Compare commits
205 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
34cd281494 | ||
|
|
99cf03a50a | ||
|
|
b36a339a65 | ||
|
|
442cb47fc9 | ||
|
|
b7795c7df1 | ||
|
|
ac161de968 | ||
|
|
d91944bb07 | ||
|
|
8798bd3105 | ||
|
|
621eea5d93 | ||
|
|
b6590a8745 | ||
|
|
458ffa70ea | ||
|
|
ebe5c117c2 | ||
|
|
adff80af11 | ||
|
|
301837e303 | ||
|
|
4f1d922a6e | ||
|
|
e4e26a3b8e | ||
|
|
7f82761813 | ||
|
|
7e16b6daa6 | ||
|
|
22d279a25c | ||
|
|
357ada3867 | ||
|
|
ab2d93ac6d | ||
|
|
53f727af64 | ||
|
|
820af98418 | ||
|
|
857f41882f | ||
|
|
381ada5cbe | ||
|
|
32a532f269 | ||
|
|
d0acf0ee26 | ||
|
|
bec40d90ef | ||
|
|
c80e959b05 | ||
|
|
2007f68302 | ||
|
|
aad9045bcb | ||
|
|
3b86e9f0b5 | ||
|
|
c1c5585d3a | ||
|
|
c45993617b | ||
|
|
d13b33e956 | ||
|
|
20a4aee5c1 | ||
|
|
4139ac8632 | ||
|
|
89be01737d | ||
|
|
29e4e878a4 | ||
|
|
ffc2832088 | ||
|
|
8b5feab7b2 | ||
|
|
a805c985a6 | ||
|
|
c0ac497ed4 | ||
|
|
a0ea197b28 | ||
|
|
74b11de9ae | ||
|
|
c2b70436e5 | ||
|
|
af9a9800e5 | ||
|
|
e7bac2cbb8 | ||
|
|
d595394243 | ||
|
|
27efb7b53c | ||
|
|
0c1fe17417 | ||
|
|
3f308e7ae4 | ||
|
|
c85a17bac2 | ||
|
|
a91672f619 | ||
|
|
81daa09d05 | ||
|
|
07be2e4555 | ||
|
|
4a642d576a | ||
|
|
8ee7108302 | ||
|
|
a9461af96f | ||
|
|
4d42a32342 | ||
|
|
21add2715b | ||
|
|
3ded353c5a | ||
|
|
b619226480 | ||
|
|
612f9346c5 | ||
|
|
90bec45008 | ||
|
|
5157e30fe7 | ||
|
|
eb2d9e2b63 | ||
|
|
09d214522f | ||
|
|
8798735ea4 | ||
|
|
7ed859c068 | ||
|
|
417e6faccf | ||
|
|
aeae13ba63 | ||
|
|
825d8ec9bb | ||
|
|
44a5c3530a | ||
|
|
14de11a420 | ||
|
|
b15620ee9c | ||
|
|
13e7f2df0a | ||
|
|
888fce5060 | ||
|
|
148a3e4f89 | ||
|
|
0e10f3227f | ||
|
|
b0667043ea | ||
|
|
bd5eac5abd | ||
|
|
dbb85200ac | ||
|
|
c1023a14b8 | ||
|
|
8899acc989 | ||
|
|
c0e7f51626 | ||
|
|
9f827eaca5 | ||
|
|
d9fc08b05c | ||
|
|
8a5ba6d575 | ||
|
|
8204930f2b | ||
|
|
013fe6a153 | ||
|
|
01ffffd04c | ||
|
|
4ddbbc0ff8 | ||
|
|
5ffdbb5c4c | ||
|
|
30530883d4 | ||
|
|
9284a7c4f4 | ||
|
|
646aaab6c1 | ||
|
|
d61eaf683d | ||
|
|
4a528670f6 | ||
|
|
d6addec366 | ||
|
|
314627635b | ||
|
|
6c3dcb6c11 | ||
|
|
f912841118 | ||
|
|
55ea29817c | ||
|
|
9e911d1d3e | ||
|
|
cc30612d12 | ||
|
|
c6b6181302 | ||
|
|
8f4321c06b | ||
|
|
5b153a64ce | ||
|
|
bd2123f4a8 | ||
|
|
a585ad7e93 | ||
|
|
30aa706d9c | ||
|
|
99a54c49e5 | ||
|
|
d7ae76cf66 | ||
|
|
d8d63cbc4c | ||
|
|
22b83afb72 | ||
|
|
e6fd329869 | ||
|
|
ca14a4ef3b | ||
|
|
97b2c28d09 | ||
|
|
1130f60d40 | ||
|
|
b7dcec1773 | ||
|
|
7fca17e14d | ||
|
|
bb7a461a57 | ||
|
|
5edf648440 | ||
|
|
bb484906d2 | ||
|
|
a1e774ea7a | ||
|
|
ed357c9924 | ||
|
|
c1b0cf9851 | ||
|
|
32ae959be5 | ||
|
|
a5caa1c13a | ||
|
|
eb5e761a33 | ||
|
|
ae5064fe94 | ||
|
|
9b6c0c6d39 | ||
|
|
dd9cf5e69a | ||
|
|
a9bf422a15 | ||
|
|
37be748aa7 | ||
|
|
ca845ca821 | ||
|
|
dfc6c57347 | ||
|
|
b59722eda4 | ||
|
|
7253b433a3 | ||
|
|
fd0203c7b8 | ||
|
|
b3aee9d5a2 | ||
|
|
d99756a91f | ||
|
|
029866786d | ||
|
|
12e03473b0 | ||
|
|
e07ac06b30 | ||
|
|
c3504851da | ||
|
|
abde07e167 | ||
|
|
3b0e6e1d61 | ||
|
|
e6ddfbf892 | ||
|
|
50624008bb | ||
|
|
3d731bf937 | ||
|
|
0989f96d2d | ||
|
|
0abb4f00b9 | ||
|
|
f79d7972bf | ||
|
|
5f2ce54b40 | ||
|
|
65aeb987b0 | ||
|
|
d9582803f8 | ||
|
|
f80989adb1 | ||
|
|
d58e43eed3 | ||
|
|
ca0eb25694 | ||
|
|
107fac52ad | ||
|
|
191bcf4f73 | ||
|
|
71d6c11b52 | ||
|
|
e4011747fa | ||
|
|
7d62b785df | ||
|
|
7f567f3140 | ||
|
|
bdbbad10f8 | ||
|
|
3a2ef54953 | ||
|
|
9894475bb6 | ||
|
|
7b6823db0f | ||
|
|
6621080197 | ||
|
|
7dccb2d34b | ||
|
|
3ca8ea1ea2 | ||
|
|
0ca3985875 | ||
|
|
cb8f2749d5 | ||
|
|
ddcd05cb54 | ||
|
|
c0533a6a1c | ||
|
|
ac7cc33bbd | ||
|
|
be952a11a3 | ||
|
|
7097a09e1c | ||
|
|
e9c3ad0c9d | ||
|
|
d4b39abcec | ||
|
|
e38eea445d | ||
|
|
1ec3c10c25 | ||
|
|
38855038a5 | ||
|
|
2db4665d36 | ||
|
|
e29dac5725 | ||
|
|
3a60b6db37 | ||
|
|
8d2b42b6ac | ||
|
|
b8c3037d5f | ||
|
|
08443361ce | ||
|
|
f37cb447a9 | ||
|
|
2a66acc564 | ||
|
|
2178668d74 | ||
|
|
eff227bd14 | ||
|
|
163caa6167 | ||
|
|
15f81cf7fa | ||
|
|
58d6cd3004 | ||
|
|
343063680d | ||
|
|
64445e75ee | ||
|
|
f60390a542 | ||
|
|
3a4803fb5a | ||
|
|
7ad24abfca | ||
|
|
fea7a89f13 |
@@ -0,0 +1,91 @@
|
||||
# An action for setting up poetry install with caching.
|
||||
# Using a custom action since the default action does not
|
||||
# take poetry install groups into account.
|
||||
# Action code from:
|
||||
# https://github.com/actions/setup-python/issues/505#issuecomment-1273013236
|
||||
name: poetry-install-with-caching
|
||||
description: Poetry install with support for caching of dependency groups.
|
||||
|
||||
inputs:
|
||||
python-version:
|
||||
description: Python version, supporting MAJOR.MINOR only
|
||||
required: true
|
||||
|
||||
poetry-version:
|
||||
description: Poetry version
|
||||
required: true
|
||||
|
||||
cache-key:
|
||||
description: Cache key to use for manual handling of caching
|
||||
required: true
|
||||
|
||||
working-directory:
|
||||
description: Directory whose poetry.lock file should be cached
|
||||
required: true
|
||||
|
||||
runs:
|
||||
using: composite
|
||||
steps:
|
||||
- uses: actions/setup-python@v4
|
||||
name: Setup python ${{ inputs.python-version }}
|
||||
with:
|
||||
python-version: ${{ inputs.python-version }}
|
||||
|
||||
- uses: actions/cache@v3
|
||||
id: cache-bin-poetry
|
||||
name: Cache Poetry binary - Python ${{ inputs.python-version }}
|
||||
env:
|
||||
SEGMENT_DOWNLOAD_TIMEOUT_MIN: "1"
|
||||
with:
|
||||
path: |
|
||||
/opt/pipx/venvs/poetry
|
||||
# This step caches the poetry installation, so make sure it's keyed on the poetry version as well.
|
||||
key: bin-poetry-${{ runner.os }}-${{ runner.arch }}-py-${{ inputs.python-version }}-${{ inputs.poetry-version }}
|
||||
|
||||
- name: Refresh shell hashtable and fixup softlinks
|
||||
if: steps.cache-bin-poetry.outputs.cache-hit == 'true'
|
||||
shell: bash
|
||||
env:
|
||||
POETRY_VERSION: ${{ inputs.poetry-version }}
|
||||
PYTHON_VERSION: ${{ inputs.python-version }}
|
||||
run: |
|
||||
set -eux
|
||||
|
||||
# Refresh the shell hashtable, to ensure correct `which` output.
|
||||
hash -r
|
||||
|
||||
# `actions/cache@v3` doesn't always seem able to correctly unpack softlinks.
|
||||
# Delete and recreate the softlinks pipx expects to have.
|
||||
rm /opt/pipx/venvs/poetry/bin/python
|
||||
cd /opt/pipx/venvs/poetry/bin
|
||||
ln -s "$(which "python$PYTHON_VERSION")" python
|
||||
chmod +x python
|
||||
cd /opt/pipx_bin/
|
||||
ln -s /opt/pipx/venvs/poetry/bin/poetry poetry
|
||||
chmod +x poetry
|
||||
|
||||
# Ensure everything got set up correctly.
|
||||
/opt/pipx/venvs/poetry/bin/python --version
|
||||
/opt/pipx_bin/poetry --version
|
||||
|
||||
- name: Install poetry
|
||||
if: steps.cache-bin-poetry.outputs.cache-hit != 'true'
|
||||
shell: bash
|
||||
env:
|
||||
POETRY_VERSION: ${{ inputs.poetry-version }}
|
||||
PYTHON_VERSION: ${{ inputs.python-version }}
|
||||
run: pipx install "poetry==$POETRY_VERSION" --python "python$PYTHON_VERSION" --verbose
|
||||
|
||||
- name: Restore pip and poetry cached dependencies
|
||||
uses: actions/cache@v3
|
||||
env:
|
||||
SEGMENT_DOWNLOAD_TIMEOUT_MIN: "4"
|
||||
WORKDIR: ${{ inputs.working-directory == '' && '.' || inputs.working-directory }}
|
||||
with:
|
||||
path: |
|
||||
~/.cache/pip
|
||||
~/.cache/pypoetry/virtualenvs
|
||||
~/.cache/pypoetry/cache
|
||||
~/.cache/pypoetry/artifacts
|
||||
${{ env.WORKDIR }}/.venv
|
||||
key: py-deps-${{ runner.os }}-${{ runner.arch }}-py-${{ inputs.python-version }}-poetry-${{ inputs.poetry-version }}-${{ inputs.cache-key }}-${{ hashFiles(format('{0}/**/poetry.lock', env.WORKDIR)) }}
|
||||
@@ -0,0 +1,83 @@
|
||||
name: lint
|
||||
|
||||
on:
|
||||
workflow_call:
|
||||
inputs:
|
||||
working-directory:
|
||||
required: true
|
||||
type: string
|
||||
description: "From which folder this pipeline executes"
|
||||
|
||||
env:
|
||||
POETRY_VERSION: "1.6.1"
|
||||
WORKDIR: ${{ inputs.working-directory == '' && '.' || inputs.working-directory }}
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
# This number is set "by eye": we want it to be big enough
|
||||
# so that it's bigger than the number of commits in any reasonable PR,
|
||||
# and also as small as possible since increasing the number makes
|
||||
# the initial `git fetch` slower.
|
||||
FETCH_DEPTH: 50
|
||||
strategy:
|
||||
matrix:
|
||||
# Only lint on the min and max supported Python versions.
|
||||
# It's extremely unlikely that there's a lint issue on any version in between
|
||||
# that doesn't show up on the min or max versions.
|
||||
#
|
||||
# GitHub rate-limits how many jobs can be running at any one time.
|
||||
# Starting new jobs is also relatively slow,
|
||||
# so linting on fewer versions makes CI faster.
|
||||
python-version:
|
||||
- "3.8"
|
||||
- "3.11"
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Set up Python ${{ matrix.python-version }} + Poetry ${{ env.POETRY_VERSION }}
|
||||
uses: "./.github/actions/poetry_setup"
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
poetry-version: ${{ env.POETRY_VERSION }}
|
||||
working-directory: ${{ inputs.working-directory }}
|
||||
cache-key: lint-with-extras
|
||||
|
||||
- name: Check Poetry File
|
||||
shell: bash
|
||||
working-directory: ${{ inputs.working-directory }}
|
||||
run: |
|
||||
poetry check
|
||||
|
||||
- name: Check lock file
|
||||
shell: bash
|
||||
working-directory: ${{ inputs.working-directory }}
|
||||
run: |
|
||||
poetry lock --check
|
||||
|
||||
- name: Install dependencies
|
||||
# Also installs dev/lint/test/typing dependencies, to ensure we have
|
||||
# type hints for as many of our libraries as possible.
|
||||
# This helps catch errors that require dependencies to be spotted, for example:
|
||||
# https://github.com/langchain-ai/langchain/pull/10249/files#diff-935185cd488d015f026dcd9e19616ff62863e8cde8c0bee70318d3ccbca98341
|
||||
#
|
||||
# If you change this configuration, make sure to change the `cache-key`
|
||||
# in the `poetry_setup` action above to stop using the old cache.
|
||||
# It doesn't matter how you change it, any change will cause a cache-bust.
|
||||
working-directory: ${{ inputs.working-directory }}
|
||||
run: |
|
||||
poetry install --with dev,lint,test,typing
|
||||
|
||||
- name: Get .mypy_cache to speed up mypy
|
||||
uses: actions/cache@v3
|
||||
env:
|
||||
SEGMENT_DOWNLOAD_TIMEOUT_MIN: "2"
|
||||
with:
|
||||
path: |
|
||||
${{ env.WORKDIR }}/.mypy_cache
|
||||
key: mypy-${{ runner.os }}-${{ runner.arch }}-py${{ matrix.python-version }}-${{ inputs.working-directory }}-${{ hashFiles(format('{0}/poetry.lock', env.WORKDIR)) }}
|
||||
|
||||
- name: Analysing the code with our lint
|
||||
working-directory: ${{ inputs.working-directory }}
|
||||
run: |
|
||||
make lint
|
||||
@@ -0,0 +1,63 @@
|
||||
name: release
|
||||
|
||||
on:
|
||||
workflow_call:
|
||||
inputs:
|
||||
working-directory:
|
||||
required: true
|
||||
type: string
|
||||
description: "From which folder this pipeline executes"
|
||||
|
||||
env:
|
||||
POETRY_VERSION: "1.6.1"
|
||||
|
||||
jobs:
|
||||
if_release:
|
||||
# Disallow publishing from branches that aren't `main`.
|
||||
if: github.ref == 'refs/heads/main'
|
||||
runs-on: ubuntu-latest
|
||||
permissions:
|
||||
# This permission is used for trusted publishing:
|
||||
# https://blog.pypi.org/posts/2023-04-20-introducing-trusted-publishers/
|
||||
#
|
||||
# Trusted publishing has to also be configured on PyPI for each package:
|
||||
# https://docs.pypi.org/trusted-publishers/adding-a-publisher/
|
||||
id-token: write
|
||||
|
||||
# This permission is needed by `ncipollo/release-action` to create the GitHub release.
|
||||
contents: write
|
||||
defaults:
|
||||
run:
|
||||
working-directory: ${{ inputs.working-directory }}
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
|
||||
- name: Set up Python + Poetry ${{ env.POETRY_VERSION }}
|
||||
uses: "./.github/actions/poetry_setup"
|
||||
with:
|
||||
python-version: "3.10"
|
||||
poetry-version: ${{ env.POETRY_VERSION }}
|
||||
working-directory: ${{ inputs.working-directory }}
|
||||
cache-key: release
|
||||
|
||||
- name: Build project for distribution
|
||||
run: poetry build
|
||||
- name: Check Version
|
||||
id: check-version
|
||||
run: |
|
||||
echo version=$(poetry version --short) >> $GITHUB_OUTPUT
|
||||
- name: Create Release
|
||||
uses: ncipollo/release-action@v1
|
||||
with:
|
||||
artifacts: "dist/*"
|
||||
token: ${{ secrets.GITHUB_TOKEN }}
|
||||
draft: false
|
||||
generateReleaseNotes: true
|
||||
tag: v${{ steps.check-version.outputs.version }}
|
||||
commit: main
|
||||
- name: Publish package distributions to PyPI
|
||||
uses: pypa/gh-action-pypi-publish@release/v1
|
||||
with:
|
||||
packages-dir: ${{ inputs.working-directory }}/dist/
|
||||
verbose: true
|
||||
print-hash: true
|
||||
@@ -0,0 +1,57 @@
|
||||
name: test
|
||||
|
||||
on:
|
||||
workflow_call:
|
||||
inputs:
|
||||
working-directory:
|
||||
required: true
|
||||
type: string
|
||||
description: "From which folder this pipeline executes"
|
||||
|
||||
env:
|
||||
POETRY_VERSION: "1.6.1"
|
||||
|
||||
jobs:
|
||||
build:
|
||||
defaults:
|
||||
run:
|
||||
working-directory: ${{ inputs.working-directory }}
|
||||
runs-on: ubuntu-latest
|
||||
strategy:
|
||||
matrix:
|
||||
python-version:
|
||||
- "3.8"
|
||||
- "3.9"
|
||||
- "3.10"
|
||||
- "3.11"
|
||||
name: Python ${{ matrix.python-version }}
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }} + Poetry ${{ env.POETRY_VERSION }}
|
||||
uses: "./.github/actions/poetry_setup"
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
poetry-version: ${{ env.POETRY_VERSION }}
|
||||
working-directory: ${{ inputs.working-directory }}
|
||||
cache-key: core
|
||||
|
||||
- name: Install dependencies
|
||||
shell: bash
|
||||
run: poetry install
|
||||
|
||||
- name: Run core tests
|
||||
shell: bash
|
||||
run: make test
|
||||
|
||||
- name: Ensure the tests did not create any additional files
|
||||
shell: bash
|
||||
run: |
|
||||
set -eu
|
||||
|
||||
STATUS="$(git status)"
|
||||
echo "$STATUS"
|
||||
|
||||
# grep will exit non-zero if the target message isn't found,
|
||||
# and `set -e` above will cause the step to fail.
|
||||
echo "$STATUS" | grep 'nothing to commit, working tree clean'
|
||||
@@ -0,0 +1,144 @@
|
||||
---
|
||||
name: Run CI Tests
|
||||
|
||||
on:
|
||||
push:
|
||||
branches: [ main ]
|
||||
pull_request:
|
||||
paths-ignore:
|
||||
- 'README.md'
|
||||
workflow_dispatch: # Allows to trigger the workflow manually in GitHub UI
|
||||
|
||||
# If another push to the same PR or branch happens while this workflow is still running,
|
||||
# cancel the earlier run in favor of the next run.
|
||||
#
|
||||
# There's no point in testing an outdated version of the code. GitHub only allows
|
||||
# a limited number of job runners to be active at the same time, so it's better to cancel
|
||||
# pointless jobs early so that more useful jobs can run sooner.
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.ref }}
|
||||
cancel-in-progress: true
|
||||
|
||||
env:
|
||||
POETRY_VERSION: "1.5.1"
|
||||
WORKDIR: "."
