Capstone2LlvmIr library translates given binary data to sequences of LLVM IR instructions. It uses Capstone Engine to disassemble the data into assembly instructions, and then uses C++ routines to generate LLVM IR sequences equivalent to these assembly instructions.
Basic design principle
Assembly instruction translation must be performed by a simple mapping between Capstone instruction and LLVM IR sequence template. Variable template parts are generated using the information about concrete assembly instruction provided by Capstone representation. Complex reasoning about an entire LLVM module, or its modifications beyond the scope of the currently translated instruction must not be performed.
Capstone2LlvmIr's ambitions regarding the scope of translated instructions
Capstone2LlvmIr was implemented to be used in the front-end of the RetDec decompiler. RetDec's goal is to produce high quality C/C++ output that could be easily understood and analyzed by humans. It is meant to ease and speed up manual binary analysis.
Therefore, Capstone2LlvmIr does not aim to fully translate (give meaning/semantics to) all the assembly instructions. In fact, such approach would be counterproductive since many assembly instructions cannot be expressed in reasonably simple C commands. Their full semantics is huge and it would clutter the C output to a point where it would be easier to analyze the original assembly.
Hence, Capstone2LlvmIr aims to translate instructions in these modes:
- Full semantic translation - assembly instruction gets a sequence of LLVM IR instructions that should ideally capture its full semantics. Only done for simple enough instructions (often from the core instruction set).
- Translation to intrinsic functions - assembly instruction gets an intrinsic function call. Parameters and return values are fully handled. Intrinsics are taken/inspired from/by functions internally used by various compilers - they are relatively well-known, or self-explanatory.
- Translation to pseudo assembly call - assembly instruction gets a call to a function automatically generated from the Capstone's instruction representation. Function name is derived from instruction name, e.g.
add->__asm_add(). Parameters and return values rely on information provided by Capstone, i.e. might be off. - No translation - sometimes we choose to ignore instruction.
