static const u32 PRIME32_2 = 2246822519U; // 0b10000101111010111100101001110111
|
||||
static const u32 PRIME32_3 = 3266489917U; // 0b11000010101100101010111000111101
|
||||
static const u32 PRIME32_4 = 668265263U; // 0b00100111110101001110101100101111
|
||||
static const u32 PRIME32_5 = 374761393U; // 0b00010110010101100110011110110001
|
||||
static const u32 PRIME32_1 = 0x9E3779B1U; // 0b10011110001101110111100110110001
|
||||
static const u32 PRIME32_2 = 0x85EBCA77U; // 0b10000101111010111100101001110111
|
||||
static const u32 PRIME32_3 = 0xC2B2AE3DU; // 0b11000010101100101010111000111101
|
||||
static const u32 PRIME32_4 = 0x27D4EB2FU; // 0b00100111110101001110101100101111
|
||||
static const u32 PRIME32_5 = 0x165667B1U; // 0b00010110010101100110011110110001
|
||||
|
||||
These constants are prime numbers, and feature a good mix of bits 1 and 0, neither too regular, nor too dissymmetric. These properties help dispersion capabilities.
|
||||
|
||||
@ -80,11 +80,11 @@ Each accumulator gets an initial value based on optional `seed` input. Since the
|
||||
u32 acc3 = seed + 0;
|
||||
u32 acc4 = seed - PRIME32_1;
|
||||
|
||||
#### Special case : input is less than 16 bytes
|
||||
#### Special case: input is less than 16 bytes
|
||||
|
||||
When input is too small (< 16 bytes), the algorithm will not process any stripe. Consequently, it will not make use of parallel accumulators.
|
||||
When the input is too small (< 16 bytes), the algorithm will not process any stripes. Consequently, it will not make use of parallel accumulators.
|
||||
|
||||
In which case, a simplified initialization is performed, using a single accumulator :
|
||||
In this case, a simplified initialization is performed, using a single accumulator:
|
||||
|
||||
u32 acc = seed + PRIME32_5;
|
||||
|
||||
@ -106,12 +106,12 @@ For each {lane, accumulator}, the update process is called a _round_, and applie
|
||||
|
||||
This shuffles the bits so that any bit from input _lane_ impacts several bits in output _accumulator_. All operations are performed modulo 2^32.
|
||||
|
||||
Input is consumed one full stripe at a time. Step 2 is looped as many times as necessary to consume the whole input, except the last remaining bytes which cannot form a stripe (< 16 bytes).
|
||||
Input is consumed one full stripe at a time. Step 2 is looped as many times as necessary to consume the whole input, except for the last remaining bytes which cannot form a stripe (< 16 bytes).
|
||||
When that happens, move to step 3.
|
||||
|
||||
### Step 3. Accumulator convergence
|
||||
|
||||
All 4 lane accumulators from previous steps are merged to produce a single remaining accumulator of same width (32-bit). The associated formula is as follows :
|
||||
All 4 lane accumulators from the previous steps are merged to produce a single remaining accumulator of the same width (32-bit). The associated formula is as follows:
|
||||
|
||||
acc = (acc1 <<< 1) + (acc2 <<< 7) + (acc3 <<< 12) + (acc4 <<< 18);
|
||||
|
||||
@ -126,7 +126,7 @@ Note that, if input length is so large that it requires more than 32-bits, only
|
||||
### Step 5. Consume remaining input
|
||||
|
||||
There may be up to 15 bytes remaining to consume from the input.
|
||||
The final stage will digest them according to following pseudo-code :
|
||||
The final stage will digest them according to following pseudo-code:
|
||||
|
||||
while (remainingLength >= 4) {
|
||||
lane = read_32bit_little_endian(input_ptr);
|
||||
@ -166,17 +166,17 @@ XXH64 Algorithm Description
|
||||
|
||||
### Overview
|
||||
|
||||
`XXH64` algorithm structure is very similar to `XXH32` one. The major difference is that `XXH64` uses 64-bit arithmetic, speeding up memory transfer for 64-bit compliant systems, but also relying on cpu capability to efficiently perform 64-bit operations.
|
||||
`XXH64`'s algorithm structure is very similar to `XXH32` one. The major difference is that `XXH64` uses 64-bit arithmetic, speeding up memory transfer for 64-bit compliant systems, but also relying on cpu capability to efficiently perform 64-bit operations.
|
||||
|
||||
The algorithm collects and transforms input in _stripes_ of 32 bytes. The transforms are stored inside 4 "accumulators", each one storing an unsigned 64-bit value. Each accumulator can be processed independently in parallel, speeding up processing for cpu with multiple execution units.
|
||||
|
||||
The algorithm uses 64-bit addition, multiplication, rotate, shift and xor operations. Many operations require some 64-bit prime number constants, all defined below :
|
||||
The algorithm uses 64-bit addition, multiplication, rotate, shift and xor operations. Many operations require some 64-bit prime number constants, all defined below:
|
||||
|
||||
static const u64 PRIME64_1 = 11400714785074694791ULL; // 0b1001111000110111011110011011000110000101111010111100101010000111
|
||||
static const u64 PRIME64_2 = 14029467366897019727ULL; // 0b1100001010110010101011100011110100100111110101001110101101001111
|
||||
static const u64 PRIME64_3 = 1609587929392839161ULL; // 0b0001011001010110011001111011000110011110001101110111100111111001
|
||||
static const u64 PRIME64_4 = 9650029242287828579ULL; // 0b1000010111101011110010100111011111000010101100101010111001100011
|
||||
static const u64 PRIME64_5 = 2870177450012600261ULL; // 0b0010011111010100111010110010111100010110010101100110011111000101
|
||||
static const u64 PRIME64_1 = 0x9E3779B185EBCA87ULL; // 0b1001111000110111011110011011000110000101111010111100101010000111
|
||||
static const u64 PRIME64_2 = 0xC2B2AE3D27D4EB4FULL; // 0b1100001010110010101011100011110100100111110101001110101101001111
|
||||
static const u64 PRIME64_3 = 0x165667B19E3779F9ULL; // 0b0001011001010110011001111011000110011110001101110111100111111001
|
||||
static const u64 PRIME64_4 = 0x85EBCA77C2B2AE63ULL; // 0b1000010111101011110010100111011111000010101100101010111001100011
|
||||
static const u64 PRIME64_5 = 0x27D4EB2F165667C5ULL; // 0b0010011111010100111010110010111100010110010101100110011111000101
|
||||
|
||||
These constants are prime numbers, and feature a good mix of bits 1 and 0, neither too regular, nor too dissymmetric. These properties help dispersion capabilities.
|
||||
|
||||
@ -189,11 +189,11 @@ Each accumulator gets an initial value based on optional `seed` input. Since the
|
||||
u64 acc3 = seed + 0;
|
||||
u64 acc4 = seed - PRIME64_1;
|
||||
|
||||
#### Special case : input is less than 32 bytes
|
||||
#### Special case: input is less than 32 bytes
|
||||
|
||||
When input is too small (< 32 bytes), the algorithm will not process any stripe. Consequently, it will not make use of parallel accumulators.
|
||||
When the input is too small (< 32 bytes), the algorithm will not process any stripes. Consequently, it will not make use of parallel accumulators.
|
||||
|
||||
In which case, a simplified initialization is performed, using a single accumulator :
|
||||
In this case, a simplified initialization is performed, using a single accumulator:
|
||||
|
||||
u64 acc = seed + PRIME64_5;
|
||||
|
||||
@ -216,14 +216,14 @@ For each {lane, accumulator}, the update process is called a _round_, and applie
|
||||
|
||||
This shuffles the bits so that any bit from input _lane_ impacts several bits in output _accumulator_. All operations are performed modulo 2^64.
|
||||
|
||||
Input is consumed one full stripe at a time. Step 2 is looped as many times as necessary to consume the whole input, except the last remaining bytes which cannot form a stripe (< 32 bytes).
|
||||
Input is consumed one full stripe at a time. Step 2 is looped as many times as necessary to consume the whole input, except for the last remaining bytes which cannot form a stripe (< 32 bytes).
|
||||
When that happens, move to step 3.
|
||||
|
||||
### Step 3. Accumulator convergence
|
||||
|
||||
All 4 lane accumulators from previous steps are merged to produce a single remaining accumulator of same width (64-bit). The associated formula is as follows.
|
||||
|
||||
Note that accumulator convergence is more complex than 32-bit variant, and requires to define another function called _mergeAccumulator()_ :
|
||||
Note that accumulator convergence is more complex than 32-bit variant, and requires to define another function called _mergeAccumulator()_:
|
||||
|
||||
mergeAccumulator(acc,accN):
|
||||
acc = acc xor round(0, accN);
|
||||
@ -247,7 +247,7 @@ The input total length is presumed known at this stage. This step is just about
|
||||
### Step 5. Consume remaining input
|
||||
|
||||
There may be up to 31 bytes remaining to consume from the input.
|
||||
The final stage will digest them according to following pseudo-code :
|
||||
The final stage will digest them according to following pseudo-code:
|
||||
|
||||
while (remainingLength >= 8) {
|
||||
lane = read_64bit_little_endian(input_ptr);
|
||||
@ -299,18 +299,19 @@ The algorithm allows input to be streamed and processed in multiple steps. In su
|
||||
|
||||
On 64-bit systems, the 64-bit variant `XXH64` is generally faster to compute, so it is a recommended variant, even when only 32-bit are needed.
|
||||
|
||||
On 32-bit systems though, positions are reversed : `XXH64` performance is reduced, due to its usage of 64-bit arithmetic. `XXH32` becomes a faster variant.
|
||||
On 32-bit systems though, positions are reversed: `XXH64` performance is reduced, due to its usage of 64-bit arithmetic. `XXH32` becomes a faster variant.
|
||||
|
||||
|
||||
Reference Implementation
|
||||
----------------------------------------
|
||||
|
||||
A reference library written in C is available at http://www.xxhash.com .
|
||||
A reference library written in C is available at http://www.xxhash.com.
|
||||
The web page also links to multiple other implementations written in many different languages.
|
||||
It links to the [github project page](https://github.com/Cyan4973/xxHash) where an [issue board](https://github.com/Cyan4973/xxHash/issues) can be used for further public discussions on the topic.
|
||||
|
||||
|
||||
Version changes
|
||||
--------------------
|
||||
v0.1.1 : added a note on rationale for selection of constants
|
||||
v0.1.0 : initial release
|
||||
v0.7.3: Minor fixes
|
||||
v0.1.1: added a note on rationale for selection of constants
|
||||
v0.1.0: initial release
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
/*
|
||||
* Hash benchmark module
|
||||
* Part of xxHash project
|
||||
* Part of the xxHash project
|
||||
* Copyright (C) 2019-present, Yann Collet
|
||||
*
|
||||
* GPL v2 License
|
||||
@ -19,9 +19,9 @@
|
||||
* with this program; if not, write to the Free Software Foundation, Inc.,
|
||||
* 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
|
||||
*
|
||||
* You can contact the author at :
|
||||
* - xxHash homepage : http://www.xxhash.com
|
||||
* - xxHash source repository : https://github.com/Cyan4973/xxHash
|
||||
* You can contact the author at:
|
||||
* - xxHash homepage: http://www.xxhash.com
|
||||
* - xxHash source repository: https://github.com/Cyan4973/xxHash
|
||||
*/
|
||||
|
||||
/* benchmark hash functions */
|
||||
@ -50,9 +50,10 @@ static void initBuffer(void* buffer, size_t size)
|
||||
|
||||
typedef size_t (*sizeFunction_f)(size_t targetSize);
|
||||
|
||||
/* bench_hash_internal() :
|
||||
* benchmark hashfn repeateadly over single input of size `size`
|
||||
* return : nb of hashes per second
|
||||
/*
|
||||
* bench_hash_internal():
|
||||
* Benchmarks hashfn repeateadly over single input of size `size`
|
||||
* return: nb of hashes per second
|
||||
*/
|
||||
static double
|
||||
bench_hash_internal(BMK_benchFn_t hashfn, void* payload,
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
/*
|
||||
* Hash benchmark module
|
||||
* Part of xxHash project
|
||||
* Part of the xxHash project
|
||||
* Copyright (C) 2019-present, Yann Collet
|
||||
*
|
||||
* GPL v2 License
|
||||
@ -19,9 +19,9 @@
|
||||
* with this program; if not, write to the Free Software Foundation, Inc.,
|
||||
* 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
|
||||
*
|
||||
* You can contact the author at :
|
||||
* - xxHash homepage : http://www.xxhash.com
|
||||
* - xxHash source repository : https://github.com/Cyan4973/xxHash
|
||||
* You can contact the author at:
|
||||
* - xxHash homepage: http://www.xxhash.com
|
||||
* - xxHash source repository: https://github.com/Cyan4973/xxHash
|
||||
*/
|
||||
|
||||
|
||||
@ -46,10 +46,12 @@ typedef enum { BMK_fixedSize, /* hash always `size` bytes */
|
||||
BMK_randomSize, /* hash a random nb of bytes, between 1 and `size` (inclusive) */
|
||||
} BMK_sizeMode;
|
||||
|
||||
/* bench_hash() :
|
||||
* returns speed expressed as nb hashes per second.
|
||||
* total_time_ms : time spent benchmarking the hash function with given parameters
|
||||
* iter_time_ms : time spent for one round. If multiple rounds are run, bench_hash() will report the speed of best round.
|
||||
/*
|
||||
* bench_hash():
|
||||
* Returns speed expressed as nb hashes per second.
|
||||
* total_time_ms: time spent benchmarking the hash function with given parameters
|
||||
* iter_time_ms: time spent for one round. If multiple rounds are run,
|
||||
* bench_hash() will report the speed of best round.
|
||||
*/
|
||||
double bench_hash(BMK_benchFn_t hashfn,
|
||||
BMK_benchMode benchMode,
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
/*
|
||||
* CSV Display module for the hash benchmark program
|
||||
* Part of xxHash project
|
||||
* Part of the xxHash project
|
||||
* Copyright (C) 2019-present, Yann Collet
|
||||
*
|
||||
* GPL v2 License
|
||||
@ -66,7 +66,7 @@ void bench_largeInput(Bench_Entry const* hashDescTable, int nbHashes, int minlog
|
||||
|
||||
|
||||
|
||||
/* === benchmark small input === */
|
||||
/* === Benchmark small inputs === */
|
||||
|
||||
#define BENCH_SMALL_ITER_MS 170
|
||||
#define BENCH_SMALL_TOTAL_MS 490
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
/*
|
||||
* CSV Display module for the hash benchmark program
|
||||
* Part of xxHash project
|
||||
* Part of the xxHash project
|
||||
* Copyright (C) 2019-present, Yann Collet
|
||||
*
|
||||
* GPL v2 License
|
||||
|
||||
@ -42,9 +42,10 @@
|
||||
#include <assert.h>
|
||||
|
||||
|
||||
/*! readIntFromChar() :
|
||||
* allows and interprets K, KB, KiB, M, MB and MiB suffix.
|
||||
* Will also modify `*stringPtr`, advancing it to position where it stopped reading.
|
||||
/*!
|
||||
* readIntFromChar():
|
||||
* Allows and interprets K, KB, KiB, M, MB and MiB suffix.
|
||||
* Will also modify `*stringPtr`, advancing it to position where it stopped reading.
|
||||
*/
|
||||
static int readIntFromChar(const char** stringPtr)
|
||||
{
|
||||
@ -72,25 +73,30 @@ static int readIntFromChar(const char** stringPtr)
|
||||
}
|
||||
|
||||
|
||||
/** longCommand() :
|
||||
* check if string is the same as longCommand.
|
||||
* If yes, @return 1 and advances *stringPtr to the position which immediately follows longCommand.
|
||||
* @return 0 and doesn't modify *stringPtr otherwise.
|
||||
/**
|
||||
* longCommand():
|
||||
* Checks if string is the same as longCommand.
|
||||
* If yes, @return 1, otherwise @return 0
|
||||
*/
|
||||
static int isCommand(const char* stringPtr, const char* longCommand)
|
||||
static int isCommand(const char* string, const char* longCommand)
|
||||
{
|
||||
assert(string);
|
||||
assert(longCommand);
|
||||
size_t const comSize = strlen(longCommand);
|
||||
assert(stringPtr); assert(longCommand);
|
||||
return !strncmp(stringPtr, longCommand, comSize);
|
||||
return !strncmp(string, longCommand, comSize);
|
||||
}
|
||||
|
||||
/** longCommandWArg() :
|
||||
* check if *stringPtr is the same as longCommand.
|
||||
* If yes, @return 1 and advances *stringPtr to the position which immediately follows longCommand.
|
||||
/*
|
||||
* longCommandWArg():
|
||||
* Checks if *stringPtr is the same as longCommand.
|
||||
* If yes, @return 1 and advances *stringPtr to the position which immediately
|
||||
* follows longCommand.
|
||||
* @return 0 and doesn't modify *stringPtr otherwise.
|
||||
*/
|
||||
static int longCommandWArg(const char** stringPtr, const char* longCommand)
|
||||
{
|
||||
assert(stringPtr);
|
||||
assert(longCommand);
|
||||
size_t const comSize = strlen(longCommand);
|
||||
int const result = isCommand(*stringPtr, longCommand);
|
||||
if (result) *stringPtr += comSize;
|
||||
@ -142,14 +148,16 @@ static int hashID(const char* hname)
|
||||
|
||||
static int help(const char* exename)
|
||||
{
|
||||
printf("usage : %s [options] [hash] \n\n", exename);
|
||||
printf("Usage: %s [options]... [hash]\n", exename);
|
||||
printf("Runs various benchmarks at various lengths for the listed hash functions\n");
|
||||
printf("and outputs them in a CSV format.\n\n");
|
||||
printf("Options: \n");
|
||||
printf("--list : name available hash algorithms and exit \n");
|
||||
printf("--mins=# : starting length for small size bench (default:%i) \n", SMALL_SIZE_MIN_DEFAULT);
|
||||
printf("--maxs=# : end length for small size bench (default:%i) \n", SMALL_SIZE_MAX_DEFAULT);
|
||||
printf("--minl=# : starting log2(length) for large size bench (default:%i) \n", LARGE_SIZELOG_MIN_DEFAULT);
|
||||
printf("--maxl=# : end log2(length) for large size bench (default:%i) \n", LARGE_SIZELOG_MAX_DEFAULT);
|
||||
printf("[hash] : is optional, bench all available hashes if not provided \n");
|
||||
printf(" --list Name available hash algorithms and exit \n");
|
||||
printf(" --mins=LEN Starting length for small size bench (default: %i) \n", SMALL_SIZE_MIN_DEFAULT);
|
||||
printf(" --maxs=LEN End length for small size bench (default: %i) \n", SMALL_SIZE_MAX_DEFAULT);
|
||||
printf(" --minl=LEN Starting log2(length) for large size bench (default: %i) \n", LARGE_SIZELOG_MIN_DEFAULT);
|
||||
printf(" --maxl=LEN End log2(length) for large size bench (default: %i) \n", LARGE_SIZELOG_MAX_DEFAULT);
|
||||
printf(" [hash] Optional, bench all available hashes if not provided \n");
|
||||
return 0;
|
||||
}
|
||||
|
||||
@ -180,17 +188,21 @@ int main(int argc, const char** argv)
|
||||
if (longCommandWArg(arg, "--maxl=")) { largeTest_log_max = readIntFromChar(arg); continue; }
|
||||
if (longCommandWArg(arg, "--mins=")) { smallTest_size_min = (size_t)readIntFromChar(arg); continue; }
|
||||
if (longCommandWArg(arg, "--maxs=")) { smallTest_size_max = (size_t)readIntFromChar(arg); continue; }
|
||||
/* not a command : must be a hash name */
|
||||
/* not a command: must be a hash name */
|
||||
hashNb = hashID(*arg);
|
||||
if (hashNb >= 0) {
|
||||
nb_h_test = 1;
|
||||
} else {
|
||||
/* not a hash name : error */
|
||||
/* not a hash name: error */
|
||||
return badusage(exename);
|
||||
}
|
||||
}
|
||||
|
||||
if (hashNb + nb_h_test > NB_HASHES) { printf("wrong hash selection \n"); return 1; } /* border case (requires (mis)using hidden command `--n=#`) */
|
||||
/* border case (requires (mis)using hidden command `--n=#`) */
|
||||
if (hashNb + nb_h_test > NB_HASHES) {
|
||||
printf("wrong hash selection \n");
|
||||
return 1;
|
||||
}
|
||||
|
||||
printf(" === benchmarking %i hash functions === \n", nb_h_test);
|
||||
if (largeTest_log_max >= largeTest_log_min) {
|
||||
|
||||
@ -9,7 +9,7 @@ By default, it will generate 24 billion of 64-bit hashes,
|
||||
requiring __192 GB of RAM__ for their storage.