|
||||
|
||||
jobs:
|
||||
lint:
|
||||
uses:
|
||||
./.github/workflows/_lint.yml
|
||||
with:
|
||||
working-directory: .
|
||||
secrets: inherit
|
||||
|
||||
test:
|
||||
timeout-minutes: 5
|
||||
runs-on: ubuntu-latest
|
||||
defaults:
|
||||
run:
|
||||
working-directory: ${{ env.WORKDIR }}
|
||||
strategy:
|
||||
matrix:
|
||||
python-version:
|
||||
- "3.8"
|
||||
- "3.9"
|
||||
- "3.10"
|
||||
- "3.11"
|
||||
name: Python ${{ matrix.python-version }} tests
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }} + Poetry ${{ env.POETRY_VERSION }}
|
||||
uses: "./.github/actions/poetry_setup"
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
poetry-version: ${{ env.POETRY_VERSION }}
|
||||
working-directory: .
|
||||
cache-key: benchmarks-all
|
||||
|
||||
- name: Install dependencies
|
||||
shell: bash
|
||||
run: |
|
||||
echo "Running tests, installing dependencies with poetry..."
|
||||
poetry install --with test,lint,typing,docs
|
||||
|
||||
- name: Run tests
|
||||
run: make test
|
||||
|
||||
- name: Ensure the tests did not create any additional files
|
||||
shell: bash
|
||||
run: |
|
||||
set -eu
|
||||
|
||||
STATUS="$(git status)"
|
||||
echo "$STATUS"
|
||||
|
||||
# grep will exit non-zero if the target message isn't found,
|
||||
# and `set -e` above will cause the step to fail.
|
||||
echo "$STATUS" | grep 'nothing to commit, working tree clean'
|
||||
test_docs:
|
||||
timeout-minutes: 5
|
||||
runs-on: ubuntu-latest
|
||||
defaults:
|
||||
run:
|
||||
working-directory: ${{ env.WORKDIR }}
|
||||
strategy:
|
||||
matrix:
|
||||
python-version:
|
||||
- "3.11"
|
||||
name: Documentation Build for Python ${{ matrix.python-version }}
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }} + Poetry ${{ env.POETRY_VERSION }}
|
||||
uses: "./.github/actions/poetry_setup"
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
poetry-version: ${{ env.POETRY_VERSION }}
|
||||
working-directory: .
|
||||
cache-key: benchmarks-all
|
||||
|
||||
- name: Install dependencies
|
||||
shell: bash
|
||||
run: |
|
||||
echo "Running tests, installing dependencies with poetry..."
|
||||
poetry install --with test,lint,typing,docs
|
||||
|
||||
- name: Test Sphinx Docs
|
||||
shell: bash
|
||||
run: |
|
||||
echo "Attempting to build docs..."
|
||||
make docs_build
|
||||
test_datasets:
|
||||
timeout-minutes: 5
|
||||
runs-on: ubuntu-latest
|
||||
defaults:
|
||||
run:
|
||||
working-directory: ${{ env.WORKDIR }}
|
||||
strategy:
|
||||
matrix:
|
||||
python-version:
|
||||
- "3.11"
|
||||
name: Validate Public Datasets
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }} + Poetry ${{ env.POETRY_VERSION }}
|
||||
uses: "./.github/actions/poetry_setup"
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
poetry-version: ${{ env.POETRY_VERSION }}
|
||||
working-directory: .
|
||||
cache-key: benchmarks-all
|
||||
|
||||
- name: Install dependencies
|
||||
shell: bash
|
||||
run: |
|
||||
echo "Running tests, installing dependencies with poetry..."
|
||||
poetry install --with test,lint,typing,docs
|
||||
|
||||
- name: Request datasets
|
||||
shell: bash
|
||||
run: |
|
||||
echo "Attempting to build docs..."
|
||||
poetry run python -m scripts.check_datasets
|
||||
@@ -0,0 +1,44 @@
|
||||
name: Publish Docs
|
||||
on: [workflow_dispatch]
|
||||
permissions:
|
||||
contents: write
|
||||
|
||||
env:
|
||||
POETRY_VERSION: "1.6.1"
|
||||
|
||||
jobs:
|
||||
docs:
|
||||
strategy:
|
||||
matrix:
|
||||
python-version:
|
||||
- "3.11"
|
||||
runs-on: ubuntu-latest
|
||||
name: Documentation Publish
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }} + Poetry ${{ env.POETRY_VERSION }}
|
||||
uses: "./.github/actions/poetry_setup"
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
poetry-version: ${{ env.POETRY_VERSION }}
|
||||
working-directory: .
|
||||
cache-key: benchmarks-all
|
||||
|
||||
- name: Install dependencies
|
||||
shell: bash
|
||||
run: |
|
||||
echo "Running tests, installing dependencies with poetry..."
|
||||
poetry install --with test,lint,typing,docs
|
||||
|
||||
- name: Sphinx build
|
||||
shell: bash
|
||||
run: |
|
||||
make docs_build
|
||||
- name: Publish Docs
|
||||
uses: peaceiris/actions-gh-pages@v3
|
||||
with:
|
||||
publish_branch: gh-pages
|
||||
github_token: ${{ secrets.GITHUB_TOKEN }}
|
||||
publish_dir: ./docs/build
|
||||
force_orphan: true
|
||||
@@ -0,0 +1,14 @@
|
||||
---
|
||||
name: Publish Package to PyPi
|
||||
|
||||
on:
|
||||
workflow_dispatch: # Allows to trigger the workflow manually in GitHub UI
|
||||
|
||||
jobs:
|
||||
release:
|
||||
uses:
|
||||
./.github/workflows/_release.yml
|
||||
permissions: write-all
|
||||
with:
|
||||
working-directory: .
|
||||
secrets: inherit
|
||||
@@ -0,0 +1,44 @@
|
||||
name: Weekly Tool Benchmarks
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
schedule:
|
||||
- cron: '0 0 * * 0' # Runs at midnight (00:00) every Sunday (UTC time)
|
||||
|
||||
env:
|
||||
POETRY_VERSION: "1.6.1"
|
||||
LANGCHAIN_API_KEY: ${{ secrets.LANGCHAIN_API_KEY }}
|
||||
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
|
||||
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
|
||||
|
||||
jobs:
|
||||
run_tool_benchmarks:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
|
||||
- name: Set up Python 3.12 + Poetry ${{ env.POETRY_VERSION }}
|
||||
uses: "./.github/actions/poetry_setup"
|
||||
with:
|
||||
python-version: '3.12'
|
||||
poetry-version: ${{ env.POETRY_VERSION }}
|
||||
working-directory: .
|
||||
cache-key: benchmarks-all
|
||||
|
||||
- name: Install dependencies
|
||||
shell: bash
|
||||
run: |
|
||||
echo "Running tests, installing dependencies with poetry..."
|
||||
poetry install --with test,lint,typing,docs
|
||||
|
||||
- name: Multiverse math benchmark
|
||||
|
||||
run: |
|
||||
cd scripts
|
||||
poetry run python multiverse_math_benchmark.py
|
||||
|
||||
- name: Query analysis benchmark
|
||||
run: |
|
||||
cd scripts
|
||||
poetry run python query_analysis_benchmark.py
|
||||
@@ -0,0 +1,162 @@
|
||||
### Python template
|
||||
# Byte-compiled / optimized / DLL files
|
||||
__pycache__/
|
||||
*.py[cod]
|
||||
*$py.class
|
||||
|
||||
# C extensions
|
||||
*.so
|
||||
|
||||
# Distribution / packaging
|
||||
.Python
|
||||
build/
|
||||
develop-eggs/
|
||||
dist/
|
||||
downloads/
|
||||
eggs/
|
||||
.eggs/
|
||||
lib/
|
||||
lib64/
|
||||
parts/
|
||||
sdist/
|
||||
var/
|
||||
wheels/
|
||||
share/python-wheels/
|
||||
*.egg-info/
|
||||
.installed.cfg
|
||||
*.egg
|
||||
MANIFEST
|
||||
|
||||
# PyInstaller
|
||||
# Usually these files are written by a python script from a template
|
||||
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
||||
*.manifest
|
||||
*.spec
|
||||
|
||||
# Installer logs
|
||||
pip-log.txt
|
||||
pip-delete-this-directory.txt
|
||||
|
||||
# Unit test / coverage reports
|
||||
htmlcov/
|
||||
.tox/
|
||||
.nox/
|
||||
.coverage
|
||||
.coverage.*
|
||||
.cache
|
||||
nosetests.xml
|
||||
coverage.xml
|
||||
*.cover
|
||||
*.py,cover
|
||||
.hypothesis/
|
||||
.pytest_cache/
|
||||
cover/
|
||||
|
||||
# Translations
|
||||
*.mo
|
||||
*.pot
|
||||
|
||||
# Django stuff:
|
||||
*.log
|
||||
local_settings.py
|
||||
db.sqlite3
|
||||
db.sqlite3-journal
|
||||
|
||||
# Flask stuff:
|
||||
instance/
|
||||
.webassets-cache
|
||||
|
||||
# Scrapy stuff:
|
||||
.scrapy
|
||||
|
||||
# Sphinx documentation
|
||||
docs/_build/
|
||||
|
||||
# PyBuilder
|
||||
.pybuilder/
|
||||
target/
|
||||
|
||||
# Jupyter Notebook
|
||||
.ipynb_checkpoints
|
||||
|
||||
# IPython
|
||||
profile_default/
|
||||
ipython_config.py
|
||||
|
||||
# pyenv
|
||||
# For a library or package, you might want to ignore these files since the code is
|
||||
# intended to run in multiple environments; otherwise, check them in:
|
||||
# .python-version
|
||||
|
||||
# pipenv
|
||||
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
||||
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
||||
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
||||
# install all needed dependencies.
|
||||
#Pipfile.lock
|
||||
|
||||
# poetry
|
||||
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
||||
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
||||
# commonly ignored for libraries.
|
||||
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
||||
#poetry.lock
|
||||
|
||||
# pdm
|
||||
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
||||
#pdm.lock
|
||||
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
||||
# in version control.
|
||||
# https://pdm.fming.dev/#use-with-ide
|
||||
.pdm.toml
|
||||
|
||||
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
||||
__pypackages__/
|
||||
|
||||
# Celery stuff
|
||||
celerybeat-schedule
|
||||
celerybeat.pid
|
||||
|
||||
# SageMath parsed files
|
||||
*.sage.py
|
||||
|
||||
# Environments
|
||||
.env
|
||||
.venv
|
||||
env/
|
||||
venv/
|
||||
ENV/
|
||||
env.bak/
|
||||
venv.bak/
|
||||
|
||||
# Spyder project settings
|
||||
.spyderproject
|
||||
.spyproject
|
||||
|
||||
# Rope project settings
|
||||
.ropeproject
|
||||
|
||||
# mkdocs documentation
|
||||
/site
|
||||
|
||||
# mypy
|
||||
.mypy_cache/
|
||||
.dmypy.json
|
||||
dmypy.json
|
||||
|
||||
# Pyre type checker
|
||||
.pyre/
|
||||
|
||||
# pytype static type analyzer
|
||||
.pytype/
|
||||
|
||||
# Cython debug symbols
|
||||
cython_debug/
|
||||
|
||||
# PyCharm
|
||||
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
||||
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
||||
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
||||
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
||||
.idea/
|
||||
.DS_Store
|
||||
@@ -0,0 +1,21 @@
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2023 Langchain AI
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
@@ -0,0 +1,67 @@
|
||||
.PHONY: all lint format test help
|
||||
|
||||
# Default target executed when no arguments are given to make.
|
||||
all: help
|
||||
|
||||
# LINTING AND FORMATTING:
|
||||
|
||||
# Define a variable for Python and notebook files.
|
||||
lint format: PYTHON_FILES=.
|
||||
lint_diff format_diff: PYTHON_FILES=$(shell git diff --relative=. --name-only --diff-filter=d master | grep -E '\.py$$|\.ipynb$$')
|
||||
|
||||
lint lint_diff:
|
||||
[ "$(PYTHON_FILES)" = "" ] || poetry run ruff format $(PYTHON_FILES) --diff
|
||||
# [ "$(PYTHON_FILES)" = "" ] || poetry run mypy $(PYTHON_FILES)
|
||||
|
||||
format format_diff:
|
||||
[ "$(PYTHON_FILES)" = "" ] || poetry run ruff format $(PYTHON_FILES)
|
||||
[ "$(PYTHON_FILES)" = "" ] || poetry run ruff --select I --fix $(PYTHON_FILES)
|
||||
|
||||
spell_check:
|
||||
poetry run codespell --toml pyproject.toml
|
||||
|
||||
spell_fix:
|
||||
poetry run codespell --toml pyproject.toml -w
|
||||
|
||||
|
||||
# TESTING AND COVERAGE:
|
||||
|
||||
# Define a variable for the test file path.
|
||||
TEST_FILE ?= tests/unit_tests/
|
||||
|
||||
test:
|
||||
poetry run pytest --disable-socket --allow-unix-socket $(TEST_FILE)
|
||||
|
||||
test_watch:
|
||||
poetry run ptw . -- $(TEST_FILE)
|
||||
|
||||
|
||||
# DOCUMENTATION:
|
||||
|
||||
docs_clean:
|
||||
rm -rf ./docs/build
|
||||
|
||||
docs_build:
|
||||
# Copy README.md to docs/index.md
|
||||
cp README.md ./docs/source/index.md
|
||||
# Append to the table of contents the contents of the file
|
||||
cat ./docs/source/toc.segment >> ./docs/source/index.md
|
||||
poetry run sphinx-build "./docs/source" "./docs/build"
|
||||
|
||||
|
||||
# HELP:
|
||||
help:
|
||||
@echo ''
|
||||
@echo 'LINTING:'
|
||||
@echo ' format - run code formatters'
|
||||
@echo ' lint - run linters'
|
||||
@echo ' spell_check - run codespell'
|
||||
@echo ' spell_fix - run codespell and fix the errors'
|
||||
@echo 'TESTS:'
|
||||
@echo ' test - run unit tests'
|
||||
@echo ' test TEST_FILE=<test_file> - run tests in <test_file>'
|
||||
@echo ' coverage - run unit tests and generate coverage report'
|
||||
@echo 'DOCUMENTATION:'
|
||||
@echo ' docs_clean - delete the docs/build directory'
|
||||
@echo ' docs_build - build the documentation'
|
||||
@echo ''
|
||||
@@ -1,8 +1,19 @@
|
||||
# LangChain Benchmarks
|
||||
# 🦜💯 LangChain Benchmarks
|
||||
|
||||
This repository shows how we benchmark some of our more popular chains and agents.
|
||||
The benchmarks are organized by end-to-end use cases.
|
||||
They utilize [LangSmith](https://smith.langchain.com/) heavily.
|
||||
[](https://github.com/langchain-ai/langchain-benchmarks/releases)
|
||||
[](https://github.com/langchain-ai/langchain-benchmarks/actions/workflows/ci.yml)
|
||||
[](https://opensource.org/licenses/MIT)
|
||||
[](https://twitter.com/langchainai)
|
||||
[](https://discord.gg/6adMQxSpJS)
|
||||
[](https://github.com/langchain-ai/langchain-benchmarks/issues)
|
||||
|
||||
|
||||
[📖 Documentation](https://langchain-ai.github.io/langchain-benchmarks/index.html)
|
||||
|
||||
A package to help benchmark various LLM related tasks.
|
||||
|
||||
The benchmarks are organized by end-to-end use cases, and
|
||||
utilize [LangSmith](https://smith.langchain.com/) heavily.
|
||||
|
||||
We have several goals in open sourcing this:
|
||||
|
||||
@@ -11,6 +22,62 @@ We have several goals in open sourcing this:
|
||||
- Showing how we evaluate each task
|
||||
- Encouraging others to benchmark their solutions on these tasks (we are always looking for better ways of doing things!)
|
||||
|
||||
We currently include the following tasks:
|
||||
- [CSV Question Answering](csv-qa)
|
||||
- [Extraction](extraction)
|
||||
## Benchmarking Results
|
||||
|
||||
Read some of the articles about benchmarking results on our blog.
|
||||
|
||||
* [Agent Tool Use](https://blog.langchain.dev/benchmarking-agent-tool-use/)
|
||||
* [Query Analysis in High Cardinality Situations](https://blog.langchain.dev/high-cardinality/)
|
||||
* [RAG on Tables](https://blog.langchain.dev/benchmarking-rag-on-tables/)
|
||||
* [Q&A over CSV data](https://blog.langchain.dev/benchmarking-question-answering-over-csv-data/)
|
||||
|
||||
|
||||
### Tool Usage (2024-04-18)
|
||||
|
||||
See [tool usage docs](https://langchain-ai.github.io/langchain-benchmarks/notebooks/tool_usage/benchmark_all_tasks.html) to recreate!
