mirror of
https://github.com/langchain-ai/langchain-benchmarks.git
synced 2026-07-01 22:34:02 -04:00
Compare commits
56 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
b41e1063f9 | ||
|
|
6823991965 | ||
|
|
adff80af11 | ||
|
|
301837e303 | ||
|
|
4f1d922a6e | ||
|
|
e4e26a3b8e | ||
|
|
7f82761813 | ||
|
|
7e16b6daa6 | ||
|
|
22d279a25c | ||
|
|
357ada3867 | ||
|
|
ab2d93ac6d | ||
|
|
53f727af64 | ||
|
|
820af98418 | ||
|
|
857f41882f | ||
|
|
381ada5cbe | ||
|
|
32a532f269 | ||
|
|
d0acf0ee26 | ||
|
|
bec40d90ef | ||
|
|
c80e959b05 | ||
|
|
2007f68302 | ||
|
|
aad9045bcb | ||
|
|
3b86e9f0b5 | ||
|
|
c1c5585d3a | ||
|
|
c45993617b | ||
|
|
d13b33e956 | ||
|
|
20a4aee5c1 | ||
|
|
4139ac8632 | ||
|
|
89be01737d | ||
|
|
29e4e878a4 | ||
|
|
ffc2832088 | ||
|
|
8b5feab7b2 | ||
|
|
a805c985a6 | ||
|
|
c0ac497ed4 | ||
|
|
a0ea197b28 | ||
|
|
74b11de9ae | ||
|
|
c2b70436e5 | ||
|
|
af9a9800e5 | ||
|
|
e7bac2cbb8 | ||
|
|
d595394243 | ||
|
|
27efb7b53c | ||
|
|
0c1fe17417 | ||
|
|
3f308e7ae4 | ||
|
|
c85a17bac2 | ||
|
|
a91672f619 | ||
|
|
81daa09d05 | ||
|
|
07be2e4555 | ||
|
|
4a642d576a | ||
|
|
8ee7108302 | ||
|
|
a9461af96f | ||
|
|
4d42a32342 | ||
|
|
21add2715b | ||
|
|
3ded353c5a | ||
|
|
b619226480 | ||
|
|
612f9346c5 | ||
|
|
90bec45008 | ||
|
|
5157e30fe7 |
@@ -39,7 +39,7 @@ jobs:
|
||||
|
||||
- name: Install dependencies
|
||||
shell: bash
|
||||
run: poetry install
|
||||
run: poetry install --with test
|
||||
|
||||
- name: Install the opposite major version of pydantic
|
||||
# If normal tests use pydantic v1, here we'll use v2, and vice versa.
|
||||
|
||||
@@ -114,7 +114,7 @@ jobs:
|
||||
shell: bash
|
||||
run: |
|
||||
echo "Attempting to build docs..."
|
||||
make build_docs
|
||||
make docs_build
|
||||
test_datasets:
|
||||
timeout-minutes: 5
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
@@ -34,7 +34,7 @@ jobs:
|
||||
- name: Sphinx build
|
||||
shell: bash
|
||||
run: |
|
||||
make build_docs
|
||||
make docs_build
|
||||
- name: Publish Docs
|
||||
uses: peaceiris/actions-gh-pages@v3
|
||||
with:
|
||||
|
||||
@@ -8,6 +8,7 @@ jobs:
|
||||
release:
|
||||
uses:
|
||||
./.github/workflows/_release.yml
|
||||
permissions: write-all
|
||||
with:
|
||||
working-directory: .
|
||||
secrets: inherit
|
||||
|
||||
@@ -0,0 +1,36 @@
|
||||
name: Weekly Tool Benchmarks
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
schedule:
|
||||
- cron: '26 * * * 2' # Runs at midnight (00:00) every Sunday (UTC time)
|
||||
|
||||
env:
|
||||
POETRY_VERSION: "1.6.1"
|
||||
|
||||
jobs:
|
||||
run_tool_benchmarks:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
|
||||
- name: Set up Python 3.12 + Poetry ${{ env.POETRY_VERSION }}
|
||||
uses: "./.github/actions/poetry_setup"
|
||||
with:
|
||||
python-version: '3.12'
|
||||
poetry-version: ${{ env.POETRY_VERSION }}
|
||||
working-directory: .
|
||||
cache-key: benchmarks-all
|
||||
|
||||
- name: Install dependencies
|
||||
shell: bash
|
||||
run: |
|
||||
echo "Running tests, installing dependencies with poetry..."
|
||||
poetry install --with test,lint,typing,docs
|
||||
|
||||
- name: Multiverse math benchmark
|
||||
run: python scripts/multiverse_math_benchmark.py
|
||||
|
||||
- name: Query analysis benchmark
|
||||
run: python scripts/query_analysis_benchmark.py
|
||||
+1
-1
@@ -158,5 +158,5 @@ cython_debug/
|
||||
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
||||
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
||||
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
||||
#.idea/
|
||||
.idea/
|
||||
.DS_Store
|
||||
|
||||
@@ -3,32 +3,7 @@
|
||||
# Default target executed when no arguments are given to make.
|
||||
all: help
|
||||
|
||||
######################
|
||||
# TESTING AND COVERAGE
|
||||
######################
|
||||
|
||||
# Define a variable for the test file path.
|
||||
TEST_FILE ?= tests/unit_tests/
|
||||
|
||||
test:
|
||||
poetry run pytest --disable-socket --allow-unix-socket $(TEST_FILE)
|
||||
|
||||
test_watch:
|
||||
poetry run ptw . -- $(TEST_FILE)
|
||||
|
||||
build_docs:
|
||||
# Copy README.md to docs/index.md
|
||||
cp README.md ./docs/source/index.md
|
||||
# Append to the table of contents the contents of the file
|
||||
cat ./docs/source/toc.segment >> ./docs/source/index.md
|
||||
poetry run sphinx-build "./docs/source" "./docs/build"
|
||||
|
||||
clean_docs:
|
||||
rm -rf ./docs/build
|
||||
|
||||
######################
|
||||
# LINTING AND FORMATTING
|
||||
######################
|
||||
# LINTING AND FORMATTING:
|
||||
|
||||
# Define a variable for Python and notebook files.
|
||||
lint format: PYTHON_FILES=.
|
||||
@@ -48,19 +23,45 @@ spell_check:
|
||||
spell_fix:
|
||||
poetry run codespell --toml pyproject.toml -w
|
||||
|
||||
######################
|
||||
# HELP
|
||||
######################
|
||||
|
||||
# TESTING AND COVERAGE:
|
||||
|
||||
# Define a variable for the test file path.
|
||||
TEST_FILE ?= tests/unit_tests/
|
||||
|
||||
test:
|
||||
poetry run pytest --disable-socket --allow-unix-socket $(TEST_FILE)
|
||||
|
||||
test_watch:
|
||||
poetry run ptw . -- $(TEST_FILE)
|
||||
|
||||
|
||||
# DOCUMENTATION:
|
||||
|
||||
docs_clean:
|
||||
rm -rf ./docs/build
|
||||
|
||||
docs_build:
|
||||
# Copy README.md to docs/index.md
|
||||
cp README.md ./docs/source/index.md
|
||||
# Append to the table of contents the contents of the file
|
||||
cat ./docs/source/toc.segment >> ./docs/source/index.md
|
||||
poetry run sphinx-build "./docs/source" "./docs/build"
|
||||
|
||||
|
||||
# HELP:
|
||||
help:
|
||||
@echo '===================='
|
||||
@echo '-- LINTING --'
|
||||
@echo 'format - run code formatters'
|
||||
@echo 'lint - run linters'
|
||||
@echo 'spell_check - run codespell on the project'
|
||||
@echo 'spell_fix - run codespell on the project and fix the errors'
|
||||
@echo '-- TESTS --'
|
||||
@echo 'coverage - run unit tests and generate coverage report'
|
||||
@echo 'test - run unit tests'
|
||||
@echo 'test TEST_FILE=<test_file> - run all tests in file'
|
||||
@echo '-- DOCUMENTATION tasks are from the top-level Makefile --'
|
||||
@echo ''
|
||||
@echo 'LINTING:'
|
||||
@echo ' format - run code formatters'
|
||||
@echo ' lint - run linters'
|
||||
@echo ' spell_check - run codespell'
|
||||
@echo ' spell_fix - run codespell and fix the errors'
|
||||
@echo 'TESTS:'
|
||||
@echo ' test - run unit tests'
|
||||
@echo ' test TEST_FILE=<test_file> - run tests in <test_file>'
|
||||
@echo ' coverage - run unit tests and generate coverage report'
|
||||
@echo 'DOCUMENTATION:'
|
||||
@echo ' docs_clean - delete the docs/build directory'
|
||||
@echo ' docs_build - build the documentation'
|
||||
@echo ''
|
||||
|
||||
@@ -22,6 +22,29 @@ We have several goals in open sourcing this:
|
||||
- Showing how we evaluate each task
|
||||
- Encouraging others to benchmark their solutions on these tasks (we are always looking for better ways of doing things!)
|
||||
|
||||
## Benchmarking Results
|
||||
|
||||
Read some of the articles about benchmarking results on our blog.
|
||||
|
||||
* [Agent Tool Use](https://blog.langchain.dev/benchmarking-agent-tool-use/)
|
||||
* [Query Analysis in High Cardinality Situations](https://blog.langchain.dev/high-cardinality/)
|
||||
* [RAG on Tables](https://blog.langchain.dev/benchmarking-rag-on-tables/)
|
||||
* [Q&A over CSV data](https://blog.langchain.dev/benchmarking-question-answering-over-csv-data/)
|
||||
|
||||
|
||||
### Tool Usage (2024-04-18)
|
||||
|
||||
See [tool usage docs](https://langchain-ai.github.io/langchain-benchmarks/notebooks/tool_usage/benchmark_all_tasks.html) to recreate!
|
||||
|
||||
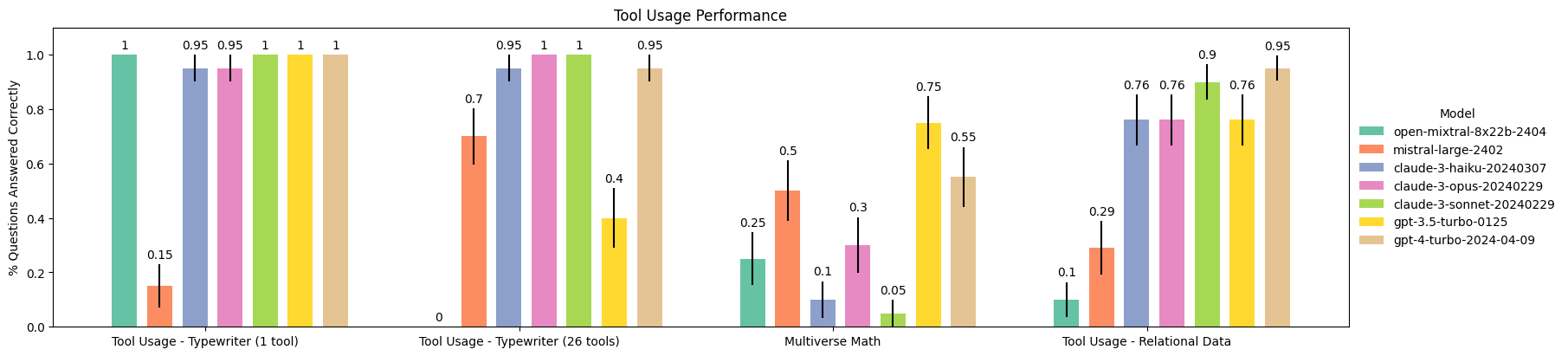
|
||||
|
||||
Explore Agent Traces on LangSmith:
|
||||
|
||||
* [Relational Data](https://smith.langchain.com/public/22721064-dcf6-4e42-be65-e7c46e6835e7/d)
|
||||
* [Tool Usage (1-tool)](https://smith.langchain.com/public/ac23cb40-e392-471f-b129-a893a77b6f62/d)
|
||||
* [Tool Usage (26-tools)](https://smith.langchain.com/public/366bddca-62b3-4b6e-849b-a478abab73db/d)
|
||||
* [Multiverse Math](https://smith.langchain.com/public/983faff2-54b9-4875-9bf2-c16913e7d489/d)
|
||||
|
||||
## Installation
|
||||
|
||||
To install the packages, run the following command:
|
||||
@@ -47,10 +70,10 @@ The other directories are legacy and may be moved in the future.
|
||||
|
||||
Below are archived benchmarks that require cloning this repo to run.
|
||||
|
||||
- [CSV Question Answering](https://github.com/langchain-ai/langchain-benchmarks/tree/main/csv-qa)
|
||||
- [Extraction](https://github.com/langchain-ai/langchain-benchmarks/tree/main/extraction)
|
||||
- [Q&A over the LangChain docs](https://github.com/langchain-ai/langchain-benchmarks/tree/main/langchain-docs-benchmarking)
|
||||
- [Meta-evaluation of 'correctness' evaluators](https://github.com/langchain-ai/langchain-benchmarks/tree/main/meta-evals)
|
||||
- [CSV Question Answering](https://github.com/langchain-ai/langchain-benchmarks/tree/main/archived/csv-qa)
|
||||
- [Extraction](https://github.com/langchain-ai/langchain-benchmarks/tree/main/archived/extraction)
|
||||
- [Q&A over the LangChain docs](https://github.com/langchain-ai/langchain-benchmarks/tree/main/archived/langchain-docs-benchmarking)
|
||||
- [Meta-evaluation of 'correctness' evaluators](https://github.com/langchain-ai/langchain-benchmarks/tree/main/archived/meta-evals)
|
||||
|
||||
|
||||
## Related
|
||||
|
||||
@@ -3,12 +3,12 @@ from langchain.agents import AgentExecutor, OpenAIFunctionsAgent
|
||||
from langchain.agents.agent_toolkits.conversational_retrieval.tool import (
|
||||
create_retriever_tool,
|
||||
)
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.embeddings import OpenAIEmbeddings
|
||||
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain.tools import PythonAstREPLTool
|
||||
from langchain.vectorstores import FAISS
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
import pandas as pd
|
||||
from langchain.agents.agent_toolkits import create_pandas_dataframe_agent
|
||||
from langchain.agents.agent_types import AgentType
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
import pandas as pd
|
||||
from langchain.agents.agent_toolkits import create_pandas_dataframe_agent
|
||||
from langchain.agents.agent_types import AgentType
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
import pandas as pd
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.prompts import ChatPromptTemplate
|
||||
from langchain.schema.output_parser import StrOutputParser
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
from pandasai import PandasAI
|
||||
|
||||
|
||||
@@ -2,7 +2,7 @@ import pandas as pd
|
||||
import streamlit as st
|
||||
from langchain.agents.agent_toolkits import create_pandas_dataframe_agent
|
||||
from langchain.agents.agent_types import AgentType
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain_openai import ChatOpenAI
|
||||
|
||||
df = pd.read_csv("titanic.csv")
|
||||
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
import streamlit as st
|
||||
from langchain.chains import create_extraction_chain
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
|
||||
st.set_page_config(page_title="🦜🔗 Text-to-graph extraction")
|
||||
|
||||
+1
-1
@@ -3,13 +3,13 @@ from typing import List, Tuple
|
||||
from langchain.agents import AgentExecutor
|
||||
from langchain.agents.format_scratchpad import format_to_openai_functions
|
||||
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
|
||||
from langchain.pydantic_v1 import BaseModel, Field
|
||||
from langchain.schema.messages import AIMessage, HumanMessage
|
||||
from langchain.tools import tool
|
||||
from langchain.tools.render import format_tool_to_openai_function
|
||||
from langchain_docs_retriever.retriever import get_retriever
|
||||
from langchain_openai import ChatOpenAI
|
||||
|
||||
# This is used to tell the model how to best use the retriever.
|
||||
|
||||
|
||||
@@ -7,9 +7,9 @@ from typing import Callable, Optional
|
||||
|
||||
from anthropic_iterative_search.chain import chain as anthropic_agent_chain
|
||||
from chat_langchain.chain import create_chain
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.schema.runnable import Runnable
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
from oai_assistant.chain import agent_executor as openai_assistant_chain
|
||||
from openai_functions_agent import agent_executor as openai_functions_agent_chain
|
||||
|
||||
@@ -1,225 +1,226 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "033684fb-65b2-4586-a959-68c614741ca2",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Datasets\n",
|
||||
"[](https://colab.research.google.com/github/langchain-ai/langchain-benchmarks/blob/main/docs/source/notebooks/datasets.ipynb)\n",
|
||||
"\n",
|
||||
"Here, we'll see how to work with LangSmith datasets."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -U langchain-benchmarks"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "6d272fbf-710e-4a49-a0da-67e010541905",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_benchmarks import clone_public_dataset, download_public_dataset"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "18ee0f96-e5c4-4ae9-aebf-7d8b88c51662",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Let's first download the dataset to the local file system"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "58b94f6d-0c91-4361-9b22-f758ffaa150a",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Fetching examples...\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"model_id": "5a2fad8c0c3549ec96a3b38fe8a002b0",
|
||||
"version_major": 2,
|
||||
"version_minor": 0
|
||||
},
|
||||
"text/plain": [
|
||||
" 0%| | 0/21 [00:00<?, ?it/s]"
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Done fetching examples.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"download_public_dataset(\n",
|
||||
" \"https://smith.langchain.com/public/452ccafc-18e1-4314-885b-edd735f17b9d/examples\"\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "841db832-b0d3-4fd1-8531-1154ec9b3caa",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"we can take a look at the first two examples"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "664e90fc-af84-4c5f-a3dd-5d9ffe649650",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[\n",
|
||||
" {\n",
|
||||
" \"created_at\": \"2023-11-15T15:26:53.511629\",\n",
|
||||
" \"dataset_id\": \"9f73165c-d333-4d14-8f59-bd7eede5db08\",\n",
|
||||
" \"id\": \"0703a989-2693-4039-a1f6-7281fc1b4cb0\",\n",
|
||||
" \"inputs\": {\n",
|
||||
" \"question\": \"do bob and alice live in the same city?\"\n",
|
||||
" },\n",
|
||||
" \"modified_at\": \"2023-11-15T15:26:53.511629\",\n",
|
||||
" \"outputs\": {\n",
|
||||
" \"expected_steps\": [\n",
|
||||
" \"find_users_by_name\",\n",
|
||||
" \"get_user_location\",\n",
|
||||
" \"get_city_for_location\",\n",
|
||||
" \"get_user_location\",\n",
|
||||
" \"get_city_for_location\"\n",
|
||||
" ],\n",
|
||||
" \"order_matters\": false,\n",
|
||||
" \"reference\": \"no\"\n",
|
||||
" },\n",
|
||||
" \"runs\": []\n",
|
||||
" },\n",
|
||||
" {\n",
|
||||
" \"created_at\": \"2023-11-15T15:26:53.491359\",\n",
|
||||
" \"dataset_id\": \"9f73165c-d333-4d14-8f59-bd7eede5db08\",\n",
|
||||
" \"id\": \"b258b95a-9524-4da7-b758-c5481109322d\",\n",
|
||||
" \"inputs\": {\n",
|
||||
" \"question\": \"Is it likely that Donna is outside with an umbrella at this time?\"\n",
|
||||
" },\n",
|
||||
" \"modified_at\": \"2023-11-15T15:26:53.491359\",\n",
|
||||
" \"outputs\": {\n",
|
||||
" \"expected_steps\": [\n",
|
||||
" \"find_users_by_name\",\n",
|
||||
" \"get_user_location\",\n",
|
||||
" \"get_current_time_for_location\",\n",
|
||||
" \"get_current_weather_for_location\"\n",
|
||||
" ],\n",
|
||||
" \"order_matters\": false,\n",
|
||||
" \"reference\": \"yes\"\n",
|
||||
" },\n",
|
||||
" \"runs\": []\n",
|
||||
" }\n",
|
||||
"]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import json\n",
|
||||
"\n",
|
||||
"with open(\"./e95d45da-aaa3-44b3-ba2b-7c15ff6e46f5.json\", \"r\", encoding=\"utf-8\") as f:\n",
|
||||
" print(json.dumps(json.load(f)[:2], indent=2, sort_keys=True))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "2c6cf01f-466b-406d-b4c7-2395747780fd",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"We can also clone the dataset to our local tenant"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e4dea4df-2f1c-436b-a71c-49ffb2295ccc",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Executing this command will clone the dataset to your own LangSmith tenant. \n",
|
||||
"For this to work you must have a [LangSmith account](https://smith.langchain.com/) set up."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"\n",
|
||||
"# Get from https://smith.langchain.com/settings\n",
|
||||
"os.environ[\"LANGCHAIN_API_KEY\"] = \"ls_...\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "18d0b905-2a6a-4752-a7cb-8653bd9049e3",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"clone_public_dataset(\n",
|
||||
" \"https://smith.langchain.com/public/452ccafc-18e1-4314-885b-edd735f17b9d/examples\",\n",
|
||||
" dataset_name=\"Agent Dataset\",\n",
|
||||
")"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.2"
|
||||
}
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "033684fb-65b2-4586-a959-68c614741ca2",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Datasets\n",
|
||||
"\n",
|
||||
"Here, we'll see how to work with LangSmith datasets."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "474292e6",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -U langchain-benchmarks"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "6d272fbf-710e-4a49-a0da-67e010541905",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_benchmarks import clone_public_dataset, download_public_dataset"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "18ee0f96-e5c4-4ae9-aebf-7d8b88c51662",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Let's first download the dataset to the local file system"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "58b94f6d-0c91-4361-9b22-f758ffaa150a",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Fetching examples...\n"
|
||||
]
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
{
|
||||
"data": {
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"model_id": "5a2fad8c0c3549ec96a3b38fe8a002b0",
|
||||
"version_major": 2,
|
||||
"version_minor": 0
|
||||
},
|
||||
"text/plain": [
|
||||
" 0%| | 0/21 [00:00<?, ?it/s]"
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Done fetching examples.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"download_public_dataset(\n",
|
||||
" \"https://smith.langchain.com/public/452ccafc-18e1-4314-885b-edd735f17b9d/examples\"\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "841db832-b0d3-4fd1-8531-1154ec9b3caa",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"we can take a look at the first two examples"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "664e90fc-af84-4c5f-a3dd-5d9ffe649650",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[\n",
|
||||
" {\n",
|
||||
" \"created_at\": \"2023-11-15T15:26:53.511629\",\n",
|
||||
" \"dataset_id\": \"9f73165c-d333-4d14-8f59-bd7eede5db08\",\n",
|
||||
" \"id\": \"0703a989-2693-4039-a1f6-7281fc1b4cb0\",\n",
|
||||
" \"inputs\": {\n",
|
||||
" \"question\": \"do bob and alice live in the same city?\"\n",
|
||||
" },\n",
|
||||
" \"modified_at\": \"2023-11-15T15:26:53.511629\",\n",
|
||||
" \"outputs\": {\n",
|
||||
" \"expected_steps\": [\n",
|
||||
" \"find_users_by_name\",\n",
|
||||
" \"get_user_location\",\n",
|
||||
" \"get_city_for_location\",\n",
|
||||
" \"get_user_location\",\n",
|
||||
" \"get_city_for_location\"\n",
|
||||
" ],\n",
|
||||
" \"order_matters\": false,\n",
|
||||
" \"reference\": \"no\"\n",
|
||||
" },\n",
|
||||
" \"runs\": []\n",
|
||||
" },\n",
|
||||
" {\n",
|
||||
" \"created_at\": \"2023-11-15T15:26:53.491359\",\n",
|
||||
" \"dataset_id\": \"9f73165c-d333-4d14-8f59-bd7eede5db08\",\n",
|
||||
" \"id\": \"b258b95a-9524-4da7-b758-c5481109322d\",\n",
|
||||
" \"inputs\": {\n",
|
||||
" \"question\": \"Is it likely that Donna is outside with an umbrella at this time?\"\n",
|
||||
" },\n",
|
||||
" \"modified_at\": \"2023-11-15T15:26:53.491359\",\n",
|
||||
" \"outputs\": {\n",
|
||||
" \"expected_steps\": [\n",
|
||||
" \"find_users_by_name\",\n",
|
||||
" \"get_user_location\",\n",
|
||||
" \"get_current_time_for_location\",\n",
|
||||
" \"get_current_weather_for_location\"\n",
|
||||
" ],\n",
|
||||
" \"order_matters\": false,\n",
|
||||
" \"reference\": \"yes\"\n",
|
||||
" },\n",
|
||||
" \"runs\": []\n",
|
||||
" }\n",
|
||||
"]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import json\n",
|
||||
"\n",
|
||||
"with open(\"./e95d45da-aaa3-44b3-ba2b-7c15ff6e46f5.json\", \"r\", encoding=\"utf-8\") as f:\n",
|
||||
" print(json.dumps(json.load(f)[:2], indent=2, sort_keys=True))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "2c6cf01f-466b-406d-b4c7-2395747780fd",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"We can also clone the dataset to our local tenant"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e4dea4df-2f1c-436b-a71c-49ffb2295ccc",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Executing this command will clone the dataset to your own LangSmith tenant. \n",
|
||||
"For this to work you must have a [LangSmith account](https://smith.langchain.com/) set up."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "7eb38ea6",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"\n",
|
||||
"# Get from https://smith.langchain.com/settings\n",
|
||||
"os.environ[\"LANGCHAIN_API_KEY\"] = \"ls_...\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "18d0b905-2a6a-4752-a7cb-8653bd9049e3",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"clone_public_dataset(\n",
|
||||
" \"https://smith.langchain.com/public/452ccafc-18e1-4314-885b-edd735f17b9d/examples\",\n",
|
||||
" dataset_name=\"Agent Dataset\",\n",
|
||||
")"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.4"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
||||
@@ -259,8 +259,8 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"llm = ChatOpenAI(model=\"gpt-4-1106-preview\", temperature=0).bind_functions(\n",
|
||||
" functions=[task.schema],\n",
|
||||
@@ -661,7 +661,7 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from typing import Any, Dict, List, Type\n",
|
||||
"from typing import Any, Dict, Type\n",
|
||||
"\n",
|
||||
"from langchain.chat_models import ChatAnthropic\n",
|
||||
"from langchain.output_parsers.xml import XMLOutputParser\n",
|
||||
@@ -1123,7 +1123,7 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from typing import Any, Dict, List, Type\n",
|
||||
"from typing import Any, Dict, Type\n",
|
||||
"\n",
|
||||
"from langchain.chat_models import ChatAnthropic\n",
|
||||
"from langchain.output_parsers.xml import XMLOutputParser\n",
|
||||
@@ -1602,7 +1602,6 @@
|
||||
"\n",
|
||||
"from langchain.chat_models import ChatFireworks\n",
|
||||
"from langchain.output_parsers.json import parse_json_markdown\n",
|
||||
"from langchain.schema.output_parser import StrOutputParser\n",
|
||||
"\n",
|
||||
"llama_prompt = ChatPromptTemplate.from_messages(\n",
|
||||
" [\n",
|
||||
@@ -1996,8 +1995,6 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import pandas as pd\n",
|
||||
"\n",
|
||||
"df = (\n",
|
||||
" test_run.to_dataframe()\n",
|
||||
" .join(claude_test_run.to_dataframe(), rsuffix=\"_claude\")\n",
|
||||
|
||||
@@ -232,8 +232,8 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"llm = ChatOpenAI(model=\"gpt-3.5-turbo-16k\", temperature=0).bind_functions(\n",
|
||||
" functions=[task.schema],\n",
|
||||
@@ -688,8 +688,6 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import pandas as pd\n",
|
||||
"\n",
|
||||
"df = test_run.to_dataframe().join(claude_test_run.to_dataframe(), rsuffix=\"_claude\")"
|
||||
]
|
||||
},
|
||||
@@ -1196,7 +1194,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.2"
|
||||
"version": "3.11.4"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -0,0 +1,749 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e4d1cb60-6d32-4337-abee-1b6c794b7f4c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Extracting high-cardinality categoricals\n",
|
||||
"\n",
|
||||
"Suppose we built a book recommendation chatbot, and as part of it we want to extract and filter on author name if that's part of the user input. A user might ask a question like:\n",
|
||||
"\n",
|
||||
"> \"what are books about aliens by Steven King\"\n",
|
||||
"\n",
|
||||
"If we're not careful, our extraction system would most likely extract the author name \"Steven King\" from this input. This might cause us to miss all the most relevant book results, since the user was almost certainly looking for books by *Stephen King*.\n",
|
||||
"\n",
|
||||
"This is a case of having to extract a **high-cardinality categorical** value. Given a dataset of books and their respective authors, there's a large but finite number of valid author names, and we need some way of making sure our extraction system outputs valid and relevant author names even if the user input refers to invalid names. \n",
|
||||
"\n",
|
||||
"We've built a dataset to help benchmark different approaches for dealing with this challenge. The dataset is simple: it is a collection of 23 mispelled and corrected human names. To use it for high-cardinality categorical testing, we're going to generate a large set of valid names (~10,000) that includes the correct spellings of all the names in the dataset. Using this, we'll test the ability of various extraction systems to extract a corrected name from the user question:\n",
|
||||
"\n",
|
||||
"> \"what are books about aliens by {mispelled_name}\"\n",
|
||||
"\n",
|
||||
"where for each datapoint in our dataset, we'll use the mispelled name as the input and expect the corrected name as the extracted output."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "dbe58c19-c29d-41d8-844a-b03c6ee1e07a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
"We need to install a few packages and set some env vars first:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "9a478941-ca99-40ee-b4f0-635f74d94a11",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -qU langchain-benchmarks langchain-openai faker chromadb numpy scikit-learn"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "8c0aa002-c334-4c51-bdf9-ffe9ae7bd56f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import getpass\n",
|
||||
"import os\n",
|
||||
"\n",
|
||||
"os.environ[\"LANGCHAIN_API_KEY\"] = getpass.getpass()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "9c3dc147-2681-437e-8a26-204f10ed4d41",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from operator import attrgetter\n",
|
||||
"\n",
|
||||
"from langchain_core.prompts import ChatPromptTemplate\n",
|
||||
"from langchain_core.pydantic_v1 import BaseModel, Field\n",
|
||||
"from langchain_core.runnables import RunnablePassthrough\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"from langsmith import Client\n",
|
||||
"\n",
|
||||
"from langchain_benchmarks import registry"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "318e0ed7-1ab5-4219-9223-900b250066de",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"This is the `Name Correction` benchmark in langchain-benchmarket:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "3f2be995-b6a9-4c3d-a19f-001c0e05ac9c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"client = Client()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "cd3d005c-9b60-4bc6-a467-815e7e3bbc7c",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'https://smith.langchain.com/public/78df83ee-ba7f-41c6-832c-2b23327d4cf7/d'"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"task = registry[\"Name Correction\"]\n",
|
||||
"task.dataset_url"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "fc4d14ea-6a46-43b1-a0ac-8e632e1297d2",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"**NOTE**: If you are running this notebook for the first time, clone the public dataset into your LangSmith organization by uncommenting the below:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "dca18a40-85f1-4911-9e41-936975fbddf8",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# client.clone_public_dataset(task.dataset_url)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "3f9ad08e-69cc-436e-94f9-b0e1e2c4a9d1",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"{'name': 'Tracy Cook'} {'name': 'Traci Cook'}\n",
|
||||
"{'name': 'Dan Klein'} {'name': 'Daniel Klein'}\n",
|
||||
"{'name': 'Jen Mcintosh'} {'name': 'Jennifer Mcintosh'}\n",
|
||||
"{'name': 'Cassie Hull'} {'name': 'Cassandra Hull'}\n",
|
||||
"{'name': 'Andy Williams'} {'name': 'Andrew Williams'}\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"examples = list(client.list_examples(dataset_name=task.dataset_name))\n",
|
||||
"for example in examples[:5]:\n",
|
||||
" print(example.inputs, example.outputs)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"id": "35c85a6f-5d8d-4018-9b83-b6cab0587c1c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def run_on_dataset(chain, run_name):\n",
|
||||
" client.run_on_dataset(\n",
|
||||
" dataset_name=task.dataset_name,\n",
|
||||
" llm_or_chain_factory=chain,\n",
|
||||
" evaluation=task.eval_config,\n",
|
||||
" project_name=run_name,\n",
|
||||
" )"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4fd7318a-4195-4da8-94d7-34ee6b7c2097",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Augmenting with more fake names\n",
|
||||
"\n",
|
||||
"For our tests we'll create a list of 10,000 names that represent all the possible values for this category. This will include our target names from the dataset."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "06098983-f5cf-4de3-ae07-4cdbe091522c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from faker import Faker\n",
|
||||
"\n",
|
||||
"Faker.seed(42)\n",
|
||||
"fake = Faker()\n",
|
||||
"fake.seed_instance(0)\n",
|
||||
"\n",
|
||||
"incorrect_names = [example.inputs[\"name\"] for example in examples]\n",
|
||||
"correct_names = [example.outputs[\"name\"] for example in examples]\n",
|
||||
"\n",
|
||||
"# We'll make sure that our list of valid names contains the correct spellings\n",
|
||||
"# and not the incorrect spellings from our dataset\n",
|
||||
"valid_names = list(\n",
|
||||
" set([fake.name() for _ in range(10_000)] + correct_names).difference(\n",
|
||||
" incorrect_names\n",
|
||||
" )\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "ab6d9b4b-717b-4947-ac17-a100a0ced088",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"9382"
|
||||
]
|
||||
},
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"len(valid_names)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "6e7d27bf-c82c-43e1-961a-ea67733b1dec",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"['Debra Lee', 'Kevin Harper', 'Donald Anderson']"
|
||||
]
|
||||
},
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"valid_names[:3]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "bd801ab5-b2a4-49bc-9c11-698dc760eb28",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Chain 1: Baseline\n",
|
||||
"\n",
|
||||
"As a baseline we'll create a function-calling chain that has no information about the set of valid names."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"id": "1e0694d9-d67d-4f90-b40c-f8373389f5c4",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"class Search(BaseModel):\n",
|
||||
" query: str\n",
|
||||
" author: str\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"system = \"\"\"Generate a relevant search query for a library system\"\"\"\n",
|
||||
"prompt = ChatPromptTemplate.from_messages(\n",
|
||||
" [\n",
|
||||
" (\"system\", \"{system}\"),\n",
|
||||
" (\"human\", \"what are books about aliens by {name}\"),\n",
|
||||
" ]\n",
|
||||
")\n",
|
||||
"llm = ChatOpenAI(model=\"gpt-3.5-turbo-0125\", temperature=0)\n",
|
||||
"structured_llm = llm.with_structured_output(Search)\n",
|
||||
"\n",
|
||||
"query_analyzer_1 = (\n",
|
||||
" prompt.partial(system=system) | structured_llm | {\"name\": attrgetter(\"author\")}\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"id": "f4a4d81f-532a-4efb-86cb-cc0555dbc4e7",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"View the evaluation results for project 'GPT-3.5' at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6/compare?selectedSessions=f429ec84-b879-4e66-b7fb-ef7be69d1acd\n",
|
||||
"\n",
|
||||
"View all tests for Dataset Extracting Corrected Names at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6\n",
|
||||
"[------------------------------------------------->] 23/23"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"run_on_dataset(query_analyzer_1, \"GPT-3.5\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b4f42968-069f-450b-a03b-f47934956f89",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"As we might have expected, this gives us a `Correct rate: 0%`. Let's see if we can do better :)\n",
|
||||
"\n",
|
||||
"See the test run in LangSmith [here](https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d/compare?selectedSessions=f429ec84-b879-4e66-b7fb-ef7be69d1acd)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "08ef2fc6-0ad9-4a3e-a306-bd7100f7b1fb",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Chain 2: All candidates in prompt\n",
|
||||
"\n",
|
||||
"Next, let's dump the full list of valid names in the system prompt. We'll need a model with a longer context window than the 16k token window of gpt-3.5-turbo-0125 so we'll use gpt-4-0125-preview."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"id": "d0f65f4f-5461-43b1-9c7b-5fcdaf48c2ce",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"valid_names_str = \"\\n\".join(valid_names)\n",
|
||||
"\n",
|
||||
"system_2 = \"\"\"Generate a relevant search query for a library system.\n",
|
||||
"\n",
|
||||
"`author` attribute MUST be one of:\n",
|
||||
"\n",
|
||||
"{valid_names_str}\n",
|
||||
"\n",
|
||||
"Do NOT hallucinate author name!\"\"\"\n",