|
||||
The number of hashes can be modified using command `--nbh=`.
|
||||
Be aware that testing the collision ratio of 64-bit hashes
|
||||
requires a very large amount of hashes (several billions) for meaningful measurements.
|
||||
requires a very large amount of hashes (several billion) for meaningful measurements.
|
||||
|
||||
To reduce RAM usage, an optional filter can be requested, with `--filter`.
|
||||
It reduces the nb of candidates to analyze, hence associated RAM budget.
|
||||
@ -22,9 +22,9 @@ It also doesn't allow advanced analysis of partial bitfields,
|
||||
since most hashes will be discarded and not stored.
|
||||
|
||||
When using the filter, the RAM budget consists of the filter and a list of candidates,
|
||||
which will be a fraction of original hash list.
|
||||
Using default settings (24 billions hashes, 32 GB filter),
|
||||
the number of potential candidates should be reduced to less than 2 billions,
|
||||
which will be a fraction of the original hash list.
|
||||
Using default settings (24 billion hashes, 32 GB filter),
|
||||
the number of potential candidates should be reduced to less than 2 billion,
|
||||
requiring ~14 GB for their storage.
|
||||
Such a result also depends on hash algorithm's efficiency.
|
||||
The number of effective candidates is likely to be lower, at ~ 1 billion,
|
||||
@ -37,26 +37,26 @@ For the default test, the expected "optimal" collision rate for a 64-bit hash fu
|
||||
make
|
||||
```
|
||||
|
||||
Note : the code is a mix of C99 and C++14,
|
||||
Note: the code is a mix of C99 and C++14,
|
||||
it's not compatible with a C90-only compiler.
|
||||
|
||||
#### Build modifier
|
||||
|
||||
- `SLAB5` : use alternative pattern generator, friendlier for weak hash algorithms
|
||||
- `POOL_MT` : if `=0`, disable multi-treading code (enabled by default)
|
||||
- `SLAB5`: use alternative pattern generator, friendlier for weak hash algorithms
|
||||
- `POOL_MT`: if `=0`, disable multi-threading code (enabled by default)
|
||||
|
||||
#### How to integrate any hash in the tester
|
||||
|
||||
The build script is expecting to compile files found in `./allcodecs`.
|
||||
The build script will compile files found in `./allcodecs`.
|
||||
Put the source code here.
|
||||
This also works if the hash is a single `*.h` file.
|
||||
|
||||
The glue happens in `hashes.h`.
|
||||
In this file, there are 2 sections :
|
||||
- Add the required `#include "header.h"`, and create a wrapper,
|
||||
In this file, there are 2 sections:
|
||||
- Adds the required `#include "header.h"`, and creates a wrapper
|
||||
to respect the format expected by the function pointer.
|
||||
- Add the wrapper, along with the name and an indication of the output width,
|
||||
to the table, at the end of `hashed.h`
|
||||
- Adds the wrapper, along with the name and an indication of the output width,
|
||||
to the table, at the end of `hashes.h`
|
||||
|
||||
Build with `make`. Locate your new hash with `./collisionsTest -h`,
|
||||
it should be listed.
|
||||
@ -67,13 +67,13 @@ it should be listed.
|
||||
```
|
||||
usage: ./collisionsTest [hashName] [opt]
|
||||
|
||||
list of hashNames : (...)
|
||||
list of hashNames: (...)
|
||||
|
||||
Optional parameters:
|
||||
--nbh=# : select nb of hashes to generate (25769803776 by default)
|
||||
--filter : activated the filter. Reduce memory usage for same nb of hashes. Slower.
|
||||
--threadlog=# : use 2^# threads
|
||||
--len=# : select length of input (255 bytes by default)
|
||||
--nbh=NB Select nb of hashes to generate (25769803776 by default)
|
||||
--filter Enable the filter. Slower, but reduces memory usage for same nb of hashes.
|
||||
--threadlog=NB Use 2^NB threads
|
||||
--len=NB Select length of input (255 bytes by default)
|
||||
```
|
||||
|
||||
#### Some advises on how to setup a collisions test
|
||||
@ -91,24 +91,24 @@ By requesting 14G, the expectation is that the program will automatically
|
||||
size the filter to 16 GB, and expect to store ~1G candidates,
|
||||
leaving enough room to breeze for the system.
|
||||
|
||||
The command line becomes :
|
||||
The command line becomes:
|
||||
```
|
||||
./collisionsTest --nbh=14G --filter NameOfHash
|
||||
```
|
||||
|
||||
#### Examples :
|
||||
|
||||
Here are a few results produced with this tester :
|
||||
Here are a few results produced with this tester:
|
||||
|
||||
| Algorithm | Input Len | Nb Hashes | Expected | Nb Collisions | Notes |
|
||||
| --- | --- | --- | --- | --- | --- |
|
||||
| __XXH3__ | 256 | 100 Gi | 312.5 | 326 | |
|
||||
| __XXH64__ | 256 | 100 Gi | 312.5 | 294 | |
|
||||
| __XXH128__ | 256 | 100 Gi | 0.0 | 0 | As a 128-bit hash, we expect XXH128 to generate 0 hash |
|
||||
| __XXH128__ | 256 | 100 Gi | 0.0 | 0 | As a 128-bit hash, we expect XXH128 to generate 0 collisions |
|
||||
| __XXH128__ low 64-bit | 512 | 100 Gi | 312.5 | 321 | |
|
||||
| __XXH128__ high 64-bit | 512 | 100 Gi | 312.5 | 325 | |
|
||||
|
||||
Test on small inputs :
|
||||
Test on small inputs:
|
||||
|
||||
| Algorithm | Input Len | Nb Hashes | Expected | Nb Collisions | Notes |
|
||||
| --- | --- | --- | --- | --- | --- |
|
||||
|
||||
@ -18,16 +18,16 @@
|
||||
* with this program; if not, write to the Free Software Foundation, Inc.,
|
||||
* 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
|
||||
*
|
||||
* You can contact the author at :
|
||||
* - xxHash homepage : http://www.xxhash.com
|
||||
* - xxHash source repository : https://github.com/Cyan4973/xxHash
|
||||
* You can contact the author at:
|
||||
* - xxHash homepage: http://www.xxhash.com
|
||||
* - xxHash source repository: https://github.com/Cyan4973/xxHash
|
||||
*/
|
||||
|
||||
#ifndef HASHES_H_1235465
|
||||
#define HASHES_H_1235465
|
||||
|
||||
#include <stddef.h> /* size_t */
|
||||
#include <stdint.h> /* uint64_t */
|
||||
#include <stddef.h> /* size_t */
|
||||
#include <stdint.h> /* uint64_t */
|
||||
#define XXH_INLINE_ALL /* XXH128_hash_t */
|
||||
#include "xxhash.h"
|
||||
|
||||
|
||||
@ -18,22 +18,22 @@
|
||||
* with this program; if not, write to the Free Software Foundation, Inc.,
|
||||
* 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
|
||||
*
|
||||
* You can contact the author at :
|
||||
* - xxHash homepage : http://www.xxhash.com
|
||||
* - xxHash source repository : https://github.com/Cyan4973/xxHash
|
||||
* You can contact the author at:
|
||||
* - xxHash homepage: http://www.xxhash.com
|
||||
* - xxHash source repository: https://github.com/Cyan4973/xxHash
|
||||
*/
|
||||
|
||||
/*
|
||||
* The collision tester will generate 24 billions hashes (by default),
|
||||
* The collision tester will generate 24 billion hashes (by default),
|
||||
* and count how many collisions were produced by the 64-bit hash algorithm.
|
||||
* The optimal amount of collisions for 64-bit is ~18 collisions.
|
||||
* A good hash should be close to this figure.
|
||||
*
|
||||
* This program requires a lot of memory :
|
||||
* This program requires a lot of memory:
|
||||
* - Either store hash values directly => 192 GB
|
||||
* - Either use a filter :
|
||||
* - Either use a filter:
|
||||
* - 32 GB (by default) for the filter itself
|
||||
* - + ~14 GB for the list of hashes (depending on filter outcome)
|
||||
* - + ~14 GB for the list of hashes (depending on the filter's outcome)
|
||||
* Due to these memory constraints, it requires a 64-bit system.
|
||||
*/
|
||||
|
||||
@ -88,7 +88,8 @@ static void printHash(const void* table, size_t n, Htype_e htype)
|
||||
|
||||
/* === Generate Random unique Samples to hash === */
|
||||
|
||||
/* These functions will generate and update a sample to hash.
|
||||
/*
|
||||
* These functions will generate and update a sample to hash.
|
||||
* initSample() will fill a buffer with random bytes,
|
||||
* updateSample() will modify one slab in the input buffer.
|
||||
* updateSample() guarantees it will produce unique samples,
|
||||
@ -122,11 +123,11 @@ typedef enum { sf_slab5, sf_sparse } sf_genMode;
|
||||
|
||||
#ifdef SLAB5
|
||||
|
||||
/* Slab5 sample generation.
|
||||
* This algorithm generates unique inputs
|
||||
* flipping on average 16 bits per candidate.
|
||||
* It is generally much more friendly for most hash algorithms,
|
||||
* especially weaker ones, as it shuffles more the input.
|
||||
/*
|
||||
* Slab5 sample generation.
|
||||
* This algorithm generates unique inputs flipping on average 16 bits per candidate.
|
||||
* It is generally much more friendly for most hash algorithms, especially
|
||||
* weaker ones, as it shuffles more the input.
|
||||
* The algorithm also avoids overfitting the per4 or per8 ingestion patterns.
|
||||
*/
|
||||
|
||||
@ -193,12 +194,13 @@ static inline void update_sampleFactory(sampleFactory* sf)
|
||||
|
||||
#else
|
||||
|
||||
/* Sparse sample generation.
|
||||
/*
|
||||
* Sparse sample generation.
|
||||
* This is the default pattern generator.
|
||||
* It only flips one bit at a time (mostly).
|
||||
* Low hamming distance scenario is more difficult for weak hash algorithms.
|
||||
* Note that CRC are immune to this scenario,
|
||||
* since they are specifically designed to detect low hamming distances.
|
||||
* Note that CRC is immune to this scenario, since they are specifically
|
||||
* designed to detect low hamming distances.
|
||||
* Prefer the Slab5 pattern generator for collisions on CRC algorithms.
|
||||
*/
|
||||
|
||||
@ -297,13 +299,13 @@ static int updateBit(void* buffer, size_t* bitIdx, int level, size_t max)
|
||||
|
||||
flipbit(buffer, bitIdx[level]); /* erase previous bits */
|
||||
|
||||
if (bitIdx[level] < max-1) { /* simple case : go to next bit */
|
||||
if (bitIdx[level] < max-1) { /* simple case: go to next bit */
|
||||
bitIdx[level]++;
|
||||
flipbit(buffer, bitIdx[level]); /* set new bit */
|
||||
return 1;
|
||||
}
|
||||
|
||||
/* reached last bit : need to update a bit from lower level */
|
||||
/* reached last bit: need to update a bit from lower level */
|
||||
if (!updateBit(buffer, bitIdx, level-1, max-1)) return 0;
|
||||
bitIdx[level] = bitIdx[level-1] + 1;
|
||||
flipbit(buffer, bitIdx[level]); /* set new bit */
|
||||
@ -349,11 +351,12 @@ void free_Filter(Filter* bf)
|
||||
|
||||
#ifdef FILTER_1_PROBE
|
||||
|
||||
/* Attach hash to a slot
|
||||
* return : Nb of potential collision candidates detected
|
||||
* 0 : position not yet occupied
|
||||
* 2 : position previously occupied by a single candidate
|
||||
* 1 : position already occupied by multiple candidates
|
||||
/*
|
||||
* Attach hash to a slot
|
||||
* return: Nb of potential collision candidates detected
|
||||
* 0: position not yet occupied
|
||||
* 2: position previously occupied by a single candidate
|
||||
* 1: position already occupied by multiple candidates
|
||||
*/
|
||||
inline int Filter_insert(Filter* bf, int bflog, uint64_t hash)
|
||||
{
|
||||
@ -372,11 +375,12 @@ inline int Filter_insert(Filter* bf, int bflog, uint64_t hash)
|
||||
return addCandidates[existingCandidates];
|
||||
}
|
||||
|
||||
/* Check if provided 64-bit hash is a collision candidate
|
||||
/*
|
||||
* Check if provided 64-bit hash is a collision candidate
|
||||
* Requires the slot to be occupied by at least 2 candidates.
|
||||
* return >0 if hash is a collision candidate
|
||||
* 0 otherwise (slot unoccupied, or only one candidate)
|
||||
* note: slot unoccupied should not happen in this algorithm,
|
||||
* note: unoccupied slots should not happen in this algorithm,
|
||||
* since all hashes are supposed to have been inserted at least once.
|
||||
*/
|
||||
inline int Filter_check(const Filter* bf, int bflog, uint64_t hash)
|
||||
@ -392,19 +396,22 @@ inline int Filter_check(const Filter* bf, int bflog, uint64_t hash)
|
||||
|
||||
#else
|
||||
|
||||
/* 2-probes strategy,
|
||||
/*
|
||||
* 2-probes strategy,
|
||||
* more efficient at filtering candidates,
|
||||
* requires filter size to be > nb of hashes */
|
||||
* requires filter size to be > nb of hashes
|
||||
*/
|
||||
|
||||
#define MIN(a,b) ((a) < (b) ? (a) : (b))
|
||||
#define MAX(a,b) ((a) > (b) ? (a) : (b))
|
||||
|
||||
/* Attach hash to 2 slots
|
||||
* return : Nb of potential candidates detected
|
||||
* 0 : position not yet occupied
|
||||
* 2 : position previously occupied by a single candidate (at most)
|
||||
* 1 : position already occupied by multiple candidates
|
||||
*/
|
||||
/*
|
||||
* Attach hash to 2 slots
|
||||
* return: Nb of potential candidates detected
|
||||
* 0: position not yet occupied
|
||||
* 2: position previously occupied by a single candidate (at most)
|
||||
* 1: position already occupied by multiple candidates
|
||||
*/
|
||||
static inline int Filter_insert(Filter* bf, int bflog, uint64_t hash)
|
||||
{
|
||||
hash = avalanche64(hash);
|
||||
@ -437,13 +444,14 @@ static inline int Filter_insert(Filter* bf, int bflog, uint64_t hash)
|
||||
}
|
||||
|
||||
|
||||
/* Check if provided 64-bit hash is a collision candidate
|
||||
* Requires the slot to be occupied by at least 2 candidates.
|
||||
* return >0 if hash is collision candidate
|
||||
* 0 otherwise (slot unoccupied, or only one candidate)
|
||||
* note: slot unoccupied should not happen in this algorithm,
|
||||
* since all hashes are supposed to have been inserted at least once.
|
||||
*/
|
||||
/*
|
||||
* Check if provided 64-bit hash is a collision candidate
|
||||
* Requires the slot to be occupied by at least 2 candidates.
|
||||
* return >0 if hash is a collision candidate
|
||||
* 0 otherwise (slot unoccupied, or only one candidate)
|
||||
* note: unoccupied slots should not happen in this algorithm,
|
||||
* since all hashes are supposed to have been inserted at least once.
|
||||
*/
|
||||
static inline int Filter_check(const Filter* bf, int bflog, uint64_t hash)
|
||||
{
|
||||
hash = avalanche64(hash);
|
||||
@ -490,7 +498,7 @@ void update_indicator(uint64_t v, uint64_t total)
|
||||
}
|
||||
}
|
||||
|
||||
/* note : not thread safe */
|
||||
/* note: not thread safe */
|
||||
const char* displayDelay(double delay_s)
|
||||
{
|
||||
static char delayString[50];
|
||||
@ -568,7 +576,7 @@ typedef struct {
|
||||
uint64_t maskSelector;
|
||||
size_t sampleSize;
|
||||
uint64_t prngSeed;
|
||||
int filterLog; /* <0 = disable filter; 0= auto-size; */
|
||||
int filterLog; /* <0 = disable filter; 0 = auto-size; */
|
||||
int hashID;
|
||||
int display;
|
||||
int nbThreads;
|
||||
@ -608,7 +616,7 @@ static int isHighEqual(void* hTablePtr, size_t index1, size_t index2, Htype_e ht
|
||||
return (h1 >> rShift) == (h2 >> rShift);
|
||||
}
|
||||
|
||||
/* assumption : (htype*)hTablePtr[index] is valid */
|
||||
/* assumption: (htype*)hTablePtr[index] is valid */
|
||||
static void addHashCandidate(void* hTablePtr, UniHash h, Htype_e htype, size_t index)
|
||||
{
|
||||
if ((htype == ht64) || (htype == ht32)) {
|
||||
@ -668,12 +676,12 @@ static size_t search_collisions(
|
||||
|
||||
if (filter) {
|
||||
time_t const filterTBegin = time(NULL);
|
||||
DISPLAY(" create filter (%i GB) \n", (int)(bfsize >> 30));
|
||||
DISPLAY(" Creating filter (%i GB) \n", (int)(bfsize >> 30));
|
||||
bf = create_Filter(bflog);
|
||||
if (!bf) EXIT("not enough memory for filter");
|
||||
|
||||
|
||||
DISPLAY(" generate %llu hashes from samples of %u bytes \n",
|
||||
DISPLAY(" Generate %llu hashes from samples of %u bytes \n",
|
||||
(unsigned long long)totalH, (unsigned)sampleSize);
|
||||
nbPresents = 0;
|
||||
|
||||
@ -689,7 +697,7 @@ static size_t search_collisions(
|
||||
}
|
||||
|
||||
if (nbPresents==0) {
|
||||
DISPLAY(" analysis completed : no collision detected \n");
|
||||
DISPLAY(" Analysis completed: No collision detected \n");
|
||||
if (param.resultPtr) param.resultPtr->nbCollisions = 0;
|
||||
free_Filter(bf);
|
||||
free_sampleFactory(sf);
|
||||
@ -697,18 +705,18 @@ static size_t search_collisions(
|
||||
}
|
||||
|
||||
{ double const filterDelay = difftime(time(NULL), filterTBegin);
|
||||
DISPLAY(" generation and filter completed in %s, detected up to %llu candidates \n",
|
||||
DISPLAY(" Generation and filter completed in %s, detected up to %llu candidates \n",
|
||||
displayDelay(filterDelay), (unsigned long long) nbPresents);
|
||||
} }
|
||||
|
||||
|
||||
/* === store hash candidates : duplicates will be present here === */
|
||||
/* === store hash candidates: duplicates will be present here === */
|
||||
|
||||
time_t const storeTBegin = time(NULL);
|
||||
size_t const hashByteSize = (htype == ht128) ? 16 : 8;
|
||||
size_t const tableSize = (nbPresents+1) * hashByteSize;
|
||||
assert(tableSize > nbPresents); /* check tableSize calculation overflow */
|
||||
DISPLAY(" store hash candidates (%i MB) \n", (int)(tableSize >> 20));
|
||||
DISPLAY(" Storing hash candidates (%i MB) \n", (int)(tableSize >> 20));
|
||||
|
||||
/* Generate and store hashes */
|
||||
void* const hashCandidates = malloc(tableSize);
|
||||
@ -733,20 +741,20 @@ static size_t search_collisions(
|
||||
}
|
||||
}
|
||||
if (nbCandidates < nbPresents) {
|
||||
/* try to mitigate gnuc_quicksort behavior, by reducing allocated memory,
|
||||
/* Try to mitigate gnuc_quicksort behavior, by reducing allocated memory,
|
||||
* since gnuc_quicksort uses a lot of additional memory for mergesort */
|
||||
void* const checkPtr = realloc(hashCandidates, nbCandidates * hashByteSize);
|
||||
assert(checkPtr != NULL);
|
||||
assert(checkPtr == hashCandidates); /* simplification : since we are reducing size,
|
||||
assert(checkPtr == hashCandidates); /* simplification: since we are reducing the size,
|
||||
* we hope to keep the same ptr position.