Decompilation is one thing, but if someone would like to use RetDec framework for other purposes, he/she might want to have semantics for even very complex instructions. Right now, we would say that projects like QEMU or McSema are a better alternative in such a case. However, it might happen that someone will add complex semantics to Capstone2LlvmIr on their own - we currently have no such plans. This would not be easy, but if good groundworks were prepared, it might not be so bad. After all, someone had to hand-write these things in QEMU as well. Even if this happens, it would not be beneficial for decompilation (as already explained). So we would either have to keep these Capstone2LlvmIr translators separate, or have it all in one translator but be able to tell it what should and should not be translated - or which mode to use for which instruction.
General library structure
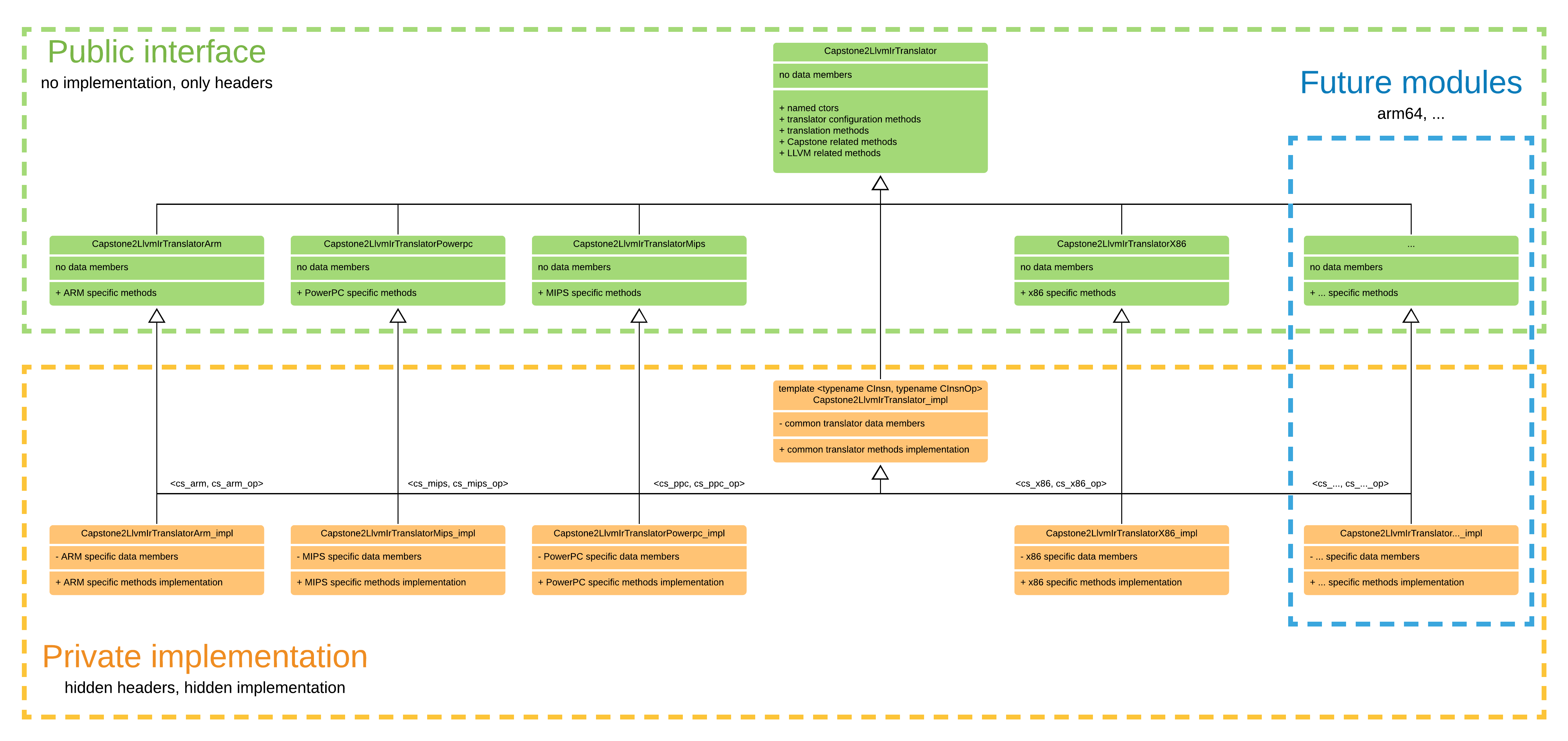
There are several ways we can divide the library:
- Public vs. hidden parts:
- Public interface headers in
include/retdec/capstone2llvmir: all that library users need to see, no implementation, no data members, only the interface provided by the hidden implementation. - Hidden implementation in
src/capstone2llvmir: hidden headers and implementation source files.
- Public interface headers in
- Generic translators vs. concrete architecture modules:
- Generic public translator with common translation interface (i.e.
Capstone2LlvmIrTranslator). - Generic hidden translator implementation with common functionality (i.e.
Capstone2LlvmIrTranslator_impl). - Architecture specific public translator headers with architecture specific extensions (e.g.
Capstone2LlvmIrTranslatorArm). - Architecture specific hidden translator implementation with architecture specific functionality (e.g.
Capstone2LlvmIrTranslatorArm_impl).
- Generic public translator with common translation interface (i.e.
- Individual architecture specific implementation modules - these are the final translators that contain all the functionality to translate the given architecture.
How to use Capstone2LlvmIr library
See comments in public headers for public interface documentation.
See Capstone2LlvmIrTool or Bin2LlvmIr's decoder module for examples of Capstone2LlvmIr usage.
How Capstone2LlvmIr library works
All architecture specific modules work basically the same. We demonstrate the process on translation of two x86 instructions add eax, 0x1234 and je 0x1000.
First, translator module for the given architecture (x86 in this case) is created. It triggers the following actions:
-
Constructor accepts an LLVM IR module. Translator expects it to be empty, passing a non-empty module causes an undefined behavior.
-
Constructor initializes Capstone engine, and other internal structures it needs in order to work.