|
||||
"\n",
|
||||
"formatted_system = system_2.format(valid_names_str=valid_names_str)\n",
|
||||
"structured_llm_2 = ChatOpenAI(\n",
|
||||
" model=\"gpt-4-0125-preview\", temperature=0\n",
|
||||
").with_structured_output(Search)\n",
|
||||
"query_analyzer_2 = (\n",
|
||||
" prompt.partial(system=formatted_system)\n",
|
||||
" | structured_llm_2\n",
|
||||
" | {\"name\": attrgetter(\"author\")}\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"id": "de679906-c69d-4ceb-bc5e-73a291b21cdc",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"View the evaluation results for project 'GPT-4, all names in prompt' at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6/compare?selectedSessions=8c4cfdfc-3646-438e-be47-43a40d66292a\n",
|
||||
"\n",
|
||||
"View all tests for Dataset Extracting Corrected Names at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6\n",
|
||||
"[------------------------------------------------->] 23/23"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"run_on_dataset(query_analyzer_2, \"GPT-4, all names in prompt\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "eb678fdd-0e57-4063-adea-56248aea11e5",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"This gets us up to `Correct rate: 26%`.\n",
|
||||
"\n",
|
||||
"See the test run in LangSmith [here](https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d/compare?selectedSessions=8c4cfdfc-3646-438e-be47-43a40d66292a)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "0aa394b5-a665-4f4c-809d-c0d756c9b23e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Chain 3: Top k candidates from vectorstore in prompt\n",
|
||||
"\n",
|
||||
"10,000 names is a lot to have in the prompt. Perhaps we could get better performance by shortening the list using vector search first to only include names that have the highest similarity to the user question. We can return to using GPT-3.5 as a result:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "f9439e3f-5aa2-45b7-ab1f-149060744e03",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_community.vectorstores import Chroma\n",
|
||||
"from langchain_core.prompts import PromptTemplate\n",
|
||||
"from langchain_openai import OpenAIEmbeddings\n",
|
||||
"\n",
|
||||
"k = 10\n",
|
||||
"embeddings = OpenAIEmbeddings(model=\"text-embedding-3-small\")\n",
|
||||
"vectorstore = Chroma.from_texts(valid_names, embeddings, collection_name=\"author_names\")\n",
|
||||
"retriever = vectorstore.as_retriever(search_kwargs={\"k\": k})"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 20,
|
||||
"id": "04018b30-2378-4c96-8515-39d66c554459",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"system_chain = (\n",
|
||||
" (lambda name: f\"what are books about aliens by {name}\")\n",
|
||||
" | retriever\n",
|
||||
" | (\n",
|
||||
" lambda docs: system_2.format(\n",
|
||||
" valid_names_str=\"\\n\".join(d.page_content for d in docs)\n",
|
||||
" )\n",
|
||||
" )\n",
|
||||
")\n",
|
||||
"query_analyzer_3 = (\n",
|
||||
" RunnablePassthrough.assign(system=system_chain)\n",
|
||||
" | prompt\n",
|
||||
" | structured_llm\n",
|
||||
" | {\"name\": attrgetter(\"author\")}\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 22,
|
||||
"id": "fd5af75e-41fa-42ee-b9ac-62eb13e21022",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"View the evaluation results for project 'GPT-3.5, top 10 names in prompt, vecstore' at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6/compare?selectedSessions=af93ec50-ccbb-4b3c-908a-70c75e5516ea\n",
|
||||
"\n",
|
||||
"View all tests for Dataset Extracting Corrected Names at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6\n",
|
||||
"[------------------------------------------------->] 23/23"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"run_on_dataset(query_analyzer_3, f\"GPT-3.5, top {k} names in prompt, vecstore\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b7e0f097-7432-4728-a60b-b980046c1275",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"This gets us up to `Correct rate: 57%`\n",
|
||||
"\n",
|
||||
"See the test run in LangSmith [here](https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d/compare?selectedSessions=af93ec50-ccbb-4b3c-908a-70c75e5516ea)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "20aaa33a-d475-41a1-8f1a-53e18382b3d7",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Chain 4: Top k candidates by ngram overlap in prompt\n",
|
||||
"\n",
|
||||
"Instead of using vector search, which requires embeddings and vector stores, a cheaper and faster approach would be to compare ngram overlap between the user question and the list of valid names:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 23,
|
||||
"id": "05b2fc1c-0f61-4638-bbf5-fed5b634db51",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import numpy as np\n",
|
||||
"from sklearn.feature_extraction.text import TfidfVectorizer\n",
|
||||
"from sklearn.metrics.pairwise import cosine_similarity\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# Function to generate character n-grams\n",
|
||||
"def ngrams(string, n=3):\n",
|
||||
" string = \"START\" + string.replace(\" \", \"\").lower() + \"END\"\n",
|
||||
" ngrams = zip(*[string[i:] for i in range(n)])\n",
|
||||
" return [\"\".join(ngram) for ngram in ngrams]\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# Vectorize documents using TfidfVectorizer with the custom n-grams function\n",
|
||||
"vectorizer = TfidfVectorizer(analyzer=ngrams)\n",
|
||||
"tfidf_matrix = vectorizer.fit_transform(valid_names)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 24,
|
||||
"id": "2994aff8-4bfd-4cf3-9b73-2bda7c470ba4",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def get_names(query):\n",
|
||||
" # Vectorize query\n",
|
||||
" query_tfidf = vectorizer.transform([query])\n",
|
||||
"\n",
|
||||
" # Compute cosine similarity\n",
|
||||
" cosine_similarities = cosine_similarity(query_tfidf, tfidf_matrix).flatten()\n",
|
||||
"\n",
|
||||
" # Find the index of the most similar document\n",
|
||||
" most_similar_document_indexes = np.argsort(-cosine_similarities)\n",
|
||||
"\n",
|
||||
" return \"\\n\".join([valid_names[i] for i in most_similar_document_indexes[:k]])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 25,
|
||||
"id": "a549a347-1449-4ae2-a30d-e8f0b917d50e",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def get_system_prompt(input):\n",
|
||||
" name = input[\"name\"]\n",
|
||||
" valid_names_str = get_names(f\"what are books about aliens by {name}\")\n",
|
||||
" return system_2.format(valid_names_str=valid_names_str)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"query_analyzer_4 = (\n",
|
||||
" RunnablePassthrough.assign(system=get_system_prompt)\n",
|
||||
" | prompt\n",
|
||||
" | structured_llm\n",
|
||||
" | {\"name\": attrgetter(\"author\")}\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 27,
|
||||
"id": "dd1b69a8-5ca6-4a2d-9ad3-567d0105b672",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"View the evaluation results for project 'GPT-3.5, top 10 names in prompt, ngram' at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6/compare?selectedSessions=bc28b761-2ac9-4391-8df1-758f0a4d5100\n",
|
||||
"\n",
|
||||
"View all tests for Dataset Extracting Corrected Names at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6\n",
|
||||
"[------------------------------------------------->] 23/23"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"run_on_dataset(query_analyzer_4, f\"GPT-3.5, top {k} names in prompt, ngram\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b4e16c1b-33d5-4ca1-932b-8234ffc668bf",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"This gets us up to `Correct rate: 65%`\n",
|
||||
"\n",
|
||||
"See the test run in LangSmith [here](https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d/compare?selectedSessions=bc28b761-2ac9-4391-8df1-758f0a4d5100)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "d3045376-e102-4ec6-877a-91448677f3f3",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Chain 5: Replace with top candidate from vectorstore\n",
|
||||
"\n",
|
||||
"Instead of (or in addition to) searching for similar candidates before extraction, we can also compare and correct the extracted value after-the-fact a search over the valid names. With Pydantic classes this is easy using a validator:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 28,
|
||||
"id": "ac719651-0775-4fa4-bd22-9fddebcc6918",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_core.pydantic_v1 import validator\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"class Search(BaseModel):\n",
|
||||
" query: str\n",
|
||||
" author: str\n",
|
||||
"\n",
|
||||
" @validator(\"author\")\n",
|
||||
" def double(cls, v: str) -> str:\n",
|
||||
" return vectorstore.similarity_search(v, k=1)[0].page_content\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"structured_llm_3 = llm.with_structured_output(Search)\n",
|
||||
"query_analyzer_5 = (\n",
|
||||
" prompt.partial(system=system) | structured_llm_3 | {\"name\": attrgetter(\"author\")}\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 29,
|
||||
"id": "fc1cfdcb-47fb-40c4-898d-f290cd53a37d",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"View the evaluation results for project 'GPT-3.5, correct name, vecstore' at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6/compare?selectedSessions=e3eda1e1-bc25-46e8-a4fb-db324cefd1c9\n",
|
||||
"\n",
|
||||
"View all tests for Dataset Extracting Corrected Names at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6\n",
|
||||
"[------------------------------------------------->] 23/23"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"run_on_dataset(query_analyzer_5, f\"GPT-3.5, correct name, vecstore\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e6e96a2c-506e-461f-bd05-cb88fe0ea3aa",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"This gets us up to `Correct rate: 83%`\n",
|
||||
"\n",
|
||||
"See the test run in LangSmith [here](https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d/compare?selectedSessions=e3eda1e1-bc25-46e8-a4fb-db324cefd1c9)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "f1f8ce77-01a3-41d1-a047-103cb2e552f9",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Chain 6: Replace with top candidate by ngram overlap\n",
|
||||
"\n",
|
||||
"We can do the same with ngram overlap search instead of vector search:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 30,
|
||||
"id": "21ffa8c9-907b-453a-9b32-01a981bca5ec",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"class Search(BaseModel):\n",
|
||||
" query: str\n",
|
||||
" author: str\n",
|
||||
"\n",
|
||||
" @validator(\"author\")\n",
|
||||
" def double(cls, v: str) -> str:\n",
|
||||
" return get_names(v).split(\"\\n\")[0]\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"structured_llm_4 = llm.with_structured_output(Search)\n",
|
||||
"query_analyzer_6 = (\n",
|
||||
" prompt.partial(system=system) | structured_llm_4 | {\"name\": attrgetter(\"author\")}\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 31,
|
||||
"id": "126354dd-c54e-4391-8a5e-5e200d006a18",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"View the evaluation results for project 'GPT-3.5, correct name, ngram' at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6/compare?selectedSessions=8f8846c8-2ada-41bc-8d2c-e1d56e7c92ce\n",
|
||||
"\n",
|
||||
"View all tests for Dataset Extracting Corrected Names at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6\n",
|
||||
"[------------------------------------------------->] 23/23"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"run_on_dataset(query_analyzer_6, f\"GPT-3.5, correct name, ngram\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b8c8cd81-61d0-4c1f-957d-1910be7706e7",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"This gets us up to `Correct rate: 74%`, slightly worse than Chain 5 (same thing using vector search insteadf of ngram).\n",
|
||||
"\n",
|
||||
"See the test run in LangSmith [here](https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d/compare?selectedSessions=8f8846c8-2ada-41bc-8d2c-e1d56e7c92ce)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4d7f7ab4-466d-434c-98bd-ebe1906599a9",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## See all results in LangSmith\n",
|
||||
"\n",
|
||||
"To see the full dataset and all the test results, head to LangSmith: https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "benchmarks-venv",
|
||||
"language": "python",
|
||||
"name": "benchmarks-venv"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.4"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -97,7 +97,7 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"from langchain_benchmarks.extraction import get_eval_config\n",
|
||||
"\n",
|
||||
@@ -122,7 +122,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.2"
|
||||
"version": "3.11.4"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
File diff suppressed because one or more lines are too long
@@ -75,6 +75,7 @@
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "7fb27b941602401d91542211134fc71a",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
@@ -311,7 +312,7 @@
|
||||
"\n",
|
||||
"## Customizing Chunking\n",
|
||||
"\n",
|
||||
"The simplest change you can make to the index is configure how you split the "
|
||||
"The simplest change you can make to the index is configure how you split the documents."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -728,12 +729,12 @@
|
||||
"from langchain.agents import AgentExecutor\n",
|
||||
"from langchain.agents.format_scratchpad import format_to_openai_functions\n",
|
||||
"from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder\n",
|
||||
"from langchain.pydantic_v1 import BaseModel, Field\n",
|
||||
"from langchain.schema.messages import AIMessage, HumanMessage\n",
|
||||
"from langchain.tools import tool\n",
|
||||
"from langchain.tools.render import format_tool_to_openai_function\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"# This is used to tell the model how to best use the retriever.\n",
|
||||
"\n",
|
||||
|
||||
@@ -286,7 +286,7 @@
|
||||
")\n",
|
||||
"\n",
|
||||
"vectorstore = Chroma(\n",
|
||||
" collection_name=f\"lcbm-b-huggingface-gte-base\",\n",
|
||||
" collection_name=\"lcbm-b-huggingface-gte-base\",\n",
|
||||
" embedding_function=embeddings,\n",
|
||||
" persist_directory=\"./chromadb\",\n",
|
||||
")\n",
|
||||
|
||||
@@ -508,8 +508,8 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.schema.messages import HumanMessage\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def image_summarize(img_base64, prompt):\n",
|
||||
|
||||
+1
-1
@@ -328,10 +328,10 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.prompts import ChatPromptTemplate\n",
|
||||
"from langchain.schema.output_parser import StrOutputParser\n",
|
||||
"from langchain.schema.runnable import RunnablePassthrough\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def rag_chain(retriever):\n",
|
||||
|
||||
@@ -412,8 +412,6 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from functools import partial\n",
|
||||
"\n",
|
||||
"from langsmith.client import Client\n",
|
||||
"\n",
|
||||
"from langchain_benchmarks.rag import get_eval_config\n",
|
||||
@@ -453,11 +451,11 @@
|
||||
"source": [
|
||||
"from operator import itemgetter\n",
|
||||
"\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.prompts import ChatPromptTemplate\n",
|
||||
"from langchain.schema.document import Document\n",
|
||||
"from langchain.schema.output_parser import StrOutputParser\n",
|
||||
"from langchain.schema.runnable.passthrough import RunnableAssign\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"# Prompt\n",
|
||||
"prompt = ChatPromptTemplate.from_messages(\n",
|
||||
|
||||
@@ -118,8 +118,6 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.callbacks.manager import CallbackManager\n",
|
||||
"from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler\n",
|
||||
"from langchain.chat_models import ChatFireworks, ChatOpenAI\n",
|
||||
"from langchain.document_loaders import PyPDFLoader\n",
|
||||
"from langchain.embeddings import OpenAIEmbeddings\n",
|
||||
|
||||
+1
-1
@@ -126,7 +126,6 @@
|
||||
"source": [
|
||||
"import uuid\n",
|
||||
"\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.document_loaders import PyPDFLoader\n",
|
||||
"from langchain.embeddings import OpenAIEmbeddings\n",
|
||||
"from langchain.prompts import ChatPromptTemplate\n",
|
||||
@@ -138,6 +137,7 @@
|
||||
"from langchain.storage import InMemoryStore\n",
|
||||
"from langchain.text_splitter import RecursiveCharacterTextSplitter\n",
|
||||
"from langchain.vectorstores import Chroma\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def prepare_documents(docs):\n",
|
||||
|
||||
@@ -0,0 +1,600 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "60bb467d-861d-4b07-a48d-8e5aa177c969",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"# Running Locally\n",
|
||||
"\n",
|
||||
"The LangChain benchmarks package is best used with LangSmith. You can create a free account [here](https://smith.langchain.com/) and read the [docs here](https://docs.smith.langchain.com/).\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"If you are unable to make an account, you can still run these benchmarks locally without an account.\n",
|
||||
"\n",
|
||||
"Below is an example."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "a00a1a5f-43ef-4445-a792-8bf6a5f74643",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Prove that we can run without LangSmith\n",
|
||||
"import os\n",
|
||||
"\n",
|
||||
"_ = [\n",
|
||||
" os.environ.pop(key)\n",
|
||||
" for key in list(os.environ.keys())\n",
|
||||
" if key.startswith(\"LANGCHAIN_\")\n",
|
||||
"]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "b39159d0-9ea1-414f-a9d8-4a7b22b3d2cc",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/html": [
|
||||
"<table>\n",
|
||||
"<tbody>\n",
|
||||
"<tr><td>Name </td><td>Multiverse Math </td></tr>\n",
|
||||
"<tr><td>Type </td><td>ToolUsageTask </td></tr>\n",
|
||||
"<tr><td>Dataset ID </td><td><a href=\"https://smith.langchain.com/public/594f9f60-30a0-49bf-b075-f44beabf546a/d\" target=\"_blank\" rel=\"noopener\">594f9f60-30a0-49bf-b075-f44beabf546a</a></td></tr>\n",
|
||||
"<tr><td>Description</td><td>An environment that contains a few basic math operations, but with altered results.\n",
|
||||
"\n",
|
||||
"For example, multiplication of 5*3 will be re-interpreted as 5*3*1.1. The basic operations retain some basic properties, such as commutativity, associativity, and distributivity; however, the results are different than expected.\n",
|
||||
"\n",
|
||||
"The objective of this task is to evaluate the ability to use the provided tools to solve simple math questions and ignore any innate knowledge about math. </td></tr>\n",
|
||||
"</tbody>\n",
|
||||
"</table>"
|
||||
],
|
||||
"text/plain": [
|
||||
"ToolUsageTask(name='Multiverse Math', dataset_id='https://smith.langchain.com/public/594f9f60-30a0-49bf-b075-f44beabf546a/d', description='An environment that contains a few basic math operations, but with altered results.\\n\\nFor example, multiplication of 5*3 will be re-interpreted as 5*3*1.1. The basic operations retain some basic properties, such as commutativity, associativity, and distributivity; however, the results are different than expected.\\n\\nThe objective of this task is to evaluate the ability to use the provided tools to solve simple math questions and ignore any innate knowledge about math.\\n', create_environment=<function get_environment at 0x137b70360>, instructions='You are requested to solve math questions in an alternate mathematical universe. The operations have been altered to yield different results than expected. Do not guess the answer or rely on your innate knowledge of math. Use the provided tools to answer the question. While associativity and commutativity apply, distributivity does not. Answer the question using the fewest possible tools. Only include the numeric response without any clarifications.', eval_params={'output_evaluation': 'qa_math'})"
|
||||
]
|
||||
},
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain_benchmarks import registry\n",
|
||||
"\n",
|
||||
"task = registry[\"Multiverse Math\"]\n",
|
||||
"task"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "3821e4b0-8e67-418a-840c-470fcde42df0",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Eval\n",
|
||||
"\n",
|
||||
"Let's evaluate an agent now. Nothing will be saved to langsmith, so be sure to save the test results to your file system if you want to use them later."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "fb32763c-79ab-426a-8fc6-bf8ebb0dd432",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"model_id": "bb6a27e067fa4887beaa78a28d8d431d",
|
||||
"version_major": 2,
|
||||
"version_minor": 0
|
||||
},
|
||||
"text/plain": [
|
||||
"Running Evaluation: 0%| | 0/10 [00:00<?, ?example/s]"
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/html": [
|
||||
"<h3>Experiment Results:</h3>"
|
||||
],
|
||||
"text/plain": [
|
||||
"<IPython.core.display.HTML object>"
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/html": [
|
||||
"<div>\n",
|
||||
"<style scoped>\n",
|
||||
" .dataframe tbody tr th:only-of-type {\n",
|
||||
" vertical-align: middle;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" .dataframe tbody tr th {\n",
|
||||
" vertical-align: top;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" .dataframe thead th {\n",
|
||||
" text-align: right;\n",
|
||||
" }\n",
|
||||
"</style>\n",
|
||||
"<table border=\"1\" class=\"dataframe\">\n",
|
||||
" <thead>\n",
|
||||
" <tr style=\"text-align: right;\">\n",
|
||||
" <th></th>\n",
|
||||
" <th>inputs.question</th>\n",
|
||||
" <th>outputs.input</th>\n",
|
||||
" <th>outputs.output</th>\n",
|
||||
" <th>outputs.intermediate_steps</th>\n",
|
||||
" <th>feedback.Intermediate steps correctness</th>\n",
|
||||
" <th>feedback.# steps / # expected steps</th>\n",
|
||||
" <th>feedback.correctness</th>\n",
|
||||
" <th>error</th>\n",
|
||||
" <th>execution_time</th>\n",
|
||||
" </tr>\n",
|
||||
" </thead>\n",
|
||||
" <tbody>\n",
|
||||
" <tr>\n",
|
||||
" <th>count</th>\n",
|
||||
" <td>10</td>\n",
|
||||
" <td>10</td>\n",
|
||||
" <td>10</td>\n",
|
||||
" <td>10</td>\n",
|
||||
" <td>10.0</td>\n",
|
||||
" <td>10.0</td>\n",
|
||||
" <td>10.0</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>10.000000</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>unique</th>\n",
|
||||
" <td>10</td>\n",
|
||||
" <td>10</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>top</th>\n",
|
||||
" <td>multiply the result of (log of 100 to base 10)...</td>\n",
|
||||
" <td>multiply the result of (log of 100 to base 10)...</td>\n",
|
||||
" <td></td>\n",
|
||||
" <td>[]</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>freq</th>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>10</td>\n",
|
||||
" <td>10</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>mean</th>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>1.453172</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>std</th>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>0.496547</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>min</th>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>0.763208</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>25%</th>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>0.963885</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>50%</th>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>1.593439</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>75%</th>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>1.870549</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>max</th>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>NaN</td>\n",
|
||||
" <td>1.957470</td>\n",
|
||||
" </tr>\n",
|
||||
" </tbody>\n",
|
||||
"</table>\n",
|
||||
"</div>"
|
||||
],
|
||||
"text/plain": [
|
||||
" inputs.question \\\n",
|
||||
"count 10 \n",
|
||||
"unique 10 \n",
|
||||
"top multiply the result of (log of 100 to base 10)... \n",
|
||||
"freq 1 \n",
|
||||
"mean NaN \n",
|
||||
"std NaN \n",
|
||||
"min NaN \n",
|
||||
"25% NaN \n",
|
||||
"50% NaN \n",
|
||||
"75% NaN \n",
|
||||
"max NaN \n",
|
||||
"\n",
|
||||
" outputs.input outputs.output \\\n",
|
||||
"count 10 10 \n",
|
||||
"unique 10 1 \n",
|
||||
"top multiply the result of (log of 100 to base 10)... \n",
|
||||
"freq 1 10 \n",
|
||||
"mean NaN NaN \n",
|
||||
"std NaN NaN \n",
|
||||
"min NaN NaN \n",
|
||||
"25% NaN NaN \n",
|
||||
"50% NaN NaN \n",
|
||||
"75% NaN NaN \n",
|
||||
"max NaN NaN \n",
|
||||
"\n",
|
||||
" outputs.intermediate_steps feedback.Intermediate steps correctness \\\n",
|
||||
"count 10 10.0 \n",
|
||||
"unique 1 NaN \n",
|
||||
"top [] NaN \n",
|
||||
"freq 10 NaN \n",
|
||||
"mean NaN 0.0 \n",
|
||||
"std NaN 0.0 \n",
|
||||
"min NaN 0.0 \n",
|
||||
"25% NaN 0.0 \n",
|
||||
"50% NaN 0.0 \n",
|
||||
"75% NaN 0.0 \n",
|
||||
"max NaN 0.0 \n",
|
||||
"\n",
|
||||
" feedback.# steps / # expected steps feedback.correctness error \\\n",
|
||||
"count 10.0 10.0 0 \n",
|
||||
"unique NaN NaN 0 \n",
|
||||
"top NaN NaN NaN \n",
|
||||
"freq NaN NaN NaN \n",
|
||||
"mean 0.0 0.0 NaN \n",
|
||||
"std 0.0 0.0 NaN \n",
|
||||
"min 0.0 0.0 NaN \n",
|
||||
"25% 0.0 0.0 NaN \n",
|
||||
"50% 0.0 0.0 NaN \n",
|
||||
"75% 0.0 0.0 NaN \n",
|
||||
"max 0.0 0.0 NaN \n",
|
||||
"\n",
|
||||
" execution_time \n",
|
||||
"count 10.000000 \n",
|
||||
"unique NaN \n",
|
||||
"top NaN \n",
|
||||
"freq NaN \n",
|
||||
"mean 1.453172 \n",
|
||||
"std 0.496547 \n",
|
||||
"min 0.763208 \n",
|
||||
"25% 0.963885 \n",
|
||||
"50% 1.593439 \n",
|
||||
"75% 1.870549 \n",
|
||||
"max 1.957470 "
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import uuid\n",
|
||||
"\n",
|
||||
"from langchain_benchmarks.tool_usage import agents, get_eval_config\n",
|
||||
"from langchain_benchmarks.utils import run_without_langsmith\n",
|
||||
"\n",
|
||||
"experiment_uuid = uuid.uuid4().hex[:4]\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"models = [\"gpt-3.5-turbo-1106\"]\n",
|
||||
"\n",
|
||||
"for model in models:\n",
|
||||
" print()\n",
|
||||
" eval_config = get_eval_config(output_evaluation=\"qa_math\")\n",
|
||||
" agent_factory = agents.OpenAIAgentFactory(task, model=model)\n",
|
||||
" test_run = run_without_langsmith(\n",
|
||||
" # This will clone the dataset locally if not already there\n",
|
||||
" path_or_token_id=task.dataset_id,\n",
|
||||
" llm_or_chain_factory=agent_factory,\n",
|
||||
" evaluation=eval_config,\n",
|
||||
" verbose=True,\n",
|
||||
" )"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "da3015b0-61b2-4748-ab0f-a0239bb74d58",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/html": [
|
||||
"<div>\n",
|
||||
"<style scoped>\n",
|
||||
" .dataframe tbody tr th:only-of-type {\n",
|
||||
" vertical-align: middle;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" .dataframe tbody tr th {\n",
|
||||
" vertical-align: top;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" .dataframe thead th {\n",
|
||||
" text-align: right;\n",
|
||||
" }\n",
|
||||
"</style>\n",
|
||||
"<table border=\"1\" class=\"dataframe\">\n",
|
||||
" <thead>\n",
|
||||
" <tr style=\"text-align: right;\">\n",
|
||||
" <th></th>\n",
|
||||
" <th>inputs.question</th>\n",
|
||||
" <th>outputs.input</th>\n",
|
||||
" <th>outputs.output</th>\n",
|
||||
" <th>outputs.intermediate_steps</th>\n",
|
||||
" <th>feedback.Intermediate steps correctness</th>\n",
|
||||
" <th>feedback.# steps / # expected steps</th>\n",
|
||||
" <th>feedback.correctness</th>\n",
|
||||
" <th>error</th>\n",
|
||||
" <th>execution_time</th>\n",
|
||||
" </tr>\n",
|
||||
" </thead>\n",
|
||||
" <tbody>\n",
|
||||
" <tr>\n",
|
||||
" <th>27c44572-6c67-4129-a95a-fe1509c350be</th>\n",
|
||||
" <td>multiply the result of (log of 100 to base 10)...</td>\n",
|
||||
" <td>multiply the result of (log of 100 to base 10)...</td>\n",
|
||||
" <td></td>\n",
|
||||
" <td>[]</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>None</td>\n",
|
||||
" <td>0.763208</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>2a20a13d-050e-4a16-84ff-22d9582f1449</th>\n",
|
||||
" <td>after calculating the sin of 1.5 radians, divi...</td>\n",
|
||||
" <td>after calculating the sin of 1.5 radians, divi...</td>\n",
|
||||
" <td></td>\n",
|
||||
" <td>[]</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>None</td>\n",
|
||||
" <td>1.413695</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>67867526-791a-452f-b534-ef2c1f5efd20</th>\n",
|
||||
" <td>ecoli divides every 20 minutes. How many cells...</td>\n",
|
||||
" <td>ecoli divides every 20 minutes. How many cells...</td>\n",
|
||||
" <td></td>\n",
|
||||
" <td>[]</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>None</td>\n",
|
||||
" <td>1.773183</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>4ac33c1a-62f0-4da4-9455-07b582f6ff52</th>\n",
|
||||
" <td>calculate 101 to the power of 0.5 to 4 digits ...</td>\n",
|
||||
" <td>calculate 101 to the power of 0.5 to 4 digits ...</td>\n",
|
||||
" <td></td>\n",
|
||||
" <td>[]</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>None</td>\n",
|
||||
" <td>1.819677</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>2e82a924-8382-425e-8738-daa2d912e9fe</th>\n",
|
||||
" <td>convert 15 degrees to radians</td>\n",
|
||||
" <td>convert 15 degrees to radians</td>\n",
|
||||
" <td></td>\n",
|
||||
" <td>[]</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>None</td>\n",
|
||||
" <td>1.957470</td>\n",
|
||||
" </tr>\n",
|
||||
" </tbody>\n",
|
||||
"</table>\n",
|
||||
"</div>"
|
||||
],
|
||||
"text/plain": [
|
||||
" inputs.question \\\n",
|
||||
"27c44572-6c67-4129-a95a-fe1509c350be multiply the result of (log of 100 to base 10)... \n",
|
||||
"2a20a13d-050e-4a16-84ff-22d9582f1449 after calculating the sin of 1.5 radians, divi... \n",
|
||||
"67867526-791a-452f-b534-ef2c1f5efd20 ecoli divides every 20 minutes. How many cells... \n",
|
||||
"4ac33c1a-62f0-4da4-9455-07b582f6ff52 calculate 101 to the power of 0.5 to 4 digits ... \n",
|
||||
"2e82a924-8382-425e-8738-daa2d912e9fe convert 15 degrees to radians \n",
|
||||
"\n",
|
||||
" outputs.input \\\n",
|
||||
"27c44572-6c67-4129-a95a-fe1509c350be multiply the result of (log of 100 to base 10)... \n",
|
||||
"2a20a13d-050e-4a16-84ff-22d9582f1449 after calculating the sin of 1.5 radians, divi... \n",
|
||||
"67867526-791a-452f-b534-ef2c1f5efd20 ecoli divides every 20 minutes. How many cells... \n",
|
||||
"4ac33c1a-62f0-4da4-9455-07b582f6ff52 calculate 101 to the power of 0.5 to 4 digits ... \n",
|
||||
"2e82a924-8382-425e-8738-daa2d912e9fe convert 15 degrees to radians \n",
|
||||
"\n",
|
||||
" outputs.output \\\n",
|
||||
"27c44572-6c67-4129-a95a-fe1509c350be \n",
|
||||
"2a20a13d-050e-4a16-84ff-22d9582f1449 \n",
|
||||
"67867526-791a-452f-b534-ef2c1f5efd20 \n",
|
||||
"4ac33c1a-62f0-4da4-9455-07b582f6ff52 \n",
|
||||
"2e82a924-8382-425e-8738-daa2d912e9fe \n",
|
||||
"\n",
|
||||
" outputs.intermediate_steps \\\n",
|
||||
"27c44572-6c67-4129-a95a-fe1509c350be [] \n",
|
||||
"2a20a13d-050e-4a16-84ff-22d9582f1449 [] \n",
|
||||
"67867526-791a-452f-b534-ef2c1f5efd20 [] \n",
|
||||
"4ac33c1a-62f0-4da4-9455-07b582f6ff52 [] \n",
|
||||
"2e82a924-8382-425e-8738-daa2d912e9fe [] \n",
|
||||
"\n",
|
||||
" feedback.Intermediate steps correctness \\\n",
|
||||
"27c44572-6c67-4129-a95a-fe1509c350be 0 \n",
|
||||
"2a20a13d-050e-4a16-84ff-22d9582f1449 0 \n",
|
||||
"67867526-791a-452f-b534-ef2c1f5efd20 0 \n",
|
||||
"4ac33c1a-62f0-4da4-9455-07b582f6ff52 0 \n",
|
||||
"2e82a924-8382-425e-8738-daa2d912e9fe 0 \n",
|
||||
"\n",
|
||||
" feedback.# steps / # expected steps \\\n",
|
||||
"27c44572-6c67-4129-a95a-fe1509c350be 0.0 \n",
|
||||
"2a20a13d-050e-4a16-84ff-22d9582f1449 0.0 \n",
|
||||
"67867526-791a-452f-b534-ef2c1f5efd20 0.0 \n",
|
||||
"4ac33c1a-62f0-4da4-9455-07b582f6ff52 0.0 \n",
|
||||
"2e82a924-8382-425e-8738-daa2d912e9fe 0.0 \n",
|
||||
"\n",
|
||||
" feedback.correctness error \\\n",
|
||||
"27c44572-6c67-4129-a95a-fe1509c350be 0 None \n",
|
||||
"2a20a13d-050e-4a16-84ff-22d9582f1449 0 None \n",
|
||||
"67867526-791a-452f-b534-ef2c1f5efd20 0 None \n",
|
||||
"4ac33c1a-62f0-4da4-9455-07b582f6ff52 0 None \n",
|
||||
"2e82a924-8382-425e-8738-daa2d912e9fe 0 None \n",
|
||||
"\n",
|
||||
" execution_time \n",
|
||||
"27c44572-6c67-4129-a95a-fe1509c350be 0.763208 \n",
|
||||
"2a20a13d-050e-4a16-84ff-22d9582f1449 1.413695 \n",
|
||||
"67867526-791a-452f-b534-ef2c1f5efd20 1.773183 \n",
|
||||
"4ac33c1a-62f0-4da4-9455-07b582f6ff52 1.819677 \n",
|
||||
"2e82a924-8382-425e-8738-daa2d912e9fe 1.957470 "
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# You can interact with the object directly or as a flattened dataframe\n",
|
||||
"df = test_run.to_dataframe()\n",
|
||||
"df.head()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "1bf4ea77-147f-4687-a2c6-7528a6eba08d",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"df.to_csv(\"output.csv\", index=False)"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -2,29 +2,132 @@
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "1ba9f105-c48f-4d8c-8253-355ef13156b0",
|
||||
"id": "6aae613b-6adb-4e6f-bae7-4974358e07aa",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"# Benchmark All Tasks\n",
|
||||
"\n",
|
||||
"Let's benchmark against all tool usage tasks. \n",
|
||||
"\n",
|
||||
"Expand the `test` list to benchmark with different models and agent architectures.\n",
|
||||
"\n",
|
||||
"Note that this requires `langsmith>=0.0.72` to run the viz parts at the end."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4525d100-b612-4118-af91-6bdc4aa3fb38",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Benchmark All\n",
|
||||
"## Set Up\n",
|
||||
"\n",
|
||||
"Here, we'll run benchmarking against all tool usage task.\n",
|
||||
"\n",
|
||||
"Expand the models list to benchmark against different models."