|
||||
* Otherwise, hashCandidates must be mutable */
|
||||
DISPLAY(" list of hash reduced to %u MB from %u MB (saved %u MB) \n",
|
||||
* Otherwise, hashCandidates must be mutable. */
|
||||
DISPLAY(" List of hashes reduced to %u MB from %u MB (saved %u MB) \n",
|
||||
(unsigned)((nbCandidates * hashByteSize) >> 20),
|
||||
(unsigned)(tableSize >> 20),
|
||||
(unsigned)((tableSize - (nbCandidates * hashByteSize)) >> 20) );
|
||||
}
|
||||
double const storeTDelay = difftime(time(NULL), storeTBegin);
|
||||
DISPLAY(" stored %llu hash candidates in %s \n",
|
||||
DISPLAY(" Stored %llu hash candidates in %s \n",
|
||||
(unsigned long long) nbCandidates, displayDelay(storeTDelay));
|
||||
free_Filter(bf);
|
||||
free_sampleFactory(sf);
|
||||
@ -754,7 +762,7 @@ static size_t search_collisions(
|
||||
|
||||
/* === step 3 : look for duplicates === */
|
||||
time_t const sortTBegin = time(NULL);
|
||||
DISPLAY(" sorting candidates... ");
|
||||
DISPLAY(" Sorting candidates... ");
|
||||
fflush(NULL);
|
||||
if ((htype == ht64) || (htype == ht32)) {
|
||||
sort64(hashCandidates, nbCandidates); /* using C++ sort, as it's faster than C stdlib's qsort,
|
||||
@ -764,16 +772,16 @@ static size_t search_collisions(
|
||||
sort128(hashCandidates, nbCandidates); /* sort with custom comparator */
|
||||
}
|
||||
double const sortTDelay = difftime(time(NULL), sortTBegin);
|
||||
DISPLAY(" completed in %s \n", displayDelay(sortTDelay));
|
||||
DISPLAY(" Completed in %s \n", displayDelay(sortTDelay));
|
||||
|
||||
/* scan and count duplicates */
|
||||
time_t const countBegin = time(NULL);
|
||||
DISPLAY(" looking for duplicates : ");
|
||||
DISPLAY(" Looking for duplicates: ");
|
||||
fflush(NULL);
|
||||
size_t collisions = 0;
|
||||
for (size_t n=1; n<nbCandidates; n++) {
|
||||
if (isEqual(hashCandidates, n, n-1, htype)) {
|
||||
printf("collision : ");
|
||||
printf("collision: ");
|
||||
printHash(hashCandidates, n, htype);
|
||||
printf(" / ");
|
||||
printHash(hashCandidates, n-1, htype);
|
||||
@ -800,17 +808,17 @@ static size_t search_collisions(
|
||||
} }
|
||||
double const collisionRatio = (double)HBits_collisions / expectedCollisions;
|
||||
if (collisionRatio > 2.0) DISPLAY("WARNING !!! ===> ");
|
||||
DISPLAY(" high %i bits : %zu collision (%.1f expected) : x%.2f \n",
|
||||
DISPLAY(" high %i bits: %zu collision (%.1f expected): x%.2f \n",
|
||||
nbHBits, HBits_collisions, expectedCollisions, collisionRatio);
|
||||
if (collisionRatio > worstRatio) {
|
||||
worstNbHBits = nbHBits;
|
||||
worstRatio = collisionRatio;
|
||||
} } }
|
||||
DISPLAY("Worst collision ratio at %i high bits : x%.2f \n",
|
||||
DISPLAY("Worst collision ratio at %i high bits: x%.2f \n",
|
||||
worstNbHBits, worstRatio);
|
||||
}
|
||||
double const countDelay = difftime(time(NULL), countBegin);
|
||||
DISPLAY(" completed in %s \n", displayDelay(countDelay));
|
||||
DISPLAY(" Completed in %s \n", displayDelay(countDelay));
|
||||
|
||||
/* clean and exit */
|
||||
free (hashCandidates);
|
||||
@ -863,7 +871,7 @@ void time_collisions(searchCollisions_parameters param)
|
||||
size_t const programBytesSelf = getProcessMemUsage(0);
|
||||
size_t const programBytesChildren = getProcessMemUsage(1);
|
||||
DISPLAY("\n\n");
|
||||
DISPLAY("===> found %llu collisions (x%.2f, %.1f expected) in %s\n",
|
||||
DISPLAY("===> Found %llu collisions (x%.2f, %.1f expected) in %s\n",
|
||||
(unsigned long long)collisions,
|
||||
(double)collisions / targetColls,
|
||||
targetColls,
|
||||
@ -883,9 +891,10 @@ void MT_searchCollisions(void* payload)
|
||||
|
||||
/* === Command Line === */
|
||||
|
||||
/*! readU64FromChar() :
|
||||
* allows and interprets K, KB, KiB, M, MB and MiB suffix.
|
||||
* Will also modify `*stringPtr`, advancing it to position where it stopped reading.
|
||||
/*!
|
||||
* readU64FromChar():
|
||||
* Allows and interprets K, KB, KiB, M, MB and MiB suffix.
|
||||
* Will also modify `*stringPtr`, advancing it to the position where it stopped reading.
|
||||
*/
|
||||
static uint64_t readU64FromChar(const char** stringPtr)
|
||||
{
|
||||
@ -917,13 +926,15 @@ static uint64_t readU64FromChar(const char** stringPtr)
|
||||
}
|
||||
|
||||
|
||||
/** longCommandWArg() :
|
||||
* check if *stringPtr is the same as longCommand.
|
||||
* If yes, @return 1 and advances *stringPtr to the position which immediately follows longCommand.
|
||||
/**
|
||||
* longCommandWArg():
|
||||
* Checks if *stringPtr is the same as longCommand.
|
||||
* If yes, @return 1 and advances *stringPtr to the position which immediately follows longCommand.
|
||||
* @return 0 and doesn't modify *stringPtr otherwise.
|
||||
*/
|
||||
static int longCommandWArg(const char** stringPtr, const char* longCommand)
|
||||
{
|
||||
assert(longCommand); assert(stringPtr); assert(*stringPtr);
|
||||
size_t const comSize = strlen(longCommand);
|
||||
int const result = !strncmp(*stringPtr, longCommand, comSize);
|
||||
if (result) *stringPtr += comSize;
|
||||
@ -933,34 +944,36 @@ static int longCommandWArg(const char** stringPtr, const char* longCommand)
|
||||
|
||||
#include "pool.h"
|
||||
|
||||
/* As some hashes use different algorithms depending on input size,
|
||||
/*
|
||||
* As some hashes use different algorithms depending on input size,
|
||||
* it can be necessary to test multiple input sizes
|
||||
* to paint an accurate picture on collision performance */
|
||||
* to paint an accurate picture of collision performance
|
||||
*/
|
||||
#define SAMPLE_SIZE_DEFAULT 255
|
||||
#define HASHFN_ID_DEFAULT 0
|
||||
|
||||
void help(const char* exeName)
|
||||
{
|
||||
printf("usage: %s [hashName] [opt] \n\n", exeName);
|
||||
printf("list of hashNames : ");
|
||||
printf("list of hashNames:");
|
||||
printf("%s ", hashfnTable[0].name);
|
||||
for (int i=1; i < HASH_FN_TOTAL; i++) {
|
||||
printf(", %s ", hashfnTable[i].name);
|
||||
}
|
||||
printf(" \n");
|
||||
printf("default hashName is %s \n", hashfnTable[HASHFN_ID_DEFAULT].name);
|
||||
printf("Default hashName is %s\n", hashfnTable[HASHFN_ID_DEFAULT].name);
|
||||
|
||||
printf(" \n");
|
||||
printf("Optional parameters: \n");
|
||||
printf("--nbh=# : select nb of hashes to generate (%llu by default) \n", (unsigned long long)select_nbh(64));
|
||||
printf("--filter : activated the filter. Reduce memory usage for same nb of hashes. Slower. \n");
|
||||
printf("--threadlog=# : use 2^# threads \n");
|
||||
printf("--len=# : select length of input (%i bytes by default) \n", SAMPLE_SIZE_DEFAULT);
|
||||
printf(" --nbh=NB Select nb of hashes to generate (%llu by default) \n", (unsigned long long)select_nbh(64));
|
||||
printf(" --filter Activates the filter. Slower, but reduces memory usage for the same nb of hashes.\n");
|
||||
printf(" --threadlog=NB Use 2^NB threads.\n");
|
||||
printf(" --len=MB Set length of the input (%i bytes by default) \n", SAMPLE_SIZE_DEFAULT);
|
||||
}
|
||||
|
||||
int bad_argument(const char* exeName)
|
||||
{
|
||||
printf("incorrect command : \n");
|
||||
printf("incorrect command: \n");
|
||||
help(exeName);
|
||||
return 1;
|
||||
}
|
||||
@ -1020,7 +1033,7 @@ int main(int argc, const char** argv)
|
||||
|
||||
printf(" *** Collision tester for 64+ bit hashes *** \n\n");
|
||||
printf("Testing %s algorithm (%i-bit) \n", hname, hwidth);
|
||||
printf("This program will allocate a lot of memory, \n");
|
||||
printf("This program will allocate a lot of memory,\n");
|
||||
printf("generate %llu %i-bit hashes from samples of %u bytes, \n",
|
||||
(unsigned long long)totalH, hwidth, (unsigned)sampleSize);
|
||||
printf("and attempt to produce %.0f collisions. \n\n", targetColls);
|
||||
@ -1087,7 +1100,7 @@ int main(int argc, const char** argv)
|
||||
size_t const programBytesSelf = getProcessMemUsage(0);
|
||||
size_t const programBytesChildren = getProcessMemUsage(1);
|
||||
printf("\n\n");
|
||||
printf("===> found %llu collisions (x%.2f, %.1f expected) in %s \n",
|
||||
printf("===> Found %llu collisions (x%.2f, %.1f expected) in %s\n",
|
||||
(unsigned long long)nbCollisions,
|
||||
(double)nbCollisions / targetColls,
|
||||
targetColls,
|
||||
|
||||
@ -1,46 +1,50 @@
|
||||
/*
|
||||
* multiinclude test program
|
||||
* validate that xxhash.h can be included multiple times and in any order
|
||||
*
|
||||
* Copyright (C) Yann Collet 2013-present
|
||||
*
|
||||
* GPL v2 License
|
||||
*
|
||||
* This program is free software; you can redistribute it and/or modify
|
||||
* it under the terms of the GNU General Public License as published by
|
||||
* the Free Software Foundation; either version 2 of the License, or
|
||||
* (at your option) any later version.
|
||||
*
|
||||
* This program is distributed in the hope that it will be useful,
|
||||
* but WITHOUT ANY WARRANTY; without even the implied warranty of
|
||||
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
||||
* GNU General Public License for more details.
|
||||
*
|
||||
* You should have received a copy of the GNU General Public License along
|
||||
* with this program; if not, write to the Free Software Foundation, Inc.,
|
||||
* 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
|
||||
*
|
||||
* You can contact the author at :
|
||||
* - xxHash homepage : http://www.xxhash.com
|
||||
* - xxHash source repository : https://github.com/Cyan4973/xxHash
|
||||
*/
|
||||
* Multi-include test program
|
||||
* Validates that xxhash.h can be included multiple times and in any order
|
||||
*
|
||||
* Copyright (C) Yann Collet 2013-present
|
||||
*
|
||||
* GPL v2 License
|
||||
*
|
||||
* This program is free software; you can redistribute it and/or modify
|
||||
* it under the terms of the GNU General Public License as published by
|
||||
* the Free Software Foundation; either version 2 of the License, or
|
||||
* (at your option) any later version.
|
||||
*
|
||||
* This program is distributed in the hope that it will be useful,
|
||||
* but WITHOUT ANY WARRANTY; without even the implied warranty of
|
||||
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
||||
* GNU General Public License for more details.
|
||||
*
|
||||
* You should have received a copy of the GNU General Public License along
|
||||
* with this program; if not, write to the Free Software Foundation, Inc.,
|
||||
* 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
|
||||
*
|
||||
* You can contact the author at:
|
||||
* - xxHash homepage: http://www.xxhash.com
|
||||
* - xxHash source repository: https://github.com/Cyan4973/xxHash
|
||||
*/
|
||||
|
||||
#include <stdio.h> /* printf */
|
||||
|
||||
/* normal include, gives access to public symbols */
|
||||
/* Normal include, gives access to public symbols */
|
||||
#include "../xxhash.h"
|
||||
|
||||
/* advanced include, gives access to experimental symbols
|
||||
* This test ensure that xxhash.h can be included multiple times
|
||||
* and in any order. This order is more difficult :
|
||||
* without care, declaration of experimental symbols could be skipped */
|
||||
/*
|
||||
* Advanced include, gives access to experimental symbols
|
||||
* This test ensure that xxhash.h can be included multiple times and in any
|
||||
* order. This order is more difficult: Without care, declaration of
|
||||
* experimental symbols could be skipped.
|
||||
*/
|
||||
#define XXH_STATIC_LINKING_ONLY
|
||||
#include "../xxhash.h"
|
||||
|
||||
/* inlining : re-define all identifiers, keep them private to the unit.
|
||||
* note : without specific efforts, identifier names would collide
|
||||
* To be linked with and withouy xxhash.o,
|
||||
* to test symbol's presence and naming collisions */
|
||||
/*
|
||||
* Inlining: Re-define all identifiers, keep them private to the unit.
|
||||
* Note: Without specific efforts, identifier names would collide
|
||||
* To be linked with and without xxhash.o,
|
||||
* to test symbol's presence and naming collisions
|
||||
*/
|
||||
#define XXH_INLINE_ALL
|
||||
#include "../xxhash.h"
|
||||
|
||||
|
||||
298
xxh3.h
298
xxh3.h
@ -28,8 +28,8 @@
|
||||
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
You can contact the author at :
|
||||
- xxHash source repository : https://github.com/Cyan4973/xxHash
|
||||
You can contact the author at:
|
||||
- xxHash source repository: https://github.com/Cyan4973/xxHash
|
||||
*/
|
||||
|
||||
/* Note :
|
||||
@ -142,12 +142,11 @@
|
||||
*
|
||||
* Therefore, we do a quick sanity check.
|
||||
*
|
||||
* If compiling Thumb-1 for a target which supports ARM instructions, we
|
||||
* will give a warning, as it is not a "sane" platform to compile for.
|
||||
* If compiling Thumb-1 for a target which supports ARM instructions, we will
|
||||
* emit a warning, as it is not a "sane" platform to compile for.
|
||||
*
|
||||
* Usually, if this happens, it is because of an accident and you probably
|
||||
* need to specify -march, as you probably meant to compile for a newer
|
||||
* architecture.
|
||||
* Usually, if this happens, it is because of an accident and you probably need
|
||||
* to specify -march, as you likely meant to compile for a newer architecture.
|
||||
*/
|
||||
#if defined(__thumb__) && !defined(__thumb2__) && defined(__ARM_ARCH_ISA_ARM)
|
||||
# warning "XXH3 is highly inefficient without ARM or Thumb-2."
|
||||
@ -181,8 +180,10 @@
|
||||
# endif
|
||||
#endif
|
||||
|
||||
/* control alignment of accumulator,
|
||||
* for compatibility with fast vector loads */
|
||||
/*
|
||||
* Controls the alignment of the accumulator.
|
||||
* This is for compatibility with aligned vector loads, which are usually faster.
|
||||
*/
|
||||
#ifndef XXH_ACC_ALIGN
|
||||
# if XXH_VECTOR == XXH_SCALAR /* scalar */
|
||||
# define XXH_ACC_ALIGN 8
|
||||
@ -199,26 +200,24 @@
|
||||
|
||||
/*
|
||||
* UGLY HACK:
|
||||
* GCC usually generates the best code with -O3 for xxHash,
|
||||
* except for AVX2 where it is overzealous in its unrolling
|
||||
* resulting in code roughly 3/4 the speed of Clang.
|
||||
* GCC usually generates the best code with -O3 for xxHash.
|
||||
*
|
||||
* There are other issues, such as GCC splitting _mm256_loadu_si256
|
||||
* into _mm_loadu_si128 + _mm256_inserti128_si256 which is an
|
||||
* optimization which only applies to Sandy and Ivy Bridge... which
|
||||
* don't even support AVX2.
|
||||
* However, when targeting AVX2, it is overzealous in its unrolling resulting
|
||||
* in code roughly 3/4 the speed of Clang.
|
||||
*
|
||||
* That is why when compiling the AVX2 version, it is recommended
|
||||
* to use either
|
||||
* There are other issues, such as GCC splitting _mm256_loadu_si256 into
|
||||
* _mm_loadu_si128 + _mm256_inserti128_si256. This is an optimization which
|
||||
* only applies to Sandy and Ivy Bridge... which don't even support AVX2.
|
||||
*
|
||||
* That is why when compiling the AVX2 version, it is recommended to use either
|
||||
* -O2 -mavx2 -march=haswell
|
||||
* or
|
||||
* -O2 -mavx2 -mno-avx256-split-unaligned-load
|
||||
* for decent performance, or just use Clang instead.
|
||||
* for decent performance, or to use Clang instead.
|
||||
*
|
||||
* Fortunately, we can control the first one with a pragma
|
||||
* that forces GCC into -O2, but the other one we can't without
|
||||
* "failed to inline always inline function due to target mismatch"
|
||||
* warnings.
|
||||
* Fortunately, we can control the first one with a pragma that forces GCC into
|
||||
* -O2, but the other one we can't control without "failed to inline always
|
||||
* inline function due to target mismatch" warnings.
|
||||
*/
|
||||
#if XXH_VECTOR == XXH_AVX2 /* AVX2 */ \
|
||||
&& defined(__GNUC__) && !defined(__clang__) /* GCC, not Clang */ \
|
||||
@ -475,10 +474,9 @@ XXH_ALIGN(64) static const xxh_u8 kSecret[XXH_SECRET_DEFAULT_SIZE] = {
|
||||
#endif
|
||||
|
||||
/*
|
||||
* GCC for x86 has a tendency to use SSE in this loop. While it
|
||||
* successfully avoids swapping (as MUL overwrites EAX and EDX), it
|
||||
* slows it down because instead of free register swap shifts, it
|
||||
* must use pshufd and punpckl/hd.
|
||||
* GCC for x86 has a tendency to use SSE in this loop. While it successfully
|
||||
* avoids swapping (as MUL overwrites EAX and EDX), it slows it down because
|
||||
* instead of free register swap shifts, it must use PSHUFD and PUNPCKL/HD
|
||||
*
|
||||
* To prevent this, we use this attribute to shut off SSE.
|
||||
*/
|
||||
@ -497,9 +495,9 @@ XXH_mult64to128(xxh_u64 lhs, xxh_u64 rhs)
|
||||
*
|
||||
* Usually.
|
||||
*
|
||||
* Despite being a 32-bit platform, Clang (and emscripten) define this
|
||||
* type despite not having the arithmetic for it. This results in a
|
||||
* laggy compiler builtin call which calculates a full 128-bit multiply.
|
||||
* Despite being a 32-bit platform, Clang (and emscripten) define this type
|
||||
* despite not having the arithmetic for it. This results in a laggy
|
||||
* compiler builtin call which calculates a full 128-bit multiply.
|
||||
* In that case it is best to use the portable one.
|
||||
* https://github.com/Cyan4973/xxHash/issues/211#issuecomment-515575677
|
||||
*/
|
||||
@ -532,8 +530,8 @@ XXH_mult64to128(xxh_u64 lhs, xxh_u64 rhs)
|
||||
/*
|
||||
* Portable scalar method. Optimized for 32-bit and 64-bit ALUs.
|
||||
*
|
||||
* This is a fast and simple grade school multiply, which is shown
|
||||
* below with base 10 arithmetic instead of base 0x100000000.
|
||||
* This is a fast and simple grade school multiply, which is shown below
|
||||
* with base 10 arithmetic instead of base 0x100000000.
|
||||
*
|
||||
* 9 3 // D2 lhs = 93
|
||||
* x 7 5 // D2 rhs = 75
|
||||
@ -550,8 +548,8 @@ XXH_mult64to128(xxh_u64 lhs, xxh_u64 rhs)
|
||||
*
|
||||
* The reasons for adding the products like this are:
|
||||
* 1. It avoids manual carry tracking. Just like how
|
||||
* (9 * 9) + 9 + 9 = 99, the same applies with this for
|
||||
* UINT64_MAX. This avoids a lot of complexity.
|
||||
* (9 * 9) + 9 + 9 = 99, the same applies with this for UINT64_MAX.
|
||||
* This avoids a lot of complexity.
|
||||
*
|
||||
* 2. It hints for, and on Clang, compiles to, the powerful UMAAL
|
||||
* instruction available in ARM's Digital Signal Processing extension
|
||||
@ -564,12 +562,12 @@ XXH_mult64to128(xxh_u64 lhs, xxh_u64 rhs)
|
||||
* *RdHi = (xxh_u32)(product >> 32);
|
||||
* }
|
||||
*
|
||||
* This instruction was designed for efficient long multiplication,
|
||||
* and allows this to be calculated in only 4 instructions which
|
||||
* is comparable to some 64-bit ALUs.
|
||||
* This instruction was designed for efficient long multiplication, and
|
||||
* allows this to be calculated in only 4 instructions at speeds
|
||||
* comparable to some 64-bit ALUs.
|
||||
*
|
||||
* 3. It isn't terrible on other platforms. Usually this will be
|
||||
* a couple of 32-bit ADD/ADCs.
|
||||
* 3. It isn't terrible on other platforms. Usually this will be a couple
|
||||
* of 32-bit ADD/ADCs.