-
Constructor creates an architecture-specific environment in the given LLVM IR module:
- Special assembly to LLVM IR mapping global variable.
@_asm_program_counter = internal global i64 0Stores to this global are special - they always store integer values that denote an address of assembly instruction to which the subsequent LLVM IR sequence corresponds (i.e. from which it was created).
@_asm_program_counter = internal global i64 0 ; ... ; add eax, 0x1234 @ 0x1000 store volatile i64 4096, i64* @_asm_program_counter ; ... LLVM IR sequence for the add instruction ; sub ebx, 0x1234 @ 0x1005 store volatile i64 4101, i64* @_asm_program_counter ; ... LLVM IR sequence for the sub instruction- Control-flow-related pseudo functions are generated.
; void (i<architecture_size> target_address) declare void @__pseudo_call(i32) ; void (i<architecture_size> target_address) declare void @__pseudo_return(i32) ; void (i<architecture_size> target_address) declare void @__pseudo_branch(i32) ; void (i1 condition, i<architecture_size> target_address) declare void @__pseudo_cond_branch(i1, i32)These denote control-flow-changing operations - call, return, branch, conditional branch. All these operations have their equivalent instructions in LLVM IR, but we do not use them and generate calls to these pseudo functions instead. The problem with LLVM IR control flow instruction is that they require target labels to branch to - they do not accept targets in a form of integer addresses. Properly creating labels require complex reasoning about control flow in the entire module, and modifications of module outside the scope of sequence that is currently being generated - both go against the basic Capstone2LlvmIr design principle. These processes are to be performed by Capstone2LlvmIr users. In other words, Capstone2LlvmIr generates a semi-finished product that needs to be further analysed and modified.
- Architecture specific registers - all registers that the architecture contains are generated as global variables. E.g. for x86:
@eax = internal global i32 0 @ecx = internal global i32 0 ; ... @st0 = internal global x86_fp80 0xK00000000000000000000 @st1 = internal global x86_fp80 0xK00000000000000000000 ; ...- Architecture specific data layout.
- Architecture-specific environment. E.g. pseudo functions used in x86 FPU semantic model.
Second, translator can be used to translate the given binary data, of a given size, on a given address, and place the result at the given position in the LLVM IR module.
Translating data 05 34 12 00 00 of size 5 at address 0x1000, and placing the result at the beginning of entry_point function, x86 translator does the following:
- Disassemble
05 34 12 00 00using Capstone engine intoadd eax, 0x1234. Capstone does not provide only this text representation of an instruction, but various internal structures containing all the necessary information about the instruction. E.g. foradd eax, 0x1234:
General info:
id : 8 (add)
addr : 1000
size : 5
bytes : 05 34 12 00 00
mnem : add
op str : eax, 0x1234
Detail info:
R regs : 0
W regs : 1
25 (eflags)
groups : 0
Architecture-dependent info:
prefix : 00 00 00 00 (-, -, -, -)
opcode : 05 00 00 00
rex : 0
addr sz: 4
modrm : 0
sib : 0
disp : 0
sib idx: 0 (-)
sib sc : 0
sib bs : 0 (-)
sse cc : X86_SSE_CC_INVALID
avx cc : X86_AVX_CC_INVALID
avx sae: false
avx rm : X86_AVX_RM_INVALID
op cnt : 2
type : X86_OP_REG
reg : 19 (eax)
size : 4
access : CS_AC_READ + CS_AC_WRITE
avx bct: X86_AVX_BCAST_INVALID
avx 0 m: false
type : X86_OP_IMM
imm : 1234
size : 4
access : CS_AC_INVALID
avx bct: X86_AVX_BCAST_INVALID
avx 0 m: false
- Find translation routine that implements LLVM IR sequence template for the given Capstone assembly instruction (
X86_INS_ADDin this case). Every translator module defines a map that may assign a translation routine to Capstone instruction ID:capstone_insn_id -> translation_routine. There are the following three possibilities (corresponding to Capstone2LlvmIr's instruction translating modes, see the discussion above):- Capstone ID is mapped to an ID-specific routine. The routine implements either a full instruction semantics, or instruction-specific intrinsic call. Sometimes, if their behavior is similar, more IDs are mapped to the same routine.