|
||||
"### Credentials\n",
|
||||
"\n",
|
||||
"First, let's set up the models to be tested and the credentials."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "13a7483b-d08f-49fa-83da-619863171e5b",
|
||||
"execution_count": 10,
|
||||
"id": "387c494b-ad7e-452e-8d11-0d5d28db855c",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import datetime\n",
|
||||
"import uuid\n",
|
||||
"import os\n",
|
||||
"from getpass import getpass\n",
|
||||
"\n",
|
||||
"from langchain.globals import set_verbose\n",
|
||||
"# This is just the default list below\n",
|
||||
"required_env_vars = [\n",
|
||||
" \"LANGCHAIN_API_KEY\",\n",
|
||||
" \"ANTHROPIC_API_KEY\",\n",
|
||||
" \"OPENAI_API_KEY\",\n",
|
||||
" \"MISTRAL_API_KEY\",\n",
|
||||
"]\n",
|
||||
"for var in required_env_vars:\n",
|
||||
" if var not in os.environ:\n",
|
||||
" os.environ[var] = getpass(f\"Provide the required {var}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "d45e54ab-ebbe-4b9a-a596-facae66e1ced",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Instantiate Models"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "d3a4e40a-5850-4a0b-b9af-36e9c8b55e8b",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_anthropic import ChatAnthropic\n",
|
||||
"from langchain_core.tools import tool\n",
|
||||
"from langchain_google_vertexai import ChatVertexAI\n",
|
||||
"from langchain_mistralai import ChatMistralAI\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"from langchain_benchmarks.tool_usage.agents import StandardAgentFactory\n",
|
||||
"\n",
|
||||
"tests = [\n",
|
||||
" (\n",
|
||||
" \"gemini-1.0-pro-002\",\n",
|
||||
" ChatVertexAI(model_name=\"gemini-1.0-pro-002\", temperature=0),\n",
|
||||
" ),\n",
|
||||
" (\n",
|
||||
" \"gemini-1.5-pro-preview-0409\",\n",
|
||||
" ChatVertexAI(model_name=\"gemini-1.5-pro-preview-0409\", temperature=0),\n",
|
||||
" ),\n",
|
||||
" (\n",
|
||||
" \"open-mixtral-8x22b-2404\",\n",
|
||||
" ChatMistralAI(model=\"open-mixtral-8x22b-2404\", temperature=0),\n",
|
||||
" ),\n",
|
||||
" (\"mistral-large-2402\", ChatMistralAI(model=\"mistral-large-2402\", temperature=0)),\n",
|
||||
" (\n",
|
||||
" \"claude-3-opus-20240229\",\n",
|
||||
" ChatAnthropic(model=\"claude-3-opus-20240229\", temperature=0),\n",
|
||||
" ),\n",
|
||||
" (\n",
|
||||
" \"claude-3-haiku-20240307\",\n",
|
||||
" ChatAnthropic(model=\"claude-3-haiku-20240307\", temperature=0),\n",
|
||||
" ),\n",
|
||||
" (\n",
|
||||
" \"claude-3-sonnet-20240229\",\n",
|
||||
" ChatAnthropic(model=\"claude-3-sonnet-20240229\", temperature=0),\n",
|
||||
" ),\n",
|
||||
" (\"gpt-3.5-turbo-0125\", ChatOpenAI(model=\"gpt-3.5-turbo-0125\", temperature=0)),\n",
|
||||
" (\n",
|
||||
" \"gpt-4-turbo-2024-04-09\",\n",
|
||||
" ChatOpenAI(model=\"gpt-4-turbo-2024-04-09\", temperature=0),\n",
|
||||
" ),\n",
|
||||
"]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "6308c18a-209c-44f8-b762-7a07851101f2",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Set up the experiment"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "9e152e2e-1fb1-4918-9a53-0744c0ef0035",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import datetime\n",
|
||||
"\n",
|
||||
"from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder\n",
|
||||
"from langsmith.client import Client\n",
|
||||
"\n",
|
||||
"from langchain_benchmarks import (\n",
|
||||
@@ -33,161 +136,372 @@
|
||||
" model_registry,\n",
|
||||
" registry,\n",
|
||||
")\n",
|
||||
"from langchain_benchmarks.rate_limiting import RateLimiter\n",
|
||||
"from langchain_benchmarks.tool_usage.agents import (\n",
|
||||
" CustomAgentFactory,\n",
|
||||
" OpenAIAgentFactory,\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "50bbe23b-a3b1-4607-929d-ea6e88b7085e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Prior to starting the tests, you may want to verify\n",
|
||||
"that the task that you're working with and the models are propelry defined."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "adfbcaa9-349c-4223-89be-4abff9cf76ff",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'input': \"Repeat the given string using the provided tools. Do not write anything else or provide any explanations. For example, if the string is 'abc', you must print the letters 'a', 'b', and 'c' one at a time and in that order. \\nWrite down your answer, but do not explain it. Input: `abc`\",\n",
|
||||
" 'output': ' Thank you for the input and for confirming the output of each letter I printed. I simply followed the instructions to repeat the given string \"abc\" by printing one letter at a time using the provided \"type_letter\" tool without any additional explanations. Please let me know if you need me to repeat this process with a different input string.',\n",
|
||||
" 'intermediate_steps': [(AgentActionMessageLog(tool='type_letter', tool_input={'letter': 'a'}, log=\"\\nInvoking type_letter: {'letter': 'a'}\\n\\t\", message_log=[AIMessage(content='<tool>{\\n \"tool_name\": \"type_letter\",\\n \"arguments\": {\\n \"letter\": \"a\"\\n }\\n}</tool>\\n')]),\n",
|
||||
" 'OK'),\n",
|
||||
" (AgentActionMessageLog(tool='type_letter', tool_input={'letter': 'b'}, log=\"\\nInvoking type_letter: {'letter': 'b'}\\n\\t\", message_log=[AIMessage(content='<tool>{\\n \"tool_name\": \"type_letter\",\\n \"arguments\": {\\n \"letter\": \"b\"\\n }\\n}</tool>\\n')]),\n",
|
||||
" 'OK'),\n",
|
||||
" (AgentActionMessageLog(tool='type_letter', tool_input={'letter': 'c'}, log=\"\\nInvoking type_letter: {'letter': 'c'}\\n\\t\", message_log=[AIMessage(content='<tool>{\\n \"tool_name\": \"type_letter\",\\n \"arguments\": {\\n \"letter\": \"c\"\\n }\\n}</tool>\\n')]),\n",
|
||||
" 'OK')],\n",
|
||||
" 'state': 'abc'}"
|
||||
]
|
||||
},
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"task = registry[\"Tool Usage - Typewriter (1 tool)\"]\n",
|
||||
"agent_factory = CustomAgentFactory(task, \"claude-2.1\")\n",
|
||||
"\n",
|
||||
"agent_factory().invoke({\"question\": \"abc\"})"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "65b32e7d-3986-4461-8a3b-8e9b6d4008cb",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Define the test cases"
|
||||
"from langchain_benchmarks.rate_limiting import RateLimiter"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "26d390b6-9ade-424c-aabb-d450f52ed121",
|
||||
"id": "28e4664d-00a1-473b-ae83-f2435962971a",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Create prompts for the agents\n",
|
||||
"# Using two prompts because some chat models do not support SystemMessage.\n",
|
||||
"without_system_message_prompt = ChatPromptTemplate.from_messages(\n",
|
||||
" [\n",
|
||||
" (\n",
|
||||
" \"human\",\n",
|
||||
" \"{instructions}\\n{question}\",\n",
|
||||
" ), # Populated from task.instructions automatically\n",
|
||||
" MessagesPlaceholder(\"agent_scratchpad\"), # Workspace for the agent\n",
|
||||
" ]\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"with_system_message_prompt = ChatPromptTemplate.from_messages(\n",
|
||||
" [\n",
|
||||
" (\"system\", \"{instructions}\"),\n",
|
||||
" (\"human\", \"{question}\"), # Populated from task.instructions automatically\n",
|
||||
" MessagesPlaceholder(\"agent_scratchpad\"), # Workspace for the agent\n",
|
||||
" ]\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "a165f3a1-4e70-4caa-b082-78d4e0c56410",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Generate an experiment id.\n",
|
||||
"\n",
|
||||
"We can tag our runs with this experiment ID and pull data from LangSmith using this experiment ID."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"id": "066d7695-416c-4faf-8c33-c40e5f136672",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"tests = [\n",
|
||||
" # 2-tuple of (architecture, model name)\n",
|
||||
" (\"xml\", \"mixtral-8x7b-instruct-fw\"),\n",
|
||||
" (\"xml\", \"claude-2.1\"),\n",
|
||||
" (\"xml\", \"claude-2\"),\n",
|
||||
" (\"xml\", \"yi-34b-200k-fw\"),\n",
|
||||
" (\"xml\", \"llama-v2-70b-chat-fw\"),\n",
|
||||
" (\"xml\", \"llama-v2-13b-chat-fw\"),\n",
|
||||
" (\"openai_functions\", \"gpt-3.5-turbo-1106\"),\n",
|
||||
" (\"openai_functions\", \"gpt-3.5-turbo-0613\"),\n",
|
||||
" (\"openai_functions\", \"gpt-4-1106-preview\")(\"openai_functions\", \"gpt-4-0613\"),\n",
|
||||
"]"
|
||||
"experiment_uuid = \"sky25\" # Or generate ranom using uuid.uuid4().hex[:4]\n",
|
||||
"# experiment_uuid = uuid.uuid4().hex[:4]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b55b7c24-8b4d-4bd7-8b00-365fbe61897f",
|
||||
"id": "d125aad7-cac7-4ec7-9c18-98defe9d2236",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Run"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "a415dd82-2e70-4173-a3f3-8e1aac60db9e",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"experiment_uuid = uuid.uuid4().hex[:4]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "e6fbc3ef-7a3f-430f-8b79-45af5861b3ee",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"id": "03c4c45e-88a6-4c96-ba5d-cfaf03905789",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"client = Client() # Launch langsmith client for cloning datasets\n",
|
||||
"today = datetime.date.today().isoformat()\n",
|
||||
"rate_limiter = RateLimiter(requests_per_second=1)\n",
|
||||
"\n",
|
||||
"for task in registry:\n",
|
||||
" dataset_name = task.name + f\"_benchmarking_{today}\"\n",
|
||||
" clone_public_dataset(task.dataset_id, dataset_name=dataset_name)\n",
|
||||
"\n",
|
||||
"for task in registry.tasks:\n",
|
||||
" if task.type != \"ToolUsageTask\":\n",
|
||||
" continue\n",
|
||||
"\n",
|
||||
" for arch, model in tests:\n",
|
||||
" # This is a small test dataset that can be used to verify\n",
|
||||
" # that everything is set up correctly prior to running over\n",
|
||||
" # all results. We may remove it in the future.\n",
|
||||
" if task.name == \"Multiverse Math (Tiny)\":\n",
|
||||
" continue\n",
|
||||
"\n",
|
||||
" dataset_name = task.name + f\" ({today})\"\n",
|
||||
" clone_public_dataset(task.dataset_id, dataset_name=dataset_name)\n",
|
||||
"\n",
|
||||
" for model_name, model in tests:\n",
|
||||
" if model_name.startswith(\"gemini\"):\n",
|
||||
" # google models don't use system prompt\n",
|
||||
" prompt = without_system_message_prompt\n",
|
||||
" rate_limiter = RateLimiter(requests_per_second=0.1)\n",
|
||||
" else:\n",
|
||||
" prompt = with_system_message_prompt\n",
|
||||
" rate_limiter = RateLimiter(requests_per_second=1)\n",
|
||||
" print()\n",
|
||||
" print(f\"Benchmarking {task.name} with model: {model} and arch: {arch}\")\n",
|
||||
" print(f\"Benchmarking {task.name} with model: {model_name}\")\n",
|
||||
" eval_config = task.get_eval_config()\n",
|
||||
"\n",
|
||||
" if arch == \"openai_functions\":\n",
|
||||
" agent_factory = OpenAIAgentFactory(\n",
|
||||
" task, model=model, rate_limiter=rate_limiter\n",
|
||||
" )\n",
|
||||
" elif arch == \"xml\":\n",
|
||||
" agent_factory = CustomAgentFactory(\n",
|
||||
" task, model=model, rate_limiter=rate_limiter\n",
|
||||
" )\n",
|
||||
" else:\n",
|
||||
" raise ValueError()\n",
|
||||
" agent_factory = StandardAgentFactory(\n",
|
||||
" task, model, prompt, rate_limiter=rate_limiter\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
" client.run_on_dataset(\n",
|
||||
" dataset_name=dataset_name,\n",
|
||||
" llm_or_chain_factory=agent_factory,\n",
|
||||
" evaluation=eval_config,\n",
|
||||
" verbose=False,\n",
|
||||
" project_name=f\"{model}{experiment_uuid}\",\n",
|
||||
" tags=[model],\n",
|
||||
" project_name=f\"{model_name}-{task.name}-{today}-{experiment_uuid}\",\n",
|
||||
" concurrency_level=5,\n",
|
||||
" project_metadata={\n",
|
||||
" \"model\": model,\n",
|
||||
" \"model\": model_name,\n",
|
||||
" \"id\": experiment_uuid,\n",
|
||||
" \"task\": task.name,\n",
|
||||
" \"date\": today,\n",
|
||||
" \"langchain_benchmarks_version\": __version__,\n",
|
||||
" \"arch\": arch,\n",
|
||||
" },\n",
|
||||
" )\n",
|
||||
" break"
|
||||
" )"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "54e7999f-e8ab-45a6-88a9-0ae76f3d24cf",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Inspect\n",
|
||||
"\n",
|
||||
"Note that if the queue is under significant load, you may want to wait before running the following to ensure all runs are in the DB and all stats are correctly computed."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "598b92f0-7d64-4731-b294-05948d4db562",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!pip install --quiet -U pandas"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"id": "7818572a-a5fb-4153-bbe0-6f9e90813a22",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import matplotlib.pyplot as plt\n",
|
||||
"import numpy as np\n",
|
||||
"import pandas as pd\n",
|
||||
"from langsmith.client import Client"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e7890951-ffde-4706-95e5-ae3e9bf0e8a6",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Let's fetch all the data that has the same experiment ID and place it in a dataframe."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 25,
|
||||
"id": "44822aa4-8c4e-46be-8126-b79a9acdf8e1",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"experiment_ids = [\"sky25\"]\n",
|
||||
"dataset_names = [\n",
|
||||
" \"Tool Usage - Typewriter (1 tool)\",\n",
|
||||
" \"Tool Usage - Typewriter (26 tools)\",\n",
|
||||
" \"Tool Usage - Relational Data\",\n",
|
||||
" \"Multiverse Math\",\n",
|
||||
"]\n",
|
||||
"\n",
|
||||
"client = Client()\n",
|
||||
"projects = []\n",
|
||||
"for dataset_name in dataset_names:\n",
|
||||
" dataset_name_ = dataset_name + f\" ({today})\"\n",
|
||||
" for project in client.list_projects(reference_dataset_name=dataset_name_):\n",
|
||||
" if (\n",
|
||||
" project.metadata.get(\"id\") in experiment_ids\n",
|
||||
" and project.end_time is not None\n",
|
||||
" ):\n",
|
||||
" projects.append(project)\n",
|
||||
"\n",
|
||||
"dfs = []\n",
|
||||
"keys = set()\n",
|
||||
"for project in projects:\n",
|
||||
" # Temporary way to get tag information\n",
|
||||
" try:\n",
|
||||
" test_results = client.get_test_results(project_name=project.name)\n",
|
||||
" except Exception as e:\n",
|
||||
" print(e, project.run_count)\n",
|
||||
" continue\n",
|
||||
"\n",
|
||||
" for k, v in project.metadata.items():\n",
|
||||
" test_results[k] = v\n",
|
||||
" keys.update(test_results.columns)\n",
|
||||
" dfs.append(test_results)\n",
|
||||
"for df in dfs:\n",
|
||||
" missing = list(keys - set(df.columns))\n",
|
||||
" for key in missing:\n",
|
||||
" df[key] = None\n",
|
||||
"df = pd.concat(dfs)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "9065b7a0-d514-49f7-9d79-67181c41f56d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Compute a standardized \"correct\" column. It uses \"Correct Final State\" for tool usage tasks, and \"correctness (which is based on output) for the other tasks."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 26,
|
||||
"id": "b3c0466a-25f4-44d7-bd2a-20da51461994",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"correct = []\n",
|
||||
"\n",
|
||||
"for r in df.to_dict(orient=\"records\"):\n",
|
||||
" if \"Typewriter\" in r[\"task\"]:\n",
|
||||
" correct.append(r[\"feedback.correct final state\"])\n",
|
||||
" else:\n",
|
||||
" correct.append(r[\"feedback.correctness\"])\n",
|
||||
"\n",
|
||||
"df[\"correct\"] = correct\n",
|
||||
"df[\"correct\"].fillna(0, inplace=True)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "270b8ae9-c84b-4ebc-88ab-fa0ac5e28a57",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Compute some statistics. We're using estimating standard error of the mean assuming a bernoulli process."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 27,
|
||||
"id": "c59d080c-d3ac-43c3-a527-9961913db2ba",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"num_correct = df.groupby([\"model\", \"task\"])[\"correct\"].sum().to_frame(\"num_correct\")\n",
|
||||
"total = df.groupby([\"task\", \"model\"]).size().to_frame(\"total\")\n",
|
||||
"stats_df = total.join(num_correct)\n",
|
||||
"stats_df[\"% correct\"] = stats_df[\"num_correct\"] / stats_df[\"total\"]\n",
|
||||
"stats_df[\"error\"] = np.sqrt(\n",
|
||||
" stats_df[\"% correct\"] * (1 - stats_df[\"% correct\"]) / stats_df[\"total\"]\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"tasks = [\n",
|
||||
" \"Tool Usage - Typewriter (1 tool)\",\n",
|
||||
" \"Tool Usage - Typewriter (26 tools)\",\n",
|
||||
" \"Multiverse Math\",\n",
|
||||
" \"Tool Usage - Relational Data\",\n",
|
||||
"]\n",
|
||||
"\n",
|
||||
"stats_df = stats_df.reset_index()\n",
|
||||
"models = stats_df[\"model\"].unique()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 28,
|
||||
"id": "bdbd6005-906a-42fd-af05-b4f27e2c3c51",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"array(['claude-3-haiku-20240307', 'claude-3-opus-20240229',\n",
|
||||
" 'claude-3-sonnet-20240229', 'gemini-1.0-pro-002',\n",
|
||||
" 'gemini-1.5-pro-preview-0409', 'gpt-3.5-turbo-0125',\n",
|
||||
" 'gpt-4-turbo-2024-04-09', 'mistral-large-2402',\n",
|
||||
" 'open-mixtral-8x22b-2404'], dtype=object)"
|
||||
]
|
||||
},
|
||||
"execution_count": 28,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"models"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "1d9f79af-128c-4e2e-8c1e-807e397b9791",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"Plot the result"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "69df66a1-960c-40a3-abc8-58b503fceda5",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from itertools import product\n",
|
||||
"\n",
|
||||
"x = np.arange(len(tasks)) # the label locations\n",
|
||||
"width = 0.06 # the width of the bars\n",
|
||||
"multiplier = 1.1\n",
|
||||
"\n",
|
||||
"fig, ax = plt.subplots(layout=\"constrained\", figsize=(20, 4))\n",
|
||||
"colormap = plt.get_cmap(\"Set3\").colors\n",
|
||||
"idx = 0\n",
|
||||
"for model in models:\n",
|
||||
" try:\n",
|
||||
" results = stats_df.set_index(\"model\").loc[model]\n",
|
||||
" except:\n",
|
||||
" continue\n",
|
||||
" if len(results) == 0:\n",
|
||||
" continue\n",
|
||||
" color = colormap[idx]\n",
|
||||
" idx += 1\n",
|
||||
"\n",
|
||||
" results = results.set_index(\"task\").loc[tasks]\n",
|
||||
" measurement = results[\"% correct\"]\n",
|
||||
"\n",
|
||||
" values = [round(m, 2) for m in measurement]\n",
|
||||
"\n",
|
||||
" offset = width * multiplier * 1.4\n",
|
||||
" rects = ax.bar(\n",
|
||||
" x + offset,\n",
|
||||
" values,\n",
|
||||
" width,\n",
|
||||
" label=f\"{model}\",\n",
|
||||
" yerr=results[\"error\"],\n",
|
||||
" color=color,\n",
|
||||
" )\n",
|
||||
" ax.bar_label(rects, padding=3)\n",
|
||||
" multiplier += 1\n",
|
||||
"\n",
|
||||
"# Add some text for labels, title and custom x-axis tick labels, etc.\n",
|
||||
"ax.set_ylabel(\"% Questions Answered Correctly\")\n",
|
||||
"ax.set_title(\"Tool Usage Performance\")\n",
|
||||
"ax.set_xticks(x + width + 0.3, tasks)\n",
|
||||
"ax.legend(\n",
|
||||
" loc=\"center left\", ncols=1, bbox_to_anchor=(1.0, 0.5), frameon=False, title=\"Model\"\n",
|
||||
")\n",
|
||||
"ax.set_ylim(0, 1.10)\n",
|
||||
"plt.savefig(\"overall_perf.png\", dpi=300, bbox_inches=\"tight\")\n",
|
||||
"plt.show()"
|
||||
]
|
||||
}
|
||||
],
|
||||
|
||||
@@ -2,8 +2,10 @@
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "6728b05f-e3bb-487a-8818-e0d5d18b5501",
|
||||
"metadata": {},
|
||||
"id": "1c9df2ed-3496-45c6-8b1b-e12776a02a0f",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"# Introduction\n",
|
||||
"\n",
|
||||
@@ -17,42 +19,11 @@
|
||||
"* Can the agent use more than 10 tools effectively?\n",
|
||||
"* Can the agent correctly incorporate information returned by the tool (and ignore internal knowledge)?\n",
|
||||
"\n",
|
||||
"To help in this evaluation, each task is associated with a LangSmith dataset that includes input/output examples of varying difficulties."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e274faca-26fc-470b-8485-5a81b83e2c54",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Evaluation"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "cbe7a63b-04f3-4121-9fe6-5ce772527e85",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"How does one evaluate an agent? Given a particular task and input, an agent uses tools to produce an output AND/OR change the state of the environment.\n",
|
||||
"To help in this evaluation, each task is associated with a LangSmith dataset that includes input/output examples of varying difficulties.\n",
|
||||
"\n",
|
||||
"To evaluate an agent, we can check the following:\n",
|
||||
"\n",
|
||||
"1. Did the agent use the expected tools?\n",
|
||||
"2. Did the agent use the tools in the most effective way; e.g., was the order of tool invocation correct?\n",
|
||||
"3. Did the environment end up in the correct final state after the agent used the tools? (e.g., does my calendar contain all the scheduled meetings?)\n",
|
||||
"4. Did the agent output match the expected reference output?"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "34bb4fb7-085a-4f8f-a670-3ad7b479d8b4",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"## Schema\n",
|
||||
"\n",
|
||||
"To make it possible to evaluate different agent implementations, we're using a standardized schema, we'll illustrate it with the following example taken from tool usage:\n",
|
||||
"To make it possible to evaluate different agent implementations, we're using a standardized schema, we'll illustrate it with the following example taken from tool usage.\n",
|
||||
"\n",
|
||||
"### Dataset\n",
|
||||
"\n",
|
||||
@@ -105,32 +76,7 @@
|
||||
" \"intermediate_steps\": [... \"find_locations_by_name\" ...], // list of the intermediate steps taken by the agent (see format in LangChain)\n",
|
||||
" \"state\": .., // Can be anything, this is the state fo the environment after the agent has taken all of its actions (optional key)\n",
|
||||
"}\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"## Standard Evaluator\n",
|
||||
"\n",
|
||||
"This task is associated with a standard evaluator that can be used to benchmark different aspects of tool usage.\n",
|
||||
"\n",
|
||||
"Specifically:\n",
|
||||
"\n",
|
||||
"1. Use an LLM to grade Compare output to reference using an LLM that grades the response.\n",
|
||||
"2. Compare equality of expected_steps to the list of tools in intermediate_steps -- simple list equality\n",
|
||||
"3. Compare the state of the environment against expected state (if present in the dataset and in the agent)\n",
|
||||
"4. It does not use `order_matters` at the moment"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "5af4134d-5c96-472c-b575-21f9be46e02d",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_benchmarks.tool_usage import get_eval_config\n",
|
||||
"\n",
|
||||
"run_eval_config = get_eval_config()"
|
||||
"```"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -147,7 +93,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"execution_count": 1,
|
||||
"id": "3b9b82fc-b689-4a25-b718-99ecc2fc6867",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -190,19 +136,21 @@
|
||||
"Each example is composed of a question, a reference answer, and information about the sequence in which tools should be used to answer the question.\n",
|
||||
"\n",
|
||||
"Success is measured by the ability to answer the question correctly, and efficiently. </td></tr>\n",
|
||||
"<tr><td>Multiverse Math </td><td>ToolUsageTask</td><td><a href=\"https://smith.langchain.com/public/594f9f60-30a0-49bf-b075-f44beabf546a/d\" target=\"_blank\" rel=\"noopener\">594f9f60-30a0-49bf-b075-f44beabf546a</a></td><td>An environment that contains a few basic math operations, but with altered results.\n",
|
||||
"<tr><td>Multiverse Math </td><td>ToolUsageTask</td><td><a href=\"https://smith.langchain.com/public/47ed57bc-e852-4f84-a23e-cce4793864e9/d\" target=\"_blank\" rel=\"noopener\">47ed57bc-e852-4f84-a23e-cce4793864e9</a></td><td>An environment that contains a few basic math operations, but with altered results.\n",
|
||||
"\n",
|
||||
"For example, multiplication of 5*3 will be re-interpreted as 5*3*1.1. The basic operations retain some basic properties, such as commutativity, associativity, and distributivity; however, the results are different than expected.\n",
|
||||
"\n",
|
||||
"The objective of this task is to evaluate the ability to use the provided tools to solve simple math questions and ignore any innate knowledge about math. </td></tr>\n",
|
||||
"The objective of this task is to evaluate the ability to use the provided tools to solve simple math questions and ignore any innate knowledge about math.\n",
|
||||
"\n",
|
||||
"This task is associated with 20 test examples. </td></tr>\n",
|
||||
"</tbody>\n",
|
||||
"</table>"
|
||||
],
|
||||
"text/plain": [
|
||||
"Registry(tasks=[ToolUsageTask(name='Tool Usage - Typewriter (1 tool)', dataset_id='https://smith.langchain.com/public/59577193-8938-4ccf-92a7-e8a96bcf4f86/d', description=\"Environment with a single tool that accepts a single letter as input, and prints it on a piece of virtual paper.\\n\\nThe objective of this task is to evaluate the ability of the model to use the provided tools to repeat a given input string.\\n\\nFor example, if the string is 'abc', the tools 'a', 'b', and 'c' must be invoked in that order.\\n\\nThe dataset includes examples of varying difficulty. The difficulty is measured by the length of the string.\\n\", create_environment=<function get_environment at 0x7f8f5f01a520>, instructions=\"Repeat the given string using the provided tools. Do not write anything else or provide any explanations. For example, if the string is 'abc', you must print the letters 'a', 'b', and 'c' one at a time and in that order. \"), ToolUsageTask(name='Tool Usage - Typewriter (26 tools)', dataset_id='https://smith.langchain.com/public/128af05e-aa00-4e3b-a958-d166dd450581/d', description=\"Environment with 26 tools each tool represents a letter of the alphabet.\\n\\nThe objective of this task is to evaluate the model's ability the use tools\\nfor a simple repetition task.\\n\\nFor example, if the string is 'abc', the tools 'a', 'b', and 'c' must be invoked in that order.\\n\\nThe dataset includes examples of varying difficulty. The difficulty is measured by the length of the string.\\n\\nThis is a variation of the typer writer task, where 26 parameterless tools are\\ngiven instead of a single tool that takes a letter as an argument.\\n\", create_environment=<function get_environment at 0x7f8f5f01aa20>, instructions=\"Repeat the given string by using the provided tools. Do not write anything else or provide any explanations. For example, if the string is 'abc', you must invoke the tools 'a', 'b', and 'c' in that order. Please invoke the functions without any arguments.\"), ToolUsageTask(name='Tool Usage - Relational Data', dataset_id='https://smith.langchain.com/public/1d89f4b3-5f73-48cf-a127-2fdeb22f6d84/d', description='Environment with fake data about users and their locations and favorite foods.\\n\\nThe environment provides a set of tools that can be used to query the data.\\n\\nThe objective of this task is to evaluate the ability to use the provided tools to answer questions about relational data.\\n\\nThe dataset contains 21 examples of varying difficulty. The difficulty is measured by the number of tools that need to be used to answer the question.\\n\\nEach example is composed of a question, a reference answer, and information about the sequence in which tools should be used to answer the question.\\n\\nSuccess is measured by the ability to answer the question correctly, and efficiently.\\n', create_environment=<function get_environment at 0x7f8f5f01a020>, instructions=\"Please answer the user's question by using the tools provided. Do not guess the answer. Keep in mind that entities like users,foods and locations have both a name and an ID, which are not the same.\"), ToolUsageTask(name='Multiverse Math', dataset_id='https://smith.langchain.com/public/594f9f60-30a0-49bf-b075-f44beabf546a/d', description='An environment that contains a few basic math operations, but with altered results.\\n\\nFor example, multiplication of 5*3 will be re-interpreted as 5*3*1.1. The basic operations retain some basic properties, such as commutativity, associativity, and distributivity; however, the results are different than expected.\\n\\nThe objective of this task is to evaluate the ability to use the provided tools to solve simple math questions and ignore any innate knowledge about math.\\n', create_environment=<function get_environment at 0x7f8f5f019a80>, instructions='You are requested to solve math questions in an alternate mathematical universe. The operations have been altered to yield different results than expected. Do not guess the answer or rely on your innate knowledge of math. Use the provided tools to answer the question. While associativity and commutativity apply, distributivity does not. Answer the question using the fewest possible tools. Only include the numeric response without any clarifications.')])"
