mirror of
https://github.com/FEX-Emu/xxHash.git
synced 2024-11-23 06:29:39 +00:00
updated benchmark results on README.md
with newest measurements featuring XXH3 on recent systems
This commit is contained in:
parent
b9a0ec2632
commit
c4792b6746
122
README.md
122
README.md
@ -1,11 +1,11 @@
|
||||
|
||||
xxHash - Extremely fast hash algorithm
|
||||
======================================
|
||||
|
||||
<!-- TODO: Update. -->
|
||||
xxHash is an Extremely fast Hash algorithm, running at RAM speed limits.
|
||||
It successfully completes the [SMHasher](https://code.google.com/p/smhasher/wiki/SMHasher) test suite
|
||||
which evaluates collision, dispersion and randomness qualities of hash functions.
|
||||
Code is highly portable, and hashes are identical on all platforms (little / big endian).
|
||||
Code is highly portable, and hashes are identical across all platforms (little / big endian).
|
||||
|
||||
|Branch |Status |
|
||||
|------------|---------|
|
||||
@ -13,50 +13,70 @@ Code is highly portable, and hashes are identical on all platforms (little / big
|
||||
|dev | [](https://travis-ci.org/Cyan4973/xxHash?branch=dev) |
|
||||
|
||||
|
||||
|
||||
Benchmarks
|
||||
-------------------------
|
||||
|
||||
The benchmark uses SMHasher speed test, compiled with Visual 2010 on a Windows Seven 32-bit box.
|
||||
The reference system uses a Core 2 Duo @3GHz
|
||||
The benchmark is compiled with clang v10.0 and run on Ubuntu x64 20.04.
|
||||
The reference system uses Intel i7-9700K
|
||||
|
||||
| Hash Name | Width | Bandwidth (GB/s) | Small Data Velocity | Quality | Comment |
|
||||
| --------- | ----- | ----------------- | ----- | --- | --- |
|
||||
| __XXH3__ (SSE2) | 64 | 31.5 GB/s | 133.1 | 10
|
||||
| __XXH128__ (SSE2) | 128 | 29.6 GB/s | 118.1 | 10
|
||||
| _RAM sequential read_ | N/A | 28.0 GB/s | N/A | N/A
|
||||
| City64 | 64 | 22.0 GB/s | 76.6 | 10
|
||||
| T1ha2 | 64 | 22.0 GB/s | 99.0 | 9 | Slightly worse [collision ratio]
|
||||
| City128 | 128 | 21.7 GB/s | 57.7 | 10
|
||||
| __XXH64__ | 64 | 19.4 GB/s | 71.0 | 10
|
||||
| SpookyHash | 64 | 19.3 GB/s | 53.2 | 10
|
||||
| Mum | 64 | 18.0 GB/s | 67.0 | 9 | Slightly worse [collision ratio]
|
||||
| __XXH32__ | 32 | 9.7 GB/s | 71.9 | 10
|
||||
| City32 | 32 | 9.1 GB/s | 66.0 | 10
|
||||
| Murmur3 | 32 | 3.9 GB/s | 56.1 | 10
|
||||
| SipHash | 64 | 3.0 GB/s | 43.2 | 10
|
||||
| HighwayHash | 64 | 1.4 GB/s | 6.0 | 10
|
||||
| FNV64 | 64 | 1.2 GB/s | 62.7 | 5 | Poor avalanche properties
|
||||
| Blake2 | 128 | 1.1 GB/s | 5.1 | 10
|
||||
|
||||
| Name | Speed | Quality | Author |
|
||||
|---------------|--------------------|:-------:|-------------------|
|
||||
| [xxHash] | 5.4 GB/s | 10 | Y.C. |
|
||||
| MurmurHash 3a | 2.7 GB/s | 10 | Austin Appleby |
|
||||
| SBox | 1.4 GB/s | 9 | Bret Mulvey |
|
||||
| Lookup3 | 1.2 GB/s | 9 | Bob Jenkins |
|
||||
| CityHash64 | 1.05 GB/s | 10 | Pike & Alakuijala |
|
||||
| FNV | 0.55 GB/s | 5 | Fowler, Noll, Vo |
|
||||
| CRC32 | 0.43 GB/s † | 9 | |
|
||||
| MD5-32 | 0.33 GB/s | 10 | Ronald L.Rivest |
|
||||
| SHA1-32 | 0.28 GB/s | 10 | |
|
||||
[collision ratio]: https://github.com/Cyan4973/xxHash/wiki/Collision-ratio-comparison#collision-study
|
||||
|
||||
[xxHash]: https://www.xxhash.com
|
||||
note: some algorithms feature _faster than RAM_ speed. In which case, they can only reach their full speed when input data is already in CPU cache (L3 or better). Otherwise, they max out on RAM speed limit.