|
||||
*/
|
||||
|
||||
/* First calculate all of the cross products. */
|
||||
@ -589,13 +587,12 @@ XXH_mult64to128(xxh_u64 lhs, xxh_u64 rhs)
|
||||
}
|
||||
|
||||
/*
|
||||
* We want to keep the attribute here because a target switch
|
||||
* disables inlining.
|
||||
* We want to keep the attribute here because a target switch disables inlining.
|
||||
*
|
||||
* Does a 64-bit to 128-bit multiply, then XOR folds it.
|
||||
* The reason for the separate function is to prevent passing
|
||||
* too many structs around by value. This will hopefully inline
|
||||
* the multiply, but we don't force it.
|
||||
*
|
||||
* The reason for the separate function is to prevent passing too many structs
|
||||
* around by value. This will hopefully inline the multiply, but we don't force it.
|
||||
*/
|
||||
#if defined(__GNUC__) && !defined(__clang__) && defined(__i386__)
|
||||
__attribute__((__target__("no-sse")))
|
||||
@ -614,7 +611,11 @@ XXH_FORCE_INLINE xxh_u64 XXH_xorshift64(xxh_u64 v64, int shift)
|
||||
return v64 ^ (v64 >> shift);
|
||||
}
|
||||
|
||||
/* We don't need to (or want to) mix as much as XXH64 - short hashes are more evenly distributed */
|
||||
/*
|
||||
* We don't need to (or want to) mix as much as XXH64.
|
||||
*
|
||||
* Short hashes are more evenly distributed, so it isn't necessary.
|
||||
*/
|
||||
static XXH64_hash_t XXH3_avalanche(xxh_u64 h64)
|
||||
{
|
||||
h64 = XXH_xorshift64(h64, 37);
|
||||
@ -627,17 +628,18 @@ static XXH64_hash_t XXH3_avalanche(xxh_u64 h64)
|
||||
/* ==========================================
|
||||
* Short keys
|
||||
* ==========================================
|
||||
* One of the shortcomings of XXH32 and XXH64 was that their performance was sub-optimal on
|
||||
* short lengths. It used an iterative algorithm which strongly favored even lengths.
|
||||
* One of the shortcomings of XXH32 and XXH64 was that their performance was
|
||||
* sub-optimal on short lengths. It used an iterative algorithm which strongly
|
||||
* favored lengths that were a multiple of 4 or 8.
|
||||
*
|
||||
* Instead of iterating over individual inputs, we use a set of single shot functions which
|
||||
* piece together a range of lengths and operate in constant time.
|
||||
* Instead of iterating over individual inputs, we use a set of single shot
|
||||
* functions which piece together a range of lengths and operate in constant time.
|
||||
*
|
||||
* Additionally, the number of multiplies has been significantly reduced. This reduces latency,
|
||||
* especially with 64-bit multiplies on 32-bit.
|
||||
* Additionally, the number of multiplies has been significantly reduced. This
|
||||
* reduces latency, especially when emulating 64-bit multiplies on 32-bit.
|
||||
*
|
||||
* Depending on the platform, this may or may not be faster than XXH32, but it is almost
|
||||
* guaranteed to be faster than XXH64.
|
||||
* Depending on the platform, this may or may not be faster than XXH32, but it
|
||||
* is almost guaranteed to be faster than XXH64.
|
||||
*/
|
||||
|
||||
XXH_FORCE_INLINE XXH64_hash_t
|
||||
@ -712,25 +714,30 @@ XXH3_len_0to16_64b(const xxh_u8* input, size_t len, const xxh_u8* secret, XXH64_
|
||||
}
|
||||
|
||||
/*
|
||||
* DISCLAIMER: There are known *seed-dependent* multicollisions here due to multiplication
|
||||
* by zero, affecting hashes of lengths 17 to 240, however, they are very unlikely.
|
||||
* DISCLAIMER: There are known *seed-dependent* multicollisions here due to
|
||||
* multiplication by zero, affecting hashes of lengths 17 to 240.
|
||||
*
|
||||
* Keep this in mind when using the unseeded XXH3_64bits() variant: As with all unseeded
|
||||
* non-cryptographic hashes, it does not attempt to defend itself against specially crafted
|
||||
* inputs, only random inputs.
|
||||
* However, they are very unlikely.
|
||||
*
|
||||
* Compared to classic UMAC where a 1 in 2^31 chance of 4 consecutive bytes cancelling out
|
||||
* the secret is taken an arbitrary number of times (addressed in XXH3_accumulate_512), this
|
||||
* collision is very unlikely with random inputs and/or proper seeding:
|
||||
* Keep this in mind when using the unseeded XXH3_64bits() variant: As with all
|
||||
* unseeded non-cryptographic hashes, it does not attempt to defend itself
|
||||
* against specially crafted inputs, only random inputs.
|
||||
*
|
||||
* This only has a 1 in 2^63 chance of 8 consecutive bytes cancelling out, in a function
|
||||
* that is only called up to 16 times per hash with up to 240 bytes of input.
|
||||
* Compared to classic UMAC where a 1 in 2^31 chance of 4 consecutive bytes
|
||||
* cancelling out the secret is taken an arbitrary number of times (addressed
|
||||
* in XXH3_accumulate_512), this collision is very unlikely with random inputs
|
||||
* and/or proper seeding:
|
||||
*
|
||||
* This is not too bad for a non-cryptographic hash function, especially with only 64 bit
|
||||
* outputs.
|
||||
* This only has a 1 in 2^63 chance of 8 consecutive bytes cancelling out, in a
|
||||
* function that is only called up to 16 times per hash with up to 240 bytes of
|
||||
* input.
|
||||
*
|
||||
* The 128-bit variant (which trades some speed for strength) is NOT affected by this,
|
||||
* although it is always a good idea to use a proper seed if you care about strength.
|
||||
* This is not too bad for a non-cryptographic hash function, especially with
|
||||
* only 64 bit outputs.
|
||||
*
|
||||
* The 128-bit variant (which trades some speed for strength) is NOT affected
|
||||
* by this, although it is always a good idea to use a proper seed if you care
|
||||
* about strength.
|
||||
*/
|
||||
XXH_FORCE_INLINE xxh_u64 XXH3_mix16B(const xxh_u8* XXH_RESTRICT input,
|
||||
const xxh_u8* XXH_RESTRICT secret, xxh_u64 seed64)
|
||||
@ -815,19 +822,20 @@ typedef enum { XXH3_acc_64bits, XXH3_acc_128bits } XXH3_accWidth_e;
|
||||
*
|
||||
* It is a hardened version of UMAC, based off of FARSH's implementation.
|
||||
*
|
||||
* This was chosen because it adapts quite well to 32-bit, 64-bit, and SIMD implementations,
|
||||
* and it is ridiculously fast.
|
||||
* This was chosen because it adapts quite well to 32-bit, 64-bit, and SIMD
|
||||
* implementations, and it is ridiculously fast.
|
||||
*
|
||||
* We harden it by mixing the original input to the accumulators as well as the product.
|
||||
*
|
||||
* This means that in the (relatively likely) case of a multiply by zero, the original
|
||||
* input is preserved.
|
||||
* This means that in the (relatively likely) case of a multiply by zero, the
|
||||
* original input is preserved.
|
||||
*
|
||||
* On 128-bit inputs, we swap 64-bit pairs when we add the input to improve cross
|
||||
* pollination, as otherwise the upper and lower halves would be essentially independent.
|
||||
* On 128-bit inputs, we swap 64-bit pairs when we add the input to improve
|
||||
* cross-pollination, as otherwise the upper and lower halves would be
|
||||
* essentially independent.
|
||||
*
|
||||
* This doesn't matter on 64-bit hashes since they all get merged together in the end,
|
||||
* so we skip the extra step.
|
||||
* This doesn't matter on 64-bit hashes since they all get merged together in
|
||||
* the end, so we skip the extra step.
|
||||
*
|
||||
* Both XXH3_64bits and XXH3_128bits use this subroutine.
|
||||
*/
|
||||
@ -841,11 +849,11 @@ XXH3_accumulate_512( void* XXH_RESTRICT acc,
|
||||
|
||||
XXH_ASSERT((((size_t)acc) & 31) == 0);
|
||||
{ XXH_ALIGN(32) __m256i* const xacc = (__m256i *) acc;
|
||||
/* Unaligned. This is mainly for pointer arithmetic, and because _mm256_loadu_si256 requires
|
||||
* a const __m256i * pointer for some reason. */
|
||||
/* Unaligned. This is mainly for pointer arithmetic, and because
|
||||
* _mm256_loadu_si256 requires a const __m256i * pointer for some reason. */
|
||||
const __m256i* const xinput = (const __m256i *) input;
|
||||
/* Unaligned. This is mainly for pointer arithmetic, and because _mm256_loadu_si256 requires
|
||||
* a const __m256i * pointer for some reason. */
|
||||
/* Unaligned. This is mainly for pointer arithmetic, and because
|
||||
* _mm256_loadu_si256 requires a const __m256i * pointer for some reason. */
|
||||
const __m256i* const xsecret = (const __m256i *) secret;
|
||||
|
||||
size_t i;
|
||||
@ -879,11 +887,11 @@ XXH3_accumulate_512( void* XXH_RESTRICT acc,
|
||||
/* SSE2 is just a half-scale version of the AVX2 version. */
|
||||
XXH_ASSERT((((size_t)acc) & 15) == 0);
|
||||
{ XXH_ALIGN(16) __m128i* const xacc = (__m128i *) acc;
|
||||
/* Unaligned. This is mainly for pointer arithmetic, and because _mm_loadu_si128 requires
|
||||
* a const __m128i * pointer for some reason. */
|
||||
/* Unaligned. This is mainly for pointer arithmetic, and because
|
||||
* _mm_loadu_si128 requires a const __m128i * pointer for some reason. */
|
||||
const __m128i* const xinput = (const __m128i *) input;
|
||||
/* Unaligned. This is mainly for pointer arithmetic, and because _mm_loadu_si128 requires
|
||||
* a const __m128i * pointer for some reason. */
|
||||
/* Unaligned. This is mainly for pointer arithmetic, and because
|
||||
* _mm_loadu_si128 requires a const __m128i * pointer for some reason. */
|
||||
const __m128i* const xsecret = (const __m128i *) secret;
|
||||
|
||||
size_t i;
|
||||
@ -982,7 +990,7 @@ XXH3_accumulate_512( void* XXH_RESTRICT acc,
|
||||
|
||||
#else /* scalar variant of Accumulator - universal */
|
||||
|
||||
XXH_ALIGN(XXH_ACC_ALIGN) xxh_u64* const xacc = (xxh_u64*) acc; /* presumed aligned on 32-bytes boundaries, little hint for the auto-vectorizer */
|
||||
XXH_ALIGN(XXH_ACC_ALIGN) xxh_u64* const xacc = (xxh_u64*) acc; /* presumed aligned */
|
||||
const xxh_u8* const xinput = (const xxh_u8*) input; /* no alignment restriction */
|
||||
const xxh_u8* const xsecret = (const xxh_u8*) secret; /* no alignment restriction */
|
||||
size_t i;
|
||||
@ -1011,12 +1019,13 @@ XXH3_accumulate_512( void* XXH_RESTRICT acc,
|
||||
* // 3 4 2 5 1 6 0 7 have quality 228 224 164 160 100 96 36 32.
|
||||
* // As expected, the upper and lower bytes are much worse.
|
||||
*
|
||||
* Source; https://github.com/google/highwayhash/blob/0aaf66b/highwayhash/hh_avx2.h#L291
|
||||
* Source: https://github.com/google/highwayhash/blob/0aaf66b/highwayhash/hh_avx2.h#L291
|
||||
*
|
||||
* Since our algorithm uses a pseudorandom secret to add some variance into the mix, we don't
|
||||
* need to (or want to) mix as often or as much as HighwayHash does.
|
||||
* Since our algorithm uses a pseudorandom secret to add some variance into the
|
||||
* mix, we don't need to (or want to) mix as often or as much as HighwayHash does.
|
||||
*
|
||||
* This isn't as tight as XXH3_accumulate, but still written in SIMD to avoid extraction.
|
||||
* This isn't as tight as XXH3_accumulate, but still written in SIMD to avoid
|
||||
* extraction.
|
||||
*
|
||||
* Both XXH3_64bits and XXH3_128bits use this subroutine.
|
||||
*/
|
||||
@ -1027,8 +1036,8 @@ XXH3_scrambleAcc(void* XXH_RESTRICT acc, const void* XXH_RESTRICT secret)
|
||||
|
||||
XXH_ASSERT((((size_t)acc) & 31) == 0);
|
||||
{ XXH_ALIGN(32) __m256i* const xacc = (__m256i*) acc;
|
||||
/* Unaligned. This is mainly for pointer arithmetic, and because _mm256_loadu_si256 requires
|
||||
* a const __m256i * pointer for some reason. */
|
||||
/* Unaligned. This is mainly for pointer arithmetic, and because
|
||||
* _mm256_loadu_si256 requires a const __m256i * pointer for some reason. */
|
||||
const __m256i* const xsecret = (const __m256i *) secret;
|
||||
const __m256i prime32 = _mm256_set1_epi32((int)PRIME32_1);
|
||||
|
||||
@ -1054,8 +1063,8 @@ XXH3_scrambleAcc(void* XXH_RESTRICT acc, const void* XXH_RESTRICT secret)
|
||||
|
||||
XXH_ASSERT((((size_t)acc) & 15) == 0);
|
||||
{ XXH_ALIGN(16) __m128i* const xacc = (__m128i*) acc;
|
||||
/* Unaligned. This is mainly for pointer arithmetic, and because _mm_loadu_si128 requires
|
||||
* a const __m128i * pointer for some reason. */
|
||||
/* Unaligned. This is mainly for pointer arithmetic, and because
|
||||
* _mm_loadu_si128 requires a const __m128i * pointer for some reason. */
|
||||
const __m128i* const xsecret = (const __m128i *) secret;
|
||||
const __m128i prime32 = _mm_set1_epi32((int)PRIME32_1);
|
||||
|
||||
@ -1102,20 +1111,24 @@ XXH3_scrambleAcc(void* XXH_RESTRICT acc, const void* XXH_RESTRICT secret)
|
||||
* data_key_hi = (uint32x2_t) (xacc[i] >> 32);
|
||||
* xacc[i] = UNDEFINED; */
|
||||
XXH_SPLIT_IN_PLACE(data_key, data_key_lo, data_key_hi);
|
||||
{ /* prod_hi = (data_key >> 32) * PRIME32_1;
|
||||
* Avoid vmul_u32 + vshll_n_u32 since Clang 6 and 7
|
||||
* will incorrectly "optimize" this:
|
||||
{ /*
|
||||
* prod_hi = (data_key >> 32) * PRIME32_1;
|
||||
*
|
||||
* Avoid vmul_u32 + vshll_n_u32 since Clang 6 and 7 will
|
||||
* incorrectly "optimize" this:
|
||||
* tmp = vmul_u32(vmovn_u64(a), vmovn_u64(b));
|
||||
* shifted = vshll_n_u32(tmp, 32);
|
||||
* to this:
|
||||
* tmp = "vmulq_u64"(a, b); // no such thing!
|
||||
* shifted = vshlq_n_u64(tmp, 32);
|
||||
*
|
||||
* However, unlike SSE, Clang lacks a 64-bit multiply routine
|
||||
* for NEON, and it scalarizes two 64-bit multiplies instead.
|
||||
*
|
||||
* vmull_u32 has the same timing as vmul_u32, and it avoids
|
||||
* this bug completely.
|
||||
* See https://bugs.llvm.org/show_bug.cgi?id=39967 */
|
||||
* See https://bugs.llvm.org/show_bug.cgi?id=39967
|
||||
*/
|
||||
uint64x2_t prod_hi = vmull_u32 (data_key_hi, prime);
|
||||
/* xacc[i] = prod_hi << 32; */
|
||||
xacc[i] = vshlq_n_u64(prod_hi, 32);
|
||||
@ -1154,7 +1167,7 @@ XXH3_scrambleAcc(void* XXH_RESTRICT acc, const void* XXH_RESTRICT secret)
|
||||
|
||||
#else /* scalar variant of Scrambler - universal */
|
||||
|
||||
XXH_ALIGN(XXH_ACC_ALIGN) xxh_u64* const xacc = (xxh_u64*) acc; /* presumed aligned on 32-bytes boundaries, little hint for the auto-vectorizer */
|
||||
XXH_ALIGN(XXH_ACC_ALIGN) xxh_u64* const xacc = (xxh_u64*) acc; /* presumed aligned */
|
||||
const xxh_u8* const xsecret = (const xxh_u8*) secret; /* no alignment restriction */
|
||||
size_t i;
|
||||
XXH_ASSERT((((size_t)acc) & (XXH_ACC_ALIGN-1)) == 0);
|
||||
@ -1229,7 +1242,8 @@ XXH3_hashLong_internal_loop( xxh_u64* XXH_RESTRICT acc,
|
||||
/* last stripe */
|
||||
if (len & (STRIPE_LEN - 1)) {
|
||||
const xxh_u8* const p = input + len - STRIPE_LEN;
|
||||
#define XXH_SECRET_LASTACC_START 7 /* do not align on 8, so that secret is different from scrambler */
|
||||
/* Do not align on 8, so that the secret is different from the scrambler */
|
||||
#define XXH_SECRET_LASTACC_START 7
|
||||
XXH3_accumulate_512(acc, p, secret + secretSize - STRIPE_LEN - XXH_SECRET_LASTACC_START, accWidth);
|
||||
} }
|
||||
}
|
||||
@ -1268,19 +1282,27 @@ XXH3_hashLong_internal(const xxh_u8* XXH_RESTRICT input, size_t len,
|
||||
|
||||
/* converge into final hash */
|
||||
XXH_STATIC_ASSERT(sizeof(acc) == 64);
|
||||
#define XXH_SECRET_MERGEACCS_START 11 /* do not align on 8, so that secret is different from accumulator */
|
||||
/* do not align on 8, so that the secret is different from the accumulator */
|
||||
#define XXH_SECRET_MERGEACCS_START 11
|
||||
XXH_ASSERT(secretSize >= sizeof(acc) + XXH_SECRET_MERGEACCS_START);
|
||||
return XXH3_mergeAccs(acc, secret + XXH_SECRET_MERGEACCS_START, (xxh_u64)len * PRIME64_1);
|
||||
}
|
||||
|
||||
|
||||
XXH_NO_INLINE XXH64_hash_t /* It's important for performance that XXH3_hashLong is not inlined. Not sure why (uop cache maybe ?), but difference is large and easily measurable */
|
||||
/*
|
||||
* It's important for performance that XXH3_hashLong is not inlined. Not sure
|
||||
* why (uop cache maybe?), but the difference is large and easily measurable.
|
||||
*/
|
||||
XXH_NO_INLINE XXH64_hash_t
|
||||
XXH3_hashLong_64b_defaultSecret(const xxh_u8* XXH_RESTRICT input, size_t len)
|
||||
{
|
||||
return XXH3_hashLong_internal(input, len, kSecret, sizeof(kSecret));
|
||||
}
|
||||
|
||||
XXH_NO_INLINE XXH64_hash_t /* It's important for performance that XXH3_hashLong is not inlined. Not sure why (uop cache maybe ?), but difference is large and easily measurable */
|
||||
/*
|
||||
* It's important for performance that XXH3_hashLong is not inlined. Not sure
|
||||
* why (uop cache maybe?), but the difference is large and easily measurable.
|
||||
*/
|
||||
XXH_NO_INLINE XXH64_hash_t
|
||||
XXH3_hashLong_64b_withSecret(const xxh_u8* XXH_RESTRICT input, size_t len,
|
||||
const xxh_u8* XXH_RESTRICT secret, size_t secretSize)
|
||||
{
|
||||
@ -1311,14 +1333,18 @@ XXH_FORCE_INLINE void XXH3_initCustomSecret(xxh_u8* customSecret, xxh_u64 seed64
|
||||
}
|
||||
|
||||
|
||||
/* XXH3_hashLong_64b_withSeed() :
|
||||
* Generate a custom key,
|
||||
* based on alteration of default kSecret with the seed,
|
||||
/*
|
||||
* XXH3_hashLong_64b_withSeed():
|
||||
* Generate a custom key based on alteration of default kSecret with the seed,
|
||||
* and then use this key for long mode hashing.
|
||||
*
|
||||
* This operation is decently fast but nonetheless costs a little bit of time.
|
||||
* Try to avoid it whenever possible (typically when seed==0).
|
||||
*
|
||||
* It's important for performance that XXH3_hashLong is not inlined. Not sure
|
||||
* why (uop cache maybe?), but the difference is large and easily measurable.