|
||||
"Registry(tasks=[ToolUsageTask(name='Tool Usage - Typewriter (1 tool)', dataset_id='https://smith.langchain.com/public/59577193-8938-4ccf-92a7-e8a96bcf4f86/d', description=\"Environment with a single tool that accepts a single letter as input, and prints it on a piece of virtual paper.\\n\\nThe objective of this task is to evaluate the ability of the model to use the provided tools to repeat a given input string.\\n\\nFor example, if the string is 'abc', the tools 'a', 'b', and 'c' must be invoked in that order.\\n\\nThe dataset includes examples of varying difficulty. The difficulty is measured by the length of the string.\\n\", create_environment=<function get_environment at 0x7b3a9f5fad40>, instructions=\"Repeat the given string using the provided tools. Do not write anything else or provide any explanations. For example, if the string is 'abc', you must print the letters 'a', 'b', and 'c' one at a time and in that order. \", eval_params={'output_evaluation': 'none'}), ToolUsageTask(name='Tool Usage - Typewriter (26 tools)', dataset_id='https://smith.langchain.com/public/128af05e-aa00-4e3b-a958-d166dd450581/d', description=\"Environment with 26 tools each tool represents a letter of the alphabet.\\n\\nThe objective of this task is to evaluate the model's ability the use tools\\nfor a simple repetition task.\\n\\nFor example, if the string is 'abc', the tools 'a', 'b', and 'c' must be invoked in that order.\\n\\nThe dataset includes examples of varying difficulty. The difficulty is measured by the length of the string.\\n\\nThis is a variation of the typer writer task, where 26 parameterless tools are\\ngiven instead of a single tool that takes a letter as an argument.\\n\", create_environment=<function get_environment at 0x7b3a9f5fb240>, instructions=\"Repeat the given string by using the provided tools. Do not write anything else or provide any explanations. For example, if the string is 'abc', you must invoke the tools 'a', 'b', and 'c' in that order. Please invoke the functions without any arguments.\", eval_params={'output_evaluation': 'none'}), ToolUsageTask(name='Tool Usage - Relational Data', dataset_id='https://smith.langchain.com/public/1d89f4b3-5f73-48cf-a127-2fdeb22f6d84/d', description='Environment with fake data about users and their locations and favorite foods.\\n\\nThe environment provides a set of tools that can be used to query the data.\\n\\nThe objective of this task is to evaluate the ability to use the provided tools to answer questions about relational data.\\n\\nThe dataset contains 21 examples of varying difficulty. The difficulty is measured by the number of tools that need to be used to answer the question.\\n\\nEach example is composed of a question, a reference answer, and information about the sequence in which tools should be used to answer the question.\\n\\nSuccess is measured by the ability to answer the question correctly, and efficiently.\\n', create_environment=<function get_environment at 0x7b3a9f5fa840>, instructions=\"Please answer the user's question by using the tools provided. Do not guess the answer. Keep in mind that entities like users,foods and locations have both a name and an ID, which are not the same.\", eval_params={}), ToolUsageTask(name='Multiverse Math', dataset_id='https://smith.langchain.com/public/47ed57bc-e852-4f84-a23e-cce4793864e9/d', description='An environment that contains a few basic math operations, but with altered results.\\n\\nFor example, multiplication of 5*3 will be re-interpreted as 5*3*1.1. The basic operations retain some basic properties, such as commutativity, associativity, and distributivity; however, the results are different than expected.\\n\\nThe objective of this task is to evaluate the ability to use the provided tools to solve simple math questions and ignore any innate knowledge about math.\\n\\nThis task is associated with 20 test examples.\\n', create_environment=<function get_environment at 0x7b3a9f5fa200>, instructions='You are requested to solve math questions in an alternate mathematical universe. The operations have been altered to yield different results than expected. Do not guess the answer or rely on your innate knowledge of math. Use the provided tools to answer the question. While associativity and commutativity apply, distributivity does not. Answer the question using the fewest possible tools. Only include the numeric response without any clarifications.', eval_params={'output_evaluation': 'qa_math_without_question'})])"
|
||||
]
|
||||
},
|
||||
"execution_count": 2,
|
||||
"execution_count": 1,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -223,7 +171,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"execution_count": 2,
|
||||
"id": "7543739b-d212-4249-9b4a-fc406a58c9c7",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -252,10 +200,10 @@
|
||||
"</table>"
|
||||
],
|
||||
"text/plain": [
|
||||
"ToolUsageTask(name='Tool Usage - Typewriter (26 tools)', dataset_id='https://smith.langchain.com/public/128af05e-aa00-4e3b-a958-d166dd450581/d', description=\"Environment with 26 tools each tool represents a letter of the alphabet.\\n\\nThe objective of this task is to evaluate the model's ability the use tools\\nfor a simple repetition task.\\n\\nFor example, if the string is 'abc', the tools 'a', 'b', and 'c' must be invoked in that order.\\n\\nThe dataset includes examples of varying difficulty. The difficulty is measured by the length of the string.\\n\\nThis is a variation of the typer writer task, where 26 parameterless tools are\\ngiven instead of a single tool that takes a letter as an argument.\\n\", create_environment=<function get_environment at 0x7f8f5f01aa20>, instructions=\"Repeat the given string by using the provided tools. Do not write anything else or provide any explanations. For example, if the string is 'abc', you must invoke the tools 'a', 'b', and 'c' in that order. Please invoke the functions without any arguments.\")"
|
||||
"ToolUsageTask(name='Tool Usage - Typewriter (26 tools)', dataset_id='https://smith.langchain.com/public/128af05e-aa00-4e3b-a958-d166dd450581/d', description=\"Environment with 26 tools each tool represents a letter of the alphabet.\\n\\nThe objective of this task is to evaluate the model's ability the use tools\\nfor a simple repetition task.\\n\\nFor example, if the string is 'abc', the tools 'a', 'b', and 'c' must be invoked in that order.\\n\\nThe dataset includes examples of varying difficulty. The difficulty is measured by the length of the string.\\n\\nThis is a variation of the typer writer task, where 26 parameterless tools are\\ngiven instead of a single tool that takes a letter as an argument.\\n\", create_environment=<function get_environment at 0x7b3a9f5fb240>, instructions=\"Repeat the given string by using the provided tools. Do not write anything else or provide any explanations. For example, if the string is 'abc', you must invoke the tools 'a', 'b', and 'c' in that order. Please invoke the functions without any arguments.\", eval_params={'output_evaluation': 'none'})"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -302,7 +250,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"execution_count": 3,
|
||||
"id": "f201dbbe-7d92-4bc7-b4b5-ea8901dd2970",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -311,13 +259,13 @@
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[StructuredTool(name='a', description='a() -> str - Run to Type the letter \"a\".', args_schema=<class 'pydantic.v1.main.aSchemaSchema'>, func=<function _create_typing_func.<locals>.func at 0x7f8f5eba2980>),\n",
|
||||
" StructuredTool(name='b', description='b() -> str - Run to Type the letter \"b\".', args_schema=<class 'pydantic.v1.main.bSchemaSchema'>, func=<function _create_typing_func.<locals>.func at 0x7f8f5eba2a20>),\n",
|
||||
" StructuredTool(name='c', description='c() -> str - Run to Type the letter \"c\".', args_schema=<class 'pydantic.v1.main.cSchemaSchema'>, func=<function _create_typing_func.<locals>.func at 0x7f8f5eba2ac0>),\n",
|
||||
" StructuredTool(name='d', description='d() -> str - Run to Type the letter \"d\".', args_schema=<class 'pydantic.v1.main.dSchemaSchema'>, func=<function _create_typing_func.<locals>.func at 0x7f8f5eba2b60>)]"
|
||||
"[StructuredTool(name='a', description='a() -> str - Run to Type the letter \"a\".', args_schema=<class 'pydantic.v1.main.aSchema'>, func=<function _create_typing_func.<locals>.func at 0x7b3a9f62c9a0>),\n",
|
||||
" StructuredTool(name='b', description='b() -> str - Run to Type the letter \"b\".', args_schema=<class 'pydantic.v1.main.bSchema'>, func=<function _create_typing_func.<locals>.func at 0x7b3a9f62c5e0>),\n",
|
||||
" StructuredTool(name='c', description='c() -> str - Run to Type the letter \"c\".', args_schema=<class 'pydantic.v1.main.cSchema'>, func=<function _create_typing_func.<locals>.func at 0x7b3a9f62cae0>),\n",
|
||||
" StructuredTool(name='d', description='d() -> str - Run to Type the letter \"d\".', args_schema=<class 'pydantic.v1.main.dSchema'>, func=<function _create_typing_func.<locals>.func at 0x7b3a9f62cb80>)]"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -329,7 +277,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"execution_count": 4,
|
||||
"id": "b07957ee-ae52-47d4-a4ff-aa99d4d9bdaf",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -341,7 +289,7 @@
|
||||
"'OK'"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -354,7 +302,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"execution_count": 5,
|
||||
"id": "40fbb9b6-00f6-4445-b480-00eed6b5b3aa",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -366,7 +314,7 @@
|
||||
"'aac'"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -380,121 +328,86 @@
|
||||
"id": "8d39b9b3-d4da-49bc-b3db-8a4165b1db55",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Agent Factory\n",
|
||||
"## Create an Agent!\n",
|
||||
"\n",
|
||||
"For evaluation, we need an agent factory that will create a new instance of an agent executor for every evaluation run.\n",
|
||||
"Now that you know how the test environment works, let's create an agent that we can test!\n",
|
||||
"\n",
|
||||
"The `AgentExecutor` should accept `question` as an input and include the fields `output`, `intermediate_steps` and potentially `state` in its response -- for this we\n",
|
||||
"will wrap the agent executor in an adapter (`apply_agent_executor_adapter`) that will help match the expected schema.\n",
|
||||
"Because an agent interacts with the environment via tools and can change the state of the environment during the course of an agent run, what we actually want is the ability to create a fresh agent and a fresh environment for each test run.\n",
|
||||
"\n",
|
||||
"Please reference the LangChain documentation to see how to [use and implement agents](https://python.langchain.com/docs/modules/agents/)"
|
||||
"We'll do this using a factory. A factory is just a fancy name in computer science for an object that can create other objects. In this case, we'll have an Agent Factory that we can call and it'll create a fresh agent for us on each call.\n",
|
||||
"\n",
|
||||
"We'll use the StandardAgentFactory which under the hood creates a standard LangChain [tool calling agent](https://python.langchain.com/docs/modules/agents/agent_types/tool_calling/). It can be used with any [Chat Model that support tool calling](https://python.langchain.com/docs/integrations/chat/)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "bca8ad69-9956-451c-b639-ea30c77d982f",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"id": "db65c253-7710-4c7b-b968-0662ec089030",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.agents import AgentExecutor, AgentType, Tool, initialize_agent\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain_anthropic.chat_models import ChatAnthropic\n",
|
||||
"from langchain_core.prompts import ChatPromptTemplate\n",
|
||||
"\n",
|
||||
"from langchain_benchmarks.schema import ExtractionTask\n",
|
||||
"from langchain_benchmarks.tool_usage.agents import apply_agent_executor_adapter"
|
||||
"from langchain_benchmarks.tool_usage.agents import StandardAgentFactory\n",
|
||||
"\n",
|
||||
"model = ChatAnthropic(model=\"claude-3-opus-20240229\", temperature=0)\n",
|
||||
"prompt = ChatPromptTemplate.from_messages(\n",
|
||||
" [\n",
|
||||
" (\"system\", \"{instructions}\"), # Populated from task.instructions automatically\n",
|
||||
" (\n",
|
||||
" \"human\",\n",
|
||||
" \"{question}\",\n",
|
||||
" ), # Each evaluation example is associated with a question\n",
|
||||
" (\"placeholder\", \"{agent_scratchpad}\"), # Space for the agent to do work\n",
|
||||
" ]\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"agent_factory = StandardAgentFactory(task, model, prompt)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "44839ebe-48ea-4d5b-87b4-2ad72acacb71",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"cell_type": "markdown",
|
||||
"id": "5c99a9bd-fa3e-4401-9062-77dbcff30d5c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"class AgentFactory:\n",
|
||||
" def __init__(self, task: ExtractionTask, model: str) -> None:\n",
|
||||
" self.task = task\n",
|
||||
" self.model = model\n",
|
||||
"\n",
|
||||
" def __call__(self):\n",
|
||||
" # This factory creates a new environment for every agent run.\n",
|
||||
" # The reason is that the environment may be associated with an environment state (e.g., typewriter)\n",
|
||||
" # which is changed by the actions of the agent.\n",
|
||||
" # At the end of the run, the environment state will be read.\n",
|
||||
" env = task.create_environment() # Create a new environment for every agent run!\n",
|
||||
" tools = env.tools\n",
|
||||
" llm = ChatOpenAI(temperature=0, model=self.model)\n",
|
||||
" agent_executor = initialize_agent(\n",
|
||||
" tools,\n",
|
||||
" llm,\n",
|
||||
" agent=AgentType.OPENAI_FUNCTIONS,\n",
|
||||
" return_intermediate_steps=True,\n",
|
||||
" handle_parsing_errors=True,\n",
|
||||
" )\n",
|
||||
" # Apply the adapters so that inputs and outputs match dataset schema\n",
|
||||
" # state_reader automatically adds the state of the environment at the end of the run.\n",
|
||||
" return apply_agent_executor_adapter(agent_executor, state_reader=env.read_state)"
|
||||
"Here, were the instructions for the task"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "755f7920-831b-4595-8c6d-cca22c935198",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"id": "8e1f0a3d-fed6-41f7-8825-08787a57ad98",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"\"Repeat the given string by using the provided tools. Do not write anything else or provide any explanations. For example, if the string is 'abc', you must invoke the tools 'a', 'b', and 'c' in that order. Please invoke the functions without any arguments.\""
|
||||
]
|
||||
},
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain import globals\n",
|
||||
"\n",
|
||||
"globals.set_verbose(True)"
|
||||
"task.instructions"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "82c9de5d-185b-4776-9ee9-112a2db32139",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Let's test it out"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "1b18952b-43b8-4f30-a0d9-e7763eb05b13",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"agent_factory = AgentFactory(task, model=\"gpt-3.5-turbo-1106\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "c31a81e5-b3d6-42e5-895d-0c4dc8413738",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"Let's check that the agent works"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"id": "c2804eae-5b0b-4a38-9dff-363a4fe8f324",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"agent = agent_factory()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"id": "eb0bb2bf-5f53-4f59-a73f-2144fe850d50",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"id": "ce67d619-fa99-4c15-bc53-3fb08b40a201",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
@@ -505,42 +418,375 @@
|
||||
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
|
||||
"\u001b[32;1m\u001b[1;3m\n",
|
||||
"Invoking: `a` with `{}`\n",
|
||||
"\n",
|
||||
"responded: [{'text': '<thinking>\\nTo repeat the string \"abc\", I need to call the a(), b(), and c() functions in that order. No parameters are required for these functions.\\n</thinking>', 'type': 'text'}, {'id': 'toolu_01MQ6oTx2j2uNGCR5LBVeKui', 'input': {}, 'name': 'a', 'type': 'tool_use'}, {'id': 'toolu_01AytT1jvNNR67VodMkhbq7r', 'input': {}, 'name': 'b', 'type': 'tool_use'}, {'id': 'toolu_015VkTYUV5hWcobtduqssi9k', 'input': {}, 'name': 'c', 'type': 'tool_use'}]\n",
|
||||
"\n",
|
||||
"\u001b[0m\u001b[36;1m\u001b[1;3mOK\u001b[0m\u001b[32;1m\u001b[1;3m\n",
|
||||
"Invoking: `b` with `{}`\n",
|
||||
"\n",
|
||||
"responded: [{'text': '<thinking>\\nTo repeat the string \"abc\", I need to call the a(), b(), and c() functions in that order. No parameters are required for these functions.\\n</thinking>', 'type': 'text'}, {'id': 'toolu_01MQ6oTx2j2uNGCR5LBVeKui', 'input': {}, 'name': 'a', 'type': 'tool_use'}, {'id': 'toolu_01AytT1jvNNR67VodMkhbq7r', 'input': {}, 'name': 'b', 'type': 'tool_use'}, {'id': 'toolu_015VkTYUV5hWcobtduqssi9k', 'input': {}, 'name': 'c', 'type': 'tool_use'}]\n",
|
||||
"\n",
|
||||
"\u001b[0m\u001b[33;1m\u001b[1;3mOK\u001b[0m\u001b[32;1m\u001b[1;3m\n",
|
||||
"Invoking: `c` with `{}`\n",
|
||||
"responded: [{'text': '<thinking>\\nTo repeat the string \"abc\", I need to call the a(), b(), and c() functions in that order. No parameters are required for these functions.\\n</thinking>', 'type': 'text'}, {'id': 'toolu_01MQ6oTx2j2uNGCR5LBVeKui', 'input': {}, 'name': 'a', 'type': 'tool_use'}, {'id': 'toolu_01AytT1jvNNR67VodMkhbq7r', 'input': {}, 'name': 'b', 'type': 'tool_use'}, {'id': 'toolu_015VkTYUV5hWcobtduqssi9k', 'input': {}, 'name': 'c', 'type': 'tool_use'}]\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[0m\u001b[38;5;200m\u001b[1;3mOK\u001b[0m\u001b[32;1m\u001b[1;3mYou've successfully typed \"abc\"! Is there anything else you'd like to do?\u001b[0m\n",
|
||||
"\u001b[0m\u001b[38;5;200m\u001b[1;3mOK\u001b[0m\u001b[32;1m\u001b[1;3m[]\u001b[0m\n",
|
||||
"\n",
|
||||
"\u001b[1m> Finished chain.\u001b[0m\n"
|
||||
]
|
||||
},
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain import globals\n",
|
||||
"\n",
|
||||
"globals.set_verbose(True)\n",
|
||||
"agent = agent_factory()\n",
|
||||
"agent.invoke({\"question\": \"abc\"})\n",
|
||||
"globals.set_verbose(False)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e3bce984-7c9c-4f6e-a51b-01c3e2b6e00a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Benchmarking\n",
|
||||
"\n",
|
||||
"How does one evaluate an agent? Given a particular task and input, an agent uses tools to produce an output AND/OR change the state of the environment.\n",
|
||||
"\n",
|
||||
"To evaluate an agent, we can check the following:\n",
|
||||
"\n",
|
||||
"1. Did the agent use the expected tools?\n",
|
||||
"2. Did the agent use the tools in the most effective way; e.g., was the order of tool invocation correct?\n",
|
||||
"3. Did the environment end up in the correct final state after the agent used the tools? (e.g., does my calendar contain all the scheduled meetings?)\n",
|
||||
"4. Did the agent output match the expected reference output?\n",
|
||||
"\n",
|
||||
"Each task is associated with a standard evaluator that does evaluation that's appropriate for the task; for example,\n",
|
||||
"\n",
|
||||
"1. Use an LLM to grade Compare output to reference using an LLM that grades the response.\n",
|
||||
"2. Compare equality of expected_steps to the list of tools in intermediate_steps -- simple list equality\n",
|
||||
"3. Compare the state of the environment against expected state (if present in the dataset and in the agent)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "5e9e5817-3b9d-4a1e-8ee8-692d39aa68ca",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Each task is associated with its own task specific evaluator!"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"id": "c88bd6e1-f77e-4668-a143-096929e897ee",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'input': 'abc',\n",
|
||||
" 'output': 'You\\'ve successfully typed \"abc\"! Is there anything else you\\'d like to do?',\n",
|
||||
" 'intermediate_steps': [(AgentActionMessageLog(tool='a', tool_input={}, log='\\nInvoking: `a` with `{}`\\n\\n\\n', message_log=[AIMessage(content='', additional_kwargs={'function_call': {'arguments': '{}', 'name': 'a'}})]),\n",
|
||||
" 'OK'),\n",
|
||||
" (AgentActionMessageLog(tool='b', tool_input={}, log='\\nInvoking: `b` with `{}`\\n\\n\\n', message_log=[AIMessage(content='', additional_kwargs={'function_call': {'arguments': '{}', 'name': 'b'}})]),\n",
|
||||
" 'OK'),\n",
|
||||
" (AgentActionMessageLog(tool='c', tool_input={}, log='\\nInvoking: `c` with `{}`\\n\\n\\n', message_log=[AIMessage(content='', additional_kwargs={'function_call': {'arguments': '{}', 'name': 'c'}})]),\n",
|
||||
" 'OK')],\n",
|
||||
" 'state': 'abc'}"
|
||||
"RunEvalConfig(evaluators=[], custom_evaluators=[<langchain_benchmarks.tool_usage.evaluators.AgentTrajectoryEvaluator object at 0x7b3a9ea5b110>], batch_evaluators=None, reference_key=None, prediction_key=None, input_key=None, eval_llm=None)"
|
||||
]
|
||||
},
|
||||
"execution_count": 12,
|
||||
"execution_count": 11,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"agent.invoke({\"input\": \"abc\"})"
|
||||
"eval_config = task.get_eval_config()\n",
|
||||
"eval_config"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "044c7f91-9bb3-44b5-802d-f9f444ddeff9",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Set up code to run against all tasks"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"id": "0770b442-f96a-4670-a4f7-3093f24fb64b",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import datetime\n",
|
||||
"import uuid\n",
|
||||
"\n",
|
||||
"from langsmith.client import Client\n",
|
||||
"\n",
|
||||
"from langchain_benchmarks import (\n",
|
||||
" __version__,\n",
|
||||
" clone_public_dataset,\n",
|
||||
" model_registry,\n",
|
||||
" registry,\n",
|
||||
")\n",
|
||||
"from langchain_benchmarks.rate_limiting import RateLimiter"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "15cbded4-5ab5-4b9b-9e88-77b24d3b750c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Create an experiment ID. we'll use it to tag our runs, which we can later use to retrieve run data from LangSmith."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"id": "c23208e3-01d1-4e83-9e4a-59544828f6f5",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"experiment_id = uuid.uuid4().hex[:]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "83050cfc-f50f-4c63-8257-07e7688a54c4",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Run evaluation against all tasks."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "b2a3463b-1c9f-494b-bcbd-1dc1760ebf19",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"client = Client() # Launch langsmith client for cloning datasets\n",
|
||||
"today = datetime.date.today().isoformat()\n",
|
||||
"\n",
|
||||
"# You can use an optional rate limiter to rate limit your requests!\n",
|
||||
"rate_limiter = RateLimiter(requests_per_second=1)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# Set up 2-tuples of (model name, model instance)\n",
|
||||
"# You can update this list with any model that supports tool calling.\n",
|
||||
"# See list here: https://python.langchain.com/docs/integrations/chat/\n",
|
||||
"tests = [\n",
|
||||
" (\n",
|
||||
" \"claude-3-haiku-20240307\",\n",
|
||||
" ChatAnthropic(model=\"claude-3-haiku-20240307\", temperature=0),\n",
|
||||
" )\n",
|
||||
"]\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"for task in registry.tasks:\n",
|
||||
" if task.type != \"ToolUsageTask\":\n",
|
||||
" continue\n",
|
||||
"\n",
|
||||
" dataset_name = task.name + f\" ({today})\"\n",
|
||||
" clone_public_dataset(task.dataset_id, dataset_name=dataset_name)\n",
|
||||
"\n",
|
||||
" for model_name, model in tests:\n",
|
||||
" print()\n",
|
||||
" print(f\"Benchmarking {task.name} with model: {model_name}\")\n",
|
||||
" eval_config = task.get_eval_config()\n",
|
||||
"\n",
|
||||
" agent_factory = StandardAgentFactory(\n",
|
||||
" task, model, prompt, rate_limiter=rate_limiter\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
" client.run_on_dataset(\n",
|
||||
" dataset_name=dataset_name,\n",
|
||||
" llm_or_chain_factory=agent_factory,\n",
|
||||
" evaluation=eval_config,\n",
|
||||
" verbose=False,\n",
|
||||
" project_name=f\"{model_name}-{task.name}-{today}-{experiment_id}\",\n",
|
||||
" concurrency_level=5,\n",
|
||||
" project_metadata={\n",
|
||||
" \"model\": model_name,\n",
|
||||
" \"id\": experiment_uuid,\n",
|
||||
" \"task\": task.name,\n",
|
||||
" \"date\": today,\n",
|
||||
" \"langchain_benchmarks_version\": __version__,\n",
|
||||
" },\n",
|
||||
" )"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4c0a6505-693d-46e5-9ed1-e33e0044b040",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Advanced Usage\n",
|
||||
"\n",
|
||||
"The following sections demonstrate slightly more \"advanced\" usage if you want to completely customize the agent runtime in a way that is compatible with our test runner.\n",
|
||||
"\n",
|
||||
"We'll also apply an adapter to the agent which will will capture its inputs and outputs (e.g, add information the agent's environment at the end of the run) so that it we can evaluate it.\n",
|
||||
"\n",
|
||||
"### Custom Agent Factory\n",
|
||||
"\n",
|
||||
"If you want even more configurability beyond what the `CustomRunnableAgentFactory` provides, you can create your owne `AgentFactory` using the following pattern.\n",
|
||||
"\n",
|
||||
"The `AgentExecutor` should accept `question` as an input and include the fields `output`, `intermediate_steps` and potentially `state` in its response -- for this we\n",
|
||||
"will wrap the agent executor in an adapter (`apply_agent_executor_adapter`) that will help match the expected schema."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"id": "69351864-2e97-43df-81ae-5067cbf5e471",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from typing import Optional\n",
|
||||
"\n",
|
||||
"from langchain.agents import AgentExecutor, create_tool_calling_agent\n",
|
||||
"from langchain_anthropic import ChatAnthropic\n",
|
||||
"from langchain_core.prompts import ChatPromptTemplate\n",
|
||||
"\n",
|
||||
"from langchain_benchmarks.schema import ExtractionTask\n",
|
||||
"from langchain_benchmarks.tool_usage.agents import apply_agent_executor_adapter\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"class CustomAgentFactory:\n",
|
||||
" def __init__(\n",
|
||||
" self,\n",
|
||||
" task: ExtractionTask,\n",
|
||||
" *,\n",
|
||||
" # It can be useful to add a rate-limiter\n",
|
||||
" # which will limit ther number of requests per second\n",
|
||||
" # when running evaluation.\n",
|
||||
" rate_limiter: Optional[RateLimiter] = None,\n",
|
||||
" ) -> None:\n",
|
||||
" self.task = task\n",
|
||||
" self.rate_limiter = rate_limiter\n",
|
||||
"\n",
|
||||
" def __call__(self):\n",
|
||||
" # This factory creates a new environment for every agent run.\n",
|
||||
" # The reason is that the environment may be associated with an environment state (e.g., typewriter)\n",
|
||||
" # which is changed by the actions of the agent.\n",
|
||||
" # At the end of the run, the environment state will be read.\n",
|
||||
" env = task.create_environment() # Create a new environment for every agent run!\n",
|
||||
" tools = env.tools\n",
|
||||
" model = ChatAnthropic(model=\"claude-3-opus-20240229\", temperature=0)\n",
|
||||
" prompt = ChatPromptTemplate.from_messages(\n",
|
||||
" [\n",
|
||||
" (\"system\", self.task.instructions),\n",
|
||||
" (\n",
|
||||
" \"human\",\n",
|
||||
" \"{question}\",\n",
|
||||
" ), # Populated from task.instructions automatically\n",
|
||||
" (\"placeholder\", \"{agent_scratchpad}\"),\n",
|
||||
" ]\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
" # This is the standard tool calling agent implementation\n",
|
||||
" # Feel free to replace it with any other implementation you want!\n",
|
||||
" # https://python.langchain.com/docs/modules/agents/how_to/custom_agent/\n",
|
||||
" agent = create_tool_calling_agent(model, env.tools, prompt)\n",
|
||||
"\n",
|
||||
" if self.rate_limiter:\n",
|
||||
" agent = with_rate_limit(agent, self.rate_limiter)\n",
|
||||
"\n",
|
||||
" executor = AgentExecutor(\n",
|
||||
" agent=agent,\n",
|
||||
" tools=env.tools,\n",
|
||||
" handle_parsing_errors=True,\n",
|
||||
" return_intermediate_steps=True,\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
" # Apply the adapters so that inputs and outputs match dataset schema\n",
|
||||
" # state_reader automatically adds the state of the environment at the end of the run.\n",
|
||||
" return apply_agent_executor_adapter(executor, state_reader=env.read_state)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"id": "18a96a6f-812b-4b0e-83c5-d001bf50851e",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/html": [
|
||||
"<table>\n",
|
||||
"<tbody>\n",
|
||||
"<tr><td>Name </td><td>Tool Usage - Typewriter (26 tools) </td></tr>\n",
|
||||
"<tr><td>Type </td><td>ToolUsageTask </td></tr>\n",
|
||||
"<tr><td>Dataset ID </td><td><a href=\"https://smith.langchain.com/public/128af05e-aa00-4e3b-a958-d166dd450581/d\" target=\"_blank\" rel=\"noopener\">128af05e-aa00-4e3b-a958-d166dd450581</a></td></tr>\n",
|
||||
"<tr><td>Description</td><td>Environment with 26 tools each tool represents a letter of the alphabet.\n",
|
||||
"\n",
|
||||
"The objective of this task is to evaluate the model's ability the use tools\n",
|
||||
"for a simple repetition task.\n",
|
||||
"\n",
|
||||
"For example, if the string is 'abc', the tools 'a', 'b', and 'c' must be invoked in that order.\n",
|
||||
"\n",
|
||||
"The dataset includes examples of varying difficulty. The difficulty is measured by the length of the string.\n",
|
||||
"\n",
|
||||
"This is a variation of the typer writer task, where 26 parameterless tools are\n",
|
||||
"given instead of a single tool that takes a letter as an argument. </td></tr>\n",
|
||||
"</tbody>\n",
|
||||
"</table>"
|
||||
],
|
||||
"text/plain": [
|
||||
"ToolUsageTask(name='Tool Usage - Typewriter (26 tools)', dataset_id='https://smith.langchain.com/public/128af05e-aa00-4e3b-a958-d166dd450581/d', description=\"Environment with 26 tools each tool represents a letter of the alphabet.\\n\\nThe objective of this task is to evaluate the model's ability the use tools\\nfor a simple repetition task.\\n\\nFor example, if the string is 'abc', the tools 'a', 'b', and 'c' must be invoked in that order.\\n\\nThe dataset includes examples of varying difficulty. The difficulty is measured by the length of the string.\\n\\nThis is a variation of the typer writer task, where 26 parameterless tools are\\ngiven instead of a single tool that takes a letter as an argument.\\n\", create_environment=<function get_environment at 0x78972c6c3060>, instructions=\"Repeat the given string by using the provided tools. Do not write anything else or provide any explanations. For example, if the string is 'abc', you must invoke the tools 'a', 'b', and 'c' in that order. Please invoke the functions without any arguments.\", eval_params={'output_evaluation': 'none'})"
|
||||
]
|
||||
},
|
||||
"execution_count": 17,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"task"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"id": "a7bd4af3-c0f1-4308-abbf-330d7497b3e3",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"custom_agent_factory = CustomAgentFactory(task)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"id": "c5b69b7c-4294-47d1-85d7-47d718945898",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"agent = custom_agent_factory()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 20,
|
||||
"id": "1ac24ef5-d3ca-41aa-b888-7ebcd8a92ff4",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'question': 'abc',\n",
|
||||
" 'output': [],\n",
|
||||
" 'intermediate_steps': [(ToolAgentAction(tool='a', tool_input={}, log='\\nInvoking: `a` with `{}`\\nresponded: [{\\'text\\': \\'<thinking>\\\\nTo repeat the string \"abc\", I need to call the a(), b(), and c() functions in that order. No parameters are required for these functions.\\\\n</thinking>\\', \\'type\\': \\'text\\'}, {\\'id\\': \\'toolu_016f6CZwwFmdz2h8KbdGRVjj\\', \\'input\\': {}, \\'name\\': \\'a\\', \\'type\\': \\'tool_use\\'}, {\\'id\\': \\'toolu_01JvfeTpU3hEuS7PknFk5a8S\\', \\'input\\': {}, \\'name\\': \\'b\\', \\'type\\': \\'tool_use\\'}, {\\'id\\': \\'toolu_01NbBCY5Fg62RsyAAUd4n2g1\\', \\'input\\': {}, \\'name\\': \\'c\\', \\'type\\': \\'tool_use\\'}]\\n\\n', message_log=[AIMessageChunk(content=[{'text': '<thinking>\\nTo repeat the string \"abc\", I need to call the a(), b(), and c() functions in that order. No parameters are required for these functions.\\n</thinking>', 'type': 'text'}, {'id': 'toolu_016f6CZwwFmdz2h8KbdGRVjj', 'input': {}, 'name': 'a', 'type': 'tool_use'}, {'id': 'toolu_01JvfeTpU3hEuS7PknFk5a8S', 'input': {}, 'name': 'b', 'type': 'tool_use'}, {'id': 'toolu_01NbBCY5Fg62RsyAAUd4n2g1', 'input': {}, 'name': 'c', 'type': 'tool_use'}], id='run-42ea263e-e52a-4fc7-8aa3-71e16a9db42b', tool_calls=[{'name': 'a', 'args': {}, 'id': 'toolu_016f6CZwwFmdz2h8KbdGRVjj'}, {'name': 'b', 'args': {}, 'id': 'toolu_01JvfeTpU3hEuS7PknFk5a8S'}, {'name': 'c', 'args': {}, 'id': 'toolu_01NbBCY5Fg62RsyAAUd4n2g1'}], tool_call_chunks=[{'name': 'a', 'args': '{}', 'id': 'toolu_016f6CZwwFmdz2h8KbdGRVjj', 'index': 0}, {'name': 'b', 'args': '{}', 'id': 'toolu_01JvfeTpU3hEuS7PknFk5a8S', 'index': 1}, {'name': 'c', 'args': '{}', 'id': 'toolu_01NbBCY5Fg62RsyAAUd4n2g1', 'index': 2}])], tool_call_id='toolu_016f6CZwwFmdz2h8KbdGRVjj'),\n",
|
||||
" 'OK'),\n",
|
||||
" (ToolAgentAction(tool='b', tool_input={}, log='\\nInvoking: `b` with `{}`\\nresponded: [{\\'text\\': \\'<thinking>\\\\nTo repeat the string \"abc\", I need to call the a(), b(), and c() functions in that order. No parameters are required for these functions.\\\\n</thinking>\\', \\'type\\': \\'text\\'}, {\\'id\\': \\'toolu_016f6CZwwFmdz2h8KbdGRVjj\\', \\'input\\': {}, \\'name\\': \\'a\\', \\'type\\': \\'tool_use\\'}, {\\'id\\': \\'toolu_01JvfeTpU3hEuS7PknFk5a8S\\', \\'input\\': {}, \\'name\\': \\'b\\', \\'type\\': \\'tool_use\\'}, {\\'id\\': \\'toolu_01NbBCY5Fg62RsyAAUd4n2g1\\', \\'input\\': {}, \\'name\\': \\'c\\', \\'type\\': \\'tool_use\\'}]\\n\\n', message_log=[AIMessageChunk(content=[{'text': '<thinking>\\nTo repeat the string \"abc\", I need to call the a(), b(), and c() functions in that order. No parameters are required for these functions.\\n</thinking>', 'type': 'text'}, {'id': 'toolu_016f6CZwwFmdz2h8KbdGRVjj', 'input': {}, 'name': 'a', 'type': 'tool_use'}, {'id': 'toolu_01JvfeTpU3hEuS7PknFk5a8S', 'input': {}, 'name': 'b', 'type': 'tool_use'}, {'id': 'toolu_01NbBCY5Fg62RsyAAUd4n2g1', 'input': {}, 'name': 'c', 'type': 'tool_use'}], id='run-42ea263e-e52a-4fc7-8aa3-71e16a9db42b', tool_calls=[{'name': 'a', 'args': {}, 'id': 'toolu_016f6CZwwFmdz2h8KbdGRVjj'}, {'name': 'b', 'args': {}, 'id': 'toolu_01JvfeTpU3hEuS7PknFk5a8S'}, {'name': 'c', 'args': {}, 'id': 'toolu_01NbBCY5Fg62RsyAAUd4n2g1'}], tool_call_chunks=[{'name': 'a', 'args': '{}', 'id': 'toolu_016f6CZwwFmdz2h8KbdGRVjj', 'index': 0}, {'name': 'b', 'args': '{}', 'id': 'toolu_01JvfeTpU3hEuS7PknFk5a8S', 'index': 1}, {'name': 'c', 'args': '{}', 'id': 'toolu_01NbBCY5Fg62RsyAAUd4n2g1', 'index': 2}])], tool_call_id='toolu_01JvfeTpU3hEuS7PknFk5a8S'),\n",
|
||||
" 'OK'),\n",
|
||||
" (ToolAgentAction(tool='c', tool_input={}, log='\\nInvoking: `c` with `{}`\\nresponded: [{\\'text\\': \\'<thinking>\\\\nTo repeat the string \"abc\", I need to call the a(), b(), and c() functions in that order. No parameters are required for these functions.\\\\n</thinking>\\', \\'type\\': \\'text\\'}, {\\'id\\': \\'toolu_016f6CZwwFmdz2h8KbdGRVjj\\', \\'input\\': {}, \\'name\\': \\'a\\', \\'type\\': \\'tool_use\\'}, {\\'id\\': \\'toolu_01JvfeTpU3hEuS7PknFk5a8S\\', \\'input\\': {}, \\'name\\': \\'b\\', \\'type\\': \\'tool_use\\'}, {\\'id\\': \\'toolu_01NbBCY5Fg62RsyAAUd4n2g1\\', \\'input\\': {}, \\'name\\': \\'c\\', \\'type\\': \\'tool_use\\'}]\\n\\n', message_log=[AIMessageChunk(content=[{'text': '<thinking>\\nTo repeat the string \"abc\", I need to call the a(), b(), and c() functions in that order. No parameters are required for these functions.\\n</thinking>', 'type': 'text'}, {'id': 'toolu_016f6CZwwFmdz2h8KbdGRVjj', 'input': {}, 'name': 'a', 'type': 'tool_use'}, {'id': 'toolu_01JvfeTpU3hEuS7PknFk5a8S', 'input': {}, 'name': 'b', 'type': 'tool_use'}, {'id': 'toolu_01NbBCY5Fg62RsyAAUd4n2g1', 'input': {}, 'name': 'c', 'type': 'tool_use'}], id='run-42ea263e-e52a-4fc7-8aa3-71e16a9db42b', tool_calls=[{'name': 'a', 'args': {}, 'id': 'toolu_016f6CZwwFmdz2h8KbdGRVjj'}, {'name': 'b', 'args': {}, 'id': 'toolu_01JvfeTpU3hEuS7PknFk5a8S'}, {'name': 'c', 'args': {}, 'id': 'toolu_01NbBCY5Fg62RsyAAUd4n2g1'}], tool_call_chunks=[{'name': 'a', 'args': '{}', 'id': 'toolu_016f6CZwwFmdz2h8KbdGRVjj', 'index': 0}, {'name': 'b', 'args': '{}', 'id': 'toolu_01JvfeTpU3hEuS7PknFk5a8S', 'index': 1}, {'name': 'c', 'args': '{}', 'id': 'toolu_01NbBCY5Fg62RsyAAUd4n2g1', 'index': 2}])], tool_call_id='toolu_01NbBCY5Fg62RsyAAUd4n2g1'),\n",
|
||||
" 'OK')],\n",
|
||||
" 'state': 'abc'}"
|
||||
]
|
||||
},
|
||||
"execution_count": 20,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"agent.invoke({\"question\": \"abc\"})"
|
||||
]
|
||||
}
|
||||
],
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
File diff suppressed because one or more lines are too long
@@ -66,22 +66,16 @@
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import json\n",
|
||||
"from copy import deepcopy\n",
|
||||
"from functools import partial\n",
|
||||
"from typing import Sequence, Tuple\n",
|
||||
"\n",
|
||||
"from langchain.agents import AgentExecutor, AgentType, Tool, initialize_agent\n",
|
||||
"from langchain.agents.format_scratchpad import format_to_openai_function_messages\n",
|
||||
"from langchain.agents import AgentExecutor\n",
|
||||
"from langchain.agents.structured_chat.output_parser import (\n",
|
||||
" AgentAction,\n",
|
||||
" AgentFinish,\n",
|
||||
" StructuredChatOutputParser,\n",
|
||||
")\n",
|
||||
"from langchain.chains.openai_functions.base import convert_to_openai_function\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.output_parsers.json import SimpleJsonOutputParser, parse_json_markdown\n",
|
||||
"from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder\n",
|
||||
"from langchain.schema.output_parser import StrOutputParser\n",
|
||||
"from langchain.output_parsers.json import parse_json_markdown\n",
|
||||
"from langchain.prompts import ChatPromptTemplate\n",
|
||||
"from langchain.tools import tool\n",
|
||||
"from langchain_core.runnables import RunnableLambda\n",
|
||||
"\n",
|
||||
@@ -353,8 +347,6 @@
|
||||
"\n",
|
||||
"from langsmith.client import Client\n",
|
||||
"\n",
|
||||
"from langchain_benchmarks.tool_usage import get_eval_config\n",
|
||||
"\n",
|
||||
"experiment_uuid = uuid.uuid4().hex[:4]\n",
|
||||
"\n",
|
||||
"client = Client()\n",
|
||||
|
||||
File diff suppressed because one or more lines are too long
@@ -53,7 +53,7 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_benchmarks import clone_public_dataset, registry"
|
||||
"from langchain_benchmarks import registry"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -76,35 +76,6 @@
|
||||