|
||||
|
||||
Note †: SMHasher's CRC32 implementation is known to be slow. Faster implementations exist.
|
||||
### Small data
|
||||
Performance on large data is only one part of the picture.
|
||||
Hashing is also very useful in constructions like hash tables and bloom filters.
|
||||
In these use cases, it's frequent to hash a lot of small data (starting at a few bytes).
|
||||
Algorithm's performance can be very different for such scenarios, since parts of the algorithm,
|
||||
such as initialization or finalization, become fixed cost.
|
||||
The impact of branch mis-prediction also becomes much more present.
|
||||
|
||||
Q.Score is a measure of quality of the hash function.
|
||||
It depends on successfully passing SMHasher test set.
|
||||
10 is a perfect score.
|
||||
Algorithms with a score < 5 are not listed on this table.
|
||||
XXH3 has been designed for excellent performance on both long and small inputs,
|
||||
which can be observed in the following graph:
|
||||
|
||||
A more recent version, XXH64, has been created thanks to [Mathias Westerdahl](https://github.com/JCash),
|
||||
which offers superior speed and dispersion for 64-bit systems.
|
||||
Note however that 32-bit applications will still run faster using the 32-bit version.
|
||||

|
||||
|
||||
SMHasher speed test, compiled using GCC 4.8.2, on Linux Mint 64-bit.
|
||||
The reference system uses a Core i5-3340M @2.7GHz
|
||||
For a more detailed analysis, visit the wiki :
|
||||
https://github.com/Cyan4973/xxHash/wiki/Performance-comparison#benchmarks-concentrating-on-small-data-
|
||||
|
||||
| Version | Speed on 64-bit | Speed on 32-bit |
|
||||
|------------|------------------|------------------|
|
||||
| XXH64 | 13.8 GB/s | 1.9 GB/s |
|
||||
| XXH32 | 6.8 GB/s | 6.0 GB/s |
|
||||
Quality
|
||||
-------------------------
|
||||
|
||||
This project also includes a command line utility, named `xxhsum`, offering similar features to `md5sum`,
|
||||
thanks to [Takayuki Matsuoka](https://github.com/t-mat)'s contributions.
|
||||
Speed is not the only property that matters.
|
||||
Produced hash values must respect excellent dispersion and randomness properties,
|
||||
so that any sub-section of it can be used to maximally spread out a table or index,
|
||||
as well as reduce the amount of collisions to the minimal theoretical level, following the [birthday paradox].
|
||||
|
||||
`xxHash` has been tested with Austin Appleby's excellent SMHasher test suite,
|
||||
and passes all tests, ensuring reasonable quality levels.
|
||||
It also passes extended tests from [newer forks of SMHasher], featuring additional scenarios and conditions.
|
||||
|
||||
Finally, xxHash provides its own [massive collision tester](https://github.com/Cyan4973/xxHash/tree/dev/tests/collisions),
|
||||
able to generate and compare billions of hash to test the limits of 64-bit hash algorithms.
|
||||
On this front too, xxHash features good results, in line with the [birthday paradox].
|
||||
A more detailed analysis is documented [in the wiki](https://github.com/Cyan4973/xxHash/wiki/Collision-ratio-comparison).
|
||||
|
||||
[birthday paradox]: https://en.wikipedia.org/wiki/Birthday_problem
|
||||
[newer forks of SMHasher]: https://github.com/rurban/smhasher
|
||||
|
||||
### License
|
||||
|
||||
@ -64,30 +84,6 @@ The library files `xxhash.c` and `xxhash.h` are BSD licensed.
|
||||
The utility `xxhsum` is GPL licensed.
|
||||
|
||||
|
||||
### New hash algorithms
|
||||
|
||||
Starting with `v0.7.0`, the library includes a new algorithm named `XXH3`,
|
||||
which is able to generate 64 and 128-bit hashes.