|
||||
*/
|
||||
XXH_NO_INLINE XXH64_hash_t /* It's important for performance that XXH3_hashLong is not inlined. Not sure why (uop cache maybe ?), but difference is large and easily measurable */
|
||||
XXH_NO_INLINE XXH64_hash_t
|
||||
XXH3_hashLong_64b_withSeed(const xxh_u8* input, size_t len, XXH64_hash_t seed)
|
||||
{
|
||||
XXH_ALIGN(8) xxh_u8 secret[XXH_SECRET_DEFAULT_SIZE];
|
||||
@ -1341,14 +1367,16 @@ XXH_PUBLIC_API XXH64_hash_t
|
||||
XXH3_64bits_withSecret(const void* input, size_t len, const void* secret, size_t secretSize)
|
||||
{
|
||||
XXH_ASSERT(secretSize >= XXH3_SECRET_SIZE_MIN);
|
||||
/* if an action must be taken should `secret` conditions not be respected,
|
||||
/*
|
||||
* If an action is to be taken if `secret` conditions are not respected,
|
||||
* it should be done here.
|
||||
* For now, it's a contract pre-condition.
|
||||
* Adding a check and a branch here would cost performance at every hash */
|
||||
if (len <= 16) return XXH3_len_0to16_64b((const xxh_u8*)input, len, (const xxh_u8*)secret, 0);
|
||||
if (len <= 128) return XXH3_len_17to128_64b((const xxh_u8*)input, len, (const xxh_u8*)secret, secretSize, 0);
|
||||
if (len <= XXH3_MIDSIZE_MAX) return XXH3_len_129to240_64b((const xxh_u8*)input, len, (const xxh_u8*)secret, secretSize, 0);
|
||||
return XXH3_hashLong_64b_withSecret((const xxh_u8*)input, len, (const xxh_u8*)secret, secretSize);
|
||||
* Adding a check and a branch here would cost performance at every hash.
|
||||
*/
|
||||
if (len <= 16) return XXH3_len_0to16_64b((const xxh_u8*)input, len, (const xxh_u8*)secret, 0);
|
||||
if (len <= 128) return XXH3_len_17to128_64b((const xxh_u8*)input, len, (const xxh_u8*)secret, secretSize, 0);
|
||||
if (len <= XXH3_MIDSIZE_MAX) return XXH3_len_129to240_64b((const xxh_u8*)input, len, (const xxh_u8*)secret, secretSize, 0);
|
||||
return XXH3_hashLong_64b_withSecret((const xxh_u8*)input, len, (const xxh_u8*)secret, secretSize);
|
||||
}
|
||||
|
||||
XXH_PUBLIC_API XXH64_hash_t
|
||||
@ -1473,12 +1501,16 @@ XXH3_update(XXH3_state_t* state, const xxh_u8* input, size_t len, XXH3_accWidth_
|
||||
state->bufferedSize += (XXH32_hash_t)len;
|
||||
return XXH_OK;
|
||||
}
|
||||
/* input now > XXH3_INTERNALBUFFER_SIZE */
|
||||
/* input is now > XXH3_INTERNALBUFFER_SIZE */
|
||||
|
||||
#define XXH3_INTERNALBUFFER_STRIPES (XXH3_INTERNALBUFFER_SIZE / STRIPE_LEN)
|
||||
XXH_STATIC_ASSERT(XXH3_INTERNALBUFFER_SIZE % STRIPE_LEN == 0); /* clean multiple */
|
||||
|
||||
if (state->bufferedSize) { /* some input within internal buffer: fill then consume it */
|
||||
/*
|
||||
* There is some input left inside the internal buffer.
|
||||
* Fill it, then consume it.
|
||||
*/
|
||||
if (state->bufferedSize) {
|
||||
size_t const loadSize = XXH3_INTERNALBUFFER_SIZE - state->bufferedSize;
|
||||
XXH_memcpy(state->buffer + state->bufferedSize, input, loadSize);
|
||||
input += loadSize;
|
||||
@ -1490,7 +1522,7 @@ XXH3_update(XXH3_state_t* state, const xxh_u8* input, size_t len, XXH3_accWidth_
|
||||
state->bufferedSize = 0;
|
||||
}
|
||||
|
||||
/* consume input by full buffer quantities */
|
||||
/* Consume input by full buffer quantities */
|
||||
if (input+XXH3_INTERNALBUFFER_SIZE <= bEnd) {
|
||||
const xxh_u8* const limit = bEnd - XXH3_INTERNALBUFFER_SIZE;
|
||||
do {
|
||||
@ -1503,7 +1535,7 @@ XXH3_update(XXH3_state_t* state, const xxh_u8* input, size_t len, XXH3_accWidth_
|
||||
} while (input<=limit);
|
||||
}
|
||||
|
||||
if (input < bEnd) { /* some remaining input input : buffer it */
|
||||
if (input < bEnd) { /* Some remaining input: buffer it */
|
||||
XXH_memcpy(state->buffer, input, (size_t)(bEnd-input));
|
||||
state->bufferedSize = (XXH32_hash_t)(bEnd-input);
|
||||
}
|
||||
@ -1522,7 +1554,11 @@ XXH3_64bits_update(XXH3_state_t* state, const void* input, size_t len)
|
||||
XXH_FORCE_INLINE void
|
||||
XXH3_digest_long (XXH64_hash_t* acc, const XXH3_state_t* state, XXH3_accWidth_e accWidth)
|
||||
{
|
||||
memcpy(acc, state->acc, sizeof(state->acc)); /* digest locally, state remains unaltered, and can continue ingesting more input afterwards */
|
||||
/*
|
||||
* Digest on a local copy. This way, the state remains unaltered, and it can
|
||||
* continue ingesting more input afterwards.
|
||||
*/
|
||||
memcpy(acc, state->acc, sizeof(state->acc));
|
||||
if (state->bufferedSize >= STRIPE_LEN) {
|
||||
size_t const totalNbStripes = state->bufferedSize / STRIPE_LEN;
|
||||
XXH32_hash_t nbStripesSoFar = state->nbStripesSoFar;
|
||||
@ -1631,8 +1667,8 @@ XXH3_len_9to16_128b(const xxh_u8* input, size_t len, const xxh_u8* secret, XXH64
|
||||
xxh_u64 const input_hi = XXH_readLE64(input + len - 8) ^ bitfliph;
|
||||
XXH128_hash_t m128 = XXH_mult64to128(input_lo ^ input_hi, PRIME64_1);
|
||||
/*
|
||||
* Put len in the middle of m128 to ensure that the length gets mixed to both the low
|
||||
* and high bits in the 128x64 multiply below.
|
||||
* Put len in the middle of m128 to ensure that the length gets mixed to
|
||||
* both the low and high bits in the 128x64 multiply below.
|
||||
*/
|
||||
m128.low64 += (xxh_u64)(len - 1) << 54;
|
||||
/*
|
||||
@ -1802,20 +1838,32 @@ XXH3_hashLong_128b_internal(const xxh_u8* XXH_RESTRICT input, size_t len,
|
||||
}
|
||||
}
|
||||
|
||||
XXH_NO_INLINE XXH128_hash_t /* It's important for performance that XXH3_hashLong is not inlined. Not sure why (uop cache maybe ?), but difference is large and easily measurable */
|
||||
/*
|
||||
* It's important for performance that XXH3_hashLong is not inlined. Not sure
|
||||
* why (uop cache maybe?), but the difference is large and easily measurable.
|
||||
*/
|
||||
XXH_NO_INLINE XXH128_hash_t
|
||||
XXH3_hashLong_128b_defaultSecret(const xxh_u8* input, size_t len)
|
||||
{
|
||||
return XXH3_hashLong_128b_internal(input, len, kSecret, sizeof(kSecret));
|
||||
}
|
||||
|
||||
XXH_NO_INLINE XXH128_hash_t /* It's important for performance that XXH3_hashLong is not inlined. Not sure why (uop cache maybe ?), but difference is large and easily measurable */
|
||||
/*
|
||||
* It's important for performance that XXH3_hashLong is not inlined. Not sure
|
||||
* why (uop cache maybe?), but the difference is large and easily measurable.
|
||||
*/
|
||||
XXH_NO_INLINE XXH128_hash_t
|
||||
XXH3_hashLong_128b_withSecret(const xxh_u8* input, size_t len,
|
||||
const xxh_u8* secret, size_t secretSize)
|
||||
{
|
||||
return XXH3_hashLong_128b_internal(input, len, secret, secretSize);
|
||||
}
|
||||
|
||||
XXH_NO_INLINE XXH128_hash_t /* It's important for performance that XXH3_hashLong is not inlined. Not sure why (uop cache maybe ?), but difference is large and easily measurable */
|
||||
/*
|
||||
* It's important for performance that XXH3_hashLong is not inlined. Not sure
|
||||
* why (uop cache maybe?), but the difference is large and easily measurable.
|
||||
*/
|
||||
XXH_NO_INLINE XXH128_hash_t
|
||||
XXH3_hashLong_128b_withSeed(const xxh_u8* input, size_t len, XXH64_hash_t seed)
|
||||
{
|
||||
XXH_ALIGN(8) xxh_u8 secret[XXH_SECRET_DEFAULT_SIZE];
|
||||
@ -1837,10 +1885,12 @@ XXH_PUBLIC_API XXH128_hash_t
|
||||
XXH3_128bits_withSecret(const void* input, size_t len, const void* secret, size_t secretSize)
|
||||
{
|
||||
XXH_ASSERT(secretSize >= XXH3_SECRET_SIZE_MIN);
|
||||
/* if an action must be taken should `secret` conditions not be respected,
|
||||
/*
|
||||
* If an action is to be taken if `secret` conditions are not respected,
|
||||
* it should be done here.
|
||||
* For now, it's a contract pre-condition.
|
||||
* Adding a check and a branch here would cost performance at every hash */
|
||||
* Adding a check and a branch here would cost performance at every hash.
|
||||
*/
|
||||
if (len <= 16) return XXH3_len_0to16_128b((const xxh_u8*)input, len, (const xxh_u8*)secret, 0);
|
||||
if (len <= 128) return XXH3_len_17to128_128b((const xxh_u8*)input, len, (const xxh_u8*)secret, secretSize, 0);
|
||||
if (len <= XXH3_MIDSIZE_MAX) return XXH3_len_129to240_128b((const xxh_u8*)input, len, (const xxh_u8*)secret, secretSize, 0);
|
||||
|
||||
511
xxhash.h
511
xxhash.h
@ -28,13 +28,14 @@
|
||||
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
You can contact the author at :
|
||||
- xxHash source repository : https://github.com/Cyan4973/xxHash
|
||||
You can contact the author at:
|
||||
- xxHash source repository: https://github.com/Cyan4973/xxHash
|
||||
*/
|
||||
|
||||
/* Notice extracted from xxHash homepage :
|
||||
/* TODO: update */
|
||||
/* Notice extracted from xxHash homepage:
|
||||
|
||||
xxHash is an extremely fast Hash algorithm, running at RAM speed limits.
|
||||
xxHash is an extremely fast hash algorithm, running at RAM speed limits.
|
||||
It also successfully passes all tests from the SMHasher suite.
|
||||
|
||||
Comparison (single thread, Windows Seven 32 bits, using SMHasher on a Core 2 Duo @3GHz)
|
||||
@ -57,9 +58,9 @@ Q.Score is a measure of quality of the hash function.
|
||||
It depends on successfully passing SMHasher test set.
|
||||
10 is a perfect score.
|
||||
|
||||
Note : SMHasher's CRC32 implementation is not the fastest one.
|
||||
Note: SMHasher's CRC32 implementation is not the fastest one.
|
||||
Other speed-oriented implementations can be faster,
|
||||
especially in combination with PCLMUL instruction :
|
||||
especially in combination with PCLMUL instruction:
|
||||
http://fastcompression.blogspot.com/2019/03/presenting-xxh3.html?showComment=1552696407071#c3490092340461170735
|
||||
|
||||
A 64-bit version, named XXH64, is available since r35.
|
||||
@ -76,22 +77,27 @@ extern "C" {
|
||||
/* ****************************
|
||||
* INLINE mode
|
||||
******************************/
|
||||
/** XXH_INLINE_ALL (and XXH_PRIVATE_API)
|
||||
* Use these build macros to inline xxhash in target unit.
|
||||
* Inlining improves performance on small inputs,
|
||||
* up to dramatic levels when length is expressed as a compile-time constant :
|
||||
* https://fastcompression.blogspot.com/2018/03/xxhash-for-small-keys-impressive-power.html .
|
||||
* It also keeps xxhash symbols private to the unit (they are not published).
|
||||
* Methodology :
|
||||
/*!
|
||||
* XXH_INLINE_ALL (and XXH_PRIVATE_API)
|
||||
* Use these build macros to inline xxhash into the target unit.
|
||||
* Inlining improves performance on small inputs, especially when the length is
|
||||
* expressed as a compile-time constant:
|
||||
*
|
||||
* https://fastcompression.blogspot.com/2018/03/xxhash-for-small-keys-impressive-power.html
|
||||
*
|
||||
* It also keeps xxHash symbols private to the unit, so they are not exported.
|
||||
*
|
||||
* Usage:
|
||||
* #define XXH_INLINE_ALL
|
||||
* #include "xxhash.h"
|
||||
* Do not compile and link xxhash.o as a separate object (not useful)
|
||||
*
|
||||
* Do not compile and link xxhash.o as a separate object, as it is not useful.
|
||||
*/
|
||||
#if (defined(XXH_INLINE_ALL) || defined(XXH_PRIVATE_API)) \
|
||||
&& !defined(XXH_INLINE_ALL_31684351384)
|
||||
/* this section should be traversed only once */
|
||||
# define XXH_INLINE_ALL_31684351384
|
||||
/* give access to advanced API, required to compile implementations */
|
||||
/* give access to the advanced API, required to compile implementations */
|
||||
# undef XXH_STATIC_LINKING_ONLY /* avoid macro redef */
|
||||
# define XXH_STATIC_LINKING_ONLY
|
||||
/* make all functions private */
|
||||
@ -103,29 +109,34 @@ extern "C" {
|
||||
# elif defined(_MSC_VER)
|
||||
# define XXH_PUBLIC_API static __inline
|
||||
# else
|
||||
/* note : this version may generate warnings for unused static functions */
|
||||
/* note: this version may generate warnings for unused static functions */
|
||||
# define XXH_PUBLIC_API static
|
||||
# endif
|
||||
|
||||
/* This part deals with the special case where a unit wants to inline xxhash,
|
||||
* but "xxhash.h" has previously been included without XXH_INLINE_ALL,
|
||||
* for example as part of some previously included *.h header file.
|
||||
/*
|
||||
* This part deals with the special case where a unit wants to inline xxHash,
|
||||
* but "xxhash.h" has previously been included without XXH_INLINE_ALL, such
|
||||
* as part of some previously included *.h header file.
|
||||
* Without further action, the new include would just be ignored,
|
||||
* and functions would effectively _not_ be inlined (silent failure).
|
||||
* The following macros solve this situation by prefixing all inlined names,
|
||||
* avoiding naming collision with previous include. */
|
||||
* avoiding naming collision with previous inclusions.
|
||||
*/
|
||||
# ifdef XXH_NAMESPACE
|
||||
# error "XXH_INLINE_ALL with XXH_NAMESPACE is not supported"
|
||||
# /* Note : Alternative : #undef all symbols (it's a pretty large list).
|
||||
* Without #error : it compiles, but functions are actually Not inlined.
|
||||
* */
|
||||
/*
|
||||
* Note: Alternative: #undef all symbols (it's a pretty large list).
|
||||
* Without #error: it compiles, but functions are actually not inlined.
|
||||
*/
|
||||
# endif
|
||||
# define XXH_NAMESPACE XXH_INLINE_
|
||||
/* some identifiers (enums, type names) are not symbols,
|
||||
* they must nonetheless be renamed to avoid double declaration/
|
||||
* Alternative solution : do not redeclare them,
|
||||
* However, this requires some #ifdef, and is more dispersed action
|
||||
* while renaming can be achieved in a single place */
|
||||
/*
|
||||
* Some identifiers (enums, type names) are not symbols, but they must
|
||||
* still be renamed to avoid redeclaration.
|
||||
* Alternative solution: do not redeclare them.
|
||||
* However, this requires some #ifdefs, and is a more dispersed action.
|
||||
* Meanwhile, renaming can be achieved in a single block
|
||||
*/
|
||||
# define XXH_IPREF(Id) XXH_INLINE_ ## Id
|
||||
# define XXH_OK XXH_IPREF(XXH_OK)
|
||||
# define XXH_ERROR XXH_IPREF(XXH_ERROR)
|
||||
@ -140,7 +151,7 @@ extern "C" {
|
||||
# define XXH3_state_s XXH_IPREF(XXH3_state_s)
|
||||
# define XXH3_state_t XXH_IPREF(XXH3_state_t)
|
||||
# define XXH128_hash_t XXH_IPREF(XXH128_hash_t)
|
||||
/* Ensure header is parsed again, even if it was previously included */
|
||||
/* Ensure the header is parsed again, even if it was previously included */
|
||||
# undef XXHASH_H_5627135585666179
|
||||
# undef XXHASH_H_STATIC_13879238742
|
||||
#endif /* XXH_INLINE_ALL || XXH_PRIVATE_API */
|
||||
@ -166,16 +177,18 @@ extern "C" {
|
||||
# endif
|
||||
#endif
|
||||
|
||||
/*! XXH_NAMESPACE, aka Namespace Emulation :
|
||||
/*!
|
||||
* XXH_NAMESPACE, aka Namespace Emulation:
|
||||
*
|
||||
* If you want to include _and expose_ xxHash functions from within your own library,
|
||||
* but also want to avoid symbol collisions with other libraries which may also include xxHash,
|
||||
* If you want to include _and expose_ xxHash functions from within your own
|
||||
* library, but also want to avoid symbol collisions with other libraries which
|
||||
* may also include xxHash, you can use XXH_NAMESPACE to automatically prefix
|
||||
* any public symbol from xxhash library with the value of XXH_NAMESPACE
|
||||
* (therefore, avoid empty or numeric values).
|
||||
*
|
||||
* you can use XXH_NAMESPACE, to automatically prefix any public symbol from xxhash library
|
||||
* with the value of XXH_NAMESPACE (therefore, avoid NULL and numeric values).
|
||||
*
|
||||
* Note that no change is required within the calling program as long as it includes `xxhash.h` :
|
||||
* regular symbol name will be automatically translated by this header.
|
||||
* Note that no change is required within the calling program as long as it
|
||||
* includes `xxhash.h`: Regular symbol names will be automatically translated
|
||||
* by this header.
|
||||
*/
|
||||
#ifdef XXH_NAMESPACE
|
||||
# define XXH_CAT(A,B) A##B
|
||||
@ -240,11 +253,13 @@ typedef enum { XXH_OK=0, XXH_ERROR } XXH_errorcode;
|
||||
# endif
|
||||
#endif
|
||||
|
||||
/*! XXH32() :
|
||||
Calculate the 32-bit hash of sequence "length" bytes stored at memory address "input".
|
||||
The memory between input & input+length must be valid (allocated and read-accessible).
|
||||
"seed" can be used to alter the result predictably.
|
||||
Speed on Core 2 Duo @ 3 GHz (single thread, SMHasher benchmark) : 5.4 GB/s */
|
||||
/*!
|
||||
* XXH32():
|
||||
* Calculate the 32-bit hash of sequence "length" bytes stored at memory address "input".
|
||||
* The memory between input & input+length must be valid (allocated and read-accessible).
|
||||
* "seed" can be used to alter the result predictably.
|
||||
* Speed on Core 2 Duo @ 3 GHz (single thread, SMHasher benchmark) : 5.4 GB/s
|
||||
*/
|
||||
XXH_PUBLIC_API XXH32_hash_t XXH32 (const void* input, size_t length, XXH32_hash_t seed);
|
||||
|
||||
/******* Streaming *******/
|
||||
@ -254,20 +269,22 @@ XXH_PUBLIC_API XXH32_hash_t XXH32 (const void* input, size_t length, XXH32_hash_
|
||||
* This method is slower than single-call functions, due to state management.
|
||||
* For small inputs, prefer `XXH32()` and `XXH64()`, which are better optimized.
|
||||
*
|
||||
* XXH state must first be allocated, using XXH*_createState() .
|
||||
* An XXH state must first be allocated using `XXH*_createState()`.
|
||||
*
|
||||
* Start a new hash by initializing state with a seed, using XXH*_reset().
|
||||
* Start a new hash by initializing the state with a seed using `XXH*_reset()`.
|
||||
*
|
||||
* Then, feed the hash state by calling XXH*_update() as many times as necessary.
|
||||
* The function returns an error code, with 0 meaning OK, and any other value meaning there is an error.
|
||||
* Then, feed the hash state by calling `XXH*_update()` as many times as necessary.