"task = registry[\"Tool Usage - Relational Data\"]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "bc33a639-3caf-4314-8ea7-1c7c8b1d114d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Clone the dataset associaetd with this task"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "70369f67-deb4-467a-801a-6d38c3d0460d",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Dataset Tool Usage - Relational Data already exists. Skipping.\n",
|
||||
"You can access the dataset at https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/datasets/df6be6c9-05b3-445e-8836-ebb4aba63826.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"clone_public_dataset(task.dataset_id, dataset_name=task.name)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "110bdafa-bdab-4194-90c9-46416d14b2f9",
|
||||
@@ -117,7 +88,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"execution_count": 3,
|
||||
"id": "27b6b0fd-639d-43a7-a730-9acdc5b2f102",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -126,14 +97,14 @@
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[StructuredTool(name='get_user_name', description=\"get_user_name(user_id: int) -> str - Get the name of the user with the given user ID.\\n\\n Args:\\n user_id: The user's ID.\\n\\n Returns:\\n The user's name.\", args_schema=<class 'pydantic.v1.main.get_user_nameSchemaSchema'>, handle_tool_error=True, func=<function get_available_functions.<locals>.get_user_name at 0x7fbb0e864f40>),\n",
|
||||
" StructuredTool(name='list_user_ids', description='list_user_ids() -> List[str] - List all the user IDs.', args_schema=<class 'pydantic.v1.main.list_user_idsSchemaSchema'>, handle_tool_error=True, func=<function get_available_functions.<locals>.list_user_ids at 0x7fbb0e864fe0>),\n",
|
||||
" StructuredTool(name='find_users_by_name', description='find_users_by_name(name: str) -> List[langchain_benchmarks.tool_usage.tasks.relational_data.SearchHit] - Find users with the given name.\\n\\n Args:\\n name: The name to search for.\\n\\n Returns:\\n The list of matching users.', args_schema=<class 'pydantic.v1.main.find_users_by_nameSchemaSchema'>, handle_tool_error=True, func=<function get_available_functions.<locals>.find_users_by_name at 0x7fbb0e865080>),\n",
|
||||
" StructuredTool(name='find_locations_by_name', description='find_locations_by_name(city: str) -> List[langchain_benchmarks.tool_usage.tasks.relational_data.SearchHit] - Find locations with the given city name.', args_schema=<class 'pydantic.v1.main.find_locations_by_nameSchemaSchema'>, handle_tool_error=True, func=<function get_available_functions.<locals>.find_locations_by_name at 0x7fbb0e865120>),\n",
|
||||
" StructuredTool(name='find_foods_by_name', description='find_foods_by_name(food: str) -> List[langchain_benchmarks.tool_usage.tasks.relational_data.SearchHit] - Find foods with the given name.', args_schema=<class 'pydantic.v1.main.find_foods_by_nameSchemaSchema'>, handle_tool_error=True, func=<function get_available_functions.<locals>.find_foods_by_name at 0x7fbb0e8651c0>)]"
|
||||
"[StructuredTool(name='get_user_name', description=\"get_user_name(user_id: int) -> str - Get the name of the user with the given user ID.\\n\\n Args:\\n user_id: The user's ID.\\n\\n Returns:\\n The user's name.\", args_schema=<class 'pydantic.v1.main.get_user_nameSchema'>, handle_tool_error=True, func=<function get_available_functions.<locals>.get_user_name at 0x78f30602fec0>),\n",
|
||||
" StructuredTool(name='list_user_ids', description='list_user_ids() -> List[str] - List all the user IDs.', args_schema=<class 'pydantic.v1.main.list_user_idsSchema'>, handle_tool_error=True, func=<function get_available_functions.<locals>.list_user_ids at 0x78f30602fe20>),\n",
|
||||
" StructuredTool(name='find_users_by_name', description='find_users_by_name(name: str) -> List[langchain_benchmarks.tool_usage.tasks.relational_data.SearchHit] - Find users with the given name.\\n\\n Args:\\n name: The name to search for.\\n\\n Returns:\\n The list of matching users.', args_schema=<class 'pydantic.v1.main.find_users_by_nameSchema'>, handle_tool_error=True, func=<function get_available_functions.<locals>.find_users_by_name at 0x78f306058040>),\n",
|
||||
" StructuredTool(name='find_locations_by_name', description='find_locations_by_name(city: str) -> List[langchain_benchmarks.tool_usage.tasks.relational_data.SearchHit] - Find locations with the given city name.', args_schema=<class 'pydantic.v1.main.find_locations_by_nameSchema'>, handle_tool_error=True, func=<function get_available_functions.<locals>.find_locations_by_name at 0x78f3060580e0>),\n",
|
||||
" StructuredTool(name='find_foods_by_name', description='find_foods_by_name(food: str) -> List[langchain_benchmarks.tool_usage.tasks.relational_data.SearchHit] - Find foods with the given name.', args_schema=<class 'pydantic.v1.main.find_foods_by_nameSchema'>, handle_tool_error=True, func=<function get_available_functions.<locals>.find_foods_by_name at 0x78f306058180>)]"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -145,7 +116,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"execution_count": 4,
|
||||
"id": "7f1c1242-449c-4536-863d-b62bf6d2dff1",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -157,7 +128,7 @@
|
||||
"'Bob'"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -168,7 +139,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"execution_count": 5,
|
||||
"id": "854e139b-a120-4012-bdf4-6394e0b1c42d",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -184,7 +155,7 @@
|
||||
" {'id': 5, 'city': 'Miami'}]"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -198,105 +169,46 @@
|
||||
"id": "b462f7b8-fd42-4613-ab5f-5f3cbbc37d28",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Agent Factory\n",
|
||||
"## Explore the task\n",
|
||||
"\n",
|
||||
"For evaluation, we need an agent factory that will create a new instance of an agent executor for every evaluation run.\n",
|
||||
"\n",
|
||||
"The `AgentExecutor` should accept `question` as an input and include the fields `output`, `intermediate_steps` and potentially `state` in its response -- for this we\n",
|
||||
"will wrap the agent executor in an adapter (`apply_agent_executor_adapter`) that will help match the expected schema.\n",
|
||||
"\n",
|
||||
"Please reference the LangChain documentation to see how to [use and implement agents](https://python.langchain.com/docs/modules/agents/)"
|
||||
"We'll use the `StandardAgentFactory` -- look at the `intro` for more information about what it does and/or how to create a custom one."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "1c2d80d2-4ddf-4b80-b6c5-331133a85314",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.agents import AgentType, Tool, initialize_agent\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"\n",
|
||||
"from langchain_benchmarks.schema import ExtractionTask\n",
|
||||
"from langchain_benchmarks.tool_usage.agents import apply_agent_executor_adapter"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"execution_count": 10,
|
||||
"id": "81c0e4a1-f56e-4117-8804-4161c642b068",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"class AgentFactory:\n",
|
||||
" def __init__(self, task: ExtractionTask, model: str) -> None:\n",
|
||||
" self.task = task\n",
|
||||
" self.model = model\n",
|
||||
"from langchain_core.prompts import ChatPromptTemplate\n",
|
||||
"from langchain_openai.chat_models import ChatOpenAI\n",
|
||||
"\n",
|
||||
" def __call__(self):\n",
|
||||
" # This factory creates a new environment for every agent run.\n",
|
||||
" # The reason is that the environment may be associated with an environment state (e.g., typewriter)\n",
|
||||
" # which is changed by the actions of the agent.\n",
|
||||
" # At the end of the run, the environment state will be read.\n",
|
||||
" env = task.create_environment() # Create a new environment for every agent run!\n",
|
||||
" tools = env.tools\n",
|
||||
" llm = ChatOpenAI(temperature=0, model=self.model)\n",
|
||||
" agent_executor = initialize_agent(\n",
|
||||
" tools,\n",
|
||||
" llm,\n",
|
||||
" agent=AgentType.OPENAI_FUNCTIONS,\n",
|
||||
" return_intermediate_steps=True,\n",
|
||||
" handle_parsing_errors=True,\n",
|
||||
" )\n",
|
||||
" # Apply the adapters so that inputs and outputs match dataset schema\n",
|
||||
" # state_reader automatically adds the state of the environment at the end of the run.\n",
|
||||
" return apply_agent_executor_adapter(agent_executor, state_reader=env.read_state)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "0ae8c6be-899c-44a6-a89b-0fc04c2cb05c",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"models = [\"gpt-3.5-turbo-1106\", \"gpt-3.5-turbo-0613\", \"gpt-4-32k-0613\"]\n",
|
||||
"agent_factory = AgentFactory(task, models[0])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "87a64f76-65ae-4367-b43f-f2be3431e7af",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Let's test that our agent works"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "127a8aa5-839c-469c-a870-7b498f37c187",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain import globals\n",
|
||||
"from langchain_benchmarks.tool_usage.agents import StandardAgentFactory\n",
|
||||
"\n",
|
||||
"globals.set_verbose(True)"
|
||||
"model = ChatOpenAI(temperature=0)\n",
|
||||
"prompt = ChatPromptTemplate.from_messages(\n",
|
||||
" [\n",
|
||||
" (\"system\", \"{instructions}\"), # Populated from task.instructions automatically\n",
|
||||
" (\"human\", \"{question}\"), # Populated from the test data\n",
|
||||
" (\n",
|
||||
" \"placeholder\",\n",
|
||||
" \"{agent_scratchpad}\",\n",
|
||||
" ), # Work where the agent can do its work (e.g., call multiple tools)\n",
|
||||
" ]\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"agent_factory = StandardAgentFactory(task, model, prompt)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"id": "0e4896fa-3633-44a1-857f-80a263cf2e03",
|
||||
"id": "382ff2f6-8099-415e-a58c-e659345f52fc",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
@@ -309,11 +221,11 @@
|
||||
"\n",
|
||||
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
|
||||
"\u001b[32;1m\u001b[1;3m\n",
|
||||
"Invoking: `find_locations_by_name` with `{'city': 'Los Angeles'}`\n",
|
||||
"Invoking: `find_locations_by_name` with `{'city': 'LA'}`\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[0m\u001b[36;1m\u001b[1;3m[{'id': 2, 'city': 'Los Angeles'}, {'id': 4, 'city': 'Houston'}, {'id': 1, 'city': 'New York'}, {'id': 3, 'city': 'Chicago'}, {'id': 5, 'city': 'Miami'}]\u001b[0m\u001b[32;1m\u001b[1;3m\n",
|
||||
"Invoking: `get_weather_at_location` with `{'location_id': 2}`\n",
|
||||
"\u001b[0m\u001b[36;1m\u001b[1;3m[{'id': 2, 'city': 'Los Angeles'}, {'id': 1, 'city': 'New York'}, {'id': 3, 'city': 'Chicago'}, {'id': 4, 'city': 'Houston'}, {'id': 5, 'city': 'Miami'}]\u001b[0m\u001b[32;1m\u001b[1;3m\n",
|
||||
"Invoking: `get_current_weather_for_location` with `{'location_id': 2}`\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[0m\u001b[36;1m\u001b[1;3mSunny, Temperature: 75°F\u001b[0m\u001b[32;1m\u001b[1;3mThe weather in Los Angeles is sunny with a temperature of 75°F.\u001b[0m\n",
|
||||
@@ -324,15 +236,15 @@
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'input': 'whats the weather in LA?',\n",
|
||||
"{'question': 'what is the weather in LA',\n",
|
||||
" 'output': 'The weather in Los Angeles is sunny with a temperature of 75°F.',\n",
|
||||
" 'intermediate_steps': [(AgentActionMessageLog(tool='find_locations_by_name', tool_input={'city': 'Los Angeles'}, log=\"\\nInvoking: `find_locations_by_name` with `{'city': 'Los Angeles'}`\\n\\n\\n\", message_log=[AIMessage(content='', additional_kwargs={'function_call': {'arguments': '{\"city\":\"Los Angeles\"}', 'name': 'find_locations_by_name'}})]),\n",
|
||||
" 'intermediate_steps': [(ToolAgentAction(tool='find_locations_by_name', tool_input={'city': 'LA'}, log=\"\\nInvoking: `find_locations_by_name` with `{'city': 'LA'}`\\n\\n\\n\", message_log=[AIMessageChunk(content='', additional_kwargs={'tool_calls': [{'index': 0, 'id': 'call_hJrCZgP4eDgaj6s4RtCKXTOo', 'function': {'arguments': '{\"city\":\"LA\"}', 'name': 'find_locations_by_name'}, 'type': 'function'}]}, response_metadata={'finish_reason': 'tool_calls'}, id='run-23ccffb0-3b17-46a4-b42e-5eaa3220b211', tool_calls=[{'name': 'find_locations_by_name', 'args': {'city': 'LA'}, 'id': 'call_hJrCZgP4eDgaj6s4RtCKXTOo'}], tool_call_chunks=[{'name': 'find_locations_by_name', 'args': '{\"city\":\"LA\"}', 'id': 'call_hJrCZgP4eDgaj6s4RtCKXTOo', 'index': 0}])], tool_call_id='call_hJrCZgP4eDgaj6s4RtCKXTOo'),\n",
|
||||
" [{'id': 2, 'city': 'Los Angeles'},\n",
|
||||
" {'id': 4, 'city': 'Houston'},\n",
|
||||
" {'id': 1, 'city': 'New York'},\n",
|
||||
" {'id': 3, 'city': 'Chicago'},\n",
|
||||
" {'id': 4, 'city': 'Houston'},\n",
|
||||
" {'id': 5, 'city': 'Miami'}]),\n",
|
||||
" (AgentActionMessageLog(tool='get_weather_at_location', tool_input={'location_id': 2}, log=\"\\nInvoking: `get_weather_at_location` with `{'location_id': 2}`\\n\\n\\n\", message_log=[AIMessage(content='', additional_kwargs={'function_call': {'arguments': '{\"location_id\":2}', 'name': 'get_weather_at_location'}})]),\n",
|
||||
" (ToolAgentAction(tool='get_current_weather_for_location', tool_input={'location_id': 2}, log=\"\\nInvoking: `get_current_weather_for_location` with `{'location_id': 2}`\\n\\n\\n\", message_log=[AIMessageChunk(content='', additional_kwargs={'tool_calls': [{'index': 0, 'id': 'call_lopYjo00MF9mZtnHtiisTqyp', 'function': {'arguments': '{\"location_id\":2}', 'name': 'get_current_weather_for_location'}, 'type': 'function'}]}, response_metadata={'finish_reason': 'tool_calls'}, id='run-9bba5827-d98b-464d-8028-25eb4a05d227', tool_calls=[{'name': 'get_current_weather_for_location', 'args': {'location_id': 2}, 'id': 'call_lopYjo00MF9mZtnHtiisTqyp'}], tool_call_chunks=[{'name': 'get_current_weather_for_location', 'args': '{\"location_id\":2}', 'id': 'call_lopYjo00MF9mZtnHtiisTqyp', 'index': 0}])], tool_call_id='call_lopYjo00MF9mZtnHtiisTqyp'),\n",
|
||||
" 'Sunny, Temperature: 75°F')]}"
|
||||
]
|
||||
},
|
||||
@@ -342,269 +254,31 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain import globals\n",
|
||||
"\n",
|
||||
"globals.set_verbose(True)\n",
|
||||
"\n",
|
||||
"agent = agent_factory()\n",
|
||||
"agent.invoke({\"question\": \"whats the weather in LA?\"})"
|
||||
"agent.invoke({\"question\": \"what is the weather in LA\"})"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "142ac640-3ce0-4f38-89cd-8d24d65997e4",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Benchmarking\n",
|
||||
"\n",
|
||||
"See `introduction` and `benchmark all` for information on how to run benchmarks. This notebook is just to here to explain and explore the task."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"id": "43edee23-109d-4f75-be68-d2b4b3240c9b",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"execution_count": null,
|
||||
"id": "e49455cc-13c5-4ea6-bb4b-e61c39ea0267",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"globals.set_verbose(False)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "3821e4b0-8e67-418a-840c-470fcde42df0",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Eval\n",
|
||||
"\n",
|
||||
"Let's evaluate an agent now"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"id": "2e02fb65-eecf-43b8-bf76-1e86ca535da0",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"View the evaluation results for project 'tool-usage-relational-data-gpt-3.5-turbo-1106-8258' at:\n",
|
||||
"https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/projects/p/8aae8e36-720a-42c8-8540-5d5475e7181e?eval=true\n",
|
||||
"\n",
|
||||
"View all tests for Dataset Tool Usage - Relational Data at:\n",
|
||||
"https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/datasets/df6be6c9-05b3-445e-8836-ebb4aba63826\n",
|
||||
"[------------------------------------------------->] 21/21\n",
|
||||
"View the evaluation results for project 'tool-usage-relational-data-gpt-3.5-turbo-0613-8258' at:\n",
|
||||
"https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/projects/p/d8773df1-b054-41e4-a947-7b256ca8738b?eval=true\n",
|
||||
"\n",
|
||||
"View all tests for Dataset Tool Usage - Relational Data at:\n",
|
||||
"https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/datasets/df6be6c9-05b3-445e-8836-ebb4aba63826\n",
|
||||
"[------------------------------------------------->] 21/21\n",
|
||||
"View the evaluation results for project 'tool-usage-relational-data-gpt-4-0613-8258' at:\n",
|
||||
"https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/projects/p/090fecae-923f-4281-93f7-2c5253a2a2a4?eval=true\n",
|
||||
"\n",
|
||||
"View all tests for Dataset Tool Usage - Relational Data at:\n",
|
||||
"https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/datasets/df6be6c9-05b3-445e-8836-ebb4aba63826\n",
|
||||
"[------------------------------------------------->] 21/21"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import uuid\n",
|
||||
"\n",
|
||||
"from langsmith.client import Client\n",
|
||||
"\n",
|
||||
"from langchain_benchmarks.tool_usage import get_eval_config\n",
|
||||
"\n",
|
||||
"experiment_uuid = uuid.uuid4().hex[:4]\n",
|
||||
"\n",
|
||||
"client = Client()\n",
|
||||
"\n",
|
||||
"models = [\"gpt-3.5-turbo-1106\", \"gpt-3.5-turbo-0613\", \"gpt-4-0613\"]\n",
|
||||
"\n",
|
||||
"for model in models:\n",
|
||||
" print()\n",
|
||||
" eval_config = get_eval_config()\n",
|
||||
" agent_factory = AgentFactory(task, model=model)\n",
|
||||
" test_run = client.run_on_dataset(\n",
|
||||
" dataset_name=task.name,\n",
|
||||
" llm_or_chain_factory=agent_factory,\n",
|
||||
" evaluation=eval_config,\n",
|
||||
" verbose=False,\n",
|
||||
" project_name=f\"tool-usage-relational-data-{model}-{experiment_uuid}\",\n",
|
||||
" tags=[model],\n",
|
||||
" project_metadata={\n",
|
||||
" \"model\": model,\n",
|
||||
" \"arch\": \"openai-functions-agent\",\n",
|
||||
" \"id\": experiment_uuid,\n",
|
||||
" },\n",
|
||||
" )"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "1b039225-01cf-481a-87a6-4e880e9b1dcd",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Inspect\n",
|
||||
"\n",
|
||||
"Here, we'll take a look at the underlying results a little bit."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 24,
|
||||
"id": "fe9b20c4-9da0-47a2-95a3-b5660a54855a",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import pandas as pd\n",
|
||||
"from langsmith.client import Client\n",
|
||||
"\n",
|
||||
"client = Client()\n",
|
||||
"projects = list(\n",
|
||||
" client.list_projects(reference_dataset_name=\"Tool Usage - Relational Data\")\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"dfs = []\n",
|
||||
"for project in projects:\n",
|
||||
" first_root_run = next(\n",
|
||||
" client.list_runs(project_name=project.name, execution_order=1)\n",
|
||||
" )\n",
|
||||
" # Temporary way to get tag information\n",
|
||||
" tags = first_root_run.tags\n",
|
||||
" test_results = client.get_test_results(project_name=project.name)\n",
|
||||
" test_results[\"model\"] = tags[0]\n",
|
||||
" dfs.append(test_results)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"df = pd.concat(dfs)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "da6962a1-81f2-445f-8547-513a105a3847",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Stats"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4b7d366a-8754-417a-a654-956528f134e2",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"In terms of function usage, gpt-4 uses more calls than is strictly necessary (`feedback.# steps / # expected steps` is > 1). However, it's doing a pretty good job.\n",
|
||||
"\n",
|
||||
"The gpt-3.5 models do not use tools enough (`feedback.# steps / # expected steps` is < 1) and as a result do a worse job at the task.\n",
|
||||
"\n",
|
||||
"Note: The intermediate step correctness happens to have the same average for the 3 models -- this is just a coincidence you can confirm by inspecting underlying results."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 25,
|
||||
"id": "066551f2-eb30-4bc1-94fd-0ca0085103ad",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/html": [
|
||||
"<div>\n",
|
||||
"<style scoped>\n",
|
||||
" .dataframe tbody tr th:only-of-type {\n",
|
||||
" vertical-align: middle;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" .dataframe tbody tr th {\n",
|
||||
" vertical-align: top;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" .dataframe thead th {\n",
|
||||
" text-align: right;\n",
|
||||
" }\n",
|
||||
"</style>\n",
|
||||
"<table border=\"1\" class=\"dataframe\">\n",
|
||||
" <thead>\n",
|
||||
" <tr style=\"text-align: right;\">\n",
|
||||
" <th></th>\n",
|
||||
" <th>feedback.correctness</th>\n",
|
||||
" <th>feedback.Intermediate steps correctness</th>\n",
|
||||
" <th>execution_time</th>\n",
|
||||
" <th>feedback.# steps / # expected steps</th>\n",
|
||||
" <th>n</th>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>model</th>\n",
|
||||
" <th></th>\n",
|
||||
" <th></th>\n",
|
||||
" <th></th>\n",
|
||||
" <th></th>\n",
|
||||
" <th></th>\n",
|
||||
" </tr>\n",
|
||||
" </thead>\n",
|
||||
" <tbody>\n",
|
||||
" <tr>\n",
|
||||
" <th>gpt-3.5-turbo-0613</th>\n",
|
||||
" <td>0.714286</td>\n",
|
||||
" <td>0.714286</td>\n",
|
||||
" <td>4.829506</td>\n",
|
||||
" <td>0.825390</td>\n",
|
||||
" <td>21</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>gpt-3.5-turbo-1106</th>\n",
|
||||
" <td>0.857143</td>\n",
|
||||
" <td>0.714286</td>\n",
|
||||
" <td>5.464218</td>\n",
|
||||
" <td>0.965871</td>\n",
|
||||
" <td>21</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>gpt-4-0613</th>\n",
|
||||
" <td>0.952381</td>\n",
|
||||
" <td>0.714286</td>\n",
|
||||
" <td>8.544358</td>\n",
|
||||
" <td>1.037300</td>\n",
|
||||
" <td>21</td>\n",
|
||||
" </tr>\n",
|
||||
" </tbody>\n",
|
||||
"</table>\n",
|
||||
"</div>"
|
||||
],
|
||||
"text/plain": [
|
||||
" feedback.correctness \\\n",
|
||||
"model \n",
|
||||
"gpt-3.5-turbo-0613 0.714286 \n",
|
||||
"gpt-3.5-turbo-1106 0.857143 \n",
|
||||
"gpt-4-0613 0.952381 \n",
|
||||
"\n",
|
||||
" feedback.Intermediate steps correctness execution_time \\\n",
|
||||
"model \n",
|
||||
"gpt-3.5-turbo-0613 0.714286 4.829506 \n",
|
||||
"gpt-3.5-turbo-1106 0.714286 5.464218 \n",
|
||||
"gpt-4-0613 0.714286 8.544358 \n",
|
||||
"\n",
|
||||
" feedback.# steps / # expected steps n \n",
|
||||
"model \n",
|
||||
"gpt-3.5-turbo-0613 0.825390 21 \n",
|
||||
"gpt-3.5-turbo-1106 0.965871 21 \n",
|
||||
"gpt-4-0613 1.037300 21 "
|
||||
]
|
||||
},
|
||||
"execution_count": 25,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"count_df = df.groupby(\"model\").size().to_frame(\"n\")\n",
|
||||
"df.groupby(\"model\")[\n",
|
||||
" [\n",
|
||||
" \"feedback.correctness\",\n",
|
||||
" \"feedback.Intermediate steps correctness\",\n",
|
||||
" \"execution_time\",\n",
|
||||
" \"feedback.# steps / # expected steps\",\n",
|
||||
" ]\n",
|
||||
"].mean().join(count_df)"
|
||||
]
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -37,7 +37,7 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_benchmarks import clone_public_dataset, registry"
|
||||
"from langchain_benchmarks import registry"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -71,7 +71,7 @@
|
||||
"</table>"
|
||||
],
|
||||
"text/plain": [
|
||||
"ToolUsageTask(name='Tool Usage - Typewriter (26 tools)', dataset_id='https://smith.langchain.com/public/128af05e-aa00-4e3b-a958-d166dd450581/d', description=\"Environment with 26 tools each tool represents a letter of the alphabet.\\n\\nThe objective of this task is to evaluate the model's ability the use tools\\nfor a simple repetition task.\\n\\nFor example, if the string is 'abc', the tools 'a', 'b', and 'c' must be invoked in that order.\\n\\nThe dataset includes examples of varying difficulty. The difficulty is measured by the length of the string.\\n\\nThis is a variation of the typer writer task, where 26 parameterless tools are\\ngiven instead of a single tool that takes a letter as an argument.\\n\", create_environment=<function get_environment at 0x7f6cd20e4f40>, instructions=\"Repeat the given string by using the provided tools. Do not write anything else or provide any explanations. For example, if the string is 'abc', you must invoke the tools 'a', 'b', and 'c' in that order. Please invoke the functions without any arguments.\")"
|
||||
"ToolUsageTask(name='Tool Usage - Typewriter (26 tools)', dataset_id='https://smith.langchain.com/public/128af05e-aa00-4e3b-a958-d166dd450581/d', description=\"Environment with 26 tools each tool represents a letter of the alphabet.\\n\\nThe objective of this task is to evaluate the model's ability the use tools\\nfor a simple repetition task.\\n\\nFor example, if the string is 'abc', the tools 'a', 'b', and 'c' must be invoked in that order.\\n\\nThe dataset includes examples of varying difficulty. The difficulty is measured by the length of the string.\\n\\nThis is a variation of the typer writer task, where 26 parameterless tools are\\ngiven instead of a single tool that takes a letter as an argument.\\n\", create_environment=<function get_environment at 0x75aa9dec2d40>, instructions=\"Repeat the given string by using the provided tools. Do not write anything else or provide any explanations. For example, if the string is 'abc', you must invoke the tools 'a', 'b', and 'c' in that order. Please invoke the functions without any arguments.\", eval_params={'output_evaluation': 'none'})"
|
||||
]
|
||||
},
|
||||
"execution_count": 2,
|
||||
@@ -84,35 +84,6 @@
|
||||
"task"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "bc33a639-3caf-4314-8ea7-1c7c8b1d114d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Clone the dataset associaetd with this task"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "70369f67-deb4-467a-801a-6d38c3d0460d",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Dataset Tool Usage - Typewriter (26 tools) already exists. Skipping.\n",
|
||||
"You can access the dataset at https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/datasets/2f462c7a-f9b9-46e7-b96b-7469e965f478.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"clone_public_dataset(task.dataset_id, dataset_name=task.name)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b462f7b8-fd42-4613-ab5f-5f3cbbc37d28",
|
||||
@@ -135,7 +106,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"execution_count": 3,
|
||||
"id": "61535a75-24f6-4727-9549-f76c263e9153",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -147,7 +118,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"execution_count": 4,
|
||||
"id": "f35a0a1d-5a1e-4de1-8d8c-c7c9a264a6c7",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -156,14 +127,14 @@
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[StructuredTool(name='a', description='a() -> str - Run to Type the letter \"a\".', args_schema=<class 'pydantic.v1.main.aSchemaSchema'>, func=<function _create_typing_func.<locals>.func at 0x7f6cd20e6520>),\n",
|
||||
" StructuredTool(name='b', description='b() -> str - Run to Type the letter \"b\".', args_schema=<class 'pydantic.v1.main.bSchemaSchema'>, func=<function _create_typing_func.<locals>.func at 0x7f6cd20e65c0>),\n",
|
||||
" StructuredTool(name='c', description='c() -> str - Run to Type the letter \"c\".', args_schema=<class 'pydantic.v1.main.cSchemaSchema'>, func=<function _create_typing_func.<locals>.func at 0x7f6cd20e6660>),\n",
|
||||
" StructuredTool(name='d', description='d() -> str - Run to Type the letter \"d\".', args_schema=<class 'pydantic.v1.main.dSchemaSchema'>, func=<function _create_typing_func.<locals>.func at 0x7f6cd20e6700>),\n",
|
||||
" StructuredTool(name='e', description='e() -> str - Run to Type the letter \"e\".', args_schema=<class 'pydantic.v1.main.eSchemaSchema'>, func=<function _create_typing_func.<locals>.func at 0x7f6cd20e67a0>)]"
|
||||
"[StructuredTool(name='a', description='a() -> str - Run to Type the letter \"a\".', args_schema=<class 'pydantic.v1.main.aSchema'>, func=<function _create_typing_func.<locals>.func at 0x75aa9defc180>),\n",
|
||||
" StructuredTool(name='b', description='b() -> str - Run to Type the letter \"b\".', args_schema=<class 'pydantic.v1.main.bSchema'>, func=<function _create_typing_func.<locals>.func at 0x75aa9defc220>),\n",
|
||||
" StructuredTool(name='c', description='c() -> str - Run to Type the letter \"c\".', args_schema=<class 'pydantic.v1.main.cSchema'>, func=<function _create_typing_func.<locals>.func at 0x75aa9defc2c0>),\n",
|
||||
" StructuredTool(name='d', description='d() -> str - Run to Type the letter \"d\".', args_schema=<class 'pydantic.v1.main.dSchema'>, func=<function _create_typing_func.<locals>.func at 0x75aa9defc360>),\n",
|
||||
" StructuredTool(name='e', description='e() -> str - Run to Type the letter \"e\".', args_schema=<class 'pydantic.v1.main.eSchema'>, func=<function _create_typing_func.<locals>.func at 0x75aa9defc400>)]"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -174,11 +145,34 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"execution_count": 5,
|
||||
"id": "5bea0190-39ec-4f30-9a00-90136bc6bf0b",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'OK'"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"env.tools[0].invoke({})"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "bf7444da-15a1-455a-b22e-639cbfff8432",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
@@ -191,36 +185,13 @@
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"env.tools[0].invoke({})"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "bf7444da-15a1-455a-b22e-639cbfff8432",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'OK'"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"env.tools[3].invoke({})"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"execution_count": 7,
|
||||
"id": "d12bd710-5c01-4539-a4b9-afbf03164923",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
@@ -232,7 +203,7 @@
|
||||
"'ad'"
|
||||
]
|
||||
},
|
||||
"execution_count": 8,
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -246,106 +217,110 @@
|
||||
"id": "f1d62a13-3771-460f-b131-4443f669ca3d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Agent Factory\n",
|
||||
"## Explore the task\n",
|
||||
"\n",
|
||||
"For evaluation, we need an agent factory that will create a new instance of an agent executor for every evaluation run.\n",
|
||||
"\n",
|
||||
"We'll use an `OpenAIAgentFactory` provided with LangChain Benchmarks -- look at the `intro` section to see how to define your own."
|
||||
"We'll use the `StandardAgentFactory` -- look at the `intro` for more information about what it does and/or how to create a custom one."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"execution_count": 10,
|
||||
"id": "6142cf4e-862c-47a3-aa75-81d7d3231308",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'input': 'hello',\n",
|
||||
" 'output': 'hello\\nhello',\n",
|
||||
" 'intermediate_steps': [(AgentActionMessageLog(tool='h', tool_input={}, log='\\nInvoking: `h` with `{}`\\n\\n\\n', message_log=[AIMessage(content='', additional_kwargs={'function_call': {'name': 'h', 'arguments': ''}})]),\n",
|
||||
" 'OK'),\n",
|
||||
" (AgentActionMessageLog(tool='e', tool_input={}, log='\\nInvoking: `e` with `{}`\\n\\n\\n', message_log=[AIMessage(content='', additional_kwargs={'function_call': {'name': 'e', 'arguments': ''}})]),\n",
|
||||
" 'OK'),\n",
|
||||
" (AgentActionMessageLog(tool='l', tool_input={}, log='\\nInvoking: `l` with `{}`\\n\\n\\n', message_log=[AIMessage(content='', additional_kwargs={'function_call': {'name': 'l', 'arguments': ''}})]),\n",
|
||||
" 'OK'),\n",
|
||||
" (AgentActionMessageLog(tool='l', tool_input={}, log='\\nInvoking: `l` with `{}`\\n\\n\\n', message_log=[AIMessage(content='', additional_kwargs={'function_call': {'name': 'l', 'arguments': ''}})]),\n",
|
||||
" 'OK'),\n",
|
||||
" (AgentActionMessageLog(tool='o', tool_input={}, log='\\nInvoking: `o` with `{}`\\n\\n\\n', message_log=[AIMessage(content='', additional_kwargs={'function_call': {'name': 'o', 'arguments': ''}})]),\n",
|
||||
" 'OK')],\n",
|
||||
" 'state': 'hello'}"
|
||||
]
|
||||
},
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain_benchmarks.tool_usage import agents\n",
|
||||
"\n",
|
||||
"agent_factory = agents.OpenAIAgentFactory(task, model=\"gpt-3.5-turbo-16k\")\n",
|
||||
"\n",
|
||||
"# Let's test that our agent works\n",
|
||||
"agent = agent_factory()\n",
|
||||
"agent.invoke({\"question\": \"hello\"})"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "3821e4b0-8e67-418a-840c-470fcde42df0",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Eval\n",
|
||||
"\n",
|
||||
"Let's evaluate an agent now.\n",
|
||||
"\n",
|
||||
"Eval code below has not been run yet."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "fb32763c-79ab-426a-8fc6-bf8ebb0dd432",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import uuid\n",
|
||||
"from langchain_core.prompts import ChatPromptTemplate\n",
|
||||
"from langchain_openai.chat_models import ChatOpenAI\n",
|
||||
"\n",
|
||||
"from langsmith.client import Client\n",
|
||||
"from langchain_benchmarks.tool_usage.agents import StandardAgentFactory\n",
|
||||
"\n",
|
||||
"from langchain_benchmarks.tool_usage import get_eval_config\n",
|
||||
"model = ChatOpenAI(temperature=0)\n",
|
||||
"prompt = ChatPromptTemplate.from_messages(\n",
|
||||
" [\n",
|
||||
" (\"system\", \"{instructions}\"), # Populated from task.instructions automatically\n",
|
||||
" (\"human\", \"{question}\"), # Populated from the test data\n",
|
||||
" (\n",
|
||||
" \"placeholder\",\n",
|
||||
" \"{agent_scratchpad}\",\n",
|
||||
" ), # Work where the agent can do its work (e.g., call multiple tools)\n",
|
||||
" ]\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"experiment_uuid = uuid.uuid4().hex[:4]\n",
|
||||
"agent_factory = StandardAgentFactory(task, model, prompt)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"id": "fb32763c-79ab-426a-8fc6-bf8ebb0dd432",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
|
||||
"\u001b[32;1m\u001b[1;3m\n",
|
||||
"Invoking: `a` with `{}`\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[0m\u001b[36;1m\u001b[1;3mOK\u001b[0m\u001b[32;1m\u001b[1;3m\n",
|
||||
"Invoking: `b` with `{}`\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[0m\u001b[33;1m\u001b[1;3mOK\u001b[0m\u001b[32;1m\u001b[1;3m\n",
|
||||
"Invoking: `c` with `{}`\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[0m\u001b[38;5;200m\u001b[1;3mOK\u001b[0m\u001b[32;1m\u001b[1;3mabcabcabc\u001b[0m\n",
|
||||
"\n",
|
||||
"\u001b[1m> Finished chain.\u001b[0m\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'question': 'abc',\n",
|
||||
" 'output': 'abcabcabc',\n",
|
||||
" 'intermediate_steps': [(ToolAgentAction(tool='a', tool_input={}, log='\\nInvoking: `a` with `{}`\\n\\n\\n', message_log=[AIMessageChunk(content='', additional_kwargs={'tool_calls': [{'index': 0, 'id': 'call_OrpjShN5uNzw2Rsb1tWF6swI', 'function': {'arguments': '{}', 'name': 'a'}, 'type': 'function'}, {'index': 1, 'id': 'call_2XO5RNgt9FjGvTXztgD0tKqW', 'function': {'arguments': '{}', 'name': 'b'}, 'type': 'function'}, {'index': 2, 'id': 'call_MRAOAgbi8vT445clqC8OybMR', 'function': {'arguments': '{}', 'name': 'c'}, 'type': 'function'}]}, response_metadata={'finish_reason': 'tool_calls'}, id='run-9a1af767-29e4-4759-ab28-5b29236e8f22', tool_calls=[{'name': 'a', 'args': {}, 'id': 'call_OrpjShN5uNzw2Rsb1tWF6swI'}, {'name': 'b', 'args': {}, 'id': 'call_2XO5RNgt9FjGvTXztgD0tKqW'}, {'name': 'c', 'args': {}, 'id': 'call_MRAOAgbi8vT445clqC8OybMR'}], tool_call_chunks=[{'name': 'a', 'args': '{}', 'id': 'call_OrpjShN5uNzw2Rsb1tWF6swI', 'index': 0}, {'name': 'b', 'args': '{}', 'id': 'call_2XO5RNgt9FjGvTXztgD0tKqW', 'index': 1}, {'name': 'c', 'args': '{}', 'id': 'call_MRAOAgbi8vT445clqC8OybMR', 'index': 2}])], tool_call_id='call_OrpjShN5uNzw2Rsb1tWF6swI'),\n",
|
||||
" 'OK'),\n",
|
||||
" (ToolAgentAction(tool='b', tool_input={}, log='\\nInvoking: `b` with `{}`\\n\\n\\n', message_log=[AIMessageChunk(content='', additional_kwargs={'tool_calls': [{'index': 0, 'id': 'call_OrpjShN5uNzw2Rsb1tWF6swI', 'function': {'arguments': '{}', 'name': 'a'}, 'type': 'function'}, {'index': 1, 'id': 'call_2XO5RNgt9FjGvTXztgD0tKqW', 'function': {'arguments': '{}', 'name': 'b'}, 'type': 'function'}, {'index': 2, 'id': 'call_MRAOAgbi8vT445clqC8OybMR', 'function': {'arguments': '{}', 'name': 'c'}, 'type': 'function'}]}, response_metadata={'finish_reason': 'tool_calls'}, id='run-9a1af767-29e4-4759-ab28-5b29236e8f22', tool_calls=[{'name': 'a', 'args': {}, 'id': 'call_OrpjShN5uNzw2Rsb1tWF6swI'}, {'name': 'b', 'args': {}, 'id': 'call_2XO5RNgt9FjGvTXztgD0tKqW'}, {'name': 'c', 'args': {}, 'id': 'call_MRAOAgbi8vT445clqC8OybMR'}], tool_call_chunks=[{'name': 'a', 'args': '{}', 'id': 'call_OrpjShN5uNzw2Rsb1tWF6swI', 'index': 0}, {'name': 'b', 'args': '{}', 'id': 'call_2XO5RNgt9FjGvTXztgD0tKqW', 'index': 1}, {'name': 'c', 'args': '{}', 'id': 'call_MRAOAgbi8vT445clqC8OybMR', 'index': 2}])], tool_call_id='call_2XO5RNgt9FjGvTXztgD0tKqW'),\n",
|
||||
" 'OK'),\n",
|
||||
" (ToolAgentAction(tool='c', tool_input={}, log='\\nInvoking: `c` with `{}`\\n\\n\\n', message_log=[AIMessageChunk(content='', additional_kwargs={'tool_calls': [{'index': 0, 'id': 'call_OrpjShN5uNzw2Rsb1tWF6swI', 'function': {'arguments': '{}', 'name': 'a'}, 'type': 'function'}, {'index': 1, 'id': 'call_2XO5RNgt9FjGvTXztgD0tKqW', 'function': {'arguments': '{}', 'name': 'b'}, 'type': 'function'}, {'index': 2, 'id': 'call_MRAOAgbi8vT445clqC8OybMR', 'function': {'arguments': '{}', 'name': 'c'}, 'type': 'function'}]}, response_metadata={'finish_reason': 'tool_calls'}, id='run-9a1af767-29e4-4759-ab28-5b29236e8f22', tool_calls=[{'name': 'a', 'args': {}, 'id': 'call_OrpjShN5uNzw2Rsb1tWF6swI'}, {'name': 'b', 'args': {}, 'id': 'call_2XO5RNgt9FjGvTXztgD0tKqW'}, {'name': 'c', 'args': {}, 'id': 'call_MRAOAgbi8vT445clqC8OybMR'}], tool_call_chunks=[{'name': 'a', 'args': '{}', 'id': 'call_OrpjShN5uNzw2Rsb1tWF6swI', 'index': 0}, {'name': 'b', 'args': '{}', 'id': 'call_2XO5RNgt9FjGvTXztgD0tKqW', 'index': 1}, {'name': 'c', 'args': '{}', 'id': 'call_MRAOAgbi8vT445clqC8OybMR', 'index': 2}])], tool_call_id='call_MRAOAgbi8vT445clqC8OybMR'),\n",
|
||||
" 'OK')],\n",
|
||||
" 'state': 'abc'}"
|
||||
]
|
||||
},
|
||||
"execution_count": 12,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain import globals\n",
|
||||
"\n",
|
||||
"client = Client()\n",
|
||||
"globals.set_verbose(True)\n",
|
||||
"\n",
|
||||
"models = [\"gpt-3.5-turbo-16k\"]\n",
|
||||
"agent = agent_factory()\n",
|
||||
"agent.invoke({\"question\": \"abc\"})"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "89124d06-41f7-4432-9f2e-542c0d85e2e5",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Benchmarking\n",
|
||||
"\n",
|
||||
"for model in models:\n",
|
||||
" print()\n",
|
||||
" # The eval config will evaluate the state, but not the output which is meaningless for this task.\n",
|
||||
" eval_config = get_eval_config(output_evaluation=\"none\")\n",
|
||||
" agent_factory = agents.OpenAIAgentFactory(task, model=model)\n",
|
||||
" test_run = client.run_on_dataset(\n",
|
||||
" dataset_name=task.name,\n",
|
||||
" llm_or_chain_factory=agent_factory,\n",
|
||||
" evaluation=eval_config,\n",
|
||||
" verbose=False,\n",
|
||||
" concurrency_level=1,\n",
|
||||
" project_name=f\"typewriter-26-{model}-{experiment_uuid}\",\n",
|
||||
" tags=[model],\n",
|
||||
" project_metadata={\n",
|
||||
" \"model\": model,\n",
|
||||
" \"arch\": \"openai-functions-agent\",\n",
|
||||
" \"id\": experiment_uuid,\n",
|
||||
" },\n",
|
||||
" )"
|
||||
"See `introduction` and `benchmark all` for information on how to run benchmarks. This notebook is just to here to explain and explore the task."