|
||||
|
||||
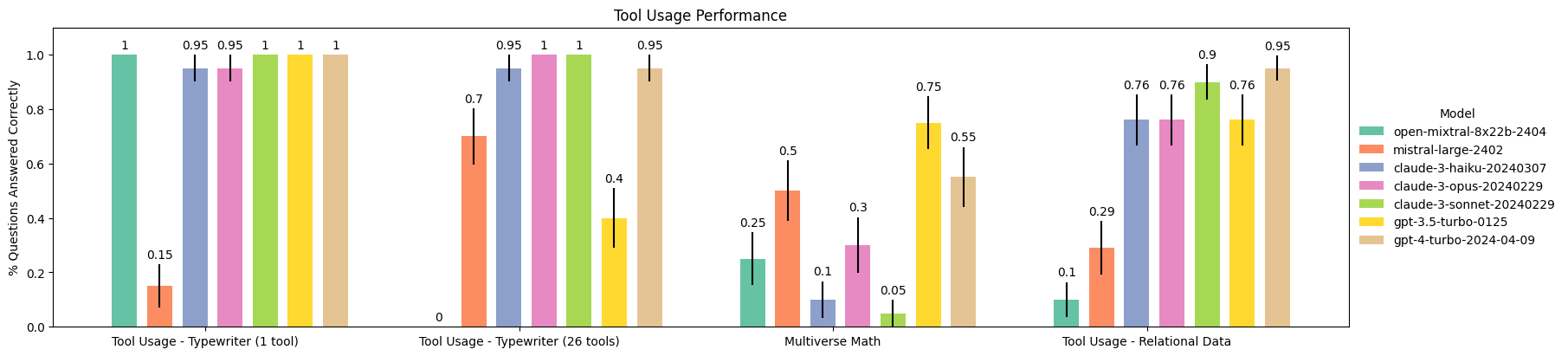
|
||||
|
||||
Explore Agent Traces on LangSmith:
|
||||
|
||||
* [Relational Data](https://smith.langchain.com/public/22721064-dcf6-4e42-be65-e7c46e6835e7/d)
|
||||
* [Tool Usage (1-tool)](https://smith.langchain.com/public/ac23cb40-e392-471f-b129-a893a77b6f62/d)
|
||||
* [Tool Usage (26-tools)](https://smith.langchain.com/public/366bddca-62b3-4b6e-849b-a478abab73db/d)
|
||||
* [Multiverse Math](https://smith.langchain.com/public/983faff2-54b9-4875-9bf2-c16913e7d489/d)
|
||||
|
||||
## Installation
|
||||
|
||||
To install the packages, run the following command:
|
||||
|
||||
```bash
|
||||
pip install -U langchain-benchmarks
|
||||
```
|
||||
|
||||
All the benchmarks come with an associated benchmark dataset stored in [LangSmith](https://smith.langchain.com). To take advantage of the eval and debugging experience, [sign up](https://smith.langchain.com), and set your API key in your environment:
|
||||
|
||||
```bash
|
||||
export LANGCHAIN_API_KEY=ls-...
|
||||
```
|
||||
|
||||
## Repo Structure
|
||||
|
||||
The package is located within [langchain_benchmarks](./langchain_benchmarks/). Check out the [docs](https://langchain-ai.github.io/langchain-benchmarks/index.html) for information on how to get starte.
|
||||
|
||||
The other directories are legacy and may be moved in the future.
|
||||
|
||||
|
||||
## Archived
|
||||
|
||||
Below are archived benchmarks that require cloning this repo to run.
|
||||
|
||||
- [CSV Question Answering](https://github.com/langchain-ai/langchain-benchmarks/tree/main/archived/csv-qa)
|
||||
- [Extraction](https://github.com/langchain-ai/langchain-benchmarks/tree/main/archived/extraction)
|
||||
- [Q&A over the LangChain docs](https://github.com/langchain-ai/langchain-benchmarks/tree/main/archived/langchain-docs-benchmarking)
|
||||
- [Meta-evaluation of 'correctness' evaluators](https://github.com/langchain-ai/langchain-benchmarks/tree/main/archived/meta-evals)
|
||||
|
||||
|
||||
## Related
|
||||
|
||||
- For cookbooks on other ways to test, debug, monitor, and improve your LLM applications, check out the [LangSmith docs](https://docs.smith.langchain.com/)
|
||||
- For information on building with LangChain, check out the [python documentation](https://python.langchain.com/docs/get_started/introduction) or [JS documentation](https://js.langchain.com/docs/get_started/introduction)
|
||||
|
||||
|
||||
@@ -1,22 +1,25 @@
|
||||
from langchain.agents import OpenAIFunctionsAgent, AgentExecutor
|
||||
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
|
||||
from langchain.tools import PythonAstREPLTool
|
||||
import pandas as pd
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langsmith import Client
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from pydantic import BaseModel, Field
|
||||
from langchain.agents import AgentExecutor, OpenAIFunctionsAgent
|
||||
from langchain.agents.agent_toolkits.conversational_retrieval.tool import (
|
||||
create_retriever_tool,
|
||||
)
|
||||
from langchain.embeddings import OpenAIEmbeddings
|
||||
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain.tools import PythonAstREPLTool
|
||||
from langchain.vectorstores import FAISS
|
||||
from langchain.agents.agent_toolkits.conversational_retrieval.tool import create_retriever_tool
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
|
||||
pd.set_option('display.max_rows', 20)
|
||||
pd.set_option('display.max_columns', 20)
|
||||
pd.set_option("display.max_rows", 20)
|
||||
pd.set_option("display.max_columns", 20)
|
||||
|
||||
embedding_model = OpenAIEmbeddings()
|
||||
vectorstore = FAISS.load_local("titanic_data", embedding_model)
|
||||
retriever_tool = create_retriever_tool(vectorstore.as_retriever(), "person_name_search", "Search for a person by name")
|
||||
retriever_tool = create_retriever_tool(
|
||||
vectorstore.as_retriever(), "person_name_search", "Search for a person by name"
|
||||
)
|
||||
|
||||
|
||||
TEMPLATE = """You are working with a pandas dataframe in Python. The name of the dataframe is `df`.
|
||||
@@ -42,7 +45,6 @@ For example:
|
||||
"""
|
||||
|
||||
|
||||
|
||||
class PythonInputs(BaseModel):
|
||||
query: str = Field(description="code snippet to run")
|
||||
|
||||
@@ -51,27 +53,33 @@ if __name__ == "__main__":
|
||||
df = pd.read_csv("titanic.csv")
|
||||
template = TEMPLATE.format(dhead=df.head().to_markdown())
|
||||
|
||||
prompt = ChatPromptTemplate.from_messages([
|
||||
("system", template),
|
||||
MessagesPlaceholder(variable_name="agent_scratchpad"),
|
||||
("human", "{input}")
|
||||
])
|
||||
prompt = ChatPromptTemplate.from_messages(
|
||||
[
|
||||
("system", template),
|
||||
MessagesPlaceholder(variable_name="agent_scratchpad"),
|
||||
("human", "{input}"),
|
||||
]
|
||||
)
|
||||
|
||||
def get_chain():
|
||||
repl = PythonAstREPLTool(locals={"df": df}, name="python_repl",
|
||||
description="Runs code and returns the output of the final line",
|
||||
args_schema=PythonInputs)
|
||||
repl = PythonAstREPLTool(
|
||||
locals={"df": df},
|
||||
name="python_repl",
|
||||
description="Runs code and returns the output of the final line",
|
||||
args_schema=PythonInputs,
|
||||
)
|
||||
tools = [repl, retriever_tool]
|
||||
agent = OpenAIFunctionsAgent(llm=ChatOpenAI(temperature=0, model="gpt-4"), prompt=prompt, tools=tools)
|
||||
agent_executor = AgentExecutor(agent=agent, tools=tools, max_iterations=5, early_stopping_method="generate")
|
||||
agent = OpenAIFunctionsAgent(
|
||||
llm=ChatOpenAI(temperature=0, model="gpt-4"), prompt=prompt, tools=tools
|
||||
)
|
||||
agent_executor = AgentExecutor(
|
||||
agent=agent, tools=tools, max_iterations=5, early_stopping_method="generate"
|
||||
)
|
||||
return agent_executor
|
||||
|
||||
|
||||
client = Client()
|
||||
eval_config = RunEvalConfig(
|
||||
evaluators=[
|
||||
"qa"
|
||||
],
|
||||
evaluators=["qa"],
|
||||
)
|
||||
chain_results = run_on_dataset(
|
||||
client,
|
||||
@@ -1,9 +1,9 @@
|
||||
import pandas as pd
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.agents.agent_toolkits import create_pandas_dataframe_agent
|
||||
from langchain.agents.agent_types import AgentType
|
||||
from langsmith import Client
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
|
||||
if __name__ == "__main__":
|
||||
df = pd.read_csv("titanic.csv")
|
||||
@@ -18,20 +18,17 @@ if __name__ == "__main__":
|
||||
df,
|
||||
agent_type=AgentType.OPENAI_FUNCTIONS,
|
||||
agent_executor_kwargs=agent_executor_kwargs,
|
||||
max_iterations=5
|
||||
max_iterations=5,
|
||||
)
|
||||
return agent
|
||||
|
||||
|
||||
client = Client()
|
||||
eval_config = RunEvalConfig(
|
||||
evaluators=[
|
||||
"qa"
|
||||
],
|
||||
evaluators=["qa"],
|
||||
)
|
||||
chain_results = run_on_dataset(
|
||||
client,
|
||||
dataset_name="Titanic CSV Data",
|
||||
llm_or_chain_factory=get_chain,
|
||||
evaluation=eval_config,
|
||||
)
|
||||
)
|
||||
@@ -1,14 +1,13 @@
|
||||
import pandas as pd
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.agents.agent_toolkits import create_pandas_dataframe_agent
|
||||
from langchain.agents.agent_types import AgentType
|
||||
from langsmith import Client
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
|
||||
if __name__ == "__main__":
|
||||
df = pd.read_csv("titanic.csv")
|
||||
|
||||
|
||||
def get_chain():
|
||||
llm = ChatOpenAI(temperature=0, model="gpt-4")
|
||||
agent_executor_kwargs = {
|
||||
@@ -19,20 +18,17 @@ if __name__ == "__main__":
|
||||
df,
|
||||
agent_type=AgentType.OPENAI_FUNCTIONS,
|
||||
agent_executor_kwargs=agent_executor_kwargs,
|
||||
max_iterations=5
|
||||
max_iterations=5,
|
||||
)
|
||||
return agent
|
||||
|
||||
|
||||
client = Client()
|
||||
eval_config = RunEvalConfig(
|
||||
evaluators=[
|
||||
"qa"
|
||||
],
|
||||
evaluators=["qa"],
|
||||
)
|
||||
chain_results = run_on_dataset(
|
||||
client,
|
||||
dataset_name="Titanic CSV Data",
|
||||
llm_or_chain_factory=get_chain,
|
||||
evaluation=eval_config,
|
||||
)
|
||||
)
|
||||
@@ -1,22 +1,24 @@
|
||||
from langchain.agents import ZeroShotAgent, AgentExecutor
|
||||
from langchain.prompts import PromptTemplate
|
||||
from langchain.tools import PythonAstREPLTool
|
||||
import pandas as pd
|
||||
from langchain.llms import OpenAI
|
||||
from langsmith import Client
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from pydantic import BaseModel, Field
|
||||
from langchain.agents import AgentExecutor, ZeroShotAgent
|
||||
from langchain.agents.agent_toolkits.conversational_retrieval.tool import (
|
||||
create_retriever_tool,
|
||||
)
|
||||
from langchain.embeddings import OpenAIEmbeddings
|
||||
from langchain.llms import OpenAI
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain.tools import PythonAstREPLTool
|
||||
from langchain.vectorstores import FAISS
|
||||
from langchain.agents.agent_toolkits.conversational_retrieval.tool import create_retriever_tool
|
||||
from langsmith import Client
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
|
||||
pd.set_option('display.max_rows', 20)
|
||||
pd.set_option('display.max_columns', 20)
|
||||
pd.set_option("display.max_rows", 20)
|
||||
pd.set_option("display.max_columns", 20)
|
||||
|
||||
embedding_model = OpenAIEmbeddings()
|
||||
vectorstore = FAISS.load_local("titanic_data", embedding_model)
|
||||
retriever_tool = create_retriever_tool(vectorstore.as_retriever(), "person_name_search", "Search for a person by name")
|
||||
retriever_tool = create_retriever_tool(
|
||||
vectorstore.as_retriever(), "person_name_search", "Search for a person by name"
|
||||
)
|
||||
|
||||
|
||||
TEMPLATE = """You are working with a pandas dataframe in Python. The name of the dataframe is `df`.
|
||||
@@ -41,7 +43,6 @@ For example:
|
||||
<logic>Use `python_repl` since even though the question is about a person, you don't know their name so you can't include it.</logic>"""
|
||||
|
||||
|
||||
|
||||
class PythonInputs(BaseModel):
|
||||
query: str = Field(description="code snippet to run")
|
||||
|
||||
@@ -50,22 +51,27 @@ if __name__ == "__main__":
|
||||
df = pd.read_csv("titanic.csv")
|
||||
template = TEMPLATE.format(dhead=df.head().to_markdown())
|
||||
|
||||
|
||||
def get_chain():
|
||||
repl = PythonAstREPLTool(locals={"df": df}, name="python_repl",
|
||||
description="Runs code and returns the output of the final line",
|
||||
args_schema=PythonInputs)
|
||||
repl = PythonAstREPLTool(
|
||||
locals={"df": df},
|
||||
name="python_repl",
|
||||
description="Runs code and returns the output of the final line",
|
||||
args_schema=PythonInputs,
|
||||
)
|
||||
tools = [repl, retriever_tool]
|
||||
agent = ZeroShotAgent.from_llm_and_tools(llm=OpenAI(temperature=0, model="gpt-3.5-turbo-instruct"), tools=tools, prefix=template)
|
||||
agent_executor = AgentExecutor(agent=agent, tools=tools, max_iterations=5, early_stopping_method="generate")
|
||||
agent = ZeroShotAgent.from_llm_and_tools(
|
||||
llm=OpenAI(temperature=0, model="gpt-3.5-turbo-instruct"),
|
||||
tools=tools,
|
||||
prefix=template,
|
||||
)
|
||||
agent_executor = AgentExecutor(
|
||||
agent=agent, tools=tools, max_iterations=5, early_stopping_method="generate"
|
||||
)
|
||||
return agent_executor
|
||||
|
||||
|
||||
client = Client()
|
||||
eval_config = RunEvalConfig(
|
||||
evaluators=[
|
||||
"qa"
|
||||
],
|
||||
evaluators=["qa"],
|
||||
)
|
||||
chain_results = run_on_dataset(
|
||||
client,
|
||||
@@ -0,0 +1,45 @@
|
||||
import pandas as pd
|
||||
from langchain.prompts import ChatPromptTemplate
|
||||
from langchain.schema.output_parser import StrOutputParser
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
from pandasai import PandasAI
|
||||
|
||||
if __name__ == "__main__":
|
||||
df = pd.read_csv("titanic.csv")
|
||||
|
||||
pandas_ai = PandasAI(ChatOpenAI(temperature=0, model="gpt-4"), enable_cache=False)
|
||||
prompt = ChatPromptTemplate.from_messages(
|
||||
[
|
||||
(
|
||||
"system",
|
||||
"Answer the users question about some data. A data scientist will run some code and the results will be returned to you to use in your answer",
|
||||
),
|
||||
("human", "Question: {input}"),
|
||||
("human", "Data Scientist Result: {result}"),
|
||||
]
|
||||
)
|
||||
|
||||
def get_chain():
|
||||
chain = (
|
||||
{
|
||||
"input": lambda x: x["input_question"],
|
||||
"result": lambda x: pandas_ai(df, prompt=x["input_question"]),
|
||||
}
|
||||
| prompt
|
||||
| ChatOpenAI(temperature=0, model="gpt-4")
|
||||
| StrOutputParser()
|
||||
)
|
||||
return chain
|
||||
|
||||
client = Client()
|
||||
eval_config = RunEvalConfig(
|
||||
evaluators=["qa"],
|
||||
)
|
||||
chain_results = run_on_dataset(
|
||||
client,
|
||||
dataset_name="Titanic CSV Data",
|
||||
llm_or_chain_factory=get_chain,
|
||||
evaluation=eval_config,
|
||||
)
|
||||
{kind=link}
|
Before Width: | Height: | Size: 12 KiB After Width: | Height: | Size: 12 KiB |
{kind=link}
|
Before Width: | Height: | Size: 12 KiB After Width: | Height: | Size: 12 KiB |
{kind=link}
|
Before Width: | Height: | Size: 9.7 KiB After Width: | Height: | Size: 9.7 KiB |
{kind=link}
|
Before Width: | Height: | Size: 11 KiB After Width: | Height: | Size: 11 KiB |
@@ -0,0 +1,47 @@
|
||||
import pandas as pd
|
||||
import streamlit as st
|
||||
from langchain.agents.agent_toolkits import create_pandas_dataframe_agent
|
||||
from langchain.agents.agent_types import AgentType
|
||||
from langchain_openai import ChatOpenAI
|
||||
|
||||
df = pd.read_csv("titanic.csv")
|
||||
|
||||
|
||||
llm = ChatOpenAI(temperature=0)
|
||||
agent = create_pandas_dataframe_agent(llm, df, agent_type=AgentType.OPENAI_FUNCTIONS)
|
||||
|
||||
|
||||
from langsmith import Client
|
||||
|
||||
client = Client()
|
||||
|
||||
|
||||
def send_feedback(run_id, score):
|
||||
client.create_feedback(run_id, "user_score", score=score)
|
||||
|
||||
|
||||
st.set_page_config(page_title="🦜🔗 Ask the CSV App")
|
||||
st.title("🦜🔗 Ask the CSV App")
|
||||
st.info(
|
||||
"Most 'question answering' applications run over unstructured text data. But a lot of the data in the world is tabular data! This is an attempt to create an application using [LangChain](https://github.com/langchain-ai/langchain) to let you ask questions of data in tabular format. For this demo application, we will use the Titanic Dataset. Please explore it [here](https://github.com/datasciencedojo/datasets/blob/master/titanic.csv) to get a sense for what questions you can ask. Please leave feedback on well the question is answered, and we will use that improve the application!"