- Capstone ID is mapped to a specific pseudo assembly generation method. These methods semi-automatically generate calls to pseudo assembly functions - they use Capstone-provided instruction info (i.e. operands), but use this info to generate a specific predefined pattern. The instruction's data flow is therefore explicitly stated and not guessed. Examples of such functions:
__asm_<mnem>(op0) op0 = __asm_<mnem>(op0) __asm_<mnem>(op0, op1) op0 = __asm_<mnem>(op1) op0 = __asm_<mnem>(op0, op1) __asm_<mnem>(op0, op1, op2) ...- Capstone ID is not mapped to any value (
nullptr). If the translator is set to automatically generate pseudo assembly calls (as it is by default), it uses Capstone-provided instruction info to autonomously create such calls. The process is fully dependent on the quality of information provided by Capstone.
- Execute the selected routine. For our example, LLVM module after translation would look like this:
@eax = internal global i32 0
@ecx = internal global i32 0
; ...
declare void @__pseudo_call(i32)
declare void @__pseudo_cond_branch(i1, i32)
; ...
@_asm_program_counter = internal global i64 0
define void @entry_point() {
entry:
; add eax, 0x1234 @ 0x1000
store volatile i64 4096, i64* @_asm_program_counter
%0 = load i32, i32* @eax
%1 = add i32 %0, 4660 ; eax + 0x1234
%2 = and i32 %0, 15
%3 = add i32 %2, 4
%4 = icmp ugt i32 %3, 15
%5 = icmp ult i32 %1, %0
%6 = xor i32 %0, %1
%7 = xor i32 4660, %1
%8 = and i32 %6, %7
%9 = icmp slt i32 %8, 0
store i1 %4, i1* @az
store i1 %5, i1* @cf
store i1 %9, i1* @of
%10 = icmp eq i32 %1, 0
store i1 %10, i1* @zf
%11 = icmp slt i32 %1, 0
store i1 %11, i1* @sf
%12 = trunc i32 %1 to i8
%13 = call i8 @llvm.ctpop.i8(i8 %12)
%14 = and i8 %13, 1
%15 = icmp eq i8 %14, 0
store i1 %15, i1* @pf
store i32 %1, i32* @eax
ret void
}
We can see that the LLVM IR sequence describes the full semantics - not only addition itself, but also implicit flag settings.
Translating data 74 f9 (i.e. je 0x1000) of size 2 at address 0x1005, and placing the result after the previously translated sequence does the same steps as before. The LLVM module after translation would look like this:
@eax = internal global i32 0
@ecx = internal global i32 0
; ...
declare void @__pseudo_call(i32)
declare void @__pseudo_cond_branch(i1, i32)
; ...
@_asm_program_counter = internal global i64 0
define void @entry_point() {
entry:
; add eax, 0x1234 @ 0x1000
store volatile i64 4096, i64* @_asm_program_counter
%0 = load i32, i32* @eax
%1 = add i32 %0, 4660 ; eax + 0x1234
; ...
store i32 %1, i32* @eax
; je 0x1000 @ 0x1005
store volatile i64 4101, i64* @_asm_program_counter
%0 = load i1, i1* @zf
call void @__pseudo_cond_branch(i1 %0, i32 4096)
ret void
}
Note that control-flow-related pseudo function was generated instead of LLVM's br instruction. This allowed us not to create label at branch target address 0x1000 and therefore not modify the module beyond the scope of currently translated instruction je 0x1000.
Capstone2LlvmIr library development
Currently, the members of RetDec team work on the following areas:
- Support for advanced x86 extension sets (MMX, SSEx, etc.).
If you would like to help, please contact us. Possible tasks range from simple tagging of unhandled instructions with specific pseudo assembly generation methods, through intermediate full semantic modeling, to writing entire modules for unsupported architectures.