|
||||
]
|
||||
}
|
||||
],
|
||||
|
||||
@@ -17,6 +17,7 @@
|
||||
./notebooks/tool_usage/multiverse_math
|
||||
./notebooks/tool_usage/typewriter_1
|
||||
./notebooks/tool_usage/typewriter_26
|
||||
./notebooks/tool_usage/benchmark_all_tasks
|
||||
```
|
||||
|
||||
```{toctree}
|
||||
@@ -26,6 +27,7 @@
|
||||
./notebooks/extraction/intro
|
||||
./notebooks/extraction/email
|
||||
./notebooks/extraction/chat_extraction
|
||||
./notebooks/extraction/high_cardinality
|
||||
```
|
||||
|
||||
```{toctree}
|
||||
@@ -42,3 +44,9 @@
|
||||
./notebooks/retrieval/multi_modal_benchmarking/multi_modal_eval
|
||||
./notebooks/retrieval/comparing_techniques
|
||||
```
|
||||
|
||||
```{toctree}
|
||||
:maxdepth: 2
|
||||
:caption: Benchmarking Without LangSmith
|
||||
./notebooks/run_without_langsmith
|
||||
```
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
from typing import Optional
|
||||
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.chat_models.base import BaseChatModel
|
||||
from langchain.smith import RunEvalConfig
|
||||
from langchain_openai import ChatOpenAI
|
||||
|
||||
|
||||
def get_eval_config(eval_llm: Optional[BaseChatModel] = None) -> RunEvalConfig:
|
||||
|
||||
@@ -2,10 +2,10 @@
|
||||
from typing import Any, Dict, List, Optional, Type
|
||||
|
||||
from langchain.chains.openai_functions import convert_to_openai_function
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
|
||||
from langchain.prompts import ChatPromptTemplate
|
||||
from langchain.schema.runnable import Runnable
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith.client import Client
|
||||
from pydantic import BaseModel
|
||||
|
||||
|
||||
@@ -0,0 +1,5 @@
|
||||
from langchain_benchmarks.extraction.tasks.high_cardinality.name_correction import (
|
||||
NAME_CORRECTION_TASK,
|
||||
)
|
||||
|
||||
__all__ = ["NAME_CORRECTION_TASK"]
|
||||
@@ -0,0 +1,36 @@
|
||||
from langchain.smith import RunEvalConfig
|
||||
from langchain_core.pydantic_v1 import BaseModel, Field
|
||||
from langsmith.evaluation import EvaluationResult, run_evaluator
|
||||
from langsmith.schemas import Example, Run
|
||||
|
||||
from langchain_benchmarks.schema import ExtractionTask
|
||||
|
||||
|
||||
@run_evaluator
|
||||
def correct_name(run: Run, example: Example) -> EvaluationResult:
|
||||
if "name" in run.outputs:
|
||||
prediction = run.outputs["name"]
|
||||
else:
|
||||
prediction = run.outputs["output"]["name"]
|
||||
name = example.outputs["name"]
|
||||
score = int(name == prediction)
|
||||
return EvaluationResult(key="correct", score=score)
|
||||
|
||||
|
||||
class Person(BaseModel):
|
||||
"""Information about a person."""
|
||||
|
||||
name: str = Field(..., description="The person's name")
|
||||
|
||||
|
||||
NAME_CORRECTION_TASK = ExtractionTask(
|
||||
name="Name Correction",
|
||||
dataset_id="https://smith.langchain.com/public/78df83ee-ba7f-41c6-832c-2b23327d4cf7/d",
|
||||
schema=Person,
|
||||
description="""A dataset of 23 misspelled full names and their correct spellings.""",
|
||||
dataset_url="https://smith.langchain.com/public/78df83ee-ba7f-41c6-832c-2b23327d4cf7/d",
|
||||
dataset_name="Extracting Corrected Names",
|
||||
eval_config=RunEvalConfig(
|
||||
custom_evaluators=[correct_name],
|
||||
),
|
||||
)
|
||||
@@ -212,10 +212,31 @@ _FIREWORKS_MODELS = [
|
||||
]
|
||||
|
||||
_ANTHROPIC_MODELS = [
|
||||
RegisteredModel(
|
||||
provider="anthropic",
|
||||
name="claude-3-haiku-20240307",
|
||||
description="Fastest and most compact model for near-instant responsiveness",
|
||||
type="chat",
|
||||
params={"model": "claude-3-haiku-20240307"},
|
||||
),
|
||||
RegisteredModel(
|
||||
provider="anthropic",
|
||||
name="claude-3-sonnet-20240229",
|
||||
description="Ideal balance of intelligence and speed for enterprise workloads",
|
||||
type="chat",
|
||||
params={"model": "claude-3-sonnet-20240229"},
|
||||
),
|
||||
RegisteredModel(
|
||||
provider="anthropic",
|
||||
name="claude-3-opus-20240229",
|
||||
description="Most powerful model for highly complex tasks",
|
||||
type="chat",
|
||||
params={"model": "claude-3-opus-20240229"},
|
||||
),
|
||||
RegisteredModel(
|
||||
provider="anthropic",
|
||||
name="claude-2",
|
||||
description=("Superior performance on tasks that require complex reasoning"),
|
||||
description="Superior performance on tasks that require complex reasoning",
|
||||
type="chat",
|
||||
params={
|
||||
"model": "claude-2",
|
||||
@@ -252,7 +273,35 @@ _ANTHROPIC_MODELS = [
|
||||
},
|
||||
),
|
||||
]
|
||||
_GOOGLE_GENAI_MODELS = [
|
||||
RegisteredModel(
|
||||
provider="google-genai",
|
||||
name="gemini-pro",
|
||||
description="Gemini Pro is a large model from Google trained on a diverse set of tasks.",
|
||||
type="chat",
|
||||
params={
|
||||
"model": "gemini-pro",
|
||||
"convert_system_message_to_human": True,
|
||||
},
|
||||
)
|
||||
]
|
||||
|
||||
_ANYSCALE_MODELS = [
|
||||
RegisteredModel(
|
||||
provider="anyscale",
|
||||
name="mistral-7b-instruct-v0.1",
|
||||
description="Mistral 7B model fine-tuned for function-calling.",
|
||||
type="chat",
|
||||
params={
|
||||
"model": "mistralai/Mistral-7B-Instruct-v0.1",
|
||||
},
|
||||
),
|
||||
]
|
||||
|
||||
model_registry = ModelRegistry(
|
||||
registered_models=_OPEN_AI_MODELS + _FIREWORKS_MODELS + _ANTHROPIC_MODELS
|
||||
registered_models=_OPEN_AI_MODELS
|
||||
+ _FIREWORKS_MODELS
|
||||
+ _ANYSCALE_MODELS
|
||||
+ _ANTHROPIC_MODELS
|
||||
+ _GOOGLE_GENAI_MODELS
|
||||
)
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
from typing import Optional
|
||||
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.evaluation import load_evaluator
|
||||
from langchain.smith import RunEvalConfig
|
||||
from langchain_openai import ChatOpenAI
|
||||
|
||||
try:
|
||||
from langchain.schema.language_model import BaseLanguageModel
|
||||
|
||||
@@ -1,9 +1,9 @@
|
||||
from typing import Optional
|
||||
|
||||
from langchain.base_language import BaseLanguageModel
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.schema.retriever import BaseRetriever
|
||||
from langchain.schema.runnable import Runnable
|
||||
from langchain_openai import ChatOpenAI
|
||||
|
||||
from langchain_benchmarks.rag.tasks.langchain_docs.architectures.crqa import (
|
||||
create_response_chain,
|
||||
|
||||
@@ -3,7 +3,6 @@ import os
|
||||
from functools import partial
|
||||
from typing import Callable, Iterable, List, Optional
|
||||
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.indexes import SQLRecordManager, index
|
||||
from langchain.output_parsers.openai_functions import JsonKeyOutputFunctionsParser
|
||||
from langchain.prompts import ChatPromptTemplate
|
||||
@@ -18,6 +17,7 @@ from langchain.schema.storage import BaseStore
|
||||
from langchain.schema.vectorstore import VectorStore
|
||||
from langchain.storage import InMemoryStore
|
||||
from langchain.text_splitter import RecursiveCharacterTextSplitter, TextSplitter
|
||||
from langchain_openai import ChatOpenAI
|
||||
from tqdm.auto import tqdm
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
@@ -1,6 +1,10 @@
|
||||
"""Registry of environments for ease of access."""
|
||||
|
||||
from langchain_benchmarks.extraction.tasks import chat_extraction, email_task
|
||||
from langchain_benchmarks.extraction.tasks import (
|
||||
chat_extraction,
|
||||
email_task,
|
||||
high_cardinality,
|
||||
)
|
||||
from langchain_benchmarks.rag.tasks import (
|
||||
LANGCHAIN_DOCS_TASK,
|
||||
MULTI_MODAL_SLIDE_DECKS_TASK,
|
||||
@@ -26,5 +30,6 @@ registry = Registry(
|
||||
LANGCHAIN_DOCS_TASK,
|
||||
SEMI_STRUCTURED_REPORTS_TASK,
|
||||
MULTI_MODAL_SLIDE_DECKS_TASK,
|
||||
high_cardinality.NAME_CORRECTION_TASK,
|
||||
]
|
||||
)
|
||||
|
||||
@@ -130,11 +130,14 @@ class ExtractionTask(BaseTask):
|
||||
|
||||
# We might want to make this optional / or support more types
|
||||
# and add validation, but let's wait until we have more examples
|
||||
instructions: ChatPromptTemplate
|
||||
instructions: Optional[ChatPromptTemplate] = None
|
||||
"""Get the prompt for the task.
|
||||
|
||||
This is the default prompt to use for the task.
|
||||
"""
|
||||
dataset_url: Optional[str] = None
|
||||
dataset_name: Optional[str] = None
|
||||
eval_config: Optional[RunEvalConfig] = None
|
||||
|
||||
|
||||
@dataclasses.dataclass(frozen=True)
|
||||
@@ -251,9 +254,15 @@ class Registry:
|
||||
self.tasks.append(task)
|
||||
|
||||
|
||||
Provider = Literal["fireworks", "openai", "anthropic"]
|
||||
Provider = Literal["fireworks", "openai", "anthropic", "anyscale"]
|
||||
ModelType = Literal["chat", "llm"]
|
||||
AUTHORIZED_NAMESPACES = {"langchain"}
|
||||
AUTHORIZED_NAMESPACES = {
|
||||
"langchain",
|
||||
"langchain_google_genai",
|
||||
"langchain_openai",
|
||||
"langchain_anthropic",
|
||||
"langchain_fireworks",
|
||||
}
|
||||
|
||||
|
||||
def _get_model_class_from_path(
|
||||
@@ -270,7 +279,15 @@ def _get_model_class_from_path(
|
||||
)
|
||||
|
||||
# Import the module dynamically
|
||||
module = importlib.import_module(module_name)
|
||||
try:
|
||||
module = importlib.import_module(module_name)
|
||||
except ImportError:
|
||||
raise ImportError(
|
||||
f"Could not import module {module_name}. "
|
||||
f"Perhaps you need to run to pip install the package? "
|
||||
f"`pip install {module_name}`."
|
||||
)
|
||||
|
||||
model_class = getattr(module, attribute_name)
|
||||
if not issubclass(model_class, (BaseLanguageModel, BaseChatModel)):
|
||||
raise ValueError(
|
||||
@@ -282,11 +299,17 @@ def _get_model_class_from_path(
|
||||
def _get_default_path(provider: str, type_: ModelType) -> str:
|
||||
"""Get the default path for a model."""
|
||||
paths = {
|
||||
("fireworks", "chat"): "langchain.chat_models.fireworks.ChatFireworks",
|
||||
("fireworks", "llm"): "langchain.llms.fireworks.Fireworks",
|
||||
("openai", "chat"): "langchain.chat_models.openai.ChatOpenAI",
|
||||
("openai", "llm"): "langchain.llms.openai.OpenAI",
|
||||
("anthropic", "chat"): "langchain.chat_models.anthropic.ChatAnthropic",
|
||||
("anthropic", "chat"): "langchain_anthropic.ChatAnthropic",
|
||||
("anyscale", "chat"): "langchain.chat_models.anyscale.ChatAnyscale",
|
||||
("anyscale", "llm"): "langchain.llms.anyscale.Anyscale",
|
||||
("fireworks", "chat"): "langchain_fireworks.ChatFireworks",
|
||||
("fireworks", "llm"): "langchain_fireworks.Fireworks",
|
||||
("openai", "chat"): "langchain_openai.ChatOpenAI",
|
||||
("openai", "llm"): "langchain_openai.OpenAI",
|
||||
(
|
||||
"google-genai",
|
||||
"chat",
|
||||
): "langchain_google_genai.chat_models.ChatGoogleGenerativeAI",
|
||||
}
|
||||
|
||||
if (provider, type_) not in paths:
|
||||
@@ -303,6 +326,10 @@ def _get_default_url(provider: str, type_: ModelType) -> Optional[str]:
|
||||
return "https://platform.openai.com/docs/models"
|
||||
elif provider == "anthropic":
|
||||
return "https://docs.anthropic.com/claude/reference/selecting-a-model"
|
||||
elif provider == "anyscale":
|
||||
return "https://docs.endpoints.anyscale.com/category/supported-models"
|
||||
elif provider == "google-genai":
|
||||
return "https://ai.google.dev/"
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
@@ -1,9 +1,15 @@
|
||||
"""Package for helping to evaluate agent runs."""
|
||||
from langchain_benchmarks.tool_usage.agents import apply_agent_executor_adapter
|
||||
from langchain_benchmarks.tool_usage.agents import (
|
||||
CustomRunnableAgentFactory,
|
||||
StandardAgentFactory,
|
||||
apply_agent_executor_adapter,
|
||||
)
|
||||
from langchain_benchmarks.tool_usage.evaluators import get_eval_config
|
||||
|
||||
# Please keep this list sorted!
|
||||
__all__ = [
|
||||
"apply_agent_executor_adapter",
|
||||
"CustomRunnableAgentFactory",
|
||||
"get_eval_config",
|
||||
"StandardAgentFactory",
|
||||
]
|
||||
|
||||
@@ -1,7 +1,11 @@
|
||||
from langchain_benchmarks.tool_usage.agents.adapters import apply_agent_executor_adapter
|
||||
from langchain_benchmarks.tool_usage.agents.experimental.factory import (
|
||||
CustomAgentFactory,
|
||||
from langchain_benchmarks.tool_usage.agents.runnable_agent import (
|
||||
CustomRunnableAgentFactory,
|
||||
)
|
||||
from langchain_benchmarks.tool_usage.agents.openai_functions import OpenAIAgentFactory
|
||||
from langchain_benchmarks.tool_usage.agents.tool_using_agent import StandardAgentFactory
|
||||
|
||||
__all__ = ["OpenAIAgentFactory", "apply_agent_executor_adapter", "CustomAgentFactory"]
|
||||
__all__ = [
|
||||
"apply_agent_executor_adapter",
|
||||
"CustomRunnableAgentFactory",
|
||||
"StandardAgentFactory",
|
||||
]
|
||||
|
||||
@@ -41,27 +41,8 @@ def apply_agent_executor_adapter(
|
||||
else:
|
||||
return None
|
||||
|
||||
def _format_input(inputs: dict) -> dict:
|
||||
"""Make sure that the input is always called `input`."""
|
||||
|
||||
if "question" not in inputs:
|
||||
raise ValueError(
|
||||
"Expected 'question' to be in the inputs. Found only the following "
|
||||
f"keys {sorted(inputs.keys())}."
|
||||
)
|
||||
|
||||
inputs = inputs.copy() # Because 'question' is popped below
|
||||
|
||||
if "input" not in inputs:
|
||||
return {"input": inputs.pop("question"), **inputs}
|
||||
return inputs
|
||||
|
||||
runnable = (
|
||||
RunnableLambda(_format_input).with_config({"run_name": "Format Input"})
|
||||
| agent_executor
|
||||
| RunnableLambda(_ensure_output_exists).with_config(
|
||||
{"run_name": "Ensure Output"}
|
||||
)
|
||||
runnable = agent_executor | RunnableLambda(_ensure_output_exists).with_config(
|
||||
{"run_name": "Ensure Output"}
|
||||
)
|
||||
|
||||
if state_reader is not None:
|
||||
|
||||
@@ -0,0 +1,11 @@
|
||||
import abc
|
||||
|
||||
from langchain_core.runnables import Runnable
|
||||
|
||||
|
||||
class AgentFactory(abc.ABC):
|
||||
"""Abstract class for agent factory"""
|
||||
|
||||
@abc.abstractmethod
|
||||
def __call__(self) -> Runnable:
|
||||
"""Create a new agent"""
|
||||
@@ -1,133 +0,0 @@
|
||||
from typing import List, Literal, Optional, Sequence, Tuple, Union
|
||||
|
||||
from langchain.agents import AgentOutputParser
|
||||
from langchain.prompts.chat import ChatPromptTemplate
|
||||
from langchain.schema.runnable import Runnable
|
||||
from langchain.tools import StructuredTool
|
||||
from langchain_core.agents import AgentAction, AgentFinish
|
||||
from langchain_core.language_models import BaseChatModel, BaseLanguageModel
|
||||
from langchain_core.messages import AIMessage, BaseMessage, HumanMessage
|
||||
from langchain_core.prompts import MessagesPlaceholder
|
||||
from typing_extensions import NotRequired, TypedDict
|
||||
|
||||
from langchain_benchmarks import RateLimiter
|
||||
from langchain_benchmarks.rate_limiting import with_rate_limit
|
||||
from langchain_benchmarks.tool_usage.agents.experimental.encoder import (
|
||||
AstPrinter,
|
||||
FunctionResult,
|
||||
TypeScriptEncoder,
|
||||
XMLEncoder,
|
||||
)
|
||||
from langchain_benchmarks.tool_usage.agents.experimental.prompts import (
|
||||
_AGENT_INSTRUCTIONS_BLOB_STYLE,
|
||||
)
|
||||
from langchain_benchmarks.tool_usage.agents.experimental.tool_utils import (
|
||||
convert_tool_to_function_definition,
|
||||
)
|
||||
|
||||
|
||||
def format_steps_for_chat(
|
||||
intermediate_steps: List[Tuple[AgentAction, str]],
|
||||
ast_printer: AstPrinter,
|
||||
) -> List[BaseMessage]:
|
||||
"""Format the steps."""
|
||||
messages = []
|
||||
for action, observation in intermediate_steps:
|
||||
# Action messages contains the tool invocation request from the LLM
|
||||
# Now add the result of the tool invocation.
|
||||
|
||||
if action.tool == "_Exception":
|
||||
messages.append(
|
||||
AIMessage(
|
||||
content=action.log,
|
||||
)
|
||||
)
|
||||
messages.append(
|
||||
# Tool input is the error message for the exception
|
||||
HumanMessage(content=action.tool_input)
|
||||
)
|
||||
else:
|
||||
messages.extend(action.messages)
|
||||
function_result: FunctionResult = {
|
||||
"name": action.tool,
|
||||
"error": None,
|
||||
"result": observation,
|
||||
}
|
||||
messages.append(
|
||||
HumanMessage(
|
||||
content=ast_printer.visit_function_result(function_result),
|
||||
)
|
||||
)
|
||||
|
||||
return messages
|
||||
|
||||
|
||||
# PUBLIC API
|
||||
|
||||
|
||||
class AgentInput(TypedDict):
|
||||
"""The input to the agent."""
|
||||
|
||||
input: str
|
||||
"""The input to the agent."""
|
||||
intermediate_steps: List[Tuple[AgentAction, str]]
|
||||
"""The intermediate steps taken by the agent."""
|
||||
examples: NotRequired[List[BaseMessage]]
|
||||
"""A list of messages that can be used to form example traces."""
|
||||
|
||||
|
||||
def create_agent(
|
||||
model: Union[BaseChatModel, BaseLanguageModel],
|
||||
tools: Sequence[StructuredTool],
|
||||
parser: AgentOutputParser,
|
||||
*,
|
||||
ast_printer: Union[AstPrinter, Literal["xml"]] = "xml",
|
||||
rate_limiter: Optional[RateLimiter] = None,
|
||||
) -> Runnable[AgentInput, Union[AgentAction, AgentFinish]]:
|
||||
"""Create an agent for a chat model."""
|
||||
if isinstance(ast_printer, str):
|
||||
if ast_printer == "xml":
|
||||
ast_printer_ = XMLEncoder()
|
||||
elif ast_printer == "typescript":
|
||||
ast_printer_ = TypeScriptEncoder()
|
||||
else:
|
||||
raise ValueError(f"Unknown ast printer: {ast_printer}")
|
||||
elif isinstance(ast_printer, AstPrinter):
|
||||
ast_printer_ = ast_printer
|
||||
else:
|
||||
raise TypeError(
|
||||
f"Expected AstPrinter or str, got {type(ast_printer)} for `ast_printer`"
|
||||
)
|
||||
|
||||
function_definitions = [convert_tool_to_function_definition(tool) for tool in tools]
|
||||
tool_description = ast_printer_.visit_function_definitions(function_definitions)
|
||||
|
||||
template = ChatPromptTemplate.from_messages(
|
||||
[
|
||||
("system", _AGENT_INSTRUCTIONS_BLOB_STYLE),
|
||||
MessagesPlaceholder("examples"), # Can use to add example traces
|
||||
("human", "{input}"),
|
||||
MessagesPlaceholder("history"),
|
||||
]
|
||||
).partial(tool_description=tool_description)
|
||||
|
||||
# For the time being, hard-coding the fact that we're using a <tool> tag.
|
||||
model = model.bind(stop=["</tool>"])
|
||||
|
||||
if rate_limiter:
|
||||
# Apply a rate limiter if it was provided
|
||||
model = with_rate_limit(model, rate_limiter)
|
||||
|
||||
agent = (
|
||||
{
|
||||
"input": lambda x: x["input"],
|
||||
"history": lambda x: format_steps_for_chat(
|
||||
x["intermediate_steps"], ast_printer_
|
||||
),
|
||||
"examples": lambda x: x.get("examples", []),
|
||||
}
|
||||
| template
|
||||
| model
|
||||
| parser
|
||||
)
|
||||
return agent
|
||||
@@ -1,240 +0,0 @@
|
||||
"""Prototyping code for rendering function definitions, invocations, and results.
|
||||
|
||||
Types are simplified for now to `str`.
|
||||
|
||||
We should actually support something like pydantic or jsonschema for the types, so
|
||||
we can expand them recursively for nested types.
|
||||
"""
|
||||
import abc
|
||||
from typing import Any, List, Optional
|
||||
|
||||
from typing_extensions import NotRequired, TypedDict
|
||||
|
||||
|
||||
class Parameter(TypedDict):
|
||||
"""Representation for a parameter."""
|
||||
|
||||
name: str
|
||||
type: str
|
||||
description: str
|
||||
|
||||
|
||||
class Arguments(TypedDict):
|
||||
"""Arguments are passed to a function during function invocation."""
|
||||
|
||||
name: Optional[str]
|
||||
value: Any
|
||||
|
||||
|
||||
class ReturnValue(TypedDict):
|
||||
"""Representation for a return value of a function call."""
|
||||
|
||||
type: str
|
||||
description: NotRequired[str]
|
||||
|
||||
|
||||
class FunctionDefinition(TypedDict):
|
||||
"""Representation for a function."""
|
||||
|
||||
name: str
|
||||
description: str # Function description
|
||||
parameters: List[Parameter]
|
||||
return_value: ReturnValue
|
||||
|
||||
|
||||
class FunctionInvocation(TypedDict):
|
||||
"""Representation for a function invocation."""
|
||||
|
||||
id: NotRequired[str]
|
||||
name: str
|
||||
arguments: List[Arguments]
|
||||
|
||||
|
||||
class FunctionResult(TypedDict):
|
||||
"""Representation for a function result."""
|
||||
|
||||
id: NotRequired[str]
|
||||
name: str
|
||||
result: Optional[str]
|
||||
error: Optional[str]
|
||||
|
||||
|
||||
class Visitor(abc.ABC):
|
||||
@abc.abstractmethod
|
||||
def visit_function_definition(self, function_definition: FunctionDefinition) -> str:
|
||||
"""Render a function."""
|
||||
|
||||
@abc.abstractmethod
|
||||
def visit_function_definitions(
|
||||
self, function_definitions: List[FunctionDefinition]
|
||||
) -> str:
|
||||
"""Render a function."""
|
||||
|
||||
@abc.abstractmethod
|
||||
def visit_function_invocation(self, function_invocation: FunctionInvocation) -> str:
|
||||
"""Render a function invocation."""
|
||||
|
||||
@abc.abstractmethod
|
||||
def visit_function_result(self, function_result: FunctionResult) -> str:
|
||||
"""Render a function result."""
|
||||
|
||||
|
||||
class AstPrinter(Visitor):
|
||||
"""Print the AST."""
|
||||
|
||||
|
||||
class XMLEncoder(AstPrinter):
|
||||
def visit_function_definition(self, function_definition: FunctionDefinition) -> str:
|
||||
"""Render a function."""
|
||||
parameters_lines = []
|
||||
|
||||
for parameter in function_definition["parameters"]:
|
||||
parameters_lines.extend(
|
||||
[
|
||||
"<parameter>",
|
||||
f"<name>{parameter['name']}</name>",
|
||||
f"<type>{parameter['type']}</type>",
|
||||
f"<description>{parameter['description']}</description>",
|
||||
"</parameter>",
|
||||
]
|
||||
)
|
||||
lines = [
|
||||
"<function>",
|
||||
f"<function_name>{function_definition['name']}</function_name>",
|
||||
"<description>",
|
||||
f"{function_definition['description']}",
|
||||
"</description>",
|
||||
"<parameters>",
|
||||
*parameters_lines,
|
||||
"</parameters>",
|
||||
"<return_value>",
|
||||
f"<type>{function_definition['return_value']['type']}</type>",
|
||||
]
|
||||
if function_definition["return_value"].get("description"):
|
||||
lines.append(
|
||||
f"<description>{function_definition['return_value']['description']}"
|
||||
f"</description>"
|
||||
)
|
||||
|
||||
lines.extend(["</return_value>", "</function>"])
|
||||
return "\n".join(lines)
|
||||
|
||||
def visit_function_definitions(
|
||||
self, function_definitions: List[FunctionDefinition]
|
||||
) -> str:
|
||||
"""Render a function."""
|
||||
strs = [
|
||||
self.visit_function_definition(function_definition)
|
||||
for function_definition in function_definitions
|
||||
]
|
||||
return "<functions>\n" + "\n".join(strs) + "\n</functions>"
|
||||
|
||||
def visit_function_invocation(self, invocation: FunctionInvocation) -> str:
|
||||
"""Render a function invocation."""
|
||||
arguments_as_strings = [
|
||||
"<argument>\n"
|
||||
f"<name>{argument['name']}</name>\n"
|
||||
f"<value>{argument['value']}</value>\n"
|
||||
"</argument>\n"
|
||||
for argument in invocation["arguments"]
|
||||
]
|
||||
lines = ["<function_invocation>"]
|
||||
|
||||
if invocation.get("id"):
|
||||
lines.append(f"<id>{invocation['id']}</id>")
|
||||
|
||||
lines.extend(
|
||||
[
|
||||
f"<function_name>{invocation['name']}</function_name>\n"
|
||||
"<arguments>\n"
|
||||
f"{''.join(arguments_as_strings)}" # Already includes trailing newline
|
||||
"</arguments>\n"
|
||||
"</function_invocation>"
|
||||
]
|
||||
)
|
||||
return "\n".join(lines)
|
||||
|
||||
def visit_function_result(self, function_result: FunctionResult) -> str:
|
||||
"""Render a function result."""
|
||||
lines = [
|
||||
"<function_result>",
|
||||
]
|
||||
|
||||
if function_result.get("id"):
|
||||
lines.append(f"<id>{function_result['id']}</id>")
|
||||
|
||||
lines.append(f"<function_name>{function_result['name']}</function_name>")
|
||||
|
||||
if function_result["error"]:
|
||||
lines.extend(
|
||||
[
|
||||
f"<error>{function_result['error']}</error>",
|
||||
]
|
||||
)
|
||||
else:
|
||||
lines.append(
|
||||
f"<result>{function_result['result']}</result>",
|
||||
)
|
||||
|
||||
lines.append("</function_result>")
|
||||
|
||||
return "\n".join(lines)
|
||||
|
||||
|
||||
class TypeScriptEncoder(AstPrinter):
|
||||
def visit_function_definition(self, function_definition: FunctionDefinition) -> str:
|
||||
"""Render a function."""
|
||||
parameters_as_strings = [
|
||||
f"{parameter['name']}: {parameter['type']}"
|
||||
for parameter in function_definition["parameters"]
|
||||
]
|
||||
# Let's use JSdoc style comments
|
||||
# First the function description
|
||||
lines = [
|
||||
f"// {function_definition['description']}",
|
||||
# Then the parameter descriptions
|
||||
*[
|
||||
f"// @param {parameter['name']} {parameter['description']}"
|
||||
for parameter in function_definition["parameters"]
|
||||
],
|
||||
# Then the return value description
|
||||
f"// @returns {function_definition['return_value']['description']}",
|
||||
# Then the function definition
|
||||
f"function {function_definition['name']}("
|
||||
f"{', '.join(parameters_as_strings)}): "
|
||||
f"{function_definition['return_value']['type']};",
|
||||
]
|
||||
|
||||
# finally join
|
||||
function = "\n".join(lines)
|
||||
return function
|
||||
|
||||
def visit_function_definitions(
|
||||
self, function_definitions: List[FunctionDefinition]
|
||||
) -> str:
|
||||
"""Render a function."""
|
||||
strs = [
|
||||
self.visit_function_definition(function_definition)
|
||||
for function_definition in function_definitions
|
||||
]
|
||||
return "\n\n".join(strs)
|
||||
|
||||
def visit_function_invocation(self, invocation: FunctionInvocation) -> str:
|
||||
"""Render a function invocation."""
|
||||
arguments_as_strings = [
|
||||
f"{argument['name']}: {argument['value']}"
|
||||
for argument in invocation["arguments"]
|
||||
]
|
||||
lines = [f"{invocation['name']}(" f"{', '.join(arguments_as_strings)});"]
|
||||
return "\n".join(lines)
|
||||
|
||||
def visit_function_result(self, function_result: FunctionResult) -> str:
|
||||
"""Render a function result."""
|
||||
lines = []
|
||||
if function_result["error"]:
|
||||
lines.append(f"ERROR: {function_result['error']}")
|
||||
else:
|
||||
lines.append(f"> {function_result['result']}")
|
||||
if function_result.get("id"):
|
||||
lines.append(f"// ID: {function_result['id']}")
|
||||
return "\n".join(lines)
|
||||
@@ -1,86 +0,0 @@
|
||||
"""Factory for creating agents for the tool usage task."""
|
||||
from typing import Optional
|
||||
|
||||
from langchain.agents import AgentExecutor
|
||||
from langchain_core.runnables import Runnable, RunnableConfig
|
||||
|
||||
from langchain_benchmarks import RateLimiter, model_registry
|
||||
from langchain_benchmarks.schema import ToolUsageTask
|
||||
from langchain_benchmarks.tool_usage.agents.adapters import apply_agent_executor_adapter
|
||||
from langchain_benchmarks.tool_usage.agents.experimental.agent import create_agent
|
||||
from langchain_benchmarks.tool_usage.agents.experimental.parser import (
|
||||
GenericAgentParser,
|
||||
)
|
||||
|
||||
|
||||
class CustomAgentFactory:
|
||||
"""A factory for creating tool using agents.
|
||||
|
||||
A factory for agents that do not leverage any special JSON mode for
|
||||
function usage; instead all function invocation behavior is implemented solely
|
||||
through prompt engineering and parsing.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
task: ToolUsageTask,
|
||||
model: str,
|
||||
*,
|
||||
rate_limiter: Optional[RateLimiter] = None,
|
||||
) -> None:
|
||||
"""Create an agent factory for the given tool usage task.
|
||||
|
||||
Args:
|
||||
task: The task to create an agent factory for
|
||||
model: model name (check model_registry)
|
||||
rate_limiter: The rate limiter to use if provided
|
||||
"""
|
||||
if model not in model_registry:
|
||||
raise ValueError(f"Unknown model: {model}")
|
||||
self.task = task
|
||||
self.model = model
|
||||
self.rate_limiter = rate_limiter
|
||||
|
||||
def __call__(self) -> Runnable:
|
||||
if isinstance(self.model, str):
|
||||
registered_model = model_registry.get_model(self.model)
|
||||
if registered_model is None:
|
||||
raise ValueError(f"Unknown model: {self.model}")
|
||||
model = registered_model.get_model(model_params={"temperature": 0})
|
||||
else:
|
||||
model = self.model
|
||||
|
||||
def _add_task_instructions(
|
||||
input: dict, config: Optional[RunnableConfig] = None, **kwargs
|
||||
) -> dict:
|
||||
"""Add task instructions to the question."""
|
||||
if not isinstance(input, dict):
|
||||
raise ValueError(
|
||||
f"Expected input to be a dict with key `question`. "
|
||||
f"Found {type(input)}."
|
||||
)
|
||||
input = input.copy()
|
||||
input["question"] = (
|
||||
f"{self.task.instructions}\nWrite down your answer, "
|
||||
f"but do not explain it. Input: `{input['question']}`"
|
||||
)
|
||||
return input
|
||||
|
||||
env = self.task.create_environment()
|
||||
|
||||
agent = create_agent(
|
||||
model,
|
||||
env.tools,
|
||||
GenericAgentParser(wrapping_xml_tag="tool", require_closing_xml_tag=False),
|
||||
rate_limiter=self.rate_limiter,
|
||||
)
|
||||
executor = AgentExecutor(
|
||||
agent=agent,
|
||||
tools=env.tools,
|
||||
handle_parsing_errors=True,
|
||||
return_intermediate_steps=True,
|
||||
)
|
||||
|
||||
return _add_task_instructions | apply_agent_executor_adapter(
|
||||
executor, state_reader=env.read_state
|
||||
)
|
||||
@@ -1,122 +0,0 @@
|
||||
import ast
|
||||
import re
|
||||
from typing import Dict, Optional, Union
|
||||
|
||||
from langchain.agents import AgentOutputParser
|
||||
from langchain.pydantic_v1 import BaseModel, Field
|
||||
from langchain_core.agents import AgentAction, AgentActionMessageLog, AgentFinish
|
||||
from langchain_core.exceptions import OutputParserException
|
||||
from langchain_core.messages import AIMessage
|
||||
|
||||
|
||||
class _ToolInvocationRequest(BaseModel):
|
||||
"""Light-weight pydantic model for validating the raw tool invocation request.