|
||||
)
|
||||
|
||||
query_text = st.text_input("Enter your question:", placeholder="Who was in cabin C128?")
|
||||
# Form input and query
|
||||
result = None
|
||||
with st.form("myform", clear_on_submit=True):
|
||||
submitted = st.form_submit_button("Submit")
|
||||
if submitted:
|
||||
with st.spinner("Calculating..."):
|
||||
response = agent({"input": query_text}, include_run_info=True)
|
||||
result = response["output"]
|
||||
run_id = response["__run"].run_id
|
||||
if result is not None:
|
||||
st.info(result)
|
||||
col_blank, col_text, col1, col2 = st.columns([10, 2, 1, 1])
|
||||
with col_text:
|
||||
st.text("Feedback:")
|
||||
with col1:
|
||||
st.button("👍", on_click=send_feedback, args=(run_id, 1))
|
||||
with col2:
|
||||
st.button("👎", on_click=send_feedback, args=(run_id, 0))
|
||||
@@ -8,5 +8,5 @@ if __name__ == "__main__":
|
||||
output_keys=["output_text"],
|
||||
name="Titanic CSV Data",
|
||||
description="QA over titanic data",
|
||||
data_type = "kv"
|
||||
data_type="kv",
|
||||
)
|
||||
@@ -0,0 +1,79 @@
|
||||
import streamlit as st
|
||||
from langchain.chains import create_extraction_chain
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
|
||||
st.set_page_config(page_title="🦜🔗 Text-to-graph extraction")
|
||||
client = Client()
|
||||
|
||||
|
||||
def send_feedback(run_id, score):
|
||||
client.create_feedback(run_id, "user_score", score=score)
|
||||
|
||||
|
||||
st.title("🦜🔗 Text-to-graph playground")
|
||||
st.info(
|
||||
"This playground explores the use of [OpenAI functions](https://openai.com/blog/function-calling-and-other-api-updates) and [LangChain](https://github.com/langchain-ai/langchain) to build knowledge graphs from user-input text. It breaks down the user input text into knowledge graph triples of subject (primary entities or concepts in a sentence), predicate (actions or relationships that connect subjects to objects), and object (entities or concepts that interact with or are acted upon by the subjects)."
|
||||
)
|
||||
|
||||
# Input text (optional default)
|
||||
oppenheimer_text = """'Julius Robert Oppenheimer, often known as Robert or "Oppie", is heralded as the father of the atomic bomb. Emerging from a non-practicing Jewish family in New York, he made several breakthroughs, such as the early black hole theory, before the monumental Manhattan Project. His wife, Katherine “Kitty” Oppenheimer, was a German-born woman with a complex past, including connections to the Communist Party. Oppenheimer\'s journey was beset by political adversaries, notably Lewis Strauss, chairman of the U.S. Atomic Energy Commission, and William Borden, an executive director with hawkish nuclear ambitions. These tensions culminated in the famous 1954 security hearing. Influential figures like lieutenant general Leslie Groves, who had also overseen the Pentagon\'s creation, stood by Oppenheimer\'s side, having earlier chosen him for the Manhattan Project and the Los Alamos location. Intimate relationships, like that with Jean Tatlock, a Communist and the possible muse behind the Trinity test\'s name, and colleagues like Frank, Oppenheimer\'s physicist brother, intertwined with his professional life. Scientists such as Ernest Lawrence, Edward Teller, David Hill, Richard Feynman, and Hans Bethe were some of Oppenheimer\'s contemporaries, each contributing to and contesting the atomic age\'s directions. Boris Pash\'s investigations, and the perspectives of figures like Leo Szilard, Niels Bohr, Harry Truman, and others, framed the broader sociopolitical context. Meanwhile, individuals like Robert Serber, Enrico Fermi, Albert Einstein, and Isidor Isaac Rabi, among many others, each played their parts in this narrative, from naming the atomic bombs to pivotal scientific contributions and advisory roles. All these figures, together with the backdrop of World War II, McCarthyism, and the dawn of the nuclear age, presented a complex mosaic of ambitions, loyalties, betrayals, and ideologies.oppenheimer_short.txt"""
|
||||
|
||||
# Knowledge triplet schema
|
||||
default_schema = {
|
||||
"properties": {
|
||||
"subject": {"type": "string"},
|
||||
"predicate": {"type": "string"},
|
||||
"object": {"type": "string"},
|
||||
},
|
||||
"required": ["subject", "predicate", "object"],
|
||||
}
|
||||
|
||||
# Create a text_area, set the default value to oppenheimer_text
|
||||
MAX_CHARS = 2000 # Maximum number of characters
|
||||
user_input_text = st.text_area("Enter your text (<2000 characters):", height=200)
|
||||
if len(user_input_text) > MAX_CHARS:
|
||||
st.warning(f"Text is too long. Processing only the first {MAX_CHARS} characters")
|
||||
user_input_text = user_input_text[:MAX_CHARS]
|
||||
|
||||
|
||||
# Output formatting of triples
|
||||
def json_to_markdown_table(json_list):
|
||||
if not json_list:
|
||||
return "No data available."
|
||||
|
||||
# Extract headers
|
||||
headers = json_list[0].keys()
|
||||
markdown_table = " | ".join(headers) + "\n"
|
||||
markdown_table += " | ".join(["---"] * len(headers)) + "\n"
|
||||
|
||||
# Extract rows
|
||||
for item in json_list:
|
||||
row = " | ".join([str(item[header]) for header in headers])
|
||||
markdown_table += row + "\n"
|
||||
|
||||
return markdown_table
|
||||
|
||||
|
||||
# Form input and query
|
||||
markdown_output = None
|
||||
with st.form("myform", clear_on_submit=True):
|
||||
submitted = st.form_submit_button("Submit")
|
||||
if submitted:
|
||||
with st.spinner("Calculating..."):
|
||||
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo")
|
||||
chain = create_extraction_chain(default_schema, llm)
|
||||
extraction_output = chain(user_input_text, include_run_info=True)
|
||||
markdown_output = json_to_markdown_table(extraction_output["text"])
|
||||
run_id = extraction_output["__run"].run_id
|
||||
|
||||
# Feeback
|
||||
if markdown_output is not None:
|
||||
st.markdown(markdown_output)
|
||||
col_blank, col_text, col1, col2 = st.columns([10, 2, 1, 1])
|
||||
with col_text:
|
||||
st.text("Feedback:")
|
||||
with col1:
|
||||
st.button("👍", on_click=send_feedback, args=(run_id, 1))
|
||||
with col2:
|
||||
st.button("👎", on_click=send_feedback, args=(run_id, 0))
|
||||
@@ -0,0 +1,89 @@
|
||||
# Benchmarking on LangChain Docs
|
||||
|
||||
This directory contains code to benchmark your cognitive architecture on the public [LangChain Q&A docs evaluation benchmark](https://smith.langchain.com/public/e1bfd348-494a-4df5-899a-7c6c09233cc4/d).
|
||||
|
||||
To one one of the existing configurations, activate your poetry environment, configure you LangSmith API key, and run the experiments.
|
||||
|
||||
**Note:** this will benchmark chains on a _copy_ of the dataset and will not update the public leaderboard.
|
||||
|
||||
## Running the published experiments
|
||||
|
||||
The following steps will let you run pre-configured experiments:
|
||||
|
||||
### 1. Install requirements
|
||||
|
||||
```bash
|
||||
pip install poetry
|
||||
poetry shell
|
||||
poetry install
|
||||
```
|
||||
|
||||
### 2. Configure API keys
|
||||
|
||||
Create a [LangSmith account](https://smith.langchain.com/) and set your API key:
|
||||
|
||||
```bash
|
||||
export LANGCHAIN_API_KEY=ls_your-api-key
|
||||
```
|
||||
|
||||
The various cognitive architectures implemented already use Anthropic, [Fireworks.AI](https://www.fireworks.ai/), and OpenAI. Set the required API keys:
|
||||
|
||||
```
|
||||
export OPENAI_API_KEY=your-api-key
|
||||
export ANTHROPIC_API_KEY=your-api-key
|
||||
export FIREWORKS_API_KEY=your-api-key
|
||||
```
|
||||
|
||||
### 3. Run Experiments
|
||||
|
||||
To run all experiments, run:
|
||||
|
||||
```bash
|
||||
python run_experiments.py
|
||||
```
|
||||
|
||||
If you want to only run certain experiments in the `run_experiments.py` file, use `--include` or `--exclude`
|
||||
|
||||
Example:
|
||||
|
||||
```bash
|
||||
python run_experiments --include mistral-7b-instruct-4k llama-v2-34b-code-instruct-w8a16
|
||||
```
|
||||
|
||||
## Evaluating your custom cognitive architecture
|
||||
|
||||
You can also evaluate your own custom cognitive architecture. To do so:
|
||||
|
||||
1. Create a python file defining your architecture:
|
||||
|
||||
```python
|
||||
# example_custom_chain.py
|
||||
|
||||
...
|
||||
def load_runnable(config: dict) -> "Runnable":
|
||||
# Load based on the config provided
|
||||
return my_chain
|
||||
```
|
||||
|
||||
2. Call `run_experiments.py` with a custom `--config my_config.json`
|
||||
|
||||
```js
|
||||
{
|
||||
// This specifies the path to your custom entrypoint followed by the loader function
|
||||
"arch": "path/to/example_custom_chain.py::load_runnable",
|
||||
"model_config": {
|
||||
// This is passed to load_runnable() in example_custom_chain.py()
|
||||
"chat_cls": "ChatOpenAI",
|
||||
"model": "gpt-4"
|
||||
},
|
||||
"project_name": "example-custom-code" // This is the resulting test project name
|
||||
}
|
||||
```
|
||||
|
||||
We have provided an example in [example_custom_chain.py](./packages/example/custom_example/example_custom_chain.py), which can be run by pointing `run_experiments` to the [example_custom_config.json](./example_custom_config.json) config file:
|
||||
|
||||
```bash
|
||||
python run_experiments.py --config ./example_custom_config.json
|
||||
```
|
||||
|
||||
Whenever you provide 1 or more `--config` files, the `--include` and `--exclude` arguments are ignored.
|
||||
@@ -0,0 +1,26 @@
|
||||
from chat_langchain.chain import chain
|
||||
from fastapi import FastAPI
|
||||
from langserve import add_routes
|
||||
from openai_functions_agent import agent_executor as openai_functions_agent_chain
|
||||
|
||||
app = FastAPI()
|
||||
|
||||
# Edit this to add the chain you want to add
|
||||
add_routes(
|
||||
app,
|
||||
chain,
|
||||
path="/chat",
|
||||
# include_callback_events=True, # TODO: Include when fixed
|
||||
)
|
||||
|
||||
add_routes(app, openai_functions_agent_chain, path="/openai-functions-agent")
|
||||
|
||||
|
||||
def run_server(port: int = 1983):
|
||||
import uvicorn
|
||||
|
||||
uvicorn.run(app, host="0.0.0.0", port=port)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
run_server()
|
||||
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"arch": "packages/example/custom_example/example_custom_chain.py::create_runnable",
|
||||
"model_config": {
|
||||
"chat_cls": "ChatOpenAI",
|
||||
"model": "gpt-4"
|
||||
},
|
||||
"project_name": "example-custom-code"
|
||||
}
|
||||
@@ -0,0 +1,69 @@
|
||||
|
||||
# anthropic-iterative-search
|
||||
|
||||
This template will create a virtual research assistant with the ability to search Wikipedia to find answers to your questions.
|
||||
|
||||
It is heavily inspired by [this notebook](https://github.com/anthropics/anthropic-cookbook/blob/main/long_context/wikipedia-search-cookbook.ipynb).
|
||||
|
||||
## Environment Setup
|
||||
|
||||
Set the `ANTHROPIC_API_KEY` environment variable to access the Anthropic models.
|
||||
|
||||
## Usage
|
||||
|
||||
To use this package, you should first have the LangChain CLI installed:
|
||||
|
||||
```shell
|
||||
pip install -U "langchain-cli[serve]"
|
||||
```
|
||||
|
||||
To create a new LangChain project and install this as the only package, you can do:
|
||||
|
||||
```shell
|
||||
langchain app new my-app --package anthropic-iterative-search
|
||||
```
|
||||
|
||||
If you want to add this to an existing project, you can just run:
|
||||
|
||||
```shell
|
||||
langchain app add anthropic-iterative-search
|
||||
```
|
||||
|
||||
And add the following code to your `server.py` file:
|
||||
```python
|
||||
from anthropic_iterative_search import chain as anthropic_iterative_search_chain
|
||||
|
||||
add_routes(app, anthropic_iterative_search_chain, path="/anthropic-iterative-search")
|
||||
```
|
||||
|
||||
(Optional) Let's now configure LangSmith.
|
||||
LangSmith will help us trace, monitor and debug LangChain applications.
|
||||
LangSmith is currently in private beta, you can sign up [here](https://smith.langchain.com/).
|
||||
If you don't have access, you can skip this section
|
||||
|
||||
|
||||
```shell
|
||||
export LANGCHAIN_TRACING_V2=true
|
||||
export LANGCHAIN_API_KEY=<your-api-key>
|
||||
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
|
||||
```
|
||||
|
||||
If you are inside this directory, then you can spin up a LangServe instance directly by:
|
||||
|
||||
```shell
|
||||
langchain serve
|
||||
```
|
||||
|
||||
This will start the FastAPI app with a server is running locally at
|
||||
[http://localhost:8000](http://localhost:8000)
|
||||
|
||||
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs)
|
||||
We can access the playground at [http://127.0.0.1:8000/anthropic-iterative-search/playground](http://127.0.0.1:8000/anthropic-iterative-search/playground)
|
||||
|
||||
We can access the template from code with:
|
||||
|
||||
```python
|
||||
from langserve.client import RemoteRunnable
|
||||
|
||||
runnable = RemoteRunnable("http://localhost:8000/anthropic-iterative-search")
|
||||
```
|
||||
@@ -0,0 +1,11 @@
|
||||
from langchain.schema.runnable import ConfigurableField
|
||||
|
||||
from .chain import chain
|
||||
from .retriever_agent import executor
|
||||
|
||||
final_chain = chain.configurable_alternatives(
|
||||
ConfigurableField(id="chain"),
|
||||
default_key="response",
|
||||
# This adds a new option, with name `openai` that is equal to `ChatOpenAI()`
|
||||
retrieve=executor,
|
||||
)
|
||||
@@ -0,0 +1,16 @@
|
||||
def _format_docs(docs):
|
||||
result = "\n".join(
|
||||
[
|
||||
f'<item index="{i+1}">\n<page_content>\n{r}\n</page_content>\n</item>'
|
||||
for i, r in enumerate(docs)
|
||||
]
|
||||
)
|
||||
return result
|
||||
|
||||
|
||||
def format_agent_scratchpad(intermediate_steps):
|
||||
thoughts = ""
|
||||
for action, observation in intermediate_steps:
|
||||
thoughts += action.log
|
||||
thoughts += "</search_query>" + _format_docs(observation)
|
||||
return thoughts
|
||||
@@ -0,0 +1,29 @@
|
||||
from langchain.chat_models import ChatAnthropic
|
||||
from langchain.prompts import ChatPromptTemplate
|
||||
from langchain.schema.output_parser import StrOutputParser
|
||||
from langchain.schema.runnable import RunnableLambda
|
||||
from pydantic import BaseModel
|
||||
|
||||
from .prompts import answer_prompt
|
||||
from .retriever_agent import executor
|
||||
|
||||
prompt = ChatPromptTemplate.from_template(answer_prompt)
|
||||
|
||||
model = ChatAnthropic(model="claude-2", temperature=0, max_tokens_to_sample=1000)
|
||||
|
||||
chain = (
|
||||
RunnableLambda(lambda x: {"query": x["question"]})
|
||||
| {"query": lambda x: x["query"], "information": executor | (lambda x: x["output"])}
|
||||
| prompt
|
||||
| model
|
||||
| StrOutputParser()
|
||||
)
|
||||
|
||||
# Add typing for the inputs to be used in the playground
|
||||
|
||||
|
||||
class Inputs(BaseModel):
|
||||
question: str
|
||||
|
||||
|
||||
chain = chain.with_types(input_type=Inputs)
|
||||
@@ -0,0 +1,37 @@
|
||||
import re
|
||||
|
||||
from langchain.schema.agent import AgentAction, AgentFinish
|
||||
|
||||
from .agent_scratchpad import _format_docs
|
||||
|
||||
|
||||
def extract_between_tags(tag: str, string: str, strip: bool = True) -> str:
|
||||
ext_list = re.findall(f"<{tag}\s?>(.+?)</{tag}\s?>", string, re.DOTALL)
|
||||
if strip:
|
||||
ext_list = [e.strip() for e in ext_list]
|
||||
if ext_list:
|
||||
if len(ext_list) != 1:
|
||||
raise ValueError
|
||||
# Only return the first one
|
||||
return ext_list[0]
|
||||
|
||||
|
||||
def parse_output(outputs):
|
||||
partial_completion = outputs["partial_completion"]
|
||||
steps = outputs["intermediate_steps"]
|
||||
search_query = extract_between_tags(
|
||||
"search_query", partial_completion + "</search_query>"
|
||||
)
|
||||
if search_query is None:
|
||||
docs = []
|
||||
str_output = ""
|
||||
for action, observation in steps:
|
||||
docs.extend(observation)
|
||||
str_output += action.log
|
||||
str_output += "</search_query>" + _format_docs(observation)
|
||||
str_output += partial_completion
|
||||
return AgentFinish({"docs": docs, "output": str_output}, log=partial_completion)
|
||||
else:
|
||||
return AgentAction(
|
||||
tool="search", tool_input=search_query, log=partial_completion
|
||||
)
|
||||
@@ -0,0 +1,7 @@
|
||||
retrieval_prompt = """{retriever_description} Before beginning to research the user's question, first think for a moment inside <scratchpad> tags about what information is necessary for a well-informed answer. If the user's question is complex, you may need to decompose the query into multiple subqueries and execute them individually. Sometimes the search engine will return empty search results, or the search results may not contain the information you need. In such cases, feel free to try again with a different query.
|
||||
|
||||
After each call to the Search Engine Tool, reflect briefly inside <search_quality></search_quality> tags about whether you now have enough information to answer, or whether more information is needed. If you have all the relevant information, write it in <information></information> tags, WITHOUT actually answering the question. Otherwise, issue a new search.