|
||||
|
||||
The new algorithm is much faster than its predecessors for both long and small inputs,
|
||||
which can be observed in the following graphs:
|
||||
|
||||
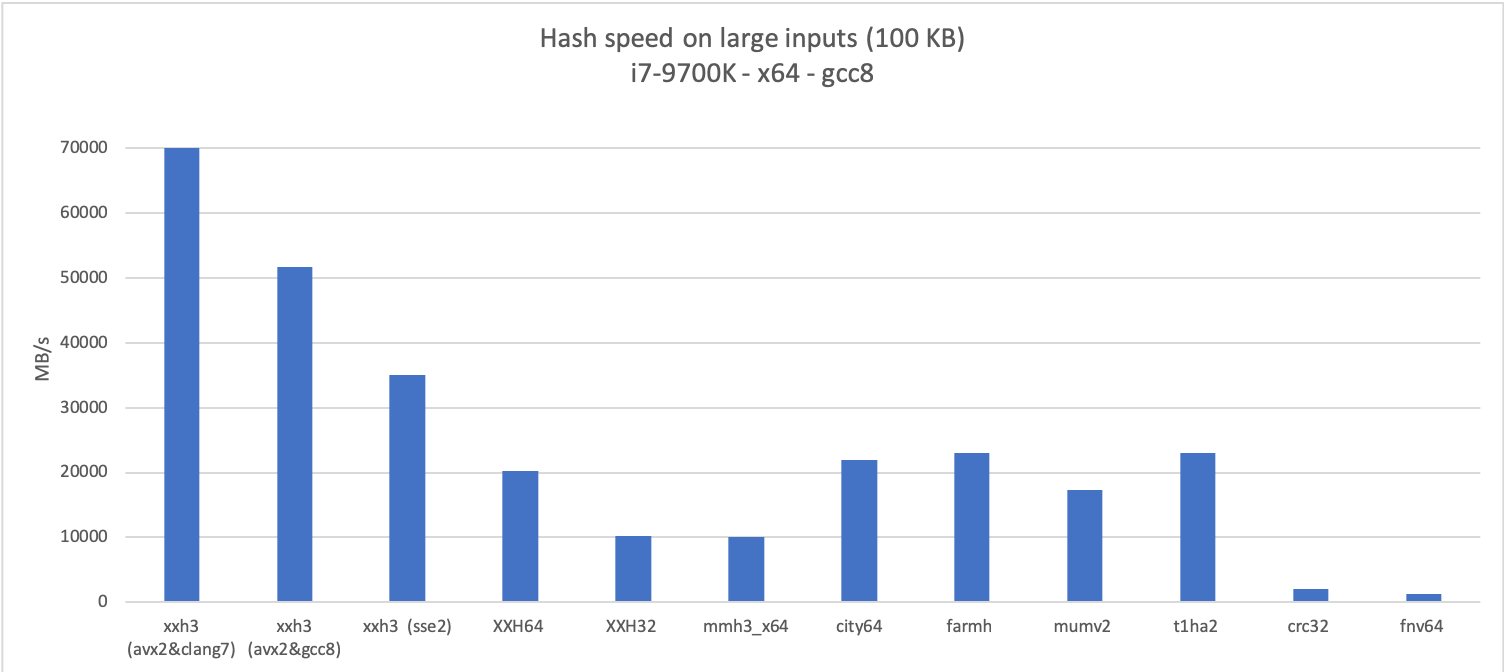
|
||||
|
||||

|
||||
|
||||
To access these new prototypes, one needs to unlock their declaration, using the build macro `XXH_STATIC_LINKING_ONLY`.
|
||||
|
||||
The algorithm is currently in development, meaning its return values might still change in future versions.
|
||||
However, the API is stable, and can be used in production,
|
||||
typically for generation of ephemeral hashes (produced and consumed in same session).
|
||||
|
||||
`XXH3` has now reached "release candidate" status.
|
||||
If everything remains fine, its format will be "frozen" and become final.
|
||||
After which, return values of `XXH3` and `XXH128` will no longer change in future versions.
|
||||
`XXH3`'s return values will be officially finalized upon reaching `v0.8.0`.
|
||||
|
||||
|
||||
### Build modifiers
|
||||
|
||||
The following macros can be set at compilation time to modify libxxhash's behavior. They are generally disabled by default.
|
||||
@ -216,11 +212,7 @@ thanks to many great contributors.
|
||||
They are [listed here](https://www.xxhash.com/#other-languages).
|
||||
|
||||
|
||||
### Branch Policy
|
||||
|
||||
> - The "master" branch is considered stable, at all times.
|
||||
> - The "dev" branch is the one where all contributions must be merged
|
||||
before being promoted to master.
|
||||
> + If you plan to propose a patch, please commit into the "dev" branch,
|
||||
or its own feature branch.
|
||||
Direct commit to "master" are not permitted.
|
||||
### Special Thanks
|
||||
Takayuki Matsuoka, aka @t-mat, for creating `xxhsum -c` and general support during early xxh releases
|
||||
Mathias Westerdahl, aka @JCash, for introducing the first version of `XXH64`
|
||||
Devin Hussey, aka @easyaspi314, for excellent low-level optimizations on `XXH3` and `XXH128`
|
||||
|
||||
Loading…
Reference in New Issue
Block a user