|
||||
|
||||
The purpose of this model, is to make sure that whatever as parsed from
|
||||
the raw llm output has `tool_name` and potential `arguments` fields, and
|
||||
nothing else.
|
||||
"""
|
||||
|
||||
tool_name: str
|
||||
# OK parameterless tools which do not take arguments
|
||||
arguments: Optional[Dict] = Field(default_factory=dict)
|
||||
|
||||
|
||||
class GenericAgentParser(AgentOutputParser):
|
||||
"""A generalized parser that makes it easier to parameterize different parsing."""
|
||||
|
||||
wrapping_xml_tag: str
|
||||
"""The tag that wraps the function invocation request.
|
||||
|
||||
For example, if "tool", then the function invocation request should be wrapped
|
||||
in <tool>...</tool>.
|
||||
"""
|
||||
require_closing_xml_tag: bool = False
|
||||
"""Whether we should require a closing tag for the wrapping_xml_tag.
|
||||
|
||||
For example, if True, then the function invocation request should be wrapped
|
||||
"""
|
||||
|
||||
def parse(self, text: str) -> Union[AgentFinish, AgentAction]:
|
||||
"""Parse the output of the agent."""
|
||||
open_tag = f"<{self.wrapping_xml_tag}>"
|
||||
close_tag = f"</{self.wrapping_xml_tag}>"
|
||||
if open_tag in text:
|
||||
# This is a hack to make sure that </tool> is always present
|
||||
# in the output if <tool>. </tool> may be a stop sequence for the
|
||||
# language model, so depending on implementation
|
||||
# the stop sequence may be cut off.
|
||||
# There might be a better way to do this, but this works and
|
||||
# is simple.
|
||||
if not self.require_closing_xml_tag:
|
||||
text += close_tag
|
||||
|
||||
pattern = rf"{open_tag}(?P<invocation>.*?){close_tag}"
|
||||
match = re.search(pattern, text, re.DOTALL)
|
||||
if match:
|
||||
content = match.group("invocation").strip()
|
||||
return parse_invocation(content, self.wrapping_xml_tag)
|
||||
|
||||
return AgentFinish(
|
||||
log=text,
|
||||
return_values={
|
||||
"output": text,
|
||||
},
|
||||
)
|
||||
|
||||
|
||||
def parse_invocation(text: str, tag: str) -> AgentAction:
|
||||
"""Parse the content of the function invocation.
|
||||
|
||||
Args:
|
||||
text: The text to parse.
|
||||
tag: The tag that wraps the function invocation request.
|
||||
|
||||
Returns:
|
||||
An AgentAction that corresponds to the function invocation.
|
||||
|
||||
Raises:
|
||||
OutputParserException: If the parsing fails.
|
||||
|
||||
This exception is meant to be caught by the agent executor and
|
||||
handled appropriately to provide feedback to the LLM.
|
||||
"""
|
||||
ai_content = f"<{tag}>{text}</{tag}>\n"
|
||||
|
||||
try:
|
||||
result = ast.literal_eval(text)
|
||||
except BaseException as e:
|
||||
# Convert this to something controllable by the user.
|
||||
err_msg = (
|
||||
f"ERROR: Please use the format "
|
||||
f'<{tag}>{{"tool_name": $TOOL_NAME, "arguments": $ARGUMENTS}}</{tag}>\n'
|
||||
)
|
||||
|
||||
raise OutputParserException(
|
||||
error=e,
|
||||
llm_output=ai_content,
|
||||
observation=err_msg,
|
||||
send_to_llm=True,
|
||||
)
|
||||
|
||||
try:
|
||||
request = _ToolInvocationRequest.validate(result)
|
||||
except Exception as e: # Using broad exception since it's not just ValidationError
|
||||
# Can also raise DictError if result is not a dict.
|
||||
err_msg = (
|
||||
f"ERROR: Please use the format "
|
||||
f'<{tag}>{{"tool_name": $TOOL_NAME, "arguments": $ARGUMENTS}}</{tag}>\n'
|
||||
)
|
||||
raise OutputParserException(
|
||||
error=e,
|
||||
llm_output=ai_content,
|
||||
send_to_llm=True,
|
||||
observation=err_msg,
|
||||
)
|
||||
|
||||
return AgentActionMessageLog(
|
||||
message_log=[AIMessage(content=ai_content)],
|
||||
tool=request.tool_name,
|
||||
tool_input=request.arguments,
|
||||
log=f"\nInvoking {request.tool_name}: {request.arguments}\n\t",
|
||||
)
|
||||
@@ -1,42 +0,0 @@
|
||||
AGENT_INSTRUCTIONS_XML_FORMAT = """\
|
||||
In this environment you have access to a set of tools you can use to answer the user's question.
|
||||
|
||||
You may call them like this:
|
||||
<function_calls>
|
||||
<invoke>
|
||||
<tool_name>$TOOL_NAME</tool_name>
|
||||
<parameters>
|
||||
<$PARAMETER_NAME>$PARAMETER_VALUE</$PARAMETER_NAME>
|
||||
...
|
||||
</parameters>
|
||||
</invoke>
|
||||
</function_calls>
|
||||
|
||||
Here are the tools available:
|
||||
|
||||
{tool_description}
|
||||
""" # noqa: E501
|
||||
|
||||
_AGENT_INSTRUCTIONS_BLOB_STYLE = """\
|
||||
In this environment you have access to a set of tools you can use to answer the user's question.
|
||||
|
||||
Here are the tools available:
|
||||
|
||||
{tool_description}
|
||||
|
||||
You may call one tool at a time using a format that includes <tool> and </tool> tag.
|
||||
|
||||
Inside the tag the content is a python dictionary that uses python literals (e.g., numbers, strings, lists, dictionaries, etc.) to specify the tool invocation.
|
||||
|
||||
It must match the schema of the function as described in the tool description.
|
||||
"arguments" is a dictionary of the arguments to the function.
|
||||
|
||||
<tool>
|
||||
{{
|
||||
"tool_name": $TOOL_NAME,
|
||||
"arguments": $ARGUMENTS
|
||||
}}
|
||||
</tool>
|
||||
|
||||
If you do not know the answer use more tools. You can only take a single action at a time.\
|
||||
""" # noqa: E501
|
||||
@@ -1,57 +0,0 @@
|
||||
"""Utilities to extract information from langchain tools for use in prompts."""
|
||||
import inspect
|
||||
from textwrap import dedent
|
||||
from typing import List
|
||||
|
||||
from langchain.tools.base import StructuredTool
|
||||
|
||||
from langchain_benchmarks.tool_usage.agents.experimental.encoder import (
|
||||
FunctionDefinition,
|
||||
Parameter,
|
||||
)
|
||||
|
||||
# PUBLIC API
|
||||
|
||||
|
||||
def get_parameters_from_tool(tool: StructuredTool) -> List[Parameter]:
|
||||
"""Convert a langchain tool to a tool user tool."""
|
||||
schema = tool.args_schema.schema()
|
||||
|
||||
properties = schema["properties"]
|
||||
parameters = []
|
||||
# Is this needed or is string OK?
|
||||
type_adapter = {
|
||||
"string": "str", # str or string?
|
||||
"integer": "int",
|
||||
"number": "float",
|
||||
"boolean": "bool",
|
||||
}
|
||||
for key, value in properties.items():
|
||||
parameters.append(
|
||||
{
|
||||
"name": key,
|
||||
"type": type_adapter.get(value["type"], value["type"]),
|
||||
"description": value.get("description", ""),
|
||||
}
|
||||
)
|
||||
|
||||
return parameters
|
||||
|
||||
|
||||
#
|
||||
def convert_tool_to_function_definition(tool: StructuredTool) -> FunctionDefinition:
|
||||
"""Convert a langchain tool to a tool user tool."""
|
||||
# Here we re-inspect the underlying function to get the doc-string
|
||||
# since StructuredTool modifies it, but we want the raw one for maximum
|
||||
# flexibility.
|
||||
description = inspect.getdoc(tool.func)
|
||||
|
||||
parameters = get_parameters_from_tool(tool)
|
||||
return {
|
||||
"name": tool.name,
|
||||
"description": dedent(description),
|
||||
"parameters": parameters,
|
||||
"return_value": {
|
||||
"type": "Any",
|
||||
},
|
||||
}
|
||||
@@ -1,91 +0,0 @@
|
||||
"""Code for creating an agent factory for evaluating tool usage tasks."""
|
||||
from typing import Optional
|
||||
|
||||
from langchain.agents import AgentExecutor
|
||||
from langchain.agents.format_scratchpad import format_to_openai_functions
|
||||
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
|
||||
from langchain.schema.runnable import Runnable
|
||||
from langchain.tools.render import format_tool_to_openai_function
|
||||
|
||||
from langchain_benchmarks import rate_limiting
|
||||
from langchain_benchmarks.schema import ToolUsageTask
|
||||
from langchain_benchmarks.tool_usage.agents.adapters import apply_agent_executor_adapter
|
||||
|
||||
# PUBLIC API
|
||||
|
||||
|
||||
class OpenAIAgentFactory:
|
||||
def __init__(
|
||||
self,
|
||||
task: ToolUsageTask,
|
||||
*,
|
||||
model: str = "gpt-3.5-turbo-16k",
|
||||
rate_limiter: Optional[rate_limiting.RateLimiter] = None,
|
||||
) -> None:
|
||||
"""Create an OpenAI agent factory for the given task.
|
||||
|
||||
Args:
|
||||
task: The task to create an agent factory for.
|
||||
model: The model to use -- this must be an open AI model.
|
||||
rate_limiter: The rate limiter to use
|
||||
"""
|
||||
self.task = task
|
||||
self.model = model
|
||||
self.rate_limiter = rate_limiter
|
||||
|
||||
def create(self) -> Runnable:
|
||||
"""Agent Executor"""
|
||||
# For backwards compatibility
|
||||
return self()
|
||||
|
||||
def __call__(self) -> Runnable:
|
||||
model = ChatOpenAI(
|
||||
model=self.model,
|
||||
temperature=0,
|
||||
)
|
||||
|
||||
env = self.task.create_environment()
|
||||
|
||||
model = model.bind(
|
||||
functions=[format_tool_to_openai_function(t) for t in env.tools]
|
||||
)
|
||||
|
||||
if rate_limiting:
|
||||
# Rate limited model
|
||||
model = rate_limiting.with_rate_limit(model, self.rate_limiter)
|
||||
|
||||
prompt = ChatPromptTemplate.from_messages(
|
||||
[
|
||||
(
|
||||
"system",
|
||||
self.task.instructions,
|
||||
),
|
||||
("user", "{input}"),
|
||||
MessagesPlaceholder(variable_name="agent_scratchpad"),
|
||||
]
|
||||
)
|
||||
|
||||
runnable_agent = (
|
||||
{
|
||||
"input": lambda x: x["input"],
|
||||
"agent_scratchpad": lambda x: format_to_openai_functions(
|
||||
x["intermediate_steps"]
|
||||
),
|
||||
}
|
||||
| prompt
|
||||
| model
|
||||
| OpenAIFunctionsAgentOutputParser()
|
||||
)
|
||||
|
||||
runnable = AgentExecutor(
|
||||
agent=runnable_agent,
|
||||
tools=env.tools,
|
||||
handle_parsing_errors=True,
|
||||
return_intermediate_steps=True,
|
||||
)
|
||||
|
||||
# Returns `state` in the output if the environment has a state reader
|
||||
# makes sure that `output` is always in the output
|
||||
return apply_agent_executor_adapter(runnable, state_reader=env.read_state)
|
||||
@@ -0,0 +1,52 @@
|
||||
"""Factory for creating agents for the tool usage task."""
|
||||
from typing import Union
|
||||
|
||||
from langchain.agents.agent import (
|
||||
AgentExecutor,
|
||||
BaseMultiActionAgent,
|
||||
BaseSingleActionAgent,
|
||||
)
|
||||
from langchain_core.runnables import Runnable
|
||||
|
||||
from langchain_benchmarks.schema import ToolUsageTask
|
||||
from langchain_benchmarks.tool_usage.agents.adapters import apply_agent_executor_adapter
|
||||
from langchain_benchmarks.tool_usage.agents.base import AgentFactory
|
||||
|
||||
|
||||
class CustomRunnableAgentFactory(AgentFactory):
|
||||
"""A factory for creating tool using agents.
|
||||
|
||||
A factory for agents that do not leverage any special JSON mode for
|
||||
function usage; instead all function invocation behavior is implemented solely
|
||||
through prompt engineering and parsing.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
task: ToolUsageTask,
|
||||
agent: Union[Runnable, BaseSingleActionAgent, BaseMultiActionAgent],
|
||||
) -> None:
|
||||
"""Create an agent factory for the given tool usage task.
|
||||
|
||||
Note: The agent should not be stateful, as it will be reused across
|
||||
multiple runs.
|
||||
|
||||
Args:
|
||||
task: The task to create an agent factory for
|
||||
agent: The agent to use
|
||||
"""
|
||||
self.task = task
|
||||
self.agent = agent
|
||||
|
||||
def __call__(self) -> Runnable:
|
||||
env = self.task.create_environment()
|
||||
executor = AgentExecutor(
|
||||
agent=self.agent,
|
||||
tools=env.tools,
|
||||
handle_parsing_errors=True,
|
||||
return_intermediate_steps=True,
|
||||
)
|
||||
|
||||
return apply_agent_executor_adapter(
|
||||
executor, state_reader=env.read_state
|
||||
).with_config({"run_name": "Agent", "metadata": {"task": self.task.name}})
|
||||
@@ -0,0 +1,81 @@
|
||||
"""Factory for creating agents.
|
||||
|
||||
This is useful for agents that follow the standard LangChain tool format.
|
||||
"""
|
||||
from typing import Optional
|
||||
|
||||
from langchain.agents import AgentExecutor, create_tool_calling_agent
|
||||
from langchain_core.language_models import BaseChatModel
|
||||
from langchain_core.prompts import ChatPromptTemplate
|
||||
from langchain_core.runnables import Runnable
|
||||
|
||||
from langchain_benchmarks.rate_limiting import RateLimiter, with_rate_limit
|
||||
from langchain_benchmarks.schema import ToolUsageTask
|
||||
from langchain_benchmarks.tool_usage.agents.adapters import apply_agent_executor_adapter
|
||||
from langchain_benchmarks.tool_usage.agents.base import AgentFactory
|
||||
|
||||
|
||||
class StandardAgentFactory(AgentFactory):
|
||||
"""A standard agent factory.
|
||||
|
||||
Use this factory with chat models that support the standard LangChain tool
|
||||
calling API where the chat model populates the tool_calls attribute on AIMessage.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
task: ToolUsageTask,
|
||||
model: BaseChatModel,
|
||||
prompt: ChatPromptTemplate,
|
||||
*,
|
||||
rate_limiter: Optional[RateLimiter] = None,
|
||||
) -> None:
|
||||
"""Create an agent factory for the given tool usage task.
|
||||
|
||||
Args:
|
||||
task: The task to create an agent factory for
|
||||
model: chat model to use, must support tool usage
|
||||
prompt: This is a chat prompt at the moment.
|
||||
Must include an agent_scratchpad
|
||||
|
||||
For example,
|
||||
|
||||
ChatPromptTemplate.from_messages(
|
||||
[
|
||||
("system", "{instructions}"),
|
||||
("human", "{input}"),
|
||||
MessagesPlaceholder("agent_scratchpad"),
|
||||
]
|
||||
)
|
||||
rate_limiter: will be appended to the agent runnable
|
||||
"""
|
||||
self.task = task
|
||||
self.model = model
|
||||
self.prompt = prompt
|
||||
self.rate_limiter = rate_limiter
|
||||
|
||||
def __call__(self) -> Runnable:
|
||||
"""Call the factory to create Runnable agent."""
|
||||
|
||||
env = self.task.create_environment()
|
||||
|
||||
if "instructions" in self.prompt.input_variables:
|
||||
finalized_prompt = self.prompt.partial(instructions=self.task.instructions)
|
||||
else:
|
||||
finalized_prompt = self.prompt
|
||||
|
||||
agent = create_tool_calling_agent(self.model, env.tools, finalized_prompt)
|
||||
|
||||
if self.rate_limiter:
|
||||
agent = with_rate_limit(agent, self.rate_limiter)
|
||||
|
||||
executor = AgentExecutor(
|
||||
agent=agent,
|
||||
tools=env.tools,
|
||||
handle_parsing_errors=True,
|
||||
return_intermediate_steps=True,
|
||||
)
|
||||
|
||||
return apply_agent_executor_adapter(
|
||||
executor, state_reader=env.read_state
|
||||
).with_config({"run_name": "Agent", "metadata": {"task": self.task.name}})
|
||||
@@ -5,14 +5,16 @@ Requirements:
|
||||
* Agents must output "intermediate_steps" in their run outputs.
|
||||
* The dataset must have "expected_steps" in its outputs.
|
||||
"""
|
||||
from typing import Literal, Optional, Union
|
||||
import re
|
||||
from typing import Any, Literal, Optional, Union
|
||||
|
||||
from langchain.callbacks.manager import collect_runs
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.evaluation import EvaluatorType, load_evaluator
|
||||
from langchain.chains import LLMChain
|
||||
from langchain.evaluation import EvaluatorType, StringEvaluator, load_evaluator
|
||||
from langchain.evaluation.schema import StringEvaluator
|
||||
from langchain.smith import RunEvalConfig
|
||||
from langchain_core.language_models import BaseChatModel, BaseLanguageModel
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith.evaluation.evaluator import (
|
||||
EvaluationResult,
|
||||
EvaluationResults,
|
||||
@@ -20,7 +22,49 @@ from langsmith.evaluation.evaluator import (
|
||||
)
|
||||
from langsmith.schemas import Example, Run
|
||||
|
||||
from langchain_benchmarks.tool_usage.prompts import QA_TEMPLATE_FOR_MULTIVERSE_MATH
|
||||
from langchain_benchmarks.tool_usage.prompts import (
|
||||
QA_TEMPLATE_FOR_MULTIVERSE_MATH,
|
||||
QA_TEMPLATE_FOR_MULTIVERSE_MATH_WITHOUT_QUESTION,
|
||||
)
|
||||
|
||||
OutputEvaluation = Literal["qa", "qa_math", "none", "qa_math_without_question"]
|
||||
|
||||
|
||||
class QAMathEvaluator(StringEvaluator):
|
||||
"""An LLM-based relevance evaluator."""
|
||||
|
||||
def __init__(self, chat_model: BaseChatModel) -> None:
|
||||
"""Initialize the evaluator."""
|
||||
self.eval_chain = QA_TEMPLATE_FOR_MULTIVERSE_MATH_WITHOUT_QUESTION | chat_model
|
||||
|
||||
@property
|
||||
def evaluation_name(self) -> str:
|
||||
"""Return the name of the evaluator."""
|
||||
return "QAMathEvaluator"
|
||||
|
||||
@property
|
||||
def requires_reference(self) -> bool:
|
||||
return True
|
||||
|
||||
@property
|
||||
def requires_input(self) -> bool:
|
||||
return False
|
||||
|
||||
def _evaluate_strings(
|
||||
self,
|
||||
prediction: str,
|
||||
input: Optional[str] = None,
|
||||
reference: Optional[str] = None,
|
||||
**kwargs: Any,
|
||||
) -> dict:
|
||||
"""Evaluate the prediction against the reference."""
|
||||
result = self.eval_chain.invoke(
|
||||
{"answer": reference, "result": prediction}, **kwargs
|
||||
)
|
||||
if result.content.startswith("CORRECT"):
|
||||
return {"score": 1}
|
||||
else:
|
||||
return {"score": 0}
|
||||
|
||||
|
||||
def compare_outputs(
|
||||
@@ -90,11 +134,17 @@ def compare_outputs(
|
||||
if "output" in run_outputs and qa_evaluator:
|
||||
output = run_outputs["output"]
|
||||
with collect_runs() as cb:
|
||||
qa_results = qa_evaluator.evaluate_strings(
|
||||
prediction=output,
|
||||
reference=example_outputs["reference"],
|
||||
input=run_inputs["question"],
|
||||
)
|
||||
if isinstance(qa_evaluator, QAMathEvaluator):
|
||||
qa_results = qa_evaluator.evaluate_strings(
|
||||
prediction=output,
|
||||
reference=example_outputs["reference"],
|
||||
)
|
||||
else:
|
||||
qa_results = qa_evaluator.evaluate_strings(
|
||||
prediction=output,
|
||||
reference=example_outputs["reference"],
|
||||
input=run_inputs["question"],
|
||||
)
|
||||
results.append(
|
||||
EvaluationResult(
|
||||
key="correctness",
|
||||
@@ -137,6 +187,8 @@ class AgentTrajectoryEvaluator(RunEvaluator):
|
||||
llm=eval_llm,
|
||||
prompt=QA_TEMPLATE_FOR_MULTIVERSE_MATH,
|
||||
)
|
||||
elif output_evaluation == "qa_math_without_question":
|
||||
qa_evaluator = QAMathEvaluator(eval_llm)
|
||||
else:
|
||||
raise ValueError(
|
||||
f"output_evaluation must be one of 'qa' or 'none', "
|
||||
@@ -144,6 +196,7 @@ class AgentTrajectoryEvaluator(RunEvaluator):
|
||||
)
|
||||
|
||||
self.qa_evaluator = qa_evaluator
|
||||
self.output_evaluation = output_evaluation
|
||||
|
||||
def evaluate_run(
|
||||
self, run: Run, example: Optional[Example] = None
|
||||
@@ -181,7 +234,7 @@ class AgentTrajectoryEvaluator(RunEvaluator):
|
||||
def get_eval_config(
|
||||
*,
|
||||
eval_llm: Union[BaseLanguageModel, BaseChatModel, None] = None,
|
||||
output_evaluation: Literal["qa", "qa_math", "none"] = "qa",
|
||||
output_evaluation: OutputEvaluation = "qa",
|
||||
) -> RunEvalConfig:
|
||||
"""Get the default evaluator for the environment.
|
||||
|
||||
|
||||
@@ -22,3 +22,28 @@ GRADE:"""
|
||||
QA_TEMPLATE_FOR_MULTIVERSE_MATH = PromptTemplate(
|
||||
input_variables=["result", "answer"], template=MATH_TEMPLATE
|
||||
)
|
||||
|
||||
MATH_TEMPLATE_NO_QUESTION = """\
|
||||
Compare the INPUT_A and INPUT_B and determine whether the numeric result in them is the same.
|
||||
|
||||
If the result is the same, reply with CORRECT. If the result is different, reply with INCORRECT.
|
||||
|
||||
Example Format:
|
||||
INPUT_A: input_a here
|
||||
INPUT_B: input_b here
|
||||
COMPARISON: CORRECT or INCORRECT here
|
||||
|
||||
Ignore differences in punctuation and phrasing between the student answer and true answer, please only compare the first 4 decimal digits.
|
||||
|
||||
For instance if INPUT_A = 123.6751345 and INPUT_B = 123.6751456 you should return CORRECT, since the first 4 decimal points match.
|
||||
|
||||
Begin!
|
||||
|
||||
INPUT_A: {answer}
|
||||
INPUT_B: {result}
|
||||
COMPARISON:"""
|
||||
|
||||
# Version without the query
|
||||
QA_TEMPLATE_FOR_MULTIVERSE_MATH_WITHOUT_QUESTION = PromptTemplate(
|
||||
input_variables=["result", "answer"], template=MATH_TEMPLATE_NO_QUESTION
|
||||
)
|
||||
|
||||
@@ -127,38 +127,8 @@ def get_environment() -> ToolUsageEnvironment:
|
||||
)
|
||||
|
||||
|
||||
MULTIVERSE_MATH = ToolUsageTask(
|
||||
name="Multiverse Math",
|
||||
dataset_id="https://smith.langchain.com/public/594f9f60-30a0-49bf-b075-f44beabf546a/d",
|
||||
create_environment=get_environment,
|
||||
instructions=(
|
||||
"You are requested to solve math questions in an alternate "
|
||||
"mathematical universe. The operations have been altered to yield "
|
||||
"different results than expected. Do not guess the answer or rely on your "
|
||||
" innate knowledge of math. Use the provided tools to answer the question. "
|
||||
"While associativity and commutativity apply, distributivity does not. Answer "
|
||||
"the question using the fewest possible tools. Only include the numeric "
|
||||
"response without any clarifications."
|
||||
),
|
||||
description=(
|
||||
"""\
|
||||
An environment that contains a few basic math operations, but with altered results.
|
||||
|
||||
For example, multiplication of 5*3 will be re-interpreted as 5*3*1.1. \
|
||||
The basic operations retain some basic properties, such as commutativity, \
|
||||
associativity, and distributivity; however, the results are different than expected.
|
||||
|
||||
The objective of this task is to evaluate the ability to use the provided tools to \
|
||||
solve simple math questions and ignore any innate knowledge about math.
|
||||
"""
|
||||
),
|
||||
eval_params={
|
||||
"output_evaluation": "qa_math",
|
||||
},
|
||||
)
|
||||
|
||||
# Source dataset used to create the public dataset in LangSmith
|
||||
DATASET = [
|
||||
DATASET_TINY = [
|
||||
{
|
||||
"question": "Add 2 and 3",
|
||||
"answer": add(2, 3),
|
||||
@@ -193,14 +163,14 @@ DATASET = [
|
||||
"expected_steps": ["log", "multiply"],
|
||||
},
|
||||
{
|
||||
"question": "calculate 101 to the power of 0.5 to 4 digits of precision",
|
||||
"answer": round(power(101, 0.5), 4),
|
||||
"expected_steps": ["power", "round"],
|
||||
"question": "calculate 101 to the power of 0.5",
|
||||
"answer": power(101, 0.5),
|
||||
"expected_steps": ["power"],
|
||||
},
|
||||
{
|
||||
"question": (
|
||||
"ecoli divides every 20 minutes. How many cells will be "
|
||||
"there after 2 hours if we start with 5 cells?"
|
||||
"there after 2 hours (120 minutes) if we start with 5 cells?"
|
||||
),
|
||||
"answer": multiply(5, power(2, divide(120, 20))),
|
||||
"expected_steps": ["divide", "power", "multiply"],
|
||||
@@ -220,6 +190,128 @@ DATASET = [
|
||||
},
|
||||
]
|
||||
|
||||
DATASET = DATASET_TINY + [
|
||||
{
|
||||
"question": "evaluate negate(-131,778)",
|
||||
"answer": negate(-131_778),
|
||||
"expected_steps": ["negate"],
|
||||
},
|
||||
{
|
||||
"question": "what is the value of pi?",
|
||||
"answer": pi(),
|
||||
"expected_steps": ["pi"],
|
||||
},
|
||||
{
|
||||
"question": "what is cos(pi)?",
|
||||
"answer": cos(pi()),
|
||||
"expected_steps": ["pi", "cos"],
|
||||
},
|
||||
{
|
||||
"question": "how much is 131,778 divided by 2?",
|
||||
"answer": divide(131_778, 2),
|
||||
"expected_steps": ["divide"],
|
||||
},
|
||||
{
|
||||
"question": "131,778 + 22,312?",
|
||||
"answer": add(131_778, 22_312),
|
||||
"expected_steps": ["add"],
|
||||
},
|
||||
{
|
||||
"question": "(1+2) + 5",
|
||||
"answer": add(add(1, 2), 5),
|
||||
"expected_steps": ["add", "add"],
|
||||
},
|
||||
{
|
||||
"question": "-(1 + 1)",
|
||||
"answer": negate(add(1, 1)),
|
||||
"expected_steps": ["add", "negate"],
|
||||
},
|
||||
{
|
||||
"question": "Evaluate 1 + 2 + 3 + 4 + 5 using only the add function",
|
||||
"answer": add(add(add(add(1, 2), 3), 4), 5),
|
||||
"expected_steps": ["add", "add", "add", "add"],
|
||||
},
|
||||
{
|
||||
"question": "Evaluate the sum of the numbers 1 through 10 using only the add function",
|
||||
"answer": add(
|
||||
add(add(add(add(add(add(add(add(1, 2), 3), 4), 5), 6), 7), 8), 9), 10
|
||||
),
|
||||
"expected_steps": ["add"] * (10 - 1),
|
||||
},
|
||||
{
|
||||
"question": "Calculate 5 divided by 5",
|
||||
"answer": divide(5, 5),
|
||||
"expected_steps": ["divide"],
|
||||
},
|
||||
]
|
||||
|
||||
# Provided here for backwards compatibility, but we do not register
|
||||
# it as a task in the task registry.
|
||||
# TINY is just the multiverse math task with 10 examples instead of full dataset.
|
||||
MULTIVERSE_MATH_TINY = ToolUsageTask(
|
||||
name="Multiverse Math (Tiny)",
|
||||
dataset_id="https://smith.langchain.com/public/594f9f60-30a0-49bf-b075-f44beabf546a/d",
|
||||
create_environment=get_environment,
|
||||
instructions=(
|
||||
"You are requested to solve math questions in an alternate "
|
||||
"mathematical universe. The operations have been altered to yield "
|
||||
"different results than expected. Do not guess the answer or rely on your "
|
||||
" innate knowledge of math. Use the provided tools to answer the question. "
|
||||
"While associativity and commutativity apply, distributivity does not. Answer "
|
||||
"the question using the fewest possible tools. Only include the numeric "
|
||||
"response without any clarifications."
|
||||
),
|
||||
description=(
|
||||
"""\
|
||||
An environment that contains a few basic math operations, but with altered results.
|
||||
|
||||
For example, multiplication of 5*3 will be re-interpreted as 5*3*1.1. \
|
||||
The basic operations retain some basic properties, such as commutativity, \
|
||||
associativity, and distributivity; however, the results are different than expected.
|
||||
|
||||
The objective of this task is to evaluate the ability to use the provided tools to \
|
||||
solve simple math questions and ignore any innate knowledge about math.
|
||||
|
||||
This is a tiny version of the Multiverse Math task, with 10 examples only.
|
||||
"""
|
||||
),
|
||||
eval_params={
|
||||
"output_evaluation": "qa_math_without_question",
|
||||
},
|
||||
)
|
||||
|
||||
MULTIVERSE_MATH = ToolUsageTask(
|
||||
name="Multiverse Math",
|
||||
dataset_id="https://smith.langchain.com/public/47ed57bc-e852-4f84-a23e-cce4793864e9/d",
|
||||
create_environment=get_environment,
|
||||
instructions=(
|
||||
"You are requested to solve math questions in an alternate "
|
||||
"mathematical universe. The operations have been altered to yield "
|
||||
"different results than expected. Do not guess the answer or rely on your "
|
||||
" innate knowledge of math. Use the provided tools to answer the question. "
|
||||
"While associativity and commutativity apply, distributivity does not. Answer "
|
||||
"the question using the fewest possible tools. Only include the numeric "
|
||||
"response without any clarifications."
|
||||
),
|
||||
description=(
|
||||
"""\
|
||||
An environment that contains a few basic math operations, but with altered results.
|
||||
|
||||
For example, multiplication of 5*3 will be re-interpreted as 5*3*1.1. \
|
||||
The basic operations retain some basic properties, such as commutativity, \
|
||||
associativity, and distributivity; however, the results are different than expected.
|
||||
|
||||
The objective of this task is to evaluate the ability to use the provided tools to \
|
||||
solve simple math questions and ignore any innate knowledge about math.
|
||||
|
||||
This task is associated with 20 test examples.
|
||||
"""
|
||||
),
|
||||
eval_params={
|
||||
"output_evaluation": "qa_math_without_question",
|
||||
},
|
||||
)
|
||||
|
||||
|
||||
def _create_dataset() -> None:
|
||||
"""Create a dataset with the langsmith client."""
|
||||
|
||||
@@ -0,0 +1,996 @@
|
||||
from datetime import datetime
|
||||
from typing import List, Literal, Union, cast
|
||||
|
||||
from langchain.pydantic_v1 import BaseModel, Field
|
||||
from langchain.tools import BaseTool, tool
|
||||
from langchain_core.messages import HumanMessage
|
||||
from langsmith.client import Client
|
||||
|
||||
from langchain_benchmarks.schema import ToolUsageEnvironment, ToolUsageTask
|
||||
|
||||
|
||||
class DocQuery(BaseModel):
|
||||
"""Query against documentation"""
|
||||
|
||||
query: str = Field(..., description="The question to answer")
|
||||
source: Literal["langchain", "langsmith", "langgraph"] = Field(
|
||||
...,
|
||||
description="The documentation source to search against. Should be one of 'langchain', 'langsmith', or "
|
||||
"'langgraph' depending on which one product the user question pertains to",
|
||||
)
|
||||
|
||||
|
||||
class TweetQuery(BaseModel):
|
||||
"""Query against tweets"""
|
||||
|
||||
subject: str = Field(..., description="Subject to search for")
|
||||
min_likes: Union[int, None] = Field(
|
||||
None, description="Minimum amount of likes on the tweet"
|
||||
)
|
||||
max_likes: Union[int, None] = Field(
|
||||
None, description="Maximum amount of likes on the tweet"
|
||||
)
|
||||
start_date: Union[datetime, None] = Field(
|
||||
None, description="Earliest date to start pulling tweets from"
|
||||
)
|
||||
end_date: Union[datetime, None] = Field(
|
||||
None,
|
||||
description="Latest date to pull tweets from, None if pulling up to the present",
|
||||
)
|
||||
has_link: bool = Field(
|
||||
False, description="Whether to query for tweets that have a link."
|
||||
)
|
||||
|
||||
|
||||
class BlogQuery(BaseModel):
|
||||
"""Query against blog posts"""
|
||||
|
||||
subject: Union[str, None] = Field(..., description="Subject to search for")
|
||||
authors: List[str] = Field(
|
||||
None,
|
||||
description="Authors to search for. None if not searching for a speific author, list if searching for more than one.",
|
||||
)
|
||||
start_date: Union[datetime, None] = Field(
|
||||
None, description="Earliest date to start pulling blog posts from"
|
||||
)
|
||||
end_date: Union[datetime, None] = Field(
|
||||
None, description="Latest date to pull blog posts from"
|
||||
)
|
||||
|
||||
|
||||
def get_environment() -> ToolUsageEnvironment:
|
||||
"""Create an environment."""
|
||||
tools = cast(
|
||||
List[BaseTool],
|
||||
[tool(func) for func in [TweetQuery, DocQuery, BlogQuery]],
|
||||
)
|
||||
return ToolUsageEnvironment(
|
||||
tools=tools,
|
||||
read_state=None,
|
||||
)
|
||||
|
||||
|
||||
DOC_DATASET = [
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Can I use the send method to map-reduce the values of different branch points?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "send method map-reduce", "source": "langgraph"},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("where is olllama function calling mentioned?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "ollama function calling", "source": "langchain"},
|
||||
},
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "ollama function calling",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
"has_link": False,
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "ollama function calling",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage("Are pairwise evals supported for different models?")
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "pairwise evals different models",
|
||||
"source": "langsmith",
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("Can a user update state during a run?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "user update state", "source": "langgraph"},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("Can I change config after each AI response?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "update model config", "source": "langchain"},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"How can I build my own run rules? Can I set up a schedule for them?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "custom run rules", "source": "langsmith"},
|
||||
},
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "run rules schedule", "source": "langsmith"},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("Is there a page on routing functions?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "routing functions", "source": "langgraph"},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage("Is there information on using Pinecone as a vectorstore?")
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "Pinecone vectorstore",
|
||||
"source": "langchain",
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "Pinecone vectorstore",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("is it possible to prevent exposing personal data?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "personal data privacy", "source": "langsmith"},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("How do you use conditional entry?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "conditional entry", "source": "langgraph"},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"How do I extract text from PDF data using PyPDF? Can I combine image and text in a prompt?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "PDF extraction using PyPDF", "source": "langchain"},
|
||||
},
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "combine image and text in a prompt",
|
||||
"source": "langchain",
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"How do I setup automation rules for my chat model app? How do I view logs for those rules?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "automation rules for chat model app",
|
||||
"source": "langsmith",
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "automation rules logs", "source": "langsmith"},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage("where can I read about how use Chroma embeddings locally?")