|
||||
|
||||
Here is the user's question: <question>{query}</question> Remind yourself to make short queries in your scratchpad as you plan out your strategy.""" # noqa: E501
|
||||
|
||||
answer_prompt = "Here is a user query: <query>{query}</query>. Here is some relevant information: <information>{information}</information>. Please answer the question using the relevant information." # noqa: E501
|
||||
@@ -0,0 +1,17 @@
|
||||
from langchain.tools import tool
|
||||
from langchain_docs_retriever.retriever import get_retriever
|
||||
|
||||
# This is used to tell the model how to best use the retriever.
|
||||
|
||||
retriever_description = """You will be asked a question by a human user. You have access to the following tool to help answer the question. <tool_description> Search Engine Tool * The search engine will exclusively search over the LangChain documentation for pages similar to your query. It returns for each page its title and full page content. Use this tool if you want to get up-to-date and comprehensive information on a topic to help answer queries. Queries should be as atomic as possible -- they only need to address one part of the user's question. For example, if the user's query is "what is the color of a basketball?", your search query should be "basketball". Here's another example: if the user's question is "Who created the first neural network?", your first query should be "neural network". As you can see, these queries are quite short. Think keywords, not phrases. * At any time, you can make a call to the search engine using the following syntax: <search_query>query_word</search_query>. * You'll then get results back in <search_result> tags.</tool_description>""" # noqa: E501
|
||||
|
||||
retriever = get_retriever()
|
||||
|
||||
# This should be the same as the function name below
|
||||
RETRIEVER_TOOL_NAME = "search"
|
||||
|
||||
|
||||
@tool
|
||||
def search(query, callbacks=None):
|
||||
"""Search the LangChain docs with the retriever."""
|
||||
return retriever.get_relevant_documents(query, callbacks=callbacks)
|
||||
@@ -0,0 +1,41 @@
|
||||
from langchain.agents import AgentExecutor
|
||||
from langchain.chat_models import ChatAnthropic
|
||||
from langchain.prompts import ChatPromptTemplate
|
||||
from langchain.schema.output_parser import StrOutputParser
|
||||
from langchain.schema.runnable import RunnableMap, RunnablePassthrough
|
||||
|
||||
from .agent_scratchpad import format_agent_scratchpad
|
||||
from .output_parser import parse_output
|
||||
from .prompts import retrieval_prompt
|
||||
from .retriever import retriever_description, search
|
||||
|
||||
prompt = ChatPromptTemplate.from_messages(
|
||||
[
|
||||
("user", retrieval_prompt),
|
||||
("ai", "{agent_scratchpad}"),
|
||||
]
|
||||
)
|
||||
prompt = prompt.partial(retriever_description=retriever_description)
|
||||
|
||||
model = ChatAnthropic(model="claude-2", temperature=0, max_tokens_to_sample=1000)
|
||||
|
||||
chain = (
|
||||
RunnablePassthrough.assign(
|
||||
agent_scratchpad=lambda x: format_agent_scratchpad(x["intermediate_steps"])
|
||||
)
|
||||
| prompt
|
||||
| model.bind(stop_sequences=["</search_query>"])
|
||||
| StrOutputParser()
|
||||
)
|
||||
|
||||
agent_chain = (
|
||||
RunnableMap(
|
||||
{
|
||||
"partial_completion": chain,
|
||||
"intermediate_steps": lambda x: x["intermediate_steps"],
|
||||
}
|
||||
)
|
||||
| parse_output
|
||||
)
|
||||
|
||||
executor = AgentExecutor(agent=agent_chain, tools=[search])
|
||||
@@ -0,0 +1,12 @@
|
||||
from anthropic_iterative_search import final_chain
|
||||
|
||||
if __name__ == "__main__":
|
||||
query = (
|
||||
"Which movie came out first: Oppenheimer, or "
|
||||
"Are You There God It's Me Margaret?"
|
||||
)
|
||||
print(
|
||||
final_chain.with_config(configurable={"chain": "retrieve"}).invoke(
|
||||
{"query": query}
|
||||
)
|
||||
)
|
||||
@@ -0,0 +1,22 @@
|
||||
[tool.poetry]
|
||||
name = "anthropic-iterative-search"
|
||||
version = "0.0.1"
|
||||
description = ""
|
||||
authors = []
|
||||
readme = "README.md"
|
||||
|
||||
[tool.poetry.dependencies]
|
||||
python = ">=3.8.1,<4.0"
|
||||
langchain = ">=0.0.331,<0.1.0"
|
||||
anthropic = "^0.5.0"
|
||||
wikipedia = "^1.4.0"
|
||||
|
||||
[tool.langserve]
|
||||
export_module = "anthropic_iterative_search"
|
||||
export_attr = "final_chain"
|
||||
|
||||
[build-system]
|
||||
requires = [
|
||||
"poetry-core",
|
||||
]
|
||||
build-backend = "poetry.core.masonry.api"
|
||||
@@ -0,0 +1,21 @@
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2023 LangChain, Inc.
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
@@ -0,0 +1,66 @@
|
||||
# chat-langchain
|
||||
|
||||
TODO: What does this package do
|
||||
|
||||
## Environment Setup
|
||||
|
||||
TODO: What environment variables need to be set (if any)
|
||||
|
||||
## Usage
|
||||
|
||||
To use this package, you should first have the LangChain CLI installed:
|
||||
|
||||
```shell
|
||||
pip install -U "langchain-cli[serve]"
|
||||
```
|
||||
|
||||
To create a new LangChain project and install this as the only package, you can do:
|
||||
|
||||
```shell
|
||||
langchain app new my-app --package chat-langchain
|
||||
```
|
||||
|
||||
If you want to add this to an existing project, you can just run:
|
||||
|
||||
```shell
|
||||
langchain app add chat-langchain
|
||||
```
|
||||
|
||||
And add the following code to your `server.py` file:
|
||||
```python
|
||||
from chat_langchain import chain as chat_langchain_chain
|
||||
|
||||
add_routes(app, chat_langchain_chain, path="/chat-langchain")
|
||||
```
|
||||
|
||||
(Optional) Let's now configure LangSmith.
|
||||
LangSmith will help us trace, monitor and debug LangChain applications.
|
||||
LangSmith is currently in private beta, you can sign up [here](https://smith.langchain.com/).
|
||||
If you don't have access, you can skip this section
|
||||
|
||||
|
||||
```shell
|
||||
export LANGCHAIN_TRACING_V2=true
|
||||
export LANGCHAIN_API_KEY=<your-api-key>
|
||||
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
|
||||
```
|
||||
|
||||
If you are inside this directory, then you can spin up a LangServe instance directly by:
|
||||
|
||||
```shell
|
||||
langchain serve
|
||||
```
|
||||
|
||||
This will start the FastAPI app with a server is running locally at
|
||||
[http://localhost:8000](http://localhost:8000)
|
||||
|
||||
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs)
|
||||
We can access the playground at [http://127.0.0.1:8000/chat-langchain/playground](http://127.0.0.1:8000/chat-langchain/playground)
|
||||
|
||||
We can access the template from code with:
|
||||
|
||||
```python
|
||||
from langserve.client import RemoteRunnable
|
||||
|
||||
runnable = RemoteRunnable("http://localhost:8000/chat-langchain")
|
||||
```
|
||||
@@ -0,0 +1,3 @@
|
||||
from chat_langchain.chain import chain
|
||||
|
||||
__all__ = ["chain"]
|
||||
@@ -0,0 +1,183 @@
|
||||
"""Chat langchain 'engine'."""
|
||||
from operator import itemgetter
|
||||
from typing import Dict, List, Optional, Sequence
|
||||
|
||||
from langchain.chat_models import ChatAnthropic, ChatFireworks, ChatOpenAI
|
||||
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder, PromptTemplate
|
||||
from langchain.schema import Document
|
||||
from langchain.schema.language_model import BaseLanguageModel
|
||||
from langchain.schema.messages import AIMessage, HumanMessage
|
||||
from langchain.schema.output_parser import StrOutputParser
|
||||
from langchain.schema.retriever import BaseRetriever
|
||||
from langchain.schema.runnable import (
|
||||
Runnable,
|
||||
RunnableBranch,
|
||||
RunnableLambda,
|
||||
RunnableMap,
|
||||
)
|
||||
from langchain_docs_retriever.retriever import get_retriever
|
||||
from pydantic import BaseModel
|
||||
|
||||
RESPONSE_TEMPLATE = """\
|
||||
You are an expert programmer and problem-solver, tasked with answering any question \
|
||||
about Langchain.
|
||||
|
||||
Generate a comprehensive and informative answer of 80 words or less for the \
|
||||
given question based solely on the provided search results (URL and content). You must \
|
||||
only use information from the provided search results. Use an unbiased and \
|
||||
journalistic tone. Combine search results together into a coherent answer. Do not \
|
||||
repeat text. Cite search results using [${{number}}] notation. Only cite the most \
|
||||
relevant results that answer the question accurately. Place these citations at the end \
|
||||
of the sentence or paragraph that reference them - do not put them all at the end. If \
|
||||
different results refer to different entities within the same name, write separate \
|
||||
answers for each entity.
|
||||
|
||||
You should use bullet points in your answer for readability. Put citations where they apply
|
||||
rather than putting them all at the end.
|
||||
|
||||
If there is nothing in the context relevant to the question at hand, just say "Hmm, \
|
||||
I'm not sure." Don't try to make up an answer.
|
||||
|
||||
Anything between the following `context` html blocks is retrieved from a knowledge \
|
||||
bank, not part of the conversation with the user.
|
||||
|
||||
<context>
|
||||
{context}
|
||||
<context/>
|
||||
|
||||
REMEMBER: If there is no relevant information within the context, just say "Hmm, I'm \
|
||||
not sure." Don't try to make up an answer. Anything between the preceding 'context' \
|
||||
html blocks is retrieved from a knowledge bank, not part of the conversation with the \
|
||||
user.\
|
||||
"""
|
||||
|
||||
REPHRASE_TEMPLATE = """\
|
||||
Given the following conversation and a follow up question, rephrase the follow up \
|
||||
question to be a standalone question.
|
||||
|
||||
Chat History:
|
||||
{chat_history}
|
||||
Follow Up Input: {question}
|
||||
Standalone Question:"""
|
||||
|
||||
|
||||
class ChatRequest(BaseModel):
|
||||
question: str
|
||||
chat_history: Optional[List[Dict[str, str]]]
|
||||
|
||||
|
||||
def create_retriever_chain(
|
||||
llm: BaseLanguageModel, retriever: BaseRetriever
|
||||
) -> Runnable:
|
||||
CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(REPHRASE_TEMPLATE)
|
||||
condense_question_chain = (
|
||||
CONDENSE_QUESTION_PROMPT | llm | StrOutputParser()
|
||||
).with_config(
|
||||
run_name="CondenseQuestion",
|
||||
)
|
||||
conversation_chain = condense_question_chain | retriever
|
||||
return RunnableBranch(
|
||||
(
|
||||
RunnableLambda(lambda x: bool(x.get("chat_history"))).with_config(
|
||||
run_name="HasChatHistoryCheck"
|
||||
),
|
||||
conversation_chain.with_config(run_name="RetrievalChainWithHistory"),
|
||||
),
|
||||
(
|
||||
RunnableLambda(itemgetter("question")).with_config(
|
||||
run_name="Itemgetter:question"
|
||||
)
|
||||
| retriever
|
||||
).with_config(run_name="RetrievalChainWithNoHistory"),
|
||||
).with_config(run_name="RouteDependingOnChatHistory")
|
||||
|
||||
|
||||
def format_docs(docs: Sequence[Document]) -> str:
|
||||
formatted_docs = []
|
||||
for i, doc in enumerate(docs):
|
||||
doc_string = f"<doc id='{i}'>{doc.page_content}</doc>"
|
||||
formatted_docs.append(doc_string)
|
||||
return "\n".join(formatted_docs)
|
||||
|
||||
|
||||
def serialize_history(request: ChatRequest):
|
||||
chat_history = request.get("chat_history") or []
|
||||
converted_chat_history = []
|
||||
for message in chat_history:
|
||||
if message.get("human") is not None:
|
||||
converted_chat_history.append(HumanMessage(content=message["human"]))
|
||||
if message.get("ai") is not None:
|
||||
converted_chat_history.append(AIMessage(content=message["ai"]))
|
||||
return converted_chat_history
|
||||
|
||||
|
||||
def create_response_chain(
|
||||
llm: BaseLanguageModel,
|
||||
retriever: BaseRetriever,
|
||||
) -> Runnable:
|
||||
retriever_chain = create_retriever_chain(
|
||||
llm,
|
||||
retriever,
|
||||
).with_config(run_name="FindDocs")
|
||||
_context = RunnableMap(
|
||||
{
|
||||
"context": retriever_chain | format_docs,
|
||||
"question": itemgetter("question"),
|
||||
"chat_history": itemgetter("chat_history"),
|
||||
}
|
||||
).with_config(run_name="RetrieveDocs")
|
||||
prompt = ChatPromptTemplate.from_messages(
|
||||
[
|
||||
("system", RESPONSE_TEMPLATE),
|
||||
MessagesPlaceholder(variable_name="chat_history"),
|
||||
("human", "{question}"),
|
||||
]
|
||||
)
|
||||
|
||||
response_generator = (prompt | llm | StrOutputParser()).with_config(
|
||||
run_name="GenerateResponse",
|
||||
)
|
||||
return (
|
||||
{
|
||||
"question": RunnableLambda(itemgetter("question")).with_config(
|
||||
run_name="Itemgetter:question"
|
||||
),
|
||||
"chat_history": RunnableLambda(serialize_history).with_config(
|
||||
run_name="SerializeHistory"
|
||||
),
|
||||
}
|
||||
| _context
|
||||
| response_generator
|
||||
)
|
||||
|
||||
|
||||
llm = ChatOpenAI(
|
||||
model="gpt-3.5-turbo-16k",
|
||||
streaming=True,
|
||||
temperature=0,
|
||||
)
|
||||
|
||||
retriever = get_retriever()
|
||||
chain = create_response_chain(
|
||||
llm,
|
||||
retriever,
|
||||
)
|
||||
chain = chain.with_types(input_type=ChatRequest)
|
||||
|
||||
|
||||
def create_chain(config: dict):
|
||||
config_copy = config.copy()
|
||||
chat_cls_name = config_copy.pop("chat_cls", "ChatOpenAI")
|
||||
|
||||
assert chat_cls_name in {"ChatOpenAI", "ChatFireworks", "ChatAnthropic"}
|
||||
chat_cls = {
|
||||
"ChatOpenAI": ChatOpenAI,
|
||||
"ChatFireworks": ChatFireworks,
|
||||
"ChatAnthropic": ChatAnthropic,
|
||||
}[chat_cls_name]
|
||||
model = chat_cls(**config_copy)
|
||||
retriever = get_retriever(config.get("retriever_config", {}))
|
||||
return create_response_chain(
|
||||
model,
|
||||
retriever,
|
||||
)
|
||||
@@ -0,0 +1,34 @@
|
||||
[tool.poetry]
|
||||
name = "chat-langchain"
|
||||
version = "0.0.1"
|
||||
description = ""
|
||||
authors = []
|
||||
readme = "README.md"
|
||||
|
||||
[tool.poetry.dependencies]
|
||||
openai = ">1,<2"
|
||||
python = "^3.10"
|
||||
fastapi = "^0.104.1"
|
||||
pydantic = "1.10"
|
||||
langchain = ">=0.0.327,<0.1.0"
|
||||
uvicorn = "^0.23.2"
|
||||
beautifulsoup4 = "^4.12.2"
|
||||
tiktoken = "^0.4.0"
|
||||
weaviate-client = "^3.23.2"
|
||||
psycopg2 = "^2.9.7"
|
||||
lxml = "^4.9.3"
|
||||
langserve = {extras = ["server"], version = ">=0.0.21,<0.1.0"}
|
||||
anthropic = "^0.5.0"
|
||||
|
||||
[tool.poetry.group.dev.dependencies]
|
||||
langchain-cli = ">=0.0.4"
|
||||
fastapi = "^0.104.0"
|
||||
sse-starlette = "^1.6.5"
|
||||
|
||||
[tool.langserve]
|
||||
export_module = "chat_langchain"
|
||||
export_attr = "chain"
|
||||
|
||||
[build-system]
|
||||
requires = ["poetry-core"]
|
||||
build-backend = "poetry.core.masonry.api"
|
||||
@@ -0,0 +1,32 @@
|
||||
from langchain.chat_models import ChatAnthropic, ChatOpenAI
|
||||
from langchain.prompts import ChatPromptTemplate
|
||||
from langchain.schema.output_parser import StrOutputParser
|
||||
from langchain_docs_retriever.retriever import get_retriever
|
||||
|
||||
|
||||
def create_runnable(config: dict):
|
||||
config_copy = config.copy()
|
||||
chat_cls_name = config_copy.pop("chat_cls", "ChatOpenAI")
|
||||
|
||||
assert chat_cls_name in {"ChatOpenAI", "ChatAnthropic"}
|
||||
chat_cls = {
|
||||
"ChatOpenAI": ChatOpenAI,
|
||||
"ChatAnthropic": ChatAnthropic,
|
||||
}[chat_cls_name]
|
||||
model = chat_cls(**config_copy)
|
||||
retriever = get_retriever(config.get("retriever_config", {}))
|
||||
prompt = ChatPromptTemplate.from_messages(
|
||||
[
|
||||
("system", "Answer the Q using the following docs\n{docs}"),
|
||||
("user", "Q: {question}"),
|
||||
]
|
||||
)
|
||||
return (
|
||||
{
|
||||
"question": lambda x: x["question"],
|
||||
"docs": (lambda x: x["question"]) | retriever,
|
||||
}
|
||||
| prompt
|
||||
| model
|
||||
| StrOutputParser()
|
||||
)
|
||||
@@ -0,0 +1,5 @@
|
||||
# LangChain Docs Retriever
|
||||
|
||||
|
||||
A simple vector store retriever over the LangChain python docs. Indexed
|
||||
simply using [ingest_docs.py](./ingest_docs.py).
|
||||
@@ -0,0 +1,242 @@
|
||||
"""Load html from files, clean up, split, ingest into Weaviate."""