|
||||
*
|
||||
* Finally, a hash value can be produced anytime, by using XXH*_digest().
|
||||
* The function returns an error code, with 0 meaning OK, and any other value
|
||||
* meaning there is an error.
|
||||
*
|
||||
* Finally, a hash value can be produced anytime, by using `XXH*_digest()`.
|
||||
* This function returns the nn-bits hash as an int or long long.
|
||||
*
|
||||
* It's still possible to continue inserting input into the hash state after a digest,
|
||||
* and generate some new hash values later on, by invoking again XXH*_digest().
|
||||
* It's still possible to continue inserting input into the hash state after a
|
||||
* digest, and generate new hash values later on by invoking `XXH*_digest()`.
|
||||
*
|
||||
* When done, release the state, using XXH*_freeState().
|
||||
* When done, release the state using `XXH*_freeState()`.
|
||||
*/
|
||||
|
||||
typedef struct XXH32_state_s XXH32_state_t; /* incomplete type */
|
||||
@ -281,19 +298,23 @@ XXH_PUBLIC_API XXH32_hash_t XXH32_digest (const XXH32_state_t* statePtr);
|
||||
|
||||
/******* Canonical representation *******/
|
||||
|
||||
/* Default return values from XXH functions are basic unsigned 32 and 64 bits.
|
||||
/*
|
||||
* The default return values from XXH functions are unsigned 32 and 64 bit
|
||||
* integers.
|
||||
* This the simplest and fastest format for further post-processing.
|
||||
* However, this leaves open the question of what is the order of bytes,
|
||||
* since little and big endian conventions will write the same number differently.
|
||||
*
|
||||
* The canonical representation settles this issue,
|
||||
* by mandating big-endian convention,
|
||||
* aka, the same convention as human-readable numbers (large digits first).
|
||||
* When writing hash values to storage, sending them over a network, or printing them,
|
||||
* it's highly recommended to use the canonical representation,
|
||||
* to ensure portability across a wider range of systems, present and future.
|
||||
* However, this leaves open the question of what is the order on the byte level,
|
||||
* since little and big endian conventions will store the same number differently.
|
||||
*
|
||||
* The following functions allow transformation of hash values into and from canonical format.
|
||||
* The canonical representation settles this issue by mandating big-endian
|
||||
* convention, the same convention as human-readable numbers (large digits first).
|
||||
*
|
||||
* When writing hash values to storage, sending them over a network, or printing
|
||||
* them, it's highly recommended to use the canonical representation to ensure
|
||||
* portability across a wider range of systems, present and future.
|
||||
*
|
||||
* The following functions allow transformation of hash values into and from
|
||||
* canonical format.
|
||||
*/
|
||||
|
||||
typedef struct { unsigned char digest[4]; } XXH32_canonical_t;
|
||||
@ -315,10 +336,13 @@ XXH_PUBLIC_API XXH32_hash_t XXH32_hashFromCanonical(const XXH32_canonical_t* src
|
||||
typedef unsigned long long XXH64_hash_t;
|
||||
#endif
|
||||
|
||||
/*! XXH64() :
|
||||
* Returns the 64-bit hash of sequence of length @length stored at memory address @input.
|
||||
* @seed can be used to alter the result predictably.
|
||||
* This function runs faster on 64-bit systems, but slower on 32-bit systems (see benchmark).
|
||||
/*!
|
||||
* XXH64():
|
||||
* Returns the 64-bit hash of sequence of length @length stored at memory
|
||||
* address @input.
|
||||
* @seed can be used to alter the result predictably.
|
||||
* This function usually runs faster on 64-bit systems, but slower on 32-bit
|
||||
* systems (see benchmark).
|
||||
*/
|
||||
XXH_PUBLIC_API XXH64_hash_t XXH64 (const void* input, size_t length, XXH64_hash_t seed);
|
||||
|
||||
@ -346,12 +370,13 @@ XXH_PUBLIC_API XXH64_hash_t XXH64_hashFromCanonical(const XXH64_canonical_t* src
|
||||
|
||||
#if defined(XXH_STATIC_LINKING_ONLY) && !defined(XXHASH_H_STATIC_13879238742)
|
||||
#define XXHASH_H_STATIC_13879238742
|
||||
/* ************************************************************************************************
|
||||
This section contains declarations which are not guaranteed to remain stable.
|
||||
They may change in future versions, becoming incompatible with a different version of the library.
|
||||
These declarations should only be used with static linking.
|
||||
Never use them in association with dynamic linking !
|
||||
*************************************************************************************************** */
|
||||
/* ****************************************************************************
|
||||
* This section contains declarations which are not guaranteed to remain stable.
|
||||
* They may change in future versions, becoming incompatible with a different
|
||||
* version of the library.
|
||||
* These declarations should only be used with static linking.
|
||||
* Never use them in association with dynamic linking!
|
||||
***************************************************************************** */
|
||||
|
||||
/* These definitions are only present to allow
|
||||
* static allocation of XXH state, on stack or in a struct for example.
|
||||
@ -390,28 +415,49 @@ struct XXH64_state_s {
|
||||
* New experimental hash
|
||||
************************************************************************/
|
||||
|
||||
/* *********************************************
|
||||
* XXH3 is a new hash algorithm,
|
||||
* featuring improved speed for both small and large inputs.
|
||||
* Speed analysis methodology is explained at :
|
||||
* http://fastcompression.blogspot.com/2019/03/presenting-xxh3.html
|
||||
* In general, expect XXH3 to run about ~2x faster on large inputs,
|
||||
* and >3x faster on small ones, though exact differences depend on platform.
|
||||
/* ************************************************************************
|
||||
* XXH3 is a new hash algorithm featuring:
|
||||
* - Improved speed for both small and large inputs
|
||||
* - True 64-bit and 128-bit outputs
|
||||
* - SIMD acceleration
|
||||
* - Improved 32-bit viability
|
||||
*
|
||||
* The algorithm is portable, it generates the same hash on all platforms.
|
||||
* It benefits greatly from vectorization units, but does not require it.
|
||||
* Speed analysis methodology is explained here:
|
||||
*
|
||||
* http://fastcompression.blogspot.com/2019/03/presenting-xxh3.html
|
||||
*
|
||||
* In general, expect XXH3 to run about ~2x faster on large inputs and >3x
|
||||
* faster on small ones compared to XXH64, though exact differences depend on
|
||||
* the platform.
|
||||
*
|
||||
* The algorithm is portable: Like XXH32 and XXH64, it generates the same hash
|
||||
* on all platforms.
|
||||
*
|
||||
* It benefits greatly from SIMD and 64-bit arithmetic, but does not require it.
|
||||
*
|
||||
* Almost all 32-bit and 64-bit targets that can run XXH32 smoothly can run
|
||||
* XXH3 at usable speeds, even if XXH64 runs slowly. Further details are
|
||||
* explained in the implementation.
|
||||
*
|
||||
* Optimized implementations are provided for AVX2, SSE2, NEON, POWER8, ZVector,
|
||||
* and scalar targets. This can be controlled with the XXH_VECTOR macro.
|
||||
*
|
||||
* XXH3 offers 2 variants, _64bits and _128bits.
|
||||
* When only 64 bits are needed, prefer calling the _64bits variant :
|
||||
* it reduces the amount of mixing, resulting in faster speed on small inputs.
|
||||
* When only 64 bits are needed, prefer calling the _64bits variant, as it
|
||||
* reduces the amount of mixing, resulting in faster speed on small inputs.
|
||||
*
|
||||
* It's also generally simpler to manipulate a scalar return type than a struct.
|
||||
*
|
||||
* The 128-bit version adds additional strength, but it is slightly slower.
|
||||
*
|
||||
* The XXH3 algorithm is still in development.
|
||||
* The results it produces may still change in future versions.
|
||||
* Results produced by v0.7.x are not comparable with results from v0.7.y .
|
||||
* However, the implementation is completely stable,
|
||||
* and can be used for ephemeral data (local sessions).
|
||||
* Avoid storing values in long-term storage for future consultations.
|
||||
*
|
||||
* Results produced by v0.7.x are not comparable with results from v0.7.y.
|
||||
* However, the API is completely stable, and it can safely be used for
|
||||
* ephemeral data (local sessions).
|
||||
*
|
||||
* Avoid storing values in long-term storage until the algorithm is finalized.
|
||||
*
|
||||
* The API supports one-shot hashing, streaming mode, and custom secrets.
|
||||
*/
|
||||
@ -437,23 +483,27 @@ struct XXH64_state_s {
|
||||
* It's the fastest variant. */
|
||||
XXH_PUBLIC_API XXH64_hash_t XXH3_64bits(const void* data, size_t len);
|
||||
|
||||
/* XXH3_64bits_withSecret() :
|
||||
/*
|
||||
* XXH3_64bits_withSecret():
|
||||
* It's possible to provide any blob of bytes as a "secret" to generate the hash.
|
||||
* This makes it more difficult for an external actor to prepare an intentional collision.
|
||||
* This makes it more difficult for an external actor to prepare an intentional
|
||||
* collision.
|
||||
* The secret *must* be large enough (>= XXH3_SECRET_SIZE_MIN).
|
||||
* It should consist of random bytes.
|
||||
* Avoid trivial sequences, such as repeating same character, or same number,
|
||||
* and especially avoid swathes of \0.
|
||||
* Avoid trivial sequences, such as repeating sequences and especially '\0',
|
||||
* as this can cancel out itself.
|
||||
* Failure to respect these conditions will result in a poor quality hash.
|
||||
*/
|
||||
#define XXH3_SECRET_SIZE_MIN 136
|
||||
XXH_PUBLIC_API XXH64_hash_t XXH3_64bits_withSecret(const void* data, size_t len, const void* secret, size_t secretSize);
|
||||
|
||||
/* XXH3_64bits_withSeed() :
|
||||
* This variant generates on the fly a custom secret,
|
||||
* based on the default secret, altered using the `seed` value.
|
||||
/*
|
||||
* XXH3_64bits_withSeed():
|
||||
* This variant generates a custom secret on the fly based on the default
|
||||
* secret, altered using the `seed` value.
|
||||
* While this operation is decently fast, note that it's not completely free.
|
||||
* note : seed==0 produces same results as XXH3_64bits() */
|
||||
* Note: seed==0 produces the same results as XXH3_64bits().
|
||||
*/
|
||||
XXH_PUBLIC_API XXH64_hash_t XXH3_64bits_withSeed(const void* data, size_t len, XXH64_hash_t seed);
|
||||
|
||||
|
||||
@ -484,7 +534,9 @@ typedef struct XXH3_state_s XXH3_state_t;
|
||||
#define XXH3_INTERNALBUFFER_SIZE 256
|
||||
struct XXH3_state_s {
|
||||
XXH_ALIGN_MEMBER(64, XXH64_hash_t acc[8]);
|
||||
XXH_ALIGN_MEMBER(64, unsigned char customSecret[XXH3_SECRET_DEFAULT_SIZE]); /* used to store a custom secret generated from the seed. Makes state larger. Design might change */
|
||||
/* used to store a custom secret generated from the seed. Makes state larger.
|
||||
* Design might change */
|
||||
XXH_ALIGN_MEMBER(64, unsigned char customSecret[XXH3_SECRET_DEFAULT_SIZE]);
|
||||
XXH_ALIGN_MEMBER(64, unsigned char buffer[XXH3_INTERNALBUFFER_SIZE]);
|
||||
XXH32_hash_t bufferedSize;
|
||||
XXH32_hash_t nbStripesPerBlock;
|
||||
@ -495,32 +547,41 @@ struct XXH3_state_s {
|
||||
XXH64_hash_t totalLen;
|
||||
XXH64_hash_t seed;
|
||||
XXH64_hash_t reserved64;
|
||||
const unsigned char* secret; /* note : there is some padding after, due to alignment on 64 bytes */
|
||||
/* note: there is some padding after due to alignment on 64 bytes */
|
||||
const unsigned char* secret;
|
||||
}; /* typedef'd to XXH3_state_t */
|
||||
|
||||
#undef XXH_ALIGN_MEMBER
|
||||
|
||||
/* Streaming requires state maintenance.
|
||||
* This operation costs memory and cpu.
|
||||
/*
|
||||
* Streaming requires state maintenance.
|
||||
* This operation costs memory and CPU.
|
||||
* As a consequence, streaming is slower than one-shot hashing.
|
||||
* For better performance, prefer one-shot functions whenever possible. */
|
||||
* For better performance, prefer one-shot functions whenever possible.
|
||||
*/
|
||||
|
||||
XXH_PUBLIC_API XXH3_state_t* XXH3_createState(void);
|
||||
XXH_PUBLIC_API XXH_errorcode XXH3_freeState(XXH3_state_t* statePtr);
|
||||
XXH_PUBLIC_API void XXH3_copyState(XXH3_state_t* dst_state, const XXH3_state_t* src_state);
|
||||
|
||||
|
||||
/* XXH3_64bits_reset() :
|
||||
* initialize with default parameters.
|
||||
* result will be equivalent to `XXH3_64bits()`. */
|
||||
/*
|
||||
* XXH3_64bits_reset():
|
||||
* Initialize with the default parameters.
|
||||
* The result will be equivalent to `XXH3_64bits()`.
|
||||
*/
|
||||
XXH_PUBLIC_API XXH_errorcode XXH3_64bits_reset(XXH3_state_t* statePtr);
|
||||
/* XXH3_64bits_reset_withSeed() :
|
||||
* generate a custom secret from `seed`, and store it into state.
|
||||
* digest will be equivalent to `XXH3_64bits_withSeed()`. */
|
||||
/*
|
||||
* XXH3_64bits_reset_withSeed():
|
||||
* Generate a custom secret from `seed`, and store it into `statePtr`.
|
||||
* digest will be equivalent to `XXH3_64bits_withSeed()`.
|
||||
*/
|
||||
XXH_PUBLIC_API XXH_errorcode XXH3_64bits_reset_withSeed(XXH3_state_t* statePtr, XXH64_hash_t seed);
|
||||
/* XXH3_64bits_reset_withSecret() :
|
||||
* `secret` is referenced, and must outlive the hash streaming session.
|
||||
* secretSize must be >= XXH3_SECRET_SIZE_MIN.
|
||||
/*
|
||||
* XXH3_64bits_reset_withSecret():
|
||||
* `secret` is referenced, and must outlive the hash streaming session, so
|
||||
* be careful when using stack arrays.
|
||||
* `secretSize` must be >= `XXH3_SECRET_SIZE_MIN`.
|
||||
*/
|
||||
XXH_PUBLIC_API XXH_errorcode XXH3_64bits_reset_withSecret(XXH3_state_t* statePtr, const void* secret, size_t secretSize);
|
||||
|
||||
@ -566,16 +627,23 @@ XXH_PUBLIC_API XXH_errorcode XXH3_128bits_update (XXH3_state_t* statePtr, const
|
||||
XXH_PUBLIC_API XXH128_hash_t XXH3_128bits_digest (const XXH3_state_t* statePtr);
|
||||
|
||||
|
||||
/* Note : for better performance, these functions can be inlined,
|
||||
* using XXH_INLINE_ALL */
|
||||
/* Note: For better performance, these functions can be inlined using XXH_INLINE_ALL */
|
||||
|
||||
/* return : 1 if equal, 0 if different */
|
||||
/*!
|
||||
* XXH128_isEqual():
|
||||
* Return: 1 if `h1` and `h2` are equal, 0 if they are not.
|
||||
*/
|
||||
XXH_PUBLIC_API int XXH128_isEqual(XXH128_hash_t h1, XXH128_hash_t h2);
|
||||
|
||||
/* This comparator is compatible with stdlib's qsort().
|
||||
* return : >0 if *h128_1 > *h128_2
|
||||
* <0 if *h128_1 < *h128_2
|
||||
* =0 if *h128_1 == *h128_2 */
|
||||
/*!
|
||||
* XXH128_cmp():
|
||||
*
|
||||
* This comparator is compatible with stdlib's `qsort()`/`bsearch()`.
|
||||
*
|
||||
* return: >0 if *h128_1 > *h128_2
|
||||
* <0 if *h128_1 < *h128_2
|
||||
* =0 if *h128_1 == *h128_2
|
||||
*/
|
||||
XXH_PUBLIC_API int XXH128_cmp(const void* h128_1, const void* h128_2);
|
||||
|
||||
|
||||
@ -600,15 +668,20 @@ XXH_PUBLIC_API XXH128_hash_t XXH128_hashFromCanonical(const XXH128_canonical_t*
|
||||
|
||||
|
||||
/*-**********************************************************************
|
||||
* xxHash implementation
|
||||
* -**********************************************************************
|
||||
* Functions implementation used to be hosted within xxhash.c .
|
||||
* However, code inlining requires implementations within the header file.
|
||||
* As a consequence, xxhash.c used to be included within xxhash.h .
|
||||
* However, some build systems don't like including *.c.
|
||||
* Therefore, implementation is now directly integrated within xxhash.h .
|
||||
* Another small advantage is that xxhash.c is no longer needed in /includes .
|
||||
************************************************************************/
|
||||
* xxHash implementation
|
||||
*-**********************************************************************
|
||||
* xxHash's implementation used to be found in xxhash.c.
|
||||
*
|
||||
* However, code inlining requires the implementation to be visible to the
|
||||
* compiler, usually within the header.
|
||||
*
|
||||
* As a workaround, xxhash.c used to be included within xxhash.h. This caused
|
||||
* some issues with some build systems, especially ones which treat .c files
|
||||
* as source files.
|
||||
*
|
||||
* Therefore, the implementation is now directly integrated within xxhash.h.
|
||||
* Another small advantage is that xxhash.c is no longer needed in /include.
|
||||
************************************************************************/
|
||||
|
||||
#if ( defined(XXH_INLINE_ALL) || defined(XXH_PRIVATE_API) \
|
||||
|| defined(XXH_IMPLEMENTATION) ) && !defined(XXH_IMPLEM_13a8737387)
|
||||
@ -617,19 +690,34 @@ XXH_PUBLIC_API XXH128_hash_t XXH128_hashFromCanonical(const XXH128_canonical_t*
|
||||
/* *************************************
|
||||
* Tuning parameters
|
||||
***************************************/
|
||||
/*!XXH_FORCE_MEMORY_ACCESS :
|
||||
* By default, access to unaligned memory is controlled by `memcpy()`, which is safe and portable.
|
||||
* Unfortunately, on some target/compiler combinations, the generated assembly is sub-optimal.
|
||||
* The below switch allow to select different access method for improved performance.
|
||||
* Method 0 (default) : use `memcpy()`. Safe and portable.
|
||||
* Method 1 : `__packed` statement. It depends on compiler extension (ie, not portable).
|
||||
* This method is safe if your compiler supports it, and *generally* as fast or faster than `memcpy`.
|
||||
* Method 2 : direct access. This method doesn't depend on compiler but violate C standard.
|
||||
* It can generate buggy code on targets which do not support unaligned memory accesses.
|
||||
* But in some circumstances, it's the only known way to get the most performance (ie GCC + ARMv6)
|
||||
* Method 3 : byteshift. This can generate the best code on old compilers which don't inline small
|
||||
* `memcpy()` calls, and it might also be faster on big-endian systems which lack a
|
||||
* native byteswap instruction.
|
||||
/*!
|
||||
* XXH_FORCE_MEMORY_ACCESS:
|
||||
* By default, access to unaligned memory is controlled by `memcpy()`, which is
|
||||
* safe and portable.
|
||||
*
|
||||
* Unfortunately, on some target/compiler combinations, the generated assembly
|
||||
* is sub-optimal.
|
||||
*
|
||||
* The below switch allow to select a different access method for improved
|
||||
* performance.
|
||||
* Method 0 (default):
|
||||
* Use `memcpy()`. Safe and portable.
|
||||
* Method 1:
|
||||
* `__attribute__((packed))` statement. It depends on compiler extensions
|
||||
* and is therefore not portable.
|
||||
* This method is safe if your compiler supports it, and *generally* as
|
||||
* fast or faster than `memcpy`.
|
||||
* Method 2:
|
||||
* Direct access via cast. This method doesn't depend on the compiler but
|
||||
* violates the C standard.
|
||||
* It can generate buggy code on targets which do not support unaligned
|
||||
* memory accesses.
|
||||
* But in some circumstances, it's the only known way to get the most
|
||||
* performance (ie GCC + ARMv6)
|
||||
* Method 3:
|
||||
* Byteshift. This can generate the best code on old compilers which don't
|
||||
* inline small `memcpy()` calls, and it might also be faster on big-endian
|
||||
* systems which lack a native byteswap instruction.
|
||||
* See http://stackoverflow.com/a/32095106/646947 for details.