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
from typing import Generator
|
||||
|
||||
from bs4 import BeautifulSoup, Doctype, NavigableString, SoupStrainer, Tag
|
||||
from langchain.document_loaders import RecursiveUrlLoader, SitemapLoader
|
||||
from langchain.embeddings import OpenAIEmbeddings, VoyageEmbeddings
|
||||
from langchain.indexes import SQLRecordManager, index
|
||||
from langchain.schema.embeddings import Embeddings
|
||||
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
||||
from langchain.utils.html import PREFIXES_TO_IGNORE_REGEX, SUFFIXES_TO_IGNORE_REGEX
|
||||
from langchain.vectorstores.chroma import Chroma
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
directory = os.path.dirname(os.path.realpath(__file__))
|
||||
db_directory = os.path.join(directory, "langchain_docs_retriever", "db")
|
||||
|
||||
|
||||
def langchain_docs_extractor(soup: BeautifulSoup) -> str:
|
||||
# Remove all the tags that are not meaningful for the extraction.
|
||||
SCAPE_TAGS = ["nav", "footer", "aside", "script", "style"]
|
||||
[tag.decompose() for tag in soup.find_all(SCAPE_TAGS)]
|
||||
|
||||
def get_text(tag: Tag) -> Generator[str, None, None]:
|
||||
for child in tag.children:
|
||||
if isinstance(child, Doctype):
|
||||
continue
|
||||
|
||||
if isinstance(child, NavigableString):
|
||||
yield child
|
||||
elif isinstance(child, Tag):
|
||||
if child.name in ["h1", "h2", "h3", "h4", "h5", "h6"]:
|
||||
yield f"{'#' * int(child.name[1:])} {child.get_text()}\n\n"
|
||||
elif child.name == "a":
|
||||
yield f"[{child.get_text(strip=False)}]({child.get('href')})"
|
||||
elif child.name == "img":
|
||||
yield f"})"
|
||||
elif child.name in ["strong", "b"]:
|
||||
yield f"**{child.get_text(strip=False)}**"
|
||||
elif child.name in ["em", "i"]:
|
||||
yield f"_{child.get_text(strip=False)}_"
|
||||
elif child.name == "br":
|
||||
yield "\n"
|
||||
elif child.name == "code":
|
||||
parent = child.find_parent()
|
||||
if parent is not None and parent.name == "pre":
|
||||
classes = parent.attrs.get("class", "")
|
||||
|
||||
language = next(
|
||||
filter(lambda x: re.match(r"language-\w+", x), classes),
|
||||
None,
|
||||
)
|
||||
if language is None:
|
||||
language = ""
|
||||
else:
|
||||
language = language.split("-")[1]
|
||||
|
||||
lines: list[str] = []
|
||||
for span in child.find_all("span", class_="token-line"):
|
||||
line_content = "".join(
|
||||
token.get_text() for token in span.find_all("span")
|
||||
)
|
||||
lines.append(line_content)
|
||||
|
||||
code_content = "\n".join(lines)
|
||||
yield f"```{language}\n{code_content}\n```\n\n"
|
||||
else:
|
||||
yield f"`{child.get_text(strip=False)}`"
|
||||
|
||||
elif child.name == "p":
|
||||
yield from get_text(child)
|
||||
yield "\n\n"
|
||||
elif child.name == "ul":
|
||||
for li in child.find_all("li", recursive=False):
|
||||
yield "- "
|
||||
yield from get_text(li)
|
||||
yield "\n\n"
|
||||
elif child.name == "ol":
|
||||
for i, li in enumerate(child.find_all("li", recursive=False)):
|
||||
yield f"{i + 1}. "
|
||||
yield from get_text(li)
|
||||
yield "\n\n"
|
||||
elif child.name == "div" and "tabs-container" in child.attrs.get(
|
||||
"class", [""]
|
||||
):
|
||||
tabs = child.find_all("li", {"role": "tab"})
|
||||
tab_panels = child.find_all("div", {"role": "tabpanel"})
|
||||
for tab, tab_panel in zip(tabs, tab_panels):
|
||||
tab_name = tab.get_text(strip=True)
|
||||
yield f"{tab_name}\n"
|
||||
yield from get_text(tab_panel)
|
||||
elif child.name == "table":
|
||||
thead = child.find("thead")
|
||||
header_exists = isinstance(thead, Tag)
|
||||
if header_exists:
|
||||
headers = thead.find_all("th")
|
||||
if headers:
|
||||
yield "| "
|
||||
yield " | ".join(header.get_text() for header in headers)
|
||||
yield " |\n"
|
||||
yield "| "
|
||||
yield " | ".join("----" for _ in headers)
|
||||
yield " |\n"
|
||||
|
||||
tbody = child.find("tbody")
|
||||
tbody_exists = isinstance(tbody, Tag)
|
||||
if tbody_exists:
|
||||
for row in tbody.find_all("tr"):
|
||||
yield "| "
|
||||
yield " | ".join(
|
||||
cell.get_text(strip=True) for cell in row.find_all("td")
|
||||
)
|
||||
yield " |\n"
|
||||
|
||||
yield "\n\n"
|
||||
elif child.name in ["button"]:
|
||||
continue
|
||||
else:
|
||||
yield from get_text(child)
|
||||
|
||||
joined = "".join(get_text(soup))
|
||||
return re.sub(r"\n\n+", "\n\n", joined).strip()
|
||||
|
||||
|
||||
RECORD_MANAGER_DB_URL = (
|
||||
os.environ.get("RECORD_MANAGER_DB_URL") or "sqlite:///lcdocs_oai_record_manager.sql"
|
||||
)
|
||||
|
||||
|
||||
def metadata_extractor(meta: dict, soup: BeautifulSoup) -> dict:
|
||||
title = soup.find("title")
|
||||
description = soup.find("meta", attrs={"name": "description"})
|
||||
html = soup.find("html")
|
||||
return {
|
||||
"source": meta["loc"] or "",
|
||||
"title": (title.get_text() if title else "") or "",
|
||||
"description": description.get("content") or "" if description else "",
|
||||
"language": html.get("lang") or "" if html else "",
|
||||
**{k: v or "" for k, v in meta.items()},
|
||||
}
|
||||
|
||||
|
||||
def load_langchain_docs():
|
||||
return SitemapLoader(
|
||||
"https://python.langchain.com/sitemap.xml",
|
||||
filter_urls=["https://python.langchain.com/"],
|
||||
parsing_function=langchain_docs_extractor,
|
||||
default_parser="lxml",
|
||||
bs_kwargs={
|
||||
"parse_only": SoupStrainer(
|
||||
name=("article", "title", "html", "lang", "content")
|
||||
),
|
||||
},
|
||||
meta_function=metadata_extractor,
|
||||
).load()
|
||||
|
||||
|
||||
def simple_extractor(html: str) -> str:
|
||||
soup = BeautifulSoup(html, "lxml")
|
||||
return re.sub(r"\n\n+", "\n\n", soup.text).strip()
|
||||
|
||||
|
||||
def load_api_docs():
|
||||
return RecursiveUrlLoader(
|
||||
url="https://api.python.langchain.com/en/latest/",
|
||||
max_depth=8,
|
||||
extractor=simple_extractor,
|
||||
prevent_outside=True,
|
||||
use_async=True,
|
||||
timeout=600,
|
||||
# Drop trailing / to avoid duplicate pages.
|
||||
link_regex=(
|
||||
f"href=[\"']{PREFIXES_TO_IGNORE_REGEX}((?:{SUFFIXES_TO_IGNORE_REGEX}.)*?)"
|
||||
r"(?:[\#'\"]|\/[\#'\"])"
|
||||
),
|
||||
check_response_status=True,
|
||||
exclude_dirs=(
|
||||
"https://api.python.langchain.com/en/latest/_sources",
|
||||
"https://api.python.langchain.com/en/latest/_modules",
|
||||
),
|
||||
).load()
|
||||
|
||||
|
||||
def get_embeddings_model() -> Embeddings:
|
||||
if os.environ.get("VOYAGE_AI_URL") and os.environ.get("VOYAGE_AI_MODEL"):
|
||||
return VoyageEmbeddings()
|
||||
return OpenAIEmbeddings(chunk_size=200)
|
||||
|
||||
|
||||
CHROMA_COLLECTION_NAME = "langchain-docs"
|
||||
|
||||
|
||||
def ingest_docs():
|
||||
docs_from_documentation = load_langchain_docs()
|
||||
logger.info(f"Loaded {len(docs_from_documentation)} docs from documentation")
|
||||
docs_from_api = load_api_docs()
|
||||
logger.info(f"Loaded {len(docs_from_api)} docs from API")
|
||||
|
||||
text_splitter = RecursiveCharacterTextSplitter(chunk_size=4000, chunk_overlap=200)
|
||||
docs_transformed = text_splitter.split_documents(
|
||||
docs_from_documentation + docs_from_api
|
||||
)
|
||||
|
||||
# We try to return 'source' and 'title' metadata when querying vector store and
|
||||
# Chroma will error at query time if one of the attributes is missing from a
|
||||
# retrieved document.
|
||||
for doc in docs_transformed:
|
||||
if "source" not in doc.metadata:
|
||||
doc.metadata["source"] = ""
|
||||
if "title" not in doc.metadata:
|
||||
doc.metadata["title"] = ""
|
||||
for k, v in doc.metadata.items():
|
||||
if v is None:
|
||||
doc.metadata[k] = ""
|
||||
|
||||
embedding = get_embeddings_model()
|
||||
vectorstore = Chroma(
|
||||
collection_name=CHROMA_COLLECTION_NAME,
|
||||
embedding_function=embedding,
|
||||
persist_directory=db_directory,
|
||||
)
|
||||
|
||||
record_manager = SQLRecordManager(
|
||||
f"chroma/{CHROMA_COLLECTION_NAME}", db_url=RECORD_MANAGER_DB_URL
|
||||
)
|
||||
record_manager.create_schema()
|
||||
|
||||
indexing_stats = index(
|
||||
docs_transformed,
|
||||
record_manager,
|
||||
vectorstore,
|
||||
cleanup="full",
|
||||
source_id_key="source",
|
||||
)
|
||||
|
||||
logger.info("Indexing stats: ", indexing_stats)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
ingest_docs()
|
||||
@@ -0,0 +1,34 @@
|
||||
import os
|
||||
import zipfile
|
||||
|
||||
import requests
|
||||
|
||||
remote_url = "https://storage.googleapis.com/benchmarks-artifacts/langchain-docs-benchmarking/chroma_db.zip"
|
||||
directory = os.path.dirname(os.path.realpath(__file__))
|
||||
db_directory = os.path.join(directory, "db")
|
||||
|
||||
|
||||
def is_folder_populated(folder):
|
||||
if os.path.exists(folder):
|
||||
return any(os.scandir(folder))
|
||||
return False
|
||||
|
||||
|
||||
def download_folder_from_gcs():
|
||||
r = requests.get(remote_url, allow_redirects=True)
|
||||
open("chroma_db.zip", "wb").write(r.content)
|
||||
|
||||
with zipfile.ZipFile("chroma_db.zip", "r") as zip_ref:
|
||||
zip_ref.extractall(directory)
|
||||
|
||||
os.remove("chroma_db.zip")
|
||||
|
||||
|
||||
def fetch_langchain_docs_db():
|
||||
if not is_folder_populated(db_directory):
|
||||
print(f"Folder {db_directory} is not populated. Downloading from GCS...")
|
||||
download_folder_from_gcs()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
fetch_langchain_docs_db()
|
||||
@@ -0,0 +1,35 @@
|
||||
import os
|
||||
from typing import Optional
|
||||
|
||||
from langchain.embeddings import OpenAIEmbeddings
|
||||
|
||||
# from langchain_docs_retriever.voyage import VoyageEmbeddings
|
||||
from langchain.embeddings.voyageai import VoyageEmbeddings
|
||||
from langchain.schema.embeddings import Embeddings
|
||||
from langchain.schema.retriever import BaseRetriever
|
||||
from langchain.vectorstores.chroma import Chroma
|
||||
|
||||
from .download_db import fetch_langchain_docs_db
|
||||
|
||||
WEAVIATE_DOCS_INDEX_NAME = "LangChain_agent_docs"
|
||||
_DIRECTORY = os.path.dirname(os.path.abspath(__file__))
|
||||
CHROMA_COLLECTION_NAME = "langchain-docs"
|
||||
_DB_DIRECTORY = os.path.join(_DIRECTORY, "db")
|
||||
|
||||
|
||||
def get_embeddings_model() -> Embeddings:
|
||||
if os.environ.get("VOYAGE_AI_MODEL"):
|
||||
return VoyageEmbeddings(model=os.environ["VOYAGE_AI_MODEL"], max_retries=20)
|
||||
return OpenAIEmbeddings(chunk_size=200)
|
||||
|
||||
|
||||
def get_retriever(search_kwargs: Optional[dict] = None) -> BaseRetriever:
|
||||
embedding_model = get_embeddings_model()
|
||||
fetch_langchain_docs_db()
|
||||
vectorstore = Chroma(
|
||||
collection_name=CHROMA_COLLECTION_NAME,
|
||||
embedding_function=embedding_model,
|
||||
persist_directory=_DB_DIRECTORY,
|
||||
)
|
||||
search_kwargs = search_kwargs or dict(k=6)
|
||||
return vectorstore.as_retriever(search_kwargs=search_kwargs)
|
||||
@@ -0,0 +1,31 @@
|
||||
[tool.poetry]
|
||||
name = "langchain-docs-retriever"
|
||||
version = "0.0.1"
|
||||
description = ""
|
||||
authors = []
|
||||
readme = "README.md"
|
||||
|
||||
[tool.poetry.dependencies]
|
||||
python = "^3.10"
|
||||
fastapi = "^0.104.1"
|
||||
pydantic = "1.10"
|
||||
langchain = ">=0.0.331,<0.1.0"
|
||||
uvicorn = "^0.23.2"
|
||||
openai = ">1,<2"
|
||||
psycopg2 = "^2.9.7"
|
||||
lxml = "^4.9.3"
|
||||
langserve = {extras = ["server"], version = ">=0.0.23,<0.1.0"}
|
||||
chromadb = "^0.4.15"
|
||||
|
||||
[tool.poetry.group.dev.dependencies]
|
||||
langchain-cli = ">=0.0.4"
|
||||
fastapi = "^0.104.0"
|
||||
sse-starlette = "^1.6.5"
|
||||
|
||||
[tool.langserve]
|
||||
export_module = "chat_langchain"
|
||||
export_attr = "chain"
|
||||
|
||||
[build-system]
|
||||
requires = ["poetry-core"]
|
||||
build-backend = "poetry.core.masonry.api"
|
||||
@@ -0,0 +1,21 @@
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2023 LangChain, Inc.
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
@@ -0,0 +1,66 @@
|
||||
# oai-assistant
|
||||
|
||||
TODO: What does this package do
|
||||
|
||||
## Environment Setup
|
||||
|
||||
TODO: What environment variables need to be set (if any)
|
||||
|
||||
## Usage
|
||||
|
||||
To use this package, you should first have the LangChain CLI installed:
|
||||
|
||||
```shell
|
||||
pip install -U "langchain-cli[serve]"
|
||||
```
|
||||
|
||||
To create a new LangChain project and install this as the only package, you can do:
|
||||
|
||||
```shell
|
||||
langchain app new my-app --package oai-assistant
|
||||
```
|
||||
|
||||
If you want to add this to an existing project, you can just run:
|
||||
|
||||
```shell
|
||||
langchain app add oai-assistant
|
||||
```
|
||||
|
||||
And add the following code to your `server.py` file:
|
||||
```python
|
||||
from oai_assistant import chain as oai_assistant_chain
|
||||
|
||||
add_routes(app, oai_assistant_chain, path="/oai-assistant")
|
||||
```
|
||||
|
||||
(Optional) Let's now configure LangSmith.
|
||||
LangSmith will help us trace, monitor and debug LangChain applications.
|
||||
LangSmith is currently in private beta, you can sign up [here](https://smith.langchain.com/).
|
||||
If you don't have access, you can skip this section
|
||||
|
||||
|
||||
```shell
|
||||
export LANGCHAIN_TRACING_V2=true
|
||||
export LANGCHAIN_API_KEY=<your-api-key>
|
||||
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
|
||||
```
|
||||
|
||||
If you are inside this directory, then you can spin up a LangServe instance directly by:
|
||||
|
||||
```shell
|
||||
langchain serve
|
||||
```
|
||||
|
||||
This will start the FastAPI app with a server is running locally at
|
||||
[http://localhost:8000](http://localhost:8000)
|
||||
|
||||
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs)
|
||||
We can access the playground at [http://127.0.0.1:8000/oai-assistant/playground](http://127.0.0.1:8000/oai-assistant/playground)
|
||||
|
||||
We can access the template from code with:
|
||||
|
||||
```python
|
||||
from langserve.client import RemoteRunnable
|
||||
|
||||
runnable = RemoteRunnable("http://localhost:8000/oai-assistant")
|
||||
```
|
||||
@@ -0,0 +1,3 @@
|
||||
from oai_assistant.chain import agent_executor
|
||||
|
||||
__all__ = ["agent_executor"]
|
||||
@@ -0,0 +1,36 @@
|
||||
import json
|
||||
|
||||
from langchain.agents import AgentExecutor
|
||||
from langchain.tools import tool
|
||||
from langchain_docs_retriever.retriever import get_retriever
|
||||
from langchain_experimental.openai_assistant import OpenAIAssistantRunnable
|
||||
|
||||
# This is used to tell the model how to best use the retriever.
|
||||
|
||||
|
||||
_RETRIEVER = get_retriever()
|
||||
|
||||
|
||||
@tool
|
||||
def search(query, callbacks=None) -> str:
|
||||
"""Search the LangChain docs with the retriever."""
|
||||
docs = _RETRIEVER.get_relevant_documents(query, callbacks=callbacks)
|
||||
return json.dumps([doc.dict() for doc in docs])
|
||||
|
||||
|
||||
tools = [search]
|
||||
|
||||
agent = OpenAIAssistantRunnable.create_assistant(
|
||||
name="langchain docs assistant",
|
||||
instructions="You are a helpful assistant tasked with answering technical questions about LangChain.",
|
||||
tools=tools,
|
||||
model="gpt-4-1106-preview",
|
||||
as_agent=True,
|
||||
)
|
||||
|
||||
|
||||
agent_executor = (
|
||||
(lambda x: {"content": x["question"]})
|
||||
| AgentExecutor(agent=agent, tools=tools)
|
||||
| (lambda x: x["output"])
|
||||
)
|
||||
@@ -0,0 +1,25 @@
|
||||
[tool.poetry]
|
||||
name = "oai-assistant"
|
||||
version = "0.0.1"
|
||||
description = ""
|
||||
authors = []
|
||||
readme = "README.md"
|
||||
|
||||
[tool.poetry.dependencies]
|
||||
python = ">=3.8.1,<4.0"
|
||||
langchain = ">=0.0.332,<0.1.0"
|
||||
openai = ">1,<2"
|
||||
langchain-experimental = "^0.0.38"
|
||||
|
||||
[tool.poetry.group.dev.dependencies]
|
||||
langchain-cli = ">=0.0.4"
|
||||
fastapi = "^0.104.0"
|
||||
sse-starlette = "^1.6.5"
|
||||
|
||||
[tool.langserve]
|
||||
export_module = "oai_assistant"
|
||||
export_attr = "agent_executor"
|
||||
|
||||
[build-system]
|
||||
requires = ["poetry-core"]
|
||||
build-backend = "poetry.core.masonry.api"
|
||||
@@ -0,0 +1,21 @@
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2023 LangChain, Inc.