|
||||
* Prefer these methods in priority order (0 > 1 > 2 > 3)
|
||||
*/
|
||||
@ -642,21 +730,25 @@ XXH_PUBLIC_API XXH128_hash_t XXH128_hashFromCanonical(const XXH128_canonical_t*
|
||||
# endif
|
||||
#endif
|
||||
|
||||
/*!XXH_ACCEPT_NULL_INPUT_POINTER :
|
||||
* If input pointer is NULL, xxHash default behavior is to dereference it, triggering a segfault.
|
||||
* When this macro is enabled, xxHash actively checks input for null pointer.
|
||||
* It it is, result for null input pointers is the same as a null-length input.
|
||||
/*!XXH_ACCEPT_NULL_INPUT_POINTER:
|
||||
* If the input pointer is NULL, xxHash's default behavior is to dereference it,
|
||||
* triggering a segfault.
|
||||
* When this macro is enabled, xxHash actively checks input for a null pointer.
|
||||
* It it is, result for null input pointers is the same as a zero-length input.
|
||||
*/
|
||||
#ifndef XXH_ACCEPT_NULL_INPUT_POINTER /* can be defined externally */
|
||||
# define XXH_ACCEPT_NULL_INPUT_POINTER 0
|
||||
#endif
|
||||
|
||||
/*!XXH_FORCE_ALIGN_CHECK :
|
||||
/*!
|
||||
* XXH_FORCE_ALIGN_CHECK:
|
||||
* This is a minor performance trick, only useful with lots of very small keys.
|
||||
* It means : check for aligned/unaligned input.
|
||||
* It means: check for aligned/unaligned input.
|
||||
* The check costs one initial branch per hash;
|
||||
* set it to 0 when the input is guaranteed to be aligned,
|
||||
* or when alignment doesn't matter for performance.
|
||||
* Set it to 0 when the input is guaranteed to be aligned or when alignment
|
||||
* doesn't matter for performance.
|
||||
*
|
||||
* This option does not affect XXH3.
|
||||
*/
|
||||
#ifndef XXH_FORCE_ALIGN_CHECK /* can be defined externally */
|
||||
# if defined(__i386) || defined(_M_IX86) || defined(__x86_64__) || defined(_M_X64)
|
||||
@ -666,22 +758,25 @@ XXH_PUBLIC_API XXH128_hash_t XXH128_hashFromCanonical(const XXH128_canonical_t*
|
||||
# endif
|
||||
#endif
|
||||
|
||||
/*!XXH_NO_INLINE_HINTS :
|
||||
* By default, xxHash tries to force the compiler to inline
|
||||
* almost all internal functions.
|
||||
* This can usually improve performance due to reduced jumping
|
||||
* and improved constant folding, but significantly increases
|
||||
* the size of the binary which might not be favorable.
|
||||
/*!
|
||||
* XXH_NO_INLINE_HINTS:
|
||||
*
|
||||
* Additionally, sometimes the forced inlining can be detrimental
|
||||
* to performance, depending on the architecture.
|
||||
* By default, xxHash tries to force the compiler to inline almost all internal
|
||||
* functions.
|
||||
*
|
||||
* XXH_NO_INLINE_HINTS marks all internal functions as static,
|
||||
* giving the compiler full control on whether to inline or not.
|
||||
* This can usually improve performance due to reduced jumping and improved
|
||||
* constant folding, but significantly increases the size of the binary which
|
||||
* might not be favorable.
|
||||
*
|
||||
* When not optimizing (-O0), optimizing for size (-Os,-Oz), or using
|
||||
* -fno-inline with GCC or Clang, this will automatically be
|
||||
* defined. */
|
||||
* Additionally, sometimes the forced inlining can be detrimental to performance,
|
||||
* depending on the architecture.
|
||||
*
|
||||
* XXH_NO_INLINE_HINTS marks all internal functions as static, giving the
|
||||
* compiler full control on whether to inline or not.
|
||||
*
|
||||
* When not optimizing (-O0), optimizing for size (-Os, -Oz), or using
|
||||
* -fno-inline with GCC or Clang, this will automatically be defined.
|
||||
*/
|
||||
#ifndef XXH_NO_INLINE_HINTS
|
||||
# if defined(__OPTIMIZE_SIZE__) /* -Os, -Oz */ \
|
||||
|| defined(__NO_INLINE__) /* -O0, -fno-inline */
|
||||
@ -708,14 +803,19 @@ XXH_PUBLIC_API XXH128_hash_t XXH128_hashFromCanonical(const XXH128_canonical_t*
|
||||
/* *************************************
|
||||
* Includes & Memory related functions
|
||||
***************************************/
|
||||
/*! Modify the local functions below should you wish to use some other memory routines
|
||||
* for malloc(), free() */
|
||||
/*!
|
||||
* Modify the local functions below should you wish to use some other memory
|
||||
* routines for malloc() and free()
|
||||
*/
|
||||
#include <stdlib.h>
|
||||
static void* XXH_malloc(size_t s) { return malloc(s); }
|
||||
static void XXH_free (void* p) { free(p); }
|
||||
/*! and for memcpy() */
|
||||
#include <string.h>
|
||||
static void* XXH_memcpy(void* dest, const void* src, size_t size) { return memcpy(dest,src,size); }
|
||||
static void* XXH_memcpy(void* dest, const void* src, size_t size)
|
||||
{
|
||||
return memcpy(dest,src,size);
|
||||
}
|
||||
|
||||
#include <limits.h> /* ULLONG_MAX */
|
||||
|
||||
@ -724,7 +824,7 @@ static void* XXH_memcpy(void* dest, const void* src, size_t size) { return memcp
|
||||
* Compiler Specific Options
|
||||
***************************************/
|
||||
#ifdef _MSC_VER /* Visual Studio warning fix */
|
||||
# pragma warning(disable : 4127) /* disable: C4127: conditional expression is constant */
|
||||
# pragma warning(disable : 4127) /* disable: C4127: conditional expression is constant */
|
||||
#endif
|
||||
|
||||
#if XXH_NO_INLINE_HINTS /* disable inlining hints */
|
||||
@ -734,7 +834,8 @@ static void* XXH_memcpy(void* dest, const void* src, size_t size) { return memcp
|
||||
# define XXH_FORCE_INLINE static __forceinline
|
||||
# define XXH_NO_INLINE static __declspec(noinline)
|
||||
#else
|
||||
# if defined (__cplusplus) || defined (__STDC_VERSION__) && __STDC_VERSION__ >= 199901L /* C99 */
|
||||
# if defined (__cplusplus) \
|
||||
|| defined (__STDC_VERSION__) && __STDC_VERSION__ >= 199901L /* C99 */
|
||||
# ifdef __GNUC__
|
||||
# define XXH_FORCE_INLINE static inline __attribute__((always_inline))
|
||||
# define XXH_NO_INLINE static __attribute__((noinline))
|
||||
@ -753,9 +854,10 @@ static void* XXH_memcpy(void* dest, const void* src, size_t size) { return memcp
|
||||
/* *************************************
|
||||
* Debug
|
||||
***************************************/
|
||||
/* DEBUGLEVEL is expected to be defined externally,
|
||||
* typically through compiler command line.
|
||||
* Value must be a number. */
|
||||
/*
|
||||
* DEBUGLEVEL is expected to be defined externally, typically via the compiler's
|
||||
* command line options. The value must be a number.
|
||||
*/
|
||||
#ifndef DEBUGLEVEL
|
||||
# define DEBUGLEVEL 0
|
||||
#endif
|
||||
@ -794,12 +896,18 @@ typedef XXH32_hash_t xxh_u32;
|
||||
*/
|
||||
#elif (defined(XXH_FORCE_MEMORY_ACCESS) && (XXH_FORCE_MEMORY_ACCESS==2))
|
||||
|
||||
/* Force direct memory access. Only works on CPU which support unaligned memory access in hardware */
|
||||
/*
|
||||
* Force direct memory access. Only works on CPU which support unaligned memory
|
||||
* access in hardware.
|
||||
*/
|
||||
static xxh_u32 XXH_read32(const void* memPtr) { return *(const xxh_u32*) memPtr; }
|
||||
|
||||
#elif (defined(XXH_FORCE_MEMORY_ACCESS) && (XXH_FORCE_MEMORY_ACCESS==1))
|
||||
|
||||
/* __pack instructions are safer, but compiler specific, hence potentially problematic for some compilers */
|
||||
/*
|
||||
* __pack instructions are safer but compiler specific, hence potentially
|
||||
* problematic for some compilers
|
||||
*/
|
||||
/* currently only defined for gcc and icc */
|
||||
typedef union { xxh_u32 u32; } __attribute__((packed)) unalign;
|
||||
static xxh_u32 XXH_read32(const void* ptr) { return ((const unalign*)ptr)->u32; }
|
||||
@ -822,8 +930,19 @@ static xxh_u32 XXH_read32(const void* memPtr)
|
||||
/* *** Endianess *** */
|
||||
typedef enum { XXH_bigEndian=0, XXH_littleEndian=1 } XXH_endianess;
|
||||
|
||||
/* XXH_CPU_LITTLE_ENDIAN can be defined externally, for example on the compiler command line */
|
||||
/*!
|
||||
* XXH_CPU_LITTLE_ENDIAN:
|
||||
* Defined to 1 if the target is little endian, or 0 if it is big endian.
|
||||
* It can be defined externally, for example on the compiler command line.
|
||||
*
|
||||
* If it is not defined, a runtime check (which is usually constant folded)
|
||||
* is used instead.
|
||||
*/
|
||||
#ifndef XXH_CPU_LITTLE_ENDIAN
|
||||
/*
|
||||
* Try to detect endianness automatically, to avoid the nonstandard behavior
|
||||
* in `XXH_isLittleEndian()`
|
||||
*/
|
||||
# if defined(_WIN32) /* Windows is always little endian */ \
|
||||
|| defined(__LITTLE_ENDIAN__) \
|
||||
|| (defined(__BYTE_ORDER__) && __BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__)
|
||||
@ -834,7 +953,11 @@ typedef enum { XXH_bigEndian=0, XXH_littleEndian=1 } XXH_endianess;
|
||||
# else
|
||||
static int XXH_isLittleEndian(void)
|
||||
{
|
||||
const union { xxh_u32 u; xxh_u8 c[4]; } one = { 1 }; /* don't use static : performance detrimental */
|
||||
/*
|
||||
* Nonstandard, but well-defined behavior in practice.
|
||||
* Don't use static: it is detrimental to performance.
|
||||
*/
|
||||
const union { xxh_u32 u; xxh_u8 c[4]; } one = { 1 };
|
||||
return one.c[0];
|
||||
}
|
||||
# define XXH_CPU_LITTLE_ENDIAN XXH_isLittleEndian()
|
||||
@ -853,7 +976,8 @@ static int XXH_isLittleEndian(void)
|
||||
# define __has_builtin(x) 0
|
||||
#endif
|
||||
|
||||
#if !defined(NO_CLANG_BUILTIN) && __has_builtin(__builtin_rotateleft32) && __has_builtin(__builtin_rotateleft64)
|
||||
#if !defined(NO_CLANG_BUILTIN) && __has_builtin(__builtin_rotateleft32) \
|
||||
&& __has_builtin(__builtin_rotateleft64)
|
||||
# define XXH_rotl32 __builtin_rotateleft32
|
||||
# define XXH_rotl64 __builtin_rotateleft64
|
||||
/* Note : although _rotl exists for minGW (GCC under windows), performance seems poor */
|
||||
@ -954,19 +1078,21 @@ static xxh_u32 XXH32_round(xxh_u32 acc, xxh_u32 input)
|
||||
acc = XXH_rotl32(acc, 13);
|
||||
acc *= PRIME32_1;
|
||||
#if defined(__GNUC__) && defined(__SSE4_1__) && !defined(XXH_ENABLE_AUTOVECTORIZE)
|
||||
/* UGLY HACK:
|
||||
/*
|
||||
* UGLY HACK:
|
||||
* This inline assembly hack forces acc into a normal register. This is the
|
||||
* only thing that prevents GCC and Clang from autovectorizing the XXH32 loop
|
||||
* (pragmas and attributes don't work for some resason) without globally
|
||||
* only thing that prevents GCC and Clang from autovectorizing the XXH32
|
||||
* loop (pragmas and attributes don't work for some resason) without globally
|
||||
* disabling SSE4.1.
|
||||
*
|
||||
* The reason we want to avoid vectorization is because despite working on
|
||||
* 4 integers at a time, there are multiple factors slowing XXH32 down on
|
||||
* SSE4:
|
||||
* - There's a ridiculous amount of lag from pmulld (10 cycles of latency on newer chips!)
|
||||
* making it slightly slower to multiply four integers at once compared to four
|
||||
* integers independently. Even when pmulld was fastest, Sandy/Ivy Bridge, it is
|
||||
* still not worth it to go into SSE just to multiply unless doing a long operation.
|
||||
* - There's a ridiculous amount of lag from pmulld (10 cycles of latency on
|
||||
* newer chips!) making it slightly slower to multiply four integers at
|
||||
* once compared to four integers independently. Even when pmulld was
|
||||
* fastest, Sandy/Ivy Bridge, it is still not worth it to go into SSE
|
||||
* just to multiply unless doing a long operation.
|
||||
*
|
||||
* - Four instructions are required to rotate,
|
||||
* movqda tmp, v // not required with VEX encoding
|
||||
@ -977,9 +1103,10 @@ static xxh_u32 XXH32_round(xxh_u32 acc, xxh_u32 input)
|
||||
* roll v, 13 // reliably fast across the board
|
||||
* shldl v, v, 13 // Sandy Bridge and later prefer this for some reason
|
||||
*
|
||||
* - Instruction level parallelism is actually more beneficial here because the
|
||||
* SIMD actually serializes this operation: While v1 is rotating, v2 can load data,
|
||||
* while v3 can multiply. SSE forces them to operate together.
|
||||
* - Instruction level parallelism is actually more beneficial here because
|
||||
* the SIMD actually serializes this operation: While v1 is rotating, v2
|
||||
* can load data, while v3 can multiply. SSE forces them to operate
|
||||
* together.
|
||||
*
|
||||
* How this hack works:
|
||||
* __asm__("" // Declare an assembly block but don't declare any instructions
|
||||
@ -994,7 +1121,8 @@ static xxh_u32 XXH32_round(xxh_u32 acc, xxh_u32 input)
|
||||
* loads and stores.
|
||||
*
|
||||
* Since the argument has to be in a normal register (not an SSE register),
|
||||
* each time XXH32_round is called, it is impossible to vectorize. */
|
||||
* each time XXH32_round is called, it is impossible to vectorize.
|
||||
*/
|
||||
__asm__("" : "+r" (acc));
|
||||
#endif
|
||||
return acc;
|
||||
@ -1289,19 +1417,22 @@ XXH_PUBLIC_API XXH32_hash_t XXH32_hashFromCanonical(const XXH32_canonical_t* src
|
||||
typedef XXH64_hash_t xxh_u64;
|
||||
|
||||
|
||||
/*! XXH_REROLL_XXH64:
|
||||
/*!
|
||||
* XXH_REROLL_XXH64:
|
||||
* Whether to reroll the XXH64_finalize() loop.
|
||||
*
|
||||
* Just like XXH32, we can unroll the XXH64_finalize() loop. This can be a performance gain
|
||||
* on 64-bit hosts, as only one jump is required.
|
||||
* Just like XXH32, we can unroll the XXH64_finalize() loop. This can be a
|
||||
* performance gain on 64-bit hosts, as only one jump is required.
|
||||
*
|
||||
* However, on 32-bit hosts, because arithmetic needs to be done with two 32-bit registers,
|
||||
* and 64-bit arithmetic needs to be simulated, it isn't beneficial to unroll. The code becomes
|
||||
* ridiculously large (the largest function in the binary on i386!), and rerolling it saves
|
||||
* anywhere from 3kB to 20kB. It is also slightly faster because it fits into cache better
|
||||
* and is more likely to be inlined by the compiler.
|
||||
* However, on 32-bit hosts, because arithmetic needs to be done with two 32-bit
|
||||
* registers, and 64-bit arithmetic needs to be simulated, it isn't beneficial
|
||||
* to unroll. The code becomes ridiculously large (the largest function in the
|
||||
* binary on i386!), and rerolling it saves anywhere from 3kB to 20kB. It is
|
||||
* also slightly faster because it fits into cache better and is more likely
|
||||
* to be inlined by the compiler.
|
||||
*
|
||||
* If XXH_REROLL is defined, this is ignored and the loop is always rerolled. */
|
||||
* If XXH_REROLL is defined, this is ignored and the loop is always rerolled.
|
||||
*/
|
||||
#ifndef XXH_REROLL_XXH64
|
||||
# if (defined(__ILP32__) || defined(_ILP32)) /* ILP32 is often defined on 32-bit GCC family */ \
|
||||
|| !(defined(__x86_64__) || defined(_M_X64) || defined(_M_AMD64) /* x86-64 */ \
|
||||
|
||||
14
xxhsum.1
14
xxhsum.1
@ -5,10 +5,10 @@
|
||||
\fBxxhsum\fR \- print or check xxHash non\-cryptographic checksums
|
||||
.
|
||||
.SH "SYNOPSIS"
|
||||
\fBxxhsum [<OPTION>] \.\.\. [<FILE>] \.\.\.\fR
|
||||
\fBxxhsum [<OPTION>]\.\.\. [<FILE>]\.\.\.\fR
|
||||
.
|
||||
.br
|
||||
\fBxxhsum \-b [<OPTION>] \.\.\.\fR
|
||||
\fBxxhsum \-b [<OPTION>]\.\.\.\fR
|
||||
.
|
||||
.P
|
||||
\fBxxh32sum\fR is equivalent to \fBxxhsum \-H0\fR
|
||||
@ -23,7 +23,7 @@
|
||||
Print or check xxHash (32, 64 or 128 bits) checksums\. When \fIFILE\fR is \fB\-\fR, read standard input\.
|
||||
.
|
||||
.P
|
||||
\fBxxhsum\fR supports a command line syntax similar but not identical to md5sum(1)\. Differences are: \fBxxhsum\fR doesn\'t have text/binary mode switch (\fB\-b\fR, \fB\-t\fR); \fBxxhsum\fR always treats file as binary file; \fBxxhsum\fR has hash bit width switch (\fB\-H\fR);
|
||||
\fBxxhsum\fR supports a command line syntax similar but not identical to md5sum(1)\. Differences are: \fBxxhsum\fR doesn\'t have text/binary mode switch (\fB\-b\fR, \fB\-t\fR); \fBxxhsum\fR always treats files as binary files; \fBxxhsum\fR has a hash bit width switch (\fB\-H\fR);
|
||||
.
|
||||
.P
|
||||
As xxHash is a fast non\-cryptographic checksum algorithm, \fBxxhsum\fR should not be used for security related purposes\.
|
||||
@ -35,7 +35,7 @@ As xxHash is a fast non\-cryptographic checksum algorithm, \fBxxhsum\fR should n
|
||||
.
|
||||
.TP
|
||||
\fB\-V\fR, \fB\-\-version\fR
|
||||
Display xxhsum version and exits
|
||||
Displays xxhsum version and exits
|
||||
.
|
||||
.TP
|
||||
\fB\-H\fR\fIHASHTYPE\fR
|
||||
@ -43,7 +43,7 @@ Hash selection\. \fIHASHTYPE\fR means \fB0\fR=32bits, \fB1\fR=64bits, \fB2\fR=12
|
||||
.
|
||||
.TP
|
||||
\fB\-q\fR, \fB\-\-quiet\fR
|
||||
Remove status messages like "Loading \.\.\." written to \fBstderr\fR \.
|
||||
Remove status messages like "Loading\.\.\." written to \fBstderr\fR \.
|
||||
.
|
||||
.TP
|
||||
\fB\-\-little\-endian\fR
|
||||
@ -51,7 +51,7 @@ Set output hexadecimal checksum value as little endian convention\. By default,
|
||||
.
|
||||
.TP
|
||||
\fB\-h\fR, \fB\-\-help\fR
|
||||
Display help and exit
|
||||
Displays help and exits
|
||||
.
|
||||
.P
|
||||
\fBThe following four options are useful only when verifying checksums (\fB\-c\fR)\fR
|
||||
@ -138,7 +138,7 @@ $ xxhsum \-c xyz\.xxh32 qux\.xxh64
|
||||
Benchmark xxHash algorithm for 16384 bytes data in 10 times\. \fBxxhsum\fR benchmarks all xxHash variants and output results to standard output\.
|
||||
.
|
||||
.br
|
||||
First column means algorithm, second column is source data size in bytes, third column is number of hashes generated per second (throughput), and finally last column translates speed in mega\-bytes per seconds\.
|
||||
The first column is the algorithm, the second column is the source data size in bytes, the third column is the number of hashes generated per second (throughput), and finally, the last column translates speed in megabytes per second\.
|
||||
.
|
||||
.IP "" 4
|
||||
.
|
||||
|
||||
19
xxhsum.1.md
19
xxhsum.1.md
@ -21,8 +21,8 @@ standard input.
|
||||
`xxhsum` supports a command line syntax similar but not identical to
|
||||
md5sum(1). Differences are:
|
||||
`xxhsum` doesn't have text/binary mode switch (`-b`, `-t`);
|
||||
`xxhsum` always treats file as binary file;
|
||||
`xxhsum` has hash bit width switch (`-H`);
|
||||
`xxhsum` always treats files as binary file;
|
||||
`xxhsum` has a hash bit width switch (`-H`);
|
||||
|
||||
As xxHash is a fast non-cryptographic checksum algorithm,
|
||||
`xxhsum` should not be used for security related purposes.
|
||||
@ -33,21 +33,21 @@ OPTIONS
|
||||
-------
|
||||
|
||||
* `-V`, `--version`:
|
||||
Display xxhsum version and exits
|
||||
Displays xxhsum version and exits
|
||||
|
||||
* `-H`<HASHTYPE>:
|
||||
Hash selection. <HASHTYPE> means `0`=32bits, `1`=64bits, `2`=128bits.
|
||||
Hash selection. <HASHTYPE> means `0`=32bits, `1`=64bits, `2`=128bits.
|
||||
Default value is `1` (64bits)
|
||||
|
||||
* `-q`, `--quiet`:
|
||||
Remove status messages like "Loading ..." written to `stderr` .
|
||||
Remove status messages like "Loading..." written to `stderr`.
|
||||
|
||||
* `--little-endian`:
|
||||
Set output hexadecimal checksum value as little endian convention.
|
||||
By default, value is displayed as big endian.
|
||||
|
||||
* `-h`, `--help`:
|
||||
Display help and exit
|
||||
Displays help and exits
|
||||
|
||||
**The following four options are useful only when verifying checksums (`-c`)**
|
||||
|
||||
@ -111,9 +111,10 @@ Read xxHash sums from specific files and check them
|
||||
|
||||
Benchmark xxHash algorithm for 16384 bytes data in 10 times. `xxhsum`
|
||||
benchmarks all xxHash variants and output results to standard output.
|
||||
First column means algorithm, second column is source data size in bytes,
|
||||
third column is number of hashes generated per second (throughput),
|
||||
and finally last column translates speed in mega-bytes per seconds.
|
||||
The first column is the algorithm, thw second column is the source data
|
||||
size in bytes, the third column is the number of hashes generated per
|
||||
second (throughput), and finally the last column translates speed in
|
||||
megabytes per second.
|
||||
|
||||
$ xxhsum -b -i10 -B16384
|
||||
|
||||
|
||||
153
xxhsum.c
153
xxhsum.c
@ -18,12 +18,13 @@
|
||||
* with this program; if not, write to the Free Software Foundation, Inc.,
|
||||
* 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
|
||||
*
|
||||
* You can contact the author at :
|
||||
* - xxHash homepage : http://www.xxhash.com
|
||||
* - xxHash source repository : https://github.com/Cyan4973/xxHash
|
||||
* You can contact the author at:
|
||||
* - xxHash homepage: http://www.xxhash.com
|
||||
* - xxHash source repository: https://github.com/Cyan4973/xxHash
|
||||
*/
|
||||
|
||||
/* xxhsum :
|
||||
/*
|
||||
* xxhsum:
|
||||
* Provides hash value of a file content, or a list of files, or stdin
|
||||
* Display convention is Big Endian, for both 32 and 64 bits algorithms
|
||||
*/
|
||||
@ -493,11 +494,13 @@ static void BMK_benchHash(hashFunction h, const char* hName, const void* buffer,
|
||||
}
|
||||
|
||||
|
||||
/* BMK_benchMem():
|
||||
* specificTest : 0 == run all tests, 1+ run only specific test
|
||||
* buffer : is supposed 8-bytes aligned (if malloc'ed, it should be)
|
||||
* the real allocated size of buffer is supposed to be >= (bufferSize+3).
|
||||
* @return : 0 on success, 1 if error (invalid mode selected) */
|
||||
/*!
|
||||
* BMK_benchMem():
|
||||
* specificTest: 0 == run all tests, 1+ runs specific test
|
||||
* buffer: Must be 8-byte aligned (if malloc'ed, it should be)
|
||||
* The real allocated size of buffer is supposed to be >= (bufferSize+3).
|
||||
* returns: 0 on success, 1 if error (invalid mode selected)
|
||||
*/
|
||||
static int BMK_benchMem(const void* buffer, size_t bufferSize, U32 specificTest)
|
||||
{
|
||||
assert((((size_t)buffer) & 8) == 0); /* ensure alignment */
|
||||
@ -651,7 +654,7 @@ static void BMK_checkResult32(XXH32_hash_t r1, XXH32_hash_t r2)
|
||||
static int nbTests = 1;
|
||||
if (r1!=r2) {
|
||||
DISPLAY("\rError: 32-bit hash test %i: Internal sanity check failed!\n", nbTests);
|
||||
DISPLAY("\rGot 0x%08X , expected 0x%08X.\n", (unsigned)r1, (unsigned)r2);
|
||||
DISPLAY("\rGot 0x%08X, expected 0x%08X.\n", (unsigned)r1, (unsigned)r2);
|
||||
DISPLAY("\rNote: If you modified the hash functions, make sure to either update the values\n"
|
||||
"or temporarily comment out the tests in BMK_sanityCheck.\n");
|
||||
exit(1);
|
||||
@ -664,7 +667,7 @@ static void BMK_checkResult64(XXH64_hash_t r1, XXH64_hash_t r2)
|
||||
static int nbTests = 1;
|
||||
if (r1!=r2) {
|
||||
DISPLAY("\rError: 64-bit hash test %i: Internal sanity check failed!\n", nbTests);
|
||||
DISPLAY("\rGot 0x%08X%08XULL , expected 0x%08X%08XULL.\n",
|
||||
DISPLAY("\rGot 0x%08X%08XULL, expected 0x%08X%08XULL.\n",
|
||||
(unsigned)(r1>>32), (unsigned)r1, (unsigned)(r2>>32), (unsigned)r2);
|
||||
DISPLAY("\rNote: If you modified the hash functions, make sure to either update the values\n"
|
||||
"or temporarily comment out the tests in BMK_sanityCheck.\n");
|
||||
@ -678,7 +681,7 @@ static void BMK_checkResult128(XXH128_hash_t r1, XXH128_hash_t r2)
|
||||
static int nbTests = 1;
|
||||
if ((r1.low64 != r2.low64) || (r1.high64 != r2.high64)) {
|
||||
DISPLAY("\rError: 128-bit hash test %i: Internal sanity check failed.\n", nbTests);
|
||||
DISPLAY("\rGot { 0x%08X%08XULL , 0x%08X%08XULL }, expected { 0x%08X%08XULL, 0x%08X%08XULL } \n",
|
||||
DISPLAY("\rGot { 0x%08X%08XULL, 0x%08X%08XULL }, expected { 0x%08X%08XULL, 0x%08X%08XULL } \n",
|
||||
(unsigned)(r1.low64>>32), (unsigned)r1.low64, (unsigned)(r1.high64>>32), (unsigned)r1.high64,
|
||||
(unsigned)(r2.low64>>32), (unsigned)r2.low64, (unsigned)(r2.high64>>32), (unsigned)r2.high64 );
|
||||
DISPLAY("\rNote: If you modified the hash functions, make sure to either update the values\n"
|
||||
@ -833,6 +836,13 @@ void BMK_testXXH128(const void* data, size_t len, U64 seed, XXH128_hash_t Nresul
|
||||
}
|
||||
|
||||
#define SANITY_BUFFER_SIZE 2243
|
||||
|
||||
/*!
|
||||
* BMK_sanityCheck():
|
||||
* Runs a sanity check before the benchmark.
|
||||
*
|
||||
* Exits on an incorrect output.
|
||||
*/
|
||||
static void BMK_sanityCheck(void)
|
||||
{
|
||||
const U32 prime = 2654435761U;
|
||||
@ -1022,10 +1032,11 @@ typedef union {
|
||||
XXH128_hash_t xxh128;
|
||||
} Multihash;
|
||||
|
||||
/* BMK_hashStream :
|
||||
* read data from inFile,
|
||||
* generating incremental hash of type hashType,
|
||||
* using buffer of size blockSize for temporary storage. */
|
||||
/*
|
||||
* BMK_hashStream:
|
||||
* Reads data from `inFile`, generating an incremental hash of type hashType,
|
||||
* using `buffer` of size `blockSize` for temporary storage.
|
||||
*/
|
||||
static Multihash
|
||||
BMK_hashStream(FILE* inFile,
|
||||
algoType hashType,
|
||||
@ -1164,8 +1175,9 @@ static int BMK_hash(const char* fileName,
|
||||
}
|
||||
|
||||
|
||||
/* BMK_hashFiles:
|
||||
* if fnTotal==0, read from stdin insteal
|
||||
/*
|
||||
* BMK_hashFiles:
|
||||
* If fnTotal==0, read from stdin instead.
|
||||
*/
|
||||
static int BMK_hashFiles(char** fnList, int fnTotal,
|
||||
algoType hashType, endianess displayEndianess)
|
||||
@ -1215,7 +1227,7 @@ typedef union {
|
||||
typedef struct {
|
||||
Canonical canonical;
|
||||
const char* filename;
|
||||
int xxhBits; /* canonical type : 32:xxh32, 64:xxh64 */
|
||||
int xxhBits; /* canonical type: 32:xxh32, 64:xxh64, 128:xxh128 */
|
||||
} ParsedLine;
|
||||
|
||||
typedef struct {
|
||||
@ -1243,11 +1255,12 @@ typedef struct {
|
||||
} ParseFileArg;
|
||||
|
||||
|
||||
/* Read line from stream.
|
||||
Returns GetLine_ok, if it reads line successfully.
|
||||
Returns GetLine_eof, if stream reaches EOF.
|
||||
Returns GetLine_exceedMaxLineLength, if line length is longer than MAX_LINE_LENGTH.
|
||||
Returns GetLine_outOfMemory, if line buffer memory allocation failed.
|
||||
/*
|
||||
* Reads a line from stream `inFile`.
|
||||
* Returns GetLine_ok, if it reads line successfully.
|
||||
* Returns GetLine_eof, if stream reaches EOF.
|
||||
* Returns GetLine_exceedMaxLineLength, if line length is longer than MAX_LINE_LENGTH.
|
||||
* Returns GetLine_outOfMemory, if line buffer memory allocation failed.
|
||||
*/
|
||||
static GetLineResult getLine(char** lineBuf, int* lineMax, FILE* inFile)
|
||||
{
|
||||
@ -1297,8 +1310,9 @@ static GetLineResult getLine(char** lineBuf, int* lineMax, FILE* inFile)
|
||||
}
|
||||
|
||||
|
||||
/* Converts one hexadecimal character to integer.
|
||||
* Returns -1, if given character is not hexadecimal.
|
||||
/*
|
||||
* Converts one hexadecimal character to integer.
|
||||
* Returns -1 if the given character is not hexadecimal.
|
||||
*/
|
||||
static int charToHex(char c)
|
||||
{
|
||||
@ -1314,9 +1328,12 @@ static int charToHex(char c)
|
||||
}
|
||||
|
||||
|
||||
/* Converts XXH32 canonical hexadecimal string hashStr to big endian unsigned char array dst.
|
||||
* Returns CANONICAL_FROM_STRING_INVALID_FORMAT, if hashStr is not well formatted.
|
||||
* Returns CANONICAL_FROM_STRING_OK, if hashStr is parsed successfully.
|
||||
/*
|
||||
* Converts XXH32 canonical hexadecimal string `hashStr` to the big endian unsigned
|
||||
* char array `dst`.
|
||||
*
|
||||
* Returns CANONICAL_FROM_STRING_INVALID_FORMAT if hashStr is not well formatted.
|
||||
* Returns CANONICAL_FROM_STRING_OK if hashStr is parsed successfully.
|
||||
*/
|
||||
static CanonicalFromStringResult canonicalFromString(unsigned char* dst,
|
||||
size_t dstSize,
|
||||
@ -1338,18 +1355,19 @@ static CanonicalFromStringResult canonicalFromString(unsigned char* dst,
|
||||
}
|
||||
|
||||
|
||||
/* Parse single line of xxHash checksum file.
|
||||
* Returns PARSE_LINE_ERROR_INVALID_FORMAT, if line is not well formatted.
|
||||
* Returns PARSE_LINE_OK if line is parsed successfully.
|
||||
* And members of parseLine will be filled by parsed values.
|
||||
/*
|
||||
* Parse single line of xxHash checksum file.
|
||||
* Returns PARSE_LINE_ERROR_INVALID_FORMAT if the line is not well formatted.
|
||||
* Returns PARSE_LINE_OK if the line is parsed successfully.
|
||||
* And members of parseLine will be filled by parsed values.
|
||||
*
|
||||
* - line must be ended with '\0'.
|
||||
* - line must be terminated with '\0'.
|
||||
* - Since parsedLine.filename will point within given argument `line`,
|
||||
* users must keep `line`s content during they are using parsedLine.
|
||||
* users must keep `line`s content when they are using parsedLine.
|
||||
*
|
||||
* Given xxHash checksum line should have the following format:
|
||||
* xxHash checksum lines should have the following format:
|
||||
*
|
||||
* <8 or 16 hexadecimal char> <space> <space> <filename...> <'\0'>
|
||||
* <8, 16, or 32 hexadecimal char> <space> <space> <filename...> <'\0'>
|
||||
*/
|
||||
static ParseLineResult parseLine(ParsedLine* parsedLine, const char* line)
|
||||
{
|
||||
@ -1589,7 +1607,7 @@ static int checkFile(const char* inFileName,
|
||||
return 0;
|
||||
}
|
||||
|
||||
/* note : stdinName is special constant pointer. It is not a string. */
|
||||
/* note: stdinName is special constant pointer. It is not a string. */
|
||||
if (inFileName == stdinName) {
|
||||
/* note : Since we expect text input for xxhash -c mode,
|
||||
* Don't set binary mode for stdin */
|
||||
@ -1683,13 +1701,13 @@ static int checkFiles(char** fnList, int fnTotal,
|
||||
static int usage(const char* exename)
|
||||
{
|
||||
DISPLAY( WELCOME_MESSAGE(exename) );
|
||||
DISPLAY( "Usage :\n");
|
||||
DISPLAY( " %s [arg] [filenames] \n", exename);
|
||||
DISPLAY( "When no filename provided, or - provided : use stdin as input \n");
|
||||
DISPLAY( "Arguments : \n");
|
||||
DISPLAY( " -H# : hash selection : 0=32bits, 1=64bits, 2=128bits (default: %i)\n", (int)g_defaultAlgo);
|
||||
DISPLAY( " -c : read xxHash sums from the [filenames] and check them \n");
|
||||
DISPLAY( " -h : help \n");
|
||||
DISPLAY( "Usage: %s [OPTION] [FILES]...\n", exename);
|
||||
DISPLAY( "Print or check xxHash checksums.\n\n" );
|
||||
DISPLAY( "When no filename provided or when '-' is provided, uses stdin as input.\n");
|
||||
DISPLAY( "Arguments: \n");
|
||||
DISPLAY( " -H# Select hash algorithm. 0=32bits, 1=64bits, 2=128bits (default: %i)\n", (int)g_defaultAlgo);
|
||||
DISPLAY( " -c Read xxHash sums from the [filenames] and check them\n");
|
||||
DISPLAY( " -h Display long help and exit\n");
|
||||
return 0;
|
||||
}
|
||||
|
||||
@ -1698,18 +1716,18 @@ static int usage_advanced(const char* exename)
|
||||
{
|
||||
usage(exename);
|
||||
DISPLAY( "Advanced :\n");
|
||||
DISPLAY( " -V, --version : display version \n");
|
||||
DISPLAY( " -q, --quiet : do not display 'Loading' messages \n");
|
||||
DISPLAY( " --little-endian : hash printed using little endian convention (default: big endian) \n");
|
||||
DISPLAY( " -h, --help : display long help and exit \n");
|
||||
DISPLAY( " -b : benchmark mode \n");
|
||||
DISPLAY( " -i# : number of iterations (benchmark mode; default %u) \n", (unsigned)g_nbIterations);
|
||||
DISPLAY( " -V, --version Display version information\n");
|
||||
DISPLAY( " -q, --quiet Do not display 'Loading' messages\n");
|
||||
DISPLAY( " --little-endian Display hashes in little endian convention (default: big endian) \n");
|
||||
DISPLAY( " -h, --help Display long help and exit\n");
|
||||
DISPLAY( " -b [N] Run a benchmark (runs all by default, or Nth benchmark)\n");
|
||||
DISPLAY( " -i ITERATIONS Number of times to run the benchmark (default: %u)\n", (unsigned)g_nbIterations);
|
||||
DISPLAY( "\n");
|
||||
DISPLAY( "The following four options are useful only when verifying checksums (-c): \n");
|
||||
DISPLAY( "--strict : don't print OK for each successfully verified file \n");
|
||||
DISPLAY( "--status : don't output anything, status code shows success \n");
|
||||
DISPLAY( "-q, --quiet : exit non-zero for improperly formatted checksum lines \n");
|
||||
DISPLAY( "--warn : warn about improperly formatted checksum lines \n");
|
||||
DISPLAY( "The following four options are useful only when verifying checksums (-c):\n");
|
||||
DISPLAY( " -q, --quiet Don't print OK for each successfully verified file\n");
|
||||
DISPLAY( " --status Don't output anything, status code shows success\n");
|
||||
DISPLAY( " --strict Exit non-zero for improperly formatted checksum lines\n");
|
||||
DISPLAY( " --warn Warn about improperly formatted checksum lines\n");
|
||||
return 0;
|
||||
}
|
||||
|
||||
@ -1725,11 +1743,13 @@ static void errorOut(const char* msg)
|
||||
DISPLAY("%s \n", msg); exit(1);
|
||||
}
|
||||
|
||||
/*! readU32FromCharChecked() :
|
||||
/*!
|
||||
* readU32FromCharChecked():
|
||||
* @return 0 if success, and store the result in *value.
|
||||
* allows and interprets K, KB, KiB, M, MB and MiB suffix.
|
||||
* Will also modify `*stringPtr`, advancing it to position where it stopped reading.
|
||||
* @return 1 if an overflow error occurs */
|
||||
* Allows and interprets K, KB, KiB, M, MB and MiB suffix.
|
||||
* Will also modify `*stringPtr`, advancing it to position where it stopped reading.
|
||||
* @return 1 if an overflow error occurs
|
||||
*/
|
||||
static int readU32FromCharChecked(const char** stringPtr, unsigned* value)
|
||||
{
|
||||
static unsigned const max = (((unsigned)(-1)) / 10) - 1;
|
||||
@ -1756,11 +1776,12 @@ static int readU32FromCharChecked(const char** stringPtr, unsigned* value)
|
||||
return 0;
|
||||
}
|
||||
|
||||
/*! readU32FromChar() :
|
||||
* @return : unsigned integer value read from input in `char` format.
|
||||
/*!
|
||||
* readU32FromChar():
|
||||
* @return: unsigned integer value read from input in `char` format.
|
||||
* allows and interprets K, KB, KiB, M, MB and MiB suffix.
|
||||
* Will also modify `*stringPtr`, advancing it to position where it stopped reading.
|
||||
* Note : function will exit() program if digit sequence overflows */
|
||||
* Note: function will exit() program if digit sequence overflows */
|
||||
static unsigned readU32FromChar(const char** stringPtr) {
|
||||
unsigned result;
|
||||
if (readU32FromCharChecked(stringPtr, &result)) {
|
||||
@ -1846,7 +1867,7 @@ static int XXH_main(int argc, char** argv)
|
||||
case 'b':
|
||||
argument++;
|
||||
benchmarkMode = 1;
|
||||
specificTest = readU32FromChar(&argument); /* select one specific test (hidden option) */
|
||||
specificTest = readU32FromChar(&argument); /* select one specific test */
|
||||
break;
|
||||
|
||||
/* Modify Nb Iterations (benchmark only) */
|
||||
@ -1933,8 +1954,8 @@ static void free_argv(int argc, char **argv)
|
||||
* However, without the -municode flag (which isn't even available on the
|
||||
* original MinGW), we will get a linker error.
|
||||
*
|
||||
* To fix this, we can combine main with GetCommandLineW and
|
||||
* CommandLineToArgvW to get the real UTF-16 arguments.
|
||||
* To fix this, we can combine main with GetCommandLineW and CommandLineToArgvW
|
||||
* to get the real UTF-16 arguments.
|
||||
*/
|
||||
#if defined(_MSC_VER) || defined(_UNICODE) || defined(UNICODE)
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user