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
@@ -0,0 +1,72 @@
|
||||
|
||||
# openai-functions-agent
|
||||
|
||||
This template creates an agent that uses OpenAI function calling to communicate its decisions on what actions to take.
|
||||
|
||||
This example creates an agent that can optionally look up information on the internet using Tavily's search engine.
|
||||
|
||||
## Environment Setup
|
||||
|
||||
The following environment variables need to be set:
|
||||
|
||||
Set the `OPENAI_API_KEY` environment variable to access the OpenAI models.
|
||||
|
||||
Set the `TAVILY_API_KEY` environment variable to access Tavily.
|
||||
|
||||
## Usage
|
||||
|
||||
To use this package, you should first have the LangChain CLI installed:
|
||||
|
||||
```shell
|
||||
pip install -U "langchain-cli[serve]"
|
||||
```
|
||||
|
||||
To create a new LangChain project and install this as the only package, you can do:
|
||||
|
||||
```shell
|
||||
langchain app new my-app --package openai-functions-agent
|
||||
```
|
||||
|
||||
If you want to add this to an existing project, you can just run:
|
||||
|
||||
```shell
|
||||
langchain app add openai-functions-agent
|
||||
```
|
||||
|
||||
And add the following code to your `server.py` file:
|
||||
```python
|
||||
from openai_functions_agent import chain as openai_functions_agent_chain
|
||||
|
||||
add_routes(app, openai_functions_agent_chain, path="/openai-functions-agent")
|
||||
```
|
||||
|
||||
(Optional) Let's now configure LangSmith.
|
||||
LangSmith will help us trace, monitor and debug LangChain applications.
|
||||
LangSmith is currently in private beta, you can sign up [here](https://smith.langchain.com/).
|
||||
If you don't have access, you can skip this section
|
||||
|
||||
```shell
|
||||
export LANGCHAIN_TRACING_V2=true
|
||||
export LANGCHAIN_API_KEY=<your-api-key>
|
||||
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
|
||||
```
|
||||
|
||||
If you are inside this directory, then you can spin up a LangServe instance directly by:
|
||||
|
||||
```shell
|
||||
langchain serve
|
||||
```
|
||||
|
||||
This will start the FastAPI app with a server is running locally at
|
||||
[http://localhost:8000](http://localhost:8000)
|
||||
|
||||
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs)
|
||||
We can access the playground at [http://127.0.0.1:8000/openai-functions-agent/playground](http://127.0.0.1:8000/openai-functions-agent/playground)
|
||||
|
||||
We can access the template from code with:
|
||||
|
||||
```python
|
||||
from langserve.client import RemoteRunnable
|
||||
|
||||
runnable = RemoteRunnable("http://localhost:8000/openai-functions-agent")
|
||||
```
|
||||
@@ -0,0 +1,5 @@
|
||||
from openai_functions_agent.agent import agent_executor
|
||||
|
||||
if __name__ == "__main__":
|
||||
question = "who won the womens world cup in 2023?"
|
||||
print(agent_executor.invoke({"input": question, "chat_history": []}))
|
||||
@@ -0,0 +1,3 @@
|
||||
from openai_functions_agent.agent import agent_executor
|
||||
|
||||
__all__ = ["agent_executor"]
|
||||
@@ -0,0 +1,85 @@
|
||||
from typing import List, Tuple
|
||||
|
||||
from langchain.agents import AgentExecutor
|
||||
from langchain.agents.format_scratchpad import format_to_openai_functions
|
||||
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
|
||||
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
|
||||
from langchain.schema.messages import AIMessage, HumanMessage
|
||||
from langchain.tools import tool
|
||||
from langchain.tools.render import format_tool_to_openai_function
|
||||
from langchain_docs_retriever.retriever import get_retriever
|
||||
from langchain_openai import ChatOpenAI
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
# This is used to tell the model how to best use the retriever.
|
||||
|
||||
|
||||
_RETRIEVER = get_retriever()
|
||||
|
||||
|
||||
@tool
|
||||
def search(query, callbacks=None):
|
||||
"""Search the LangChain docs with the retriever."""
|
||||
return _RETRIEVER.get_relevant_documents(query, callbacks=callbacks)
|
||||
|
||||
|
||||
tools = [search]
|
||||
|
||||
llm = ChatOpenAI(model="gpt-3.5-turbo-16k", temperature=0)
|
||||
assistant_system_message = """You are a helpful assistant tasked with answering technical questions about LangChain. \
|
||||
Use tools (only if necessary) to best answer the users questions. Do not make up information if you cannot find the answer using your tools."""
|
||||
prompt = ChatPromptTemplate.from_messages(
|
||||
[
|
||||
("system", assistant_system_message),
|
||||
MessagesPlaceholder(variable_name="chat_history"),
|
||||
("user", "{input}"),
|
||||
MessagesPlaceholder(variable_name="agent_scratchpad"),
|
||||
]
|
||||
)
|
||||
|
||||
llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools])
|
||||
|
||||
|
||||
def _format_chat_history(chat_history: List[Tuple[str, str]]):
|
||||
buffer = []
|
||||
for human, ai in chat_history:
|
||||
buffer.append(HumanMessage(content=human))
|
||||
buffer.append(AIMessage(content=ai))
|
||||
return buffer
|
||||
|
||||
|
||||
agent = (
|
||||
{
|
||||
"input": lambda x: x["input"],
|
||||
"chat_history": lambda x: _format_chat_history(x["chat_history"]),
|
||||
"agent_scratchpad": lambda x: format_to_openai_functions(
|
||||
x["intermediate_steps"]
|
||||
),
|
||||
}
|
||||
| prompt
|
||||
| llm_with_tools
|
||||
| OpenAIFunctionsAgentOutputParser()
|
||||
)
|
||||
|
||||
|
||||
class AgentInput(BaseModel):
|
||||
input: str
|
||||
chat_history: List[Tuple[str, str]] = Field(..., extra={"widget": {"type": "chat"}})
|
||||
|
||||
|
||||
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=False).with_types(
|
||||
input_type=AgentInput
|
||||
)
|
||||
|
||||
|
||||
class ChainInput(BaseModel):
|
||||
question: str
|
||||
|
||||
|
||||
def mapper(input: dict):
|
||||
return {"input": input["question"], "chat_history": []}
|
||||
|
||||
|
||||
agent_executor = (mapper | agent_executor | (lambda x: x["output"])).with_types(
|
||||
input_type=ChainInput
|
||||
)
|
||||
@@ -0,0 +1,24 @@
|
||||
[tool.poetry]
|
||||
name = "openai-functions-agent"
|
||||
version = "0.1.0"
|
||||
description = ""
|
||||
authors = [
|
||||
"Lance Martin <lance@langchain.dev>",
|
||||
]
|
||||
readme = "README.md"
|
||||
|
||||
[tool.poetry.dependencies]
|
||||
python = ">=3.8.1,<4.0"
|
||||
langchain = ">=0.0.327,<0.1.0"
|
||||
openai = ">=0.5.0"
|
||||
tavily-python = "^0.1.9"
|
||||
|
||||
[tool.langserve]
|
||||
export_module = "openai_functions_agent"
|
||||
export_attr = "agent_executor"
|
||||
|
||||
[build-system]
|
||||
requires = [
|
||||
"poetry-core",
|
||||
]
|
||||
build-backend = "poetry.core.masonry.api"
|
||||
@@ -0,0 +1,57 @@
|
||||
"""Copy the public dataset to your own langsmith tenant."""
|
||||
from typing import Optional
|
||||
|
||||
from langsmith import Client
|
||||
|
||||
DATASET_NAME = "LangChain Docs Q&A"
|
||||
PUBLIC_DATASET_TOKEN = "452ccafc-18e1-4314-885b-edd735f17b9d"
|
||||
|
||||
|
||||
def create_langchain_docs_dataset(
|
||||
dataset_name: str = DATASET_NAME,
|
||||
public_dataset_token: str = PUBLIC_DATASET_TOKEN,
|
||||
client: Optional[Client] = None,
|
||||
):
|
||||
shared_client = Client(
|
||||
api_url="https://api.smith.langchain.com", api_key="placeholder"
|
||||
)
|
||||
examples = list(shared_client.list_shared_examples(public_dataset_token))
|
||||
client = client or Client()
|
||||
if client.has_dataset(dataset_name=dataset_name):
|
||||
loaded_examples = list(client.list_examples(dataset_name=dataset_name))
|
||||
if len(loaded_examples) == len(examples):
|
||||
return
|
||||
else:
|
||||
ds = client.read_dataset(dataset_name=dataset_name)
|
||||
else:
|
||||
ds = client.create_dataset(dataset_name=dataset_name)
|
||||
client.create_examples(
|
||||
inputs=[e.inputs for e in examples],
|
||||
outputs=[e.outputs for e in examples],
|
||||
dataset_id=ds.id,
|
||||
)
|
||||
print("Done creating dataset.")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import argparse
|
||||
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--target-api-key", type=str, required=False)
|
||||
parser.add_argument("--target-endpoint", type=str, required=False)
|
||||
parser.add_argument("--dataset-name", type=str, default=DATASET_NAME)
|
||||
parser.add_argument(
|
||||
"--public-dataset-token", type=str, default=PUBLIC_DATASET_TOKEN
|
||||
)
|
||||
args = parser.parse_args()
|
||||
client = None
|
||||
if args.target_api_key or args.target_endpoint:
|
||||
client = Client(
|
||||
api_key=args.target_api_key,
|
||||
api_url=args.target_endpoint,
|
||||
)
|
||||
create_langchain_docs_dataset(
|
||||
dataset_name=args.dataset_name,
|
||||
public_dataset_token=args.public_dataset_token,
|
||||
client=client,
|
||||
)
|
||||
@@ -0,0 +1,29 @@
|
||||
[tool.poetry]
|
||||
name = "langservehub-template"
|
||||
version = "0.1.0"
|
||||
description = ""
|
||||
authors = ["Your Name <you@example.com>"]
|
||||
readme = "README.md"
|
||||
|
||||
[tool.poetry.dependencies]
|
||||
python = "^3.11"
|
||||
langsmith = ">=0.0.64,<0.1.0"
|
||||
sse-starlette = "^1.6.5"
|
||||
tomli-w = "^1.0.0"
|
||||
uvicorn = "^0.23.2"
|
||||
fastapi = "^0.104"
|
||||
langserve = ">=0.0.16"
|
||||
chat-langchain = {path = "packages/chat-langchain", develop = true}
|
||||
langchain-docs-retriever = {path = "packages/langchain-docs-retriever", develop = true}
|
||||
anthropic-iterative-search = {path = "packages/anthropic-iterative-search", develop = true}
|
||||
oai-assistant = {path = "packages/oai-assistant", develop = true}
|
||||
openai-functions-agent = {path = "packages/openai-functions-agent", develop = true}
|
||||
|
||||
[tool.poetry.group.dev.dependencies]
|
||||
uvicorn = "^0.23.2"
|
||||
pygithub = "^2.1.1"
|
||||
|
||||
|
||||
[build-system]
|
||||
requires = ["poetry-core"]
|
||||
build-backend = "poetry.core.masonry.api"
|
||||
@@ -0,0 +1,120 @@
|
||||
import argparse
|
||||
import importlib.util
|
||||
import sys
|
||||
import uuid
|
||||
from functools import partial
|
||||
from typing import Callable, Optional
|
||||
|
||||
from anthropic_iterative_search.chain import chain as anthropic_agent_chain
|
||||
from chat_langchain.chain import create_chain
|
||||
from langchain.schema.runnable import Runnable
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
from oai_assistant.chain import agent_executor as openai_assistant_chain
|
||||
from openai_functions_agent import agent_executor as openai_functions_agent_chain
|
||||
|
||||
ls_client = Client()
|
||||
|
||||
|
||||
def import_from_path(path_name: str):
|
||||
func_name = "create_chain"
|
||||
if "::" in path_name:
|
||||
path_name, func_name = path_name.split("::")
|
||||
spec = importlib.util.spec_from_file_location("module_name", path_name)
|
||||
module = importlib.util.module_from_spec(spec)
|
||||
sys.modules["module_name"] = module
|
||||
spec.loader.exec_module(module)
|
||||
return getattr(module, func_name)
|
||||
|
||||
|
||||
def _get_chain_factory(arch: str) -> Callable:
|
||||
_map = {
|
||||
"chat": create_chain,
|
||||
"anthropic-iterative-search": lambda _: anthropic_agent_chain,
|
||||
"openai-functions-agent": lambda _: openai_functions_agent_chain,
|
||||
"openai-assistant": lambda _: openai_assistant_chain,
|
||||
}
|
||||
if arch in _map:
|
||||
return _map[arch]
|
||||
else:
|
||||
return import_from_path(arch)
|
||||
|
||||
|
||||
def create_runnable(
|
||||
arch: str, model_config: Optional[dict], retry_config: Optional[dict] = None
|
||||
):
|
||||
factory = _get_chain_factory(arch)
|
||||
chain: Runnable = factory(model_config)
|
||||
if retry_config:
|
||||
return chain.with_retry(**retry_config)
|
||||
return chain
|
||||
|
||||
|
||||
def get_eval_config():
|
||||
accuracy_criteria = {
|
||||
"accuracy": """
|
||||
Score 1: The answer is incorrect and unrelated to the question or reference document.
|
||||
Score 3: The answer shows slight relevance to the question or reference document but is largely incorrect.
|
||||
Score 5: The answer is partially correct but has significant errors or omissions.
|
||||
Score 7: The answer is mostly correct with minor errors or omissions, and aligns with the reference document.
|
||||
Score 10: The answer is correct, complete, and perfectly aligns with the reference document.
|
||||
|
||||
If the reference answer contains multiple alternatives, the predicted answer must only match one of the alternatives to be considered correct.
|
||||
If the predicted answer contains additional helpful and accurate information that is not present in the reference answer, it should still be considered correct.
|
||||
""" # noqa
|
||||
}
|
||||
|
||||
eval_llm = ChatOpenAI(model="gpt-4", temperature=0.0)
|
||||
return RunEvalConfig(
|
||||
evaluators=[
|
||||
RunEvalConfig.LabeledScoreString(
|
||||
criteria=accuracy_criteria, llm=eval_llm, normalize_by=10.0
|
||||
),
|
||||
# Mainly to compare with the above
|
||||
# Suspected to be less reliable.
|
||||
RunEvalConfig.EmbeddingDistance(),
|
||||
]
|
||||
)
|
||||
|
||||
|
||||
def main(
|
||||
arch: str,
|
||||
dataset_name: str,
|
||||
model_config: Optional[dict] = None,
|
||||
max_concurrency: int = 5,
|
||||
project_name: Optional[str] = None,
|
||||
retry_config: Optional[dict] = None,
|
||||
):
|
||||
eval_config = get_eval_config()
|
||||
project_name = project_name or arch
|
||||
project_name += f" {uuid.uuid4().hex[:4]}"
|
||||
run_on_dataset(
|
||||
client=ls_client,
|
||||
dataset_name=dataset_name,
|
||||
llm_or_chain_factory=partial(
|
||||
create_runnable,
|
||||
arch=arch,
|
||||
model_config=model_config,
|
||||
retry_config=retry_config,
|
||||
),
|
||||
evaluation=eval_config,
|
||||
concurrency_level=max_concurrency,
|
||||
project_name=project_name,
|
||||
project_metadata={"arch": arch, "model_config": model_config},
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--url", type=str)
|
||||
parser.add_argument("--dataset-name", type=str, default="Chat Langchain Pub")
|
||||
parser.add_argument("--project-name", type=Optional[str], default=None)
|
||||
parser.add_argument("--max-concurrency", type=int, default=5)
|
||||
args = parser.parse_args()
|
||||
main(
|
||||
args.url,
|
||||
args.dataset_name,
|
||||
max_concurrency=args.max_concurrency,
|
||||
project_name=args.project_name,
|
||||
)
|
||||
@@ -0,0 +1,127 @@
|
||||
import argparse
|
||||
import json
|
||||
|
||||
from prepare_dataset import create_langchain_docs_dataset
|
||||
from run_evals import main
|
||||
|
||||
experiments = [
|
||||
{
|
||||
# "server_url": "http://localhost:1983/openai-functions-agent",
|
||||
"arch": "openai-functions-agent",
|
||||
"project_name": "openai-functions-agent",
|
||||
},
|
||||
{
|
||||
# "server_url": "http://localhost:1983/anthropic_chat",
|
||||
"arch": "chat",
|
||||
"model_config": {
|
||||
"chat_cls": "ChatAnthropic",
|
||||
"model": "claude-2",
|
||||
"temperature": 1.0,
|
||||
},
|
||||
"project_name": "anthropic-chat",
|
||||
},
|
||||
{
|
||||
"arch": "chat",
|
||||
"model_config": {
|
||||
"chat_cls": "ChatOpenAI",
|
||||
"model": "gpt-3.5-turbo-16k",
|
||||
},
|
||||
# "server_url": "http://localhost:1983/chat",
|
||||
"project_name": "chat-gpt-3.5",
|
||||
},
|
||||
{
|
||||
"arch": "chat",
|
||||
"model_config": {
|
||||
"chat_cls": "ChatFireworks",
|
||||
"model": "accounts/fireworks/models/mistral-7b-instruct-4k",
|
||||
},
|
||||
"project_name": "mistral-7b-instruct-4k",
|
||||
},
|
||||
{
|
||||
"arch": "chat",
|
||||
"model_config": {
|
||||
"chat_cls": "ChatFireworks",
|
||||
"model": "accounts/fireworks/models/llama-v2-34b-code-instruct-w8a16",
|
||||
},
|
||||
"project_name": "llama-v2-34b-code-instruct-w8a16",
|
||||
},
|
||||
{
|
||||
"arch": "chat",
|
||||
"model_config": {
|
||||
"chat_cls": "ChatFireworks",
|
||||
"model": "accounts/fireworks/models/zephyr-7b-beta",
|
||||
},
|
||||
"project_name": "zephyr-7b-beta",
|
||||
},
|
||||
{
|
||||
"arch": "chat",
|
||||
"model_config": {
|
||||
"chat_cls": "ChatOpenAI",
|
||||
"model": "gpt-4",
|
||||
},
|
||||
"project_name": "gpt-4-chat",
|
||||
},
|
||||
{
|
||||
"arch": "openai-assistant",
|
||||
"model_config": {},
|
||||
"project_name": "openai-assistant",
|
||||
"max_concurrency": 2, # Rate limit is VERY low right now.
|
||||
"retry_config": {
|
||||
"stop_after_attempt": 10,
|
||||
},
|
||||
},
|
||||
# Not worth our time it's so bad and slow
|
||||
{
|
||||
# "server_url": "http://localhost:1983/anthropic_iterative_search",
|
||||
"arch": "anthropic-iterative-search",
|
||||
"max_concurrency": 2,
|
||||
"project_name": "anthropic-iterative-search",
|
||||
},
|
||||
]
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--dataset-name", type=str, default="LangChain Docs Q&A")
|
||||
parser.add_argument(
|
||||
"--config",
|
||||
type=str,
|
||||
default=None,
|
||||
nargs="*",
|
||||
help="Path to a JSON file with experiment config."
|
||||
" If specified, the include and exclude args are ignored",
|
||||
)
|
||||
parser.add_argument("--include", type=str, nargs="+", default=None)
|
||||
parser.add_argument(
|
||||
"--exclude",
|
||||
type=str,
|
||||
nargs="+",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
create_langchain_docs_dataset(dataset_name=args.dataset_name)
|
||||
selected_experiments = experiments
|
||||
if args.config:
|
||||
selected_experiments = []
|
||||
for config_path in args.config:
|
||||
with open(config_path) as f:
|
||||
selected_experiments.append(json.load(f))
|
||||
elif args.include:
|
||||
selected_experiments = [
|
||||
e for e in selected_experiments if e["project_name"] in args.include
|
||||
]
|
||||
to_exclude = args.exclude or []
|
||||
if args.include and not to_exclude:
|
||||
to_exclude = [
|
||||
"anthropic-iterative-search",
|
||||
"openai-assistant",
|
||||
]
|
||||
if args.exclude:
|
||||
selected_experiments = [
|
||||
e for e in selected_experiments if e["project_name"] not in args.exclude
|
||||
]
|
||||
|
||||
for experiment in selected_experiments:
|
||||
print("Running experiment:", experiment)
|
||||
main(
|
||||
**experiment,
|
||||
dataset_name=args.dataset_name,
|
||||
)
|
||||
@@ -1,7 +1,9 @@
|
||||
from pathlib import Path
|
||||
from langsmith import Client
|
||||
import json
|
||||
import logging
|
||||
from pathlib import Path
|
||||
|
||||
from langsmith import Client
|
||||
|
||||
logging.basicConfig(level=logging.INFO)
|
||||
|
||||
# Synthetic dataset adapted from https://aclanthology.org/D13-1160/
|
||||
@@ -9,6 +11,7 @@ logging.basicConfig(level=logging.INFO)
|
||||
_DATA_REPO = Path(__file__).parent / "data"
|
||||
_CLIENT = Client()
|
||||
|
||||
|
||||
def _upload_dataset(path: str):
|
||||
with open(path, "r") as f:
|
||||
data = json.load(f)
|
||||
@@ -16,15 +19,18 @@ def _upload_dataset(path: str):
|
||||
examples = data["examples"]
|
||||
try:
|
||||
dataset = _CLIENT.create_dataset(dataset_name)
|
||||
except Exception as e:
|
||||
logging.warning(f"Skipping {dataset_name}", e)
|
||||
except Exception:
|
||||
logging.warning(f"Skipping {dataset_name}")
|
||||
return
|
||||
logging.info(f"Uploading dataset: {dataset_name}")
|
||||
for i, example in enumerate(examples):
|
||||
_CLIENT.create_example(example["inputs"], dataset_id=dataset.id, outputs=example["outputs"])
|
||||
print(f"Uploaded {i+1}/{len(examples)}", end="\r")
|
||||
|
||||
if __name__ == '__main__':
|
||||
for dataset in _DATA_REPO.glob("*.json"):
|
||||
_upload_dataset(dataset)
|
||||
_CLIENT.create_examples(
|
||||
inputs=[example["inputs"] for example in examples],
|
||||
outputs=[example["outputs"] for example in examples],
|
||||
dataset_id=dataset.id,
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
for dataset in _DATA_REPO.glob("*.json"):
|
||||
print("Uploading dataset:", dataset)
|
||||
_upload_dataset(dataset)
|
||||
@@ -0,0 +1,206 @@
|
||||
# Tests for the criteria evaluator
|
||||
from typing import Tuple
|
||||
from uuid import uuid4
|
||||
|
||||
import pytest
|
||||
from langchain import chat_models, hub, llms
|
||||
from langchain.evaluation import load_evaluator
|
||||
from langchain.schema import runnable
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langsmith import Client, EvaluationResult
|
||||
from langsmith.evaluation import RunEvaluator
|
||||
from langsmith.schemas import Example, Run
|
||||
|
||||
|
||||
class ExactScoreMatch(RunEvaluator):
|
||||
def evaluate_run(self, run: Run, example: Example) -> EvaluationResult:
|
||||
predicted_score = run.outputs["score"]
|
||||
return EvaluationResult(
|
||||
key="exact_score_match",
|
||||
score=predicted_score == example.outputs["output_correctness_score"],
|
||||
)
|
||||
|
||||
|
||||
class AbsDistanceEvaluator(RunEvaluator):
|
||||
def __init__(self) -> None:
|
||||
super().__init__()
|
||||
|
||||
def evaluate_run(self, run: Run, example: Example) -> EvaluationResult:
|
||||
predicted_score = run.outputs["score"]
|
||||
if predicted_score is None:
|
||||
return EvaluationResult(key="absolute_distance", score=None)
|
||||
return EvaluationResult(
|
||||
key="absolute_distance",
|
||||
score=abs(predicted_score - example.outputs["output_correctness_score"]),
|
||||
)
|
||||
|
||||
|
||||
class NullScore(RunEvaluator):
|
||||
def __init__(self) -> None:
|
||||
super().__init__()
|
||||
|
||||
def evaluate_run(self, run: Run, example: Example) -> EvaluationResult:
|
||||
predicted_score = run.outputs["score"]
|
||||
null_score = 1 if predicted_score is None else 0
|
||||
return EvaluationResult(key="null_score", score=null_score)
|
||||
|
||||
|
||||
@pytest.fixture(scope="session")
|
||||
def uid() -> str:
|
||||
return uuid4().hex[:8]
|
||||
|
||||
|
||||
def _check_dataset(
|
||||
loader_kwargs: dict,
|
||||
dataset_name: str,
|
||||
project_name: str,
|
||||
model_provider: str,
|
||||
model_name: str,
|
||||
tags: list,
|
||||
metadata: dict,
|
||||
) -> Tuple[float, float]:
|
||||
client = Client()
|
||||
match model_provider:
|
||||
case "openai":
|
||||
llm = chat_models.ChatOpenAI(model_name=model_name, temperature=0)
|
||||
case "openai-completion":
|
||||
llm = llms.OpenAI(model_name=model_name, temperature=0)
|
||||
case "anthropic":
|
||||
llm = chat_models.ChatAnthropic(
|
||||
model_name=model_name, max_tokens=1000, temperature=0
|
||||
)
|
||||
eval_chain = load_evaluator(**loader_kwargs, llm=llm)
|
||||
|
||||
def to_evaluate(input: dict, config: runnable.RunnableConfig) -> dict:
|
||||
return eval_chain.evaluate_strings(
|
||||
input=input["input"],
|
||||
prediction=input["input_prediction"],
|
||||
reference=input["input_answer"],
|
||||
**config,
|
||||
)
|
||||
|
||||
res = run_on_dataset(
|
||||
dataset_name=dataset_name,
|
||||
llm_or_chain_factory=runnable.RunnableLambda(to_evaluate).with_config(
|
||||
{"metadata": metadata}
|
||||
),
|
||||
evaluation=RunEvalConfig(
|
||||
custom_evaluators=[
|
||||
ExactScoreMatch(),
|
||||
# AbsDistanceEvaluator(),
|
||||
NullScore(),
|
||||
],
|
||||
),
|
||||
concurrency_level=8,
|
||||
client=client,
|
||||
verbose=True,
|
||||
project_name=project_name,
|
||||
tags=["int-test"] + tags,
|
||||
)
|
||||
df = res.to_dataframe()
|
||||
feedback_cols = [
|
||||
col for col in df.columns if col not in ["input", "output", "reference"]
|
||||
]
|
||||
# Return averages
|
||||
return df[feedback_cols].mean()
|
||||
|
||||
|
||||
def _get_project_name(
|
||||
loader_kwargs: dict, uid: str, dataset_name: str, model: Tuple[str]
|
||||
) -> str:
|
||||
other_args = "-".join(f"[{k}={v}]" for k, v in loader_kwargs.items())
|
||||
return f"{model[0]}.{model[1]}-{loader_kwargs['evaluator']}{other_args} - {dataset_name} - {uid}"
|
||||
|
||||
|
||||
# prompt = "wfh/criteria_candidates"
|
||||
# commits = [
|
||||
# "f470538b",
|
||||
# "c92fcf90",
|
||||
# ]
|
||||
|
||||
# anthropic_prompt = "wfh/criteria_candidates_anthropic"
|
||||
|
||||
prompt_list = [
|
||||
{
|
||||
"openai": "wfh/criteria_candidates:f470538b",
|
||||
"anthropic": "wfh/criteria_candidates_anthropic:fb037730",
|
||||
}, # Here we'll try the anthropic one that inserts the "reasoning" step in the AI's mouth
|
||||
{
|
||||
"openai": "wfh/criteria_candidates:c92fcf90",
|
||||
}, # It's the same as the openai one
|
||||
]
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"dataset_name",
|
||||
[
|
||||
"Web Q&A Dataset - Incorrect",
|
||||
"Carb-IE-Test INCORRECT",
|
||||
"Opus100 - Incorrect",
|
||||
]
|
||||
+ [
|
||||
"Web Q&A Dataset - Correct",
|
||||
"Opus100 - Correct",
|
||||
"Carb-IE-Test CORRECT",
|
||||
],
|
||||
)
|
||||
@pytest.mark.parametrize(
|
||||
"model",
|
||||
[
|
||||
("openai", "gpt-4"),
|
||||
("openai", "gpt-3.5-turbo"),
|
||||
("openai-completion", "gpt-3.5-turbo-instruct"),
|
||||
("anthropic", "claude-2"),
|
||||
],
|
||||
)
|
||||
@pytest.mark.parametrize(
|
||||
"loader_kwargs",
|
||||
[
|
||||
{"evaluator": "cot_qa"},
|
||||
{"evaluator": "qa"},
|
||||
]
|
||||
+ [
|
||||
{
|
||||
"evaluator": "labeled_criteria",
|
||||
"criteria": "correctness",
|
||||
"prompt_lookup": pl,
|
||||
}
|
||||
for pl in prompt_list
|
||||
],
|
||||
)
|
||||
@pytest.mark.asyncio
|
||||
async def test_metaeval_correctness(
|
||||
loader_kwargs: dict, uid: str, dataset_name: str, model: Tuple[str, str]
|
||||
):
|
||||
project_name = _get_project_name(loader_kwargs, uid, dataset_name, model)
|
||||
tags = ["test_metaeval_correctness", loader_kwargs["evaluator"]]
|
||||
metadata = {
|
||||
"model_provider": model[0],
|
||||
"model_name": model[1],
|
||||
"dataset_name": dataset_name,
|
||||
"evaluator": loader_kwargs["evaluator"],
|
||||
"uid": str(uid),
|
||||
}
|
||||
if "prompt_lookup" in loader_kwargs:
|
||||
prompt_lookup = loader_kwargs.get("prompt_lookup")
|
||||
prompt_repo = prompt_lookup.get(
|
||||
model[0], prompt_lookup.get("openai")
|
||||
) # Fall back on openai prompt
|
||||
commit = prompt_repo.split(":")[-1]
|
||||
prompt = hub.pull(prompt_repo)
|
||||
loader_kwargs["prompt"] = prompt
|
||||
tags += [commit]
|
||||
print("Using prompt:", prompt_repo, commit)
|
||||
metadata["prompt"] = prompt_repo
|
||||
metadata["commit"] = commit
|
||||
scores = _check_dataset(
|
||||
loader_kwargs,
|
||||
dataset_name,
|
||||
project_name,
|
||||
model_provider=model[0],
|
||||
model_name=model[1],
|
||||
tags=tags,
|
||||
metadata=metadata,
|
||||
)
|
||||
score = scores["exact_score_match"]
|
||||
assert score >= 0.95
|
||||
@@ -1,44 +0,0 @@
|
||||
import pandas as pd
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.agents.agent_toolkits import create_pandas_dataframe_agent
|
||||
from langchain.agents.agent_types import AgentType
|
||||
from langsmith import Client
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
import pandas as pd
|
||||
from pandasai import PandasAI
|
||||
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.prompts import ChatPromptTemplate
|
||||
from langchain.schema.output_parser import StrOutputParser
|
||||
|
||||
if __name__ == "__main__":
|
||||
df = pd.read_csv("titanic.csv")
|
||||
|
||||
pandas_ai = PandasAI(ChatOpenAI(temperature=0, model="gpt-4"), enable_cache=False)
|
||||
prompt = ChatPromptTemplate.from_messages([
|
||||
("system",
|
||||
"Answer the users question about some data. A data scientist will run some code and the results will be returned to you to use in your answer"),
|
||||
("human", "Question: {input}"),
|
||||
("human", "Data Scientist Result: {result}"),
|
||||
])
|
||||
|
||||
def get_chain():
|
||||
chain = {
|
||||
"input": lambda x: x["input_question"],
|
||||
"result": lambda x: pandas_ai(df, prompt=x['input_question'])
|
||||
} | prompt | ChatOpenAI(temperature=0, model="gpt-4") | StrOutputParser()
|
||||
return chain
|
||||
|
||||
|
||||
client = Client()
|
||||
eval_config = RunEvalConfig(
|
||||
evaluators=[
|
||||
"qa"
|
||||
],
|
||||
)
|
||||
chain_results = run_on_dataset(
|
||||
client,
|
||||
dataset_name="Titanic CSV Data",
|
||||
llm_or_chain_factory=get_chain,
|
||||
evaluation=eval_config,
|
||||
)
|
||||
@@ -1,42 +0,0 @@
|
||||
import pandas as pd
|
||||
import streamlit as st
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.agents.agent_toolkits import create_pandas_dataframe_agent
|
||||
from langchain.agents.agent_types import AgentType
|
||||
|
||||
df = pd.read_csv('titanic.csv')
|
||||
|
||||
|
||||
llm = ChatOpenAI(temperature=0)
|
||||
agent = create_pandas_dataframe_agent(llm, df, agent_type=AgentType.OPENAI_FUNCTIONS)
|
||||
|
||||
|
||||
from langsmith import Client
|
||||
client = Client()
|
||||
def send_feedback(run_id, score):
|
||||
client.create_feedback(run_id, "user_score", score=score)
|
||||
|
||||
st.set_page_config(page_title='🦜🔗 Ask the CSV App')
|
||||
st.title('🦜🔗 Ask the CSV App')
|
||||
st.info("Most 'question answering' applications run over unstructured text data. But a lot of the data in the world is tabular data! This is an attempt to create an application using [LangChain](https://github.com/langchain-ai/langchain) to let you ask questions of data in tabular format. For this demo application, we will use the Titanic Dataset. Please explore it [here](https://github.com/datasciencedojo/datasets/blob/master/titanic.csv) to get a sense for what questions you can ask. Please leave feedback on well the question is answered, and we will use that improve the application!")
|
||||
|
||||
query_text = st.text_input('Enter your question:', placeholder = 'Who was in cabin C128?')
|
||||
# Form input and query
|
||||
result = None
|
||||
with st.form('myform', clear_on_submit=True):
|
||||
submitted = st.form_submit_button('Submit')
|
||||
if submitted:
|
||||
with st.spinner('Calculating...'):
|
||||
response = agent({"input": query_text}, include_run_info=True)
|
||||
result = response["output"]
|
||||
run_id = response["__run"].run_id
|
||||
if result is not None:
|
||||
st.info(result)
|
||||
col_blank, col_text, col1, col2 = st.columns([10, 2,1,1])
|
||||
with col_text:
|
||||
st.text("Feedback:")
|
||||
with col1:
|
||||
st.button("👍", on_click=send_feedback, args=(run_id, 1))
|
||||
with col2:
|
||||
st.button("👎", on_click=send_feedback, args=(run_id, 0))
|
||||
|
||||
@@ -0,0 +1,20 @@
|
||||
# Minimal makefile for Sphinx documentation
|
||||
#
|
||||
|
||||
# You can set these variables from the command line, and also
|
||||
# from the environment for the first two.
|
||||
SPHINXOPTS ?=
|
||||
SPHINXBUILD ?= sphinx-build
|
||||
SOURCEDIR = source
|
||||
BUILDDIR = build
|
||||
|
||||
# Put it first so that "make" without argument is like "make help".
|
||||
help:
|
||||
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
||||
|
||||
.PHONY: help Makefile
|
||||
|
||||
# Catch-all target: route all unknown targets to Sphinx using the new
|
||||
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
|
||||
%: Makefile
|
||||
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
||||
@@ -0,0 +1,35 @@
|
||||
@ECHO OFF
|
||||
|
||||
pushd %~dp0
|
||||
|
||||
REM Command file for Sphinx documentation
|
||||
|
||||
if "%SPHINXBUILD%" == "" (
|
||||
set SPHINXBUILD=sphinx-build
|
||||
)
|
||||
set SOURCEDIR=source
|
||||
set BUILDDIR=build
|
||||
|
||||
%SPHINXBUILD% >NUL 2>NUL
|
||||
if errorlevel 9009 (
|
||||
echo.
|
||||
echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
|
||||
echo.installed, then set the SPHINXBUILD environment variable to point
|
||||
echo.to the full path of the 'sphinx-build' executable. Alternatively you
|
||||
echo.may add the Sphinx directory to PATH.
|
||||
echo.
|
||||
echo.If you don't have Sphinx installed, grab it from
|
||||
echo.https://www.sphinx-doc.org/
|
||||
exit /b 1
|
||||
)
|
||||
|
||||
if "%1" == "" goto help
|
||||
|
||||
%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
|
||||
goto end
|
||||
|
||||
:help
|
||||
%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
|
||||
|
||||
:end
|
||||
popd
|
||||