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "local Chroma embeddings", "source": "langchain"},
|
||||
},
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "local Chroma embeddings",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("how to index documents in a RAG app?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "index documents RAG app", "source": "langchain"},
|
||||
},
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "index documents RAG app", "source": "langgraph"},
|
||||
},
|
||||
],
|
||||
},
|
||||
]
|
||||
|
||||
TWEET_DATASET = [
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Did we have any announcements about agents with more than 1000 likes that also included a link?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "agents",
|
||||
"min_likes": 1000,
|
||||
"max_likes": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
"has_link": True,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Are there any posts about evaluators by langchain with less than 100 likes?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "evaluators",
|
||||
"min_likes": None,
|
||||
"max_likes": 100,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
"has_link": False,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Is there anywhere on socials where we link to the anthropic website in the last year?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "anthropic",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": datetime(2023, 1, 1),
|
||||
"end_date": None,
|
||||
"has_link": True,
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "anthropic",
|
||||
"authors": None,
|
||||
"start_date": datetime(2023, 1, 1),
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("In Q2 2023 what updates to LangSmith were made?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "LangSmith",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": datetime(2023, 4, 1),
|
||||
"end_date": datetime(2023, 6, 30),
|
||||
"has_link": False,
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "LangSmith",
|
||||
"authors": None,
|
||||
"start_date": datetime(2023, 4, 1),
|
||||
"end_date": datetime(2023, 6, 30),
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Were there any social media posts with triple digit likes about few shot prompting?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "few shot prompting",
|
||||
"min_likes": 100,
|
||||
"max_likes": 999,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
"has_link": False,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Are there any posts about LangServe before June 2023 that have more than 2000 likes and include a link?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "LangServe",
|
||||
"min_likes": 2000,
|
||||
"max_likes": None,
|
||||
"start_date": None,
|
||||
"end_date": datetime(2023, 5, 31),
|
||||
"has_link": True,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
]
|
||||
|
||||
BLOG_DATASET = [
|
||||
{
|
||||
"question": [
|
||||
HumanMessage("Have there been release notes in the past year about agents?")
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "agents",
|
||||
"authors": None,
|
||||
"start_date": datetime(2023, 1, 1),
|
||||
"end_date": None,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"how many press releases mentioned chat-gpt in the month after October 2023?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "chat-gpt",
|
||||
"authors": None,
|
||||
"start_date": datetime(2023, 11, 1),
|
||||
"end_date": datetime(2023, 11, 30),
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "chat-gpt",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": datetime(2023, 11, 1),
|
||||
"end_date": datetime(2023, 11, 30),
|
||||
"has_link": False,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage("what has been said about universal configurable models?")
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "universal configurable models",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "universal configurable models",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
"has_link": False,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"In the last week, Have Harrison or Bagatur written anything about passing in runnables as tools in LangChain?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "runnables as tools",
|
||||
"authors": ["Harrison", "Bagatur"],
|
||||
"start_date": datetime(2023, 12, 25),
|
||||
"end_date": None,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Are there any case studies of agents running on swe-benchmark?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "agents running on swe-benchmark",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("Why is using fewshot prompting helpful?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "fewshot prompting",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "few shot prompting", "source": "langchain"},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"i need to implement similarity search with filtering in FAISS. how can i do that in my app?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "similarity search with FAISS",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
] # Realease notes/announcements + Case studies +
|
||||
|
||||
AMBIGUOUS_DATASET = [
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"I want to migrate from agentexecutor to langgraph. What do I need to do?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "migrate agentexecutor", "source": "langchain"},
|
||||
},
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "migrate agentexecutor", "source": "langgraph"},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"In the last month, what are the latest updates to the openai partner package?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "openai partner package",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": datetime(2023, 12, 1),
|
||||
"end_date": None,
|
||||
"has_link": False,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"What are best practices for setting up a document loader for a RAG chain?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "document loader for RAG chain",
|
||||
"source": "langchain",
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "document loader best practies",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("case studies using langgraph last week?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "langgraph case studies",
|
||||
"authors": None,
|
||||
"start_date": datetime(2023, 12, 25),
|
||||
"end_date": None,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
]
|
||||
|
||||
DATASET = DOC_DATASET + TWEET_DATASET + BLOG_DATASET + AMBIGUOUS_DATASET
|
||||
|
||||
QUERY_ANALYSIS_TASK = ToolUsageTask(
|
||||
name="Extraction Task",
|
||||
dataset_id="https://smith.langchain.com/public/594f9f60-30a0-49bf-b075-f44beabf546a/d",
|
||||
create_environment=get_environment,
|
||||
instructions=(
|
||||
"""
|
||||
You are requested to generate queries for searching either through tweets, docs, or blog entries.
|
||||
Inside the docs there are three different sources that you may wish to query for: LangGraph, LangSmith, or LangChain.
|
||||
LangGraph is a library for building multi-actor applications with LLMs, used to create agent and multi-agent workflows.
|
||||
LangSmith is an all-in-one developer platform for every step of the LLM-powered application lifecycle.
|
||||
It helps you debug, evaluate, test, and monitor your LLM applications. LangChain is a framework to build with LLMs by chaining interoperable components.
|
||||
One last important thing to remember is that some queries will ask for date ranges, and you must remember that today is 2024-01-01. Also, remember that \
|
||||
each question should be answered by a single query. In addition, you can return multiple queries to answer one question. Do not generate text, just tool calls that \
|
||||
if executed would answer the users question. Do NOT pass the whole question as the query/subject, only extract key ideas/words.
|
||||
"""
|
||||
),
|
||||
description=(
|
||||
"""\
|
||||
An environment that contains three different mock query tools for searching through LangChain material.
|
||||
|
||||
The three tools are for querying LangChain documentation, tweets, and blogs respectively.
|
||||
|
||||
The objective of the task it to measure how well the agent can select the correct tool and \
|
||||
select the right parameters for the query. It is not a test of the actual querying process, \
|
||||
merely the process of constructing the query.
|
||||
"""
|
||||
),
|
||||
eval_params={
|
||||
"output_evaluation": "qa_math_without_question",
|
||||
},
|
||||
)
|
||||
|
||||
FEW_SHOT_DATASET = [
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"What are good rules to follow when using multi modal chat models?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "multi modal chat models", "source": "langchain"},
|
||||
},
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "multi modal chat models",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage("How do you build a RAG chain with a Postgres vectorstore?")
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "RAG chain with Postgres vectorstore",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "RAG chain with Postgres vectorstore",
|
||||
"source": "langchain",
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage("What case studies have we written about tool usage?")
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "tool usage case study",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("How do I migrate from run_on_dataset to evaluate?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "migrate run_on_dataset to evaluate",
|
||||
"source": "langchain",
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "migrate run_on_dataset to evaluate",
|
||||
"source": "langsmith",
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Do any of our posts in the last 2 months about Anthropic have less than 100 likes?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "Anthropic",
|
||||
"min_likes": None,
|
||||
"max_likes": 100,
|
||||
"start_date": datetime(2023, 11, 1),
|
||||
"end_date": None,
|
||||
"has_link": True,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Did we release any information about claude-3.5 in the last week?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "claude-3.5",
|
||||
"authors": None,
|
||||
"start_date": datetime(2023, 12, 25),
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "claude-3.5",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": datetime(2023, 12, 25),
|
||||
"end_date": None,
|
||||
"has_link": False,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Do we have press statements about filtering traces by metadata before October 2023?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "filtering traces by metadata",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": datetime(2023, 9, 30),
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "filtering traces by metadata",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": None,
|
||||
"end_date": datetime(2023, 9, 30),
|
||||
"has_link": False,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"What updates to mistral partner package were posted in the last year?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "mistral partner package",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": datetime(2023, 1, 1),
|
||||
"end_date": None,
|
||||
"has_link": False,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Have there been updates to the best practices for initializing chat models in the past month?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "best practices for initializing chat models",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": datetime(2023, 12, 1),
|
||||
"end_date": None,
|
||||
"has_link": False,
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "best practices for initializing chat models",
|
||||
"authors": None,
|
||||
"start_date": datetime(2023, 12, 1),
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"How can I learn about the differences between chat agents and graphs"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "differences between chat agents and graphs",
|
||||
"source": "langchain",
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "differences between chat agents and graphs",
|
||||
"source": "langgraph",
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"What are good practices to follow for switching from legacy packages?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "switching from legacy packages",
|
||||
"source": "langchain",
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "switching from legacy packages",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("What data is exposed when I run custom evals?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "data exposed running custom evaluation",
|
||||
"source": "langsmith",
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("Where are document loaders talked about?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "document loaders", "source": "langchain"},
|
||||
},
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "document loaders",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
"has_link": False,
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "document loaders",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
]
|
||||
|
||||
|
||||
def _create_dataset(examples: list, dataset_id: str) -> None:
|
||||
"""Create a dataset with the langsmith client."""
|
||||
|
||||
client = Client()
|
||||
for example in examples:
|
||||
client.create_example(
|
||||
inputs={"question": example["question"]},
|
||||
outputs={"reference": example["tool_calls"]},
|
||||
dataset_id=dataset_id,
|
||||
)
|
||||
@@ -0,0 +1,3 @@
|
||||
from langchain_benchmarks.utils._langsmith import run_without_langsmith
|
||||
|
||||
__all__ = ["run_without_langsmith"]
|
||||
|
||||
@@ -1,14 +1,26 @@
|
||||
"""Copy the public dataset to your own langsmith tenant."""
|
||||
import functools
|
||||
import json
|
||||
import logging
|
||||
import threading
|
||||
import urllib.parse
|
||||
from pathlib import Path
|
||||
from typing import Optional, Tuple, Union
|
||||
from typing import Any, Callable, List, Optional, Tuple, Union, cast
|
||||
from uuid import UUID
|
||||
|
||||
from langsmith import Client
|
||||
from langchain.smith import RunEvalConfig
|
||||
from langchain.smith.evaluation import runner_utils as eval_runner_utils
|
||||
from langchain_core import runnables
|
||||
from langchain_core.runnables import config as runnable_config
|
||||
from langchain_core.tracers.root_listeners import RootListenersTracer
|
||||
from langsmith import Client, EvaluationResult
|
||||
from langsmith.evaluation.evaluator import EvaluationResults
|
||||
from langsmith.schemas import DataType, Example, Run
|
||||
from langsmith.utils import LangSmithNotFoundError
|
||||
from tqdm import auto
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
API_URL = "https://api.smith.langchain.com/"
|
||||
|
||||
|
||||
@@ -133,3 +145,167 @@ def exists_public_dataset(token_or_url: str, *, api_url: str = API_URL) -> bool:
|
||||
|
||||
finally:
|
||||
del source_client
|
||||
|
||||
|
||||
def _select_eval_results(
|
||||
results: Union[EvaluationResult, EvaluationResults],
|
||||
) -> List[EvaluationResult]:
|
||||
if isinstance(results, EvaluationResult):
|
||||
results_ = [results]
|
||||
elif isinstance(results, dict) and "results" in results:
|
||||
results_ = cast(List[EvaluationResult], results["results"])
|
||||
else:
|
||||
raise TypeError(
|
||||
f"Invalid evaluation result type {type(results)}."
|
||||
" Expected EvaluationResult or EvaluationResults."
|
||||
)
|
||||
return results_
|
||||
|
||||
|
||||
def _is_jupyter_environment() -> bool:
|
||||
try:
|
||||
from IPython import get_ipython
|
||||
|
||||
res = get_ipython()
|
||||
return get_ipython() is not None and "zmqshell" in str(type(res))
|
||||
except ImportError:
|
||||
return False
|
||||
|
||||
|
||||
def _display_aggregate_results(aggregate_results: Any) -> None:
|
||||
if _is_jupyter_environment():
|
||||
from IPython.display import HTML, display
|
||||
|
||||
display(HTML("<h3>Experiment Results:</h3>"))
|
||||
display(aggregate_results)
|
||||
else:
|
||||
formatted_string = aggregate_results.to_string(
|
||||
float_format=lambda x: f"{x:.2f}", justify="right"
|
||||
)
|
||||
print("\n Experiment Results:")
|
||||
print(formatted_string)
|
||||
|
||||
|
||||
def run_without_langsmith(
|
||||
path_or_token_id: Union[str, Path],
|
||||
llm_or_chain_factory: Union[
|
||||
Callable[[], runnables.Runnable], Callable[[dict], Any]
|
||||
],
|
||||
*,
|
||||
evaluation: Optional[RunEvalConfig] = None,
|
||||
concurrency_level: int = 5,
|
||||
verbose: bool = True,
|
||||
) -> None:
|
||||
"""Run a public dataset without langsmith."""
|
||||
from langchain.smith.evaluation.runner_utils import (
|
||||
_setup_evaluation,
|
||||
_wrap_in_chain_factory,
|
||||
)
|
||||
|
||||
if isinstance(path_or_token_id, Path) or path_or_token_id.endswith(".json"):
|
||||
dataset_path = path_or_token_id
|
||||
else:
|
||||
_, token_uuid = _parse_token_or_url(path_or_token_id, API_URL)
|
||||
dataset_path = f"{token_uuid}.json"
|
||||
if not Path(dataset_path).exists():
|
||||
download_public_dataset(path_or_token_id, path=dataset_path)
|
||||
if not dataset_path.endswith(".json"):
|
||||
raise ValueError(f"Unrecognized dataset path: {path_or_token_id}")
|
||||
with open(str(dataset_path), encoding="utf-8") as f:
|
||||
example_dicts = json.load(f)
|
||||
examples = [Example(**example_dict) for example_dict in example_dicts]
|
||||
wrapped_model = _wrap_in_chain_factory(llm_or_chain_factory)
|
||||
run_evaluators = _setup_evaluation(
|
||||
llm_or_chain_factory=wrapped_model,
|
||||
examples=examples,
|
||||
evaluation=evaluation,
|
||||
data_type=DataType.kv,
|
||||
)
|
||||
|
||||
all_eval_results = {}
|
||||
results_lock = threading.RLock()
|
||||
_progress_bar = iter(
|
||||
auto.tqdm(
|
||||
iterable=range(len(examples)),
|
||||
desc="Running Evaluation",
|
||||
unit="example",
|
||||
total=len(examples),
|
||||
)
|
||||
)
|
||||
|
||||
def _evaluate_run(run: Run, example: Example):
|
||||
with results_lock:
|
||||
next(_progress_bar)
|
||||
example_result = all_eval_results.setdefault(str(example.id), {}) or {}
|
||||
example_result.update(
|
||||
{
|
||||
"input": run.inputs,
|
||||
"execution_time": (
|
||||
(run.end_time - run.start_time).total_seconds()
|
||||
if run.end_time
|
||||
else None
|
||||
),
|
||||
"run_id": str(run.id),
|
||||
}
|
||||
)
|
||||
if run.error is not None:
|
||||
example_result["Error"] = run.error
|
||||
else:
|
||||
example_result["output"] = run.outputs
|
||||
all_eval_results[str(example.id)] = example_result
|
||||
if run_evaluators is None:
|
||||
return
|
||||
feedback = []
|
||||
for evaluator in run_evaluators:
|
||||
try:
|
||||
eval_results = evaluator.evaluate_run(run, example)
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to evaluate run {run.id}: {repr(e)}")
|
||||
continue
|
||||
flattened = _select_eval_results(eval_results)
|
||||
feedback.extend(flattened)
|
||||
|
||||
with results_lock:
|
||||
example_result = all_eval_results.setdefault(str(example.id), {}) or {}
|
||||
example_result.update(
|
||||
{
|
||||
"feedback": feedback,
|
||||
}
|
||||
)
|
||||
all_eval_results[str(example.id)] = example_result
|
||||
|
||||
configs = [
|
||||
runnable_config.RunnableConfig(
|
||||
callbacks=[
|
||||
RootListenersTracer(
|
||||
config={},
|
||||
on_start=None,
|
||||
on_end=functools.partial(_evaluate_run, example=example),
|
||||
on_error=functools.partial(_evaluate_run, example=example),
|
||||
),
|
||||
],
|
||||
max_concurrency=concurrency_level,
|
||||
)
|
||||
for example in examples
|
||||
]
|
||||
|
||||
def run_runnable(x: dict) -> Any:
|
||||
model = wrapped_model()
|
||||
return model.invoke(x)
|
||||
|
||||
runnables.RunnableLambda(run_runnable).batch(
|
||||
inputs=[example.inputs for example in examples],
|
||||
config=configs,
|
||||
return_exceptions=True,
|
||||
)
|
||||
results = eval_runner_utils.TestResult(
|
||||
project_name="Local",
|
||||
results=all_eval_results,
|
||||
)
|
||||
if verbose:
|
||||
try:
|
||||
agg_feedback = results.get_aggregate_feedback()
|
||||
_display_aggregate_results(agg_feedback)
|
||||
except Exception as e:
|
||||
logger.debug(f"Failed to print aggregate feedback: {repr(e)}")
|
||||
return results
|
||||
|
||||
Generated
+2422
-1617
File diff suppressed because it is too large
Load Diff
+23
-5
@@ -1,6 +1,6 @@
|
||||
[tool.poetry]
|
||||
name = "langchain-benchmarks"
|
||||
version = "0.0.9"
|
||||
version = "0.0.14"
|
||||
description = "🦜💪 Flex those feathers!"
|
||||
authors = ["LangChain AI"]
|
||||
license = "MIT"
|
||||
@@ -8,21 +8,34 @@ readme = "README.md"
|
||||
|
||||
[tool.poetry.dependencies]
|
||||
python = "^3.8.1"
|
||||
langchain = ">=0.0.300"
|
||||
langsmith = ">=0.0.66"
|
||||
langchain = "^0.2.7"
|
||||
langchain-community = "^0.2"
|
||||
langsmith = ">=0.0.70"
|
||||
tqdm = "^4"
|
||||
ipywidgets = "^8"
|
||||
tabulate = ">=0.8.0"
|
||||
langchain-openai = "^0.1.14"
|
||||
|
||||
[tool.poetry.group.dev]
|
||||
optional = true
|
||||
|
||||
[tool.poetry.group.dev.dependencies]
|
||||
jupyterlab = "^3.6.1"
|
||||
jupyter = "^1.0.0"
|
||||
|
||||
[tool.poetry.group.typing]
|
||||
optional = true
|
||||
|
||||
[tool.poetry.group.typing.dependencies]
|
||||
mypy = "^1.7.0"
|
||||
[tool.poetry.group.lint]
|
||||
optional = true
|
||||
|
||||
[tool.poetry.group.lint.dependencies]
|
||||
ruff = "^0.1.5"
|
||||
|
||||
[tool.poetry.group.docs]
|
||||
optional = true
|
||||
|
||||
[tool.poetry.group.docs.dependencies]
|
||||
nbsphinx = ">=0.8.9"
|
||||
sphinx = ">=5.2.0"
|
||||
@@ -32,6 +45,8 @@ myst-nb = { version = "^1.0.0", python = "^3.9" }
|
||||
toml = "^0.10.2"
|
||||
sphinx-copybutton = ">=0.5.1"
|
||||
|
||||
[tool.poetry.group.test]
|
||||
optional = true
|
||||
|
||||
[tool.poetry.group.test.dependencies]
|
||||
pytest = "^7.2.1"
|
||||
@@ -42,7 +57,10 @@ pytest-socket = "^0.6.0"
|
||||
pytest-watch = "^4.2.0"
|
||||
pytest-timeout = "^2.2.0"
|
||||
freezegun = "^1.3.1"
|
||||
|
||||
langchain-anthropic = "^0.1.19"
|
||||
langchain-fireworks = "^0.1.4"
|
||||
langchain-mistralai = "^0.1.9"
|
||||
langchain-groq = "^0.1.6"
|
||||
|
||||
[tool.ruff]
|
||||
select = [
|
||||
|
||||
@@ -0,0 +1,192 @@
|
||||
import datetime
|
||||
import sys
|
||||
import uuid
|
||||
|
||||
from langchain_core.messages import HumanMessage, SystemMessage, ToolMessage
|
||||
from langchain_core.messages.utils import convert_to_messages
|
||||
from langsmith.client import Client
|
||||
|
||||
from langchain_benchmarks import __version__
|
||||
|
||||
sys.path.append("./../langchain_benchmarks")
|
||||
from langchain.agents import AgentExecutor, create_tool_calling_agent
|
||||
from langchain.chat_models import init_chat_model
|
||||
from langsmith.evaluation import evaluate
|
||||
from tool_usage.tasks.multiverse_math import *
|
||||
|
||||
tests = [
|
||||
(
|
||||
"claude-3-haiku-20240307",
|
||||
"anthropic",
|
||||
),
|
||||
(
|
||||
"claude-3-sonnet-20240229",
|
||||
"anthropic",
|
||||
),
|
||||
(
|
||||
"claude-3-opus-20240229",
|
||||
"anthropic",
|
||||
),
|
||||
(
|
||||
"claude-3-5-sonnet-20240620",
|
||||
"anthropic",
|
||||
),
|
||||
("gpt-3.5-turbo-0125", "openai"),
|
||||
(
|
||||
"gpt-4o",
|
||||
"openai",
|
||||
),
|
||||
("gpt-4o-mini", "openai"),
|
||||
]
|
||||
|
||||
client = Client() # Launch langsmith client for cloning datasets
|
||||
|
||||
|
||||
def get_few_shot_messages(task_name):
|
||||
if task_name == "Multiverse Math":
|
||||
uncleaned_examples = [
|
||||
e
|
||||
for e in client.list_examples(
|
||||
dataset_name="multiverse-math-examples-for-few-shot"
|
||||
)
|
||||
]
|
||||
few_shot_messages = []
|
||||
few_shot_three_messages = []
|
||||
examples = []
|
||||
for i in range(len(uncleaned_examples)):
|
||||
converted_messages = convert_to_messages(
|
||||
uncleaned_examples[i].outputs["output"]
|
||||
)
|
||||
examples.append(
|
||||
# The message at index 1 is the human message asking the actual math question (0th message is system prompt)
|
||||
{
|
||||
"question": converted_messages[1].content,
|
||||
"messages": [
|
||||
m
|
||||
for m in converted_messages
|
||||
if isinstance(m, SystemMessage) == False
|
||||
],
|
||||
}
|
||||
)
|
||||
few_shot_messages += converted_messages
|
||||
if i < 3:
|
||||
few_shot_three_messages += converted_messages
|
||||
|
||||
return (
|
||||
examples,
|
||||
[m for m in few_shot_messages if not isinstance(m, SystemMessage)],
|
||||
[m for m in few_shot_three_messages if not isinstance(m, SystemMessage)],
|
||||
)
|
||||
else:
|
||||
raise ValueError("Few shot messages not supported for this dataset")
|
||||
|
||||
|
||||
def turn_messages_to_str(few_shot_messages):
|
||||
few_shot_str = ""
|
||||
for m in few_shot_messages:
|
||||
if isinstance(m.content, list):
|
||||
few_shot_str += "<|im_start|>assistant"
|
||||
for tool_use in m.content:
|
||||
if "name" in tool_use:
|
||||
few_shot_str += f"Use tool {tool_use['name']}, input: {', '.join(f'{k}:{v}' for k,v in tool_use['input'].items())}"
|
||||
else:
|
||||
few_shot_str += tool_use["text"]
|
||||
few_shot_str += "\n"
|
||||
few_shot_str += "\n<|im_end|>"
|
||||
else:
|
||||
if isinstance(m, HumanMessage):
|
||||
few_shot_str += f"<|im_start|>user\n{m.content}\n<|im_end|>"
|
||||
elif isinstance(m, ToolMessage):
|
||||
few_shot_str += f"<|im_start|>tool\n{m.content}\n<|im_end|>"
|
||||
else:
|
||||
few_shot_str += f"<|im_start|>assistant\n{m.content}\n<|im_end|>"
|
||||
|
||||
few_shot_str += "\n"
|
||||
return few_shot_str
|
||||
|
||||
|
||||
def get_few_shot_str_from_messages(few_shot_messages, few_shot_three_messages):
|
||||
few_shot_str = turn_messages_to_str(few_shot_messages)
|
||||
few_shot_three_str = turn_messages_to_str(few_shot_three_messages)
|
||||
return few_shot_str, few_shot_three_str
|
||||
|
||||
|
||||
def get_prompts(task_name, **kwargs):
|
||||
if task_name == "Multiverse Math":
|
||||
return [
|
||||
(
|
||||
client.pull_prompt("langchain-ai/multiverse-math-no-few-shot"),
|
||||
"no-few-shot",
|
||||
),
|
||||
(
|
||||
client.pull_prompt("langchain-ai/multiverse-math-few-shot-messages"),
|
||||
"few-shot-messages",
|
||||
),
|
||||
(
|
||||
client.pull_prompt("langchain-ai/multiverse-math-few-shot-str"),
|
||||
"few-shot-string",
|
||||
),
|
||||
(
|
||||
client.pull_prompt("langchain-ai/multiverse-math-few-shot-3-messages"),
|
||||
"few-shot-three-messages",
|
||||
),
|
||||
(
|
||||
client.pull_prompt("langchain-ai/multiverse-math-few-shot-3-str"),
|
||||
"few-shot-three-strings",
|
||||
),
|
||||
]
|
||||
|
||||
|
||||
def predict_from_callable(callable, instructions):
|
||||
def predict(run):
|
||||
return callable.invoke(
|
||||
{"question": run["question"], "instructions": instructions}
|
||||
)
|
||||
|
||||
return predict
|
||||
|
||||
|
||||
experiment_uuid = uuid.uuid4().hex[:4]
|
||||
today = datetime.date.today().isoformat()
|
||||
|
||||
task = MULTIVERSE_MATH
|
||||
dataset_name = task.name
|
||||
examples, few_shot_messages, few_shot_three_messages = get_few_shot_messages(task.name)
|
||||
few_shot_str, few_shot_three_str = get_few_shot_str_from_messages(
|
||||
few_shot_messages, few_shot_three_messages
|
||||
)
|
||||
|
||||
prompts = get_prompts(
|
||||
task.name,
|
||||
examples=examples,
|
||||
few_shot_three_messages=few_shot_three_messages,
|
||||
few_shot_three_str=few_shot_three_str,
|
||||
)
|
||||
|
||||
for model_name, model_provider in tests:
|
||||
model = init_chat_model(model_name, model_provider=model_provider, temperature=0)
|
||||
|
||||
print(f"Benchmarking {task.name} with model: {model_name}")
|
||||
eval_config = task.get_eval_config()
|
||||
|
||||
for prompt, prompt_name in prompts:
|
||||
tools = task.create_environment().tools
|
||||
agent = create_tool_calling_agent(model, tools, prompt)
|
||||
agent_executor = AgentExecutor(
|
||||
agent=agent, tools=tools, return_intermediate_steps=True
|
||||
)
|
||||
|
||||
evaluate(
|
||||
predict_from_callable(agent_executor, task.instructions),
|
||||
data=dataset_name,
|
||||
evaluators=eval_config.custom_evaluators,
|
||||
max_concurrency=5,
|
||||
metadata={
|
||||
"model": model_name,
|
||||
"id": experiment_uuid,
|
||||
"task": task.name,
|
||||
"date": today,
|
||||
"langchain_benchmarks_version": __version__,
|
||||
},
|
||||
experiment_prefix=f"{model_name}-{task.name}-{prompt_name}",
|
||||
)
|
||||
@@ -0,0 +1,331 @@
|
||||
import uuid
|
||||
from collections import Counter
|
||||
from datetime import datetime
|
||||
from typing import Optional
|
||||
|
||||
from langchain.chat_models import init_chat_model
|
||||
from langchain_community.vectorstores import FAISS
|
||||
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
|
||||
from langchain_core.messages import AIMessage, HumanMessage, ToolMessage
|
||||
from langchain_core.output_parsers import StrOutputParser
|
||||
from langchain_core.prompts import (
|
||||
ChatPromptTemplate,
|
||||
FewShotChatMessagePromptTemplate,
|
||||
MessagesPlaceholder,
|
||||
)
|
||||
from langchain_openai import OpenAIEmbeddings
|
||||
from langsmith.client import Client
|
||||
from langsmith.evaluation import evaluate
|
||||
from langsmith.evaluation.evaluator import EvaluationResult, EvaluationResults
|
||||
from langsmith.schemas import Example, Run
|
||||
|
||||
from langchain_benchmarks.tool_usage.tasks.query_analysis import (
|
||||
QUERY_ANALYSIS_TASK,
|
||||
BlogQuery,
|
||||
DocQuery,
|
||||
TweetQuery,
|
||||
)
|
||||
|
||||
|
||||
def calculate_recall(A, B):
|
||||
# Count the occurrences of each element in A and B
|
||||
count_A = Counter(A)
|
||||
count_B = Counter(B)
|
||||
|
||||
# Calculate the number of true positives
|
||||
true_positives = sum(min(count_A[elem], count_B.get(elem, 0)) for elem in count_A)
|
||||
|
||||
# Calculate recall
|
||||
recall = true_positives / sum(count_A.values()) if count_A else 0
|
||||
|
||||
return recall
|
||||
|
||||
|
||||
client = Client()
|
||||
|
||||
|
||||
def is_iso_format(date_str):
|
||||
if not isinstance(date_str, str):
|
||||
return False
|
||||
try:
|
||||
# Try to parse the string with datetime.fromisoformat
|
||||
datetime.fromisoformat(date_str)
|
||||
return True
|
||||
except ValueError:
|
||||
return False
|
||||
|
||||
|
||||
llm_judge = init_chat_model("gpt-4o")
|
||||
|
||||
judge_prompt = ChatPromptTemplate.from_messages(
|
||||
[
|
||||
(
|
||||
"system",
|
||||
"You are an llm tasked with determining if the subject extracted by another LLM is an accurate "
|
||||
"representation of the correct answer. You are to check for general semantic similarity since the words might not "
|
||||
"match up perfectly but the meaning might still be the same. Return YES if the answers match, and NO otherwise. "
|
||||
"Never return anything other than YES or NO.",
|
||||
),
|
||||
(
|
||||
"human",
|
||||
"Is this query: {run_query} somewhat similar to this reference query: {reference_query}",
|
||||
),
|
||||
]
|
||||
)
|
||||
|
||||
judge_chain = judge_prompt | llm_judge | StrOutputParser()
|
||||
|
||||
tools = [DocQuery, TweetQuery, BlogQuery]
|
||||
|
||||
|
||||
def compare_outputs(run_outputs: dict, example_outputs: dict) -> EvaluationResults:
|
||||
if len(run_outputs["response"].tool_calls) == 0:
|
||||
correct_tool_score, deterministic_score, nondeterministic_score = 0, 0, 0
|
||||
else:
|
||||
# Chose the correct tool
|
||||
reference_tools = [tool["name"] for tool in example_outputs["reference"]]
|
||||
outputted_tools = [tool["name"] for tool in run_outputs["response"].tool_calls]
|
||||
correct_tool_score = calculate_recall(reference_tools, outputted_tools)
|
||||
|
||||
# Has the correct deterministic args
|
||||
deterministic_score = 0
|
||||
# Has the correct in-deterministic args
|
||||
nondeterministic_score = 0
|
||||
|
||||
if correct_tool_score == 1:
|
||||
deterministic_score, nondeterministic_score = 1, 1
|
||||
for tool in example_outputs["reference"]:
|
||||
corresponding_response_tool = [
|
||||
t
|
||||
for t in run_outputs["response"].tool_calls
|
||||
if t["name"] == tool["name"]
|
||||
][0]["args"]
|
||||
for arg in tool["args"]:
|
||||
if arg in ["query", "subject"]:
|
||||
ans = judge_chain.invoke(
|
||||
{
|
||||
"run_query": corresponding_response_tool[arg],
|
||||
"reference_query": tool["args"][arg],
|
||||
}
|
||||
)
|
||||
nondeterministic_score = 1 if ans == "YES" else 0
|
||||
else:
|
||||
if (
|
||||
tool["args"][arg] and arg not in corresponding_response_tool
|
||||
) or (
|
||||
tool["args"][arg]
|
||||
and not (
|
||||
tool["args"][arg] == corresponding_response_tool[arg]
|
||||
)
|
||||
and not (
|
||||
is_iso_format(tool["args"][arg])
|
||||
and is_iso_format(corresponding_response_tool[arg])
|
||||
and datetime.fromisoformat(
|
||||
(corresponding_response_tool[arg])
|
||||
).replace(tzinfo=None)
|
||||
== datetime.fromisoformat(tool["args"][arg])
|
||||
)
|
||||
):
|
||||
deterministic_score = 0
|
||||
# Overall correctness
|
||||
overall_score = int(
|
||||
correct_tool_score == 1
|
||||
and bool(deterministic_score)
|
||||
and bool(nondeterministic_score)
|
||||
)
|
||||
results = [
|
||||
EvaluationResult(
|
||||
key="Correct tool",
|
||||
score=correct_tool_score,
|
||||
),
|
||||
EvaluationResult(
|
||||
key="Correct deterministic args",
|
||||
score=deterministic_score,
|
||||
),
|
||||
EvaluationResult(
|
||||
key="Correct nondeterministic args",
|
||||
score=nondeterministic_score,
|
||||
),
|
||||
EvaluationResult(
|
||||
key="Overall correctness",
|
||||
score=overall_score,
|
||||
),
|
||||
]
|
||||
|
||||
return {"results": results}
|
||||
|
||||
|
||||
def evaluate_run(run: Run, example: Optional[Example] = None) -> EvaluationResults:
|
||||
return compare_outputs(run.outputs, example.outputs)
|
||||
|
||||
|
||||
uncleaned_examples = [
|
||||
e for e in client.list_examples(dataset_name="Extraction Task Few Shot")
|
||||
]
|
||||
static_indices = [0, 2, 5]
|
||||
few_shot_messages, few_shot_str = [], ""
|
||||
few_shot_messages_by_index = {}
|
||||
examples_for_semantic_search = []
|
||||
|
||||
for j, example in enumerate(uncleaned_examples):
|
||||
few_shot_messages_for_example = []
|
||||
few_shot_messages_for_example.append(
|
||||
HumanMessage(
|
||||
name="example_human", content=example.inputs["question"][0]["content"]
|
||||
)
|
||||
)
|
||||
few_shot_messages_for_example.append(
|
||||
AIMessage(
|
||||
name="example_assistant",
|
||||
content="",
|
||||
tool_calls=[
|
||||
{
|
||||
"name": tc["name"],
|
||||
"args": tc["args"],
|
||||
"type": "tool_call",
|
||||
"id": f"{10*j+i}",
|
||||
}
|
||||
for i, tc in enumerate(example.outputs["reference"])
|
||||
],
|
||||
)
|
||||
)
|
||||
few_shot_str += (
|
||||
f"<|im_start|>user\n{example.inputs['question'][0]['content']}\n<|im_end|>"
|
||||
)
|
||||
few_shot_str += "\n<|im_start|>assistant\n"
|
||||
for i, tool_call in enumerate(example.outputs["reference"]):
|
||||
few_shot_messages_for_example.append(
|
||||
ToolMessage(
|
||||
"You have correctly called this tool",
|
||||
name=tool_call["name"],
|
||||
tool_call_id=f"{10*j+i}",
|
||||
)
|
||||
)
|
||||
few_shot_str += f"Tool Call: Name: {tool_call['name']} Args: {{{', '.join(f'{k}: {v}' for k,v in tool_call['args'].items())}}}"
|
||||
few_shot_str += "\n"
|
||||
few_shot_str += "<|im_end|>"
|
||||
|
||||
few_shot_messages += few_shot_messages_for_example
|
||||
few_shot_messages_by_index[j] = few_shot_messages_for_example
|
||||
examples_for_semantic_search.append(
|
||||
{
|
||||
"question": example.inputs["question"][0]["content"],
|
||||
"messages": few_shot_messages_for_example,
|
||||
}
|
||||
)
|
||||
|
||||
prompt = ChatPromptTemplate.from_messages(
|
||||
[
|
||||
("system", "{instructions}"),
|
||||
MessagesPlaceholder("few_shot_message_list"),
|
||||
("human", "{input}"),
|
||||
]
|
||||
)
|
||||
|
||||
|
||||
def predict_for_model(model, instructions, few_shot_method, model_name):
|
||||
few_shot_message_list = []
|
||||
chain = prompt | model.bind_tools(tools).with_retry(stop_after_attempt=5)
|
||||
if few_shot_method == "few-shot-string":
|
||||
instructions += f"\n Here are some examples: \n {few_shot_str}"
|
||||
elif few_shot_method == "few-shot-messages":
|
||||
few_shot_message_list = few_shot_messages
|
||||
elif few_shot_method == "few-shot-static-messages":
|
||||
few_shot_message_list = [
|
||||
message
|
||||
for index in static_indices
|
||||
for message in few_shot_messages_by_index[index]
|
||||
]
|
||||
elif few_shot_method == "few-shot-dynamic-messages":
|
||||
|
||||
def predict(example: dict):
|
||||
example_selector = SemanticSimilarityExampleSelector.from_examples(
|
||||
examples_for_semantic_search,
|
||||
OpenAIEmbeddings(model="text-embedding-3-large"),
|
||||
FAISS,
|
||||
k=3,
|
||||
input_keys=["question"],
|
||||
example_keys=["messages"],
|
||||
)
|
||||
|
||||
few_shot_prompt = FewShotChatMessagePromptTemplate(
|
||||
input_variables=[],
|
||||
example_selector=example_selector,
|
||||
example_prompt=MessagesPlaceholder("messages"),
|
||||
)
|
||||
return {
|
||||
"response": chain.invoke(
|
||||
{
|
||||
"input": example["question"],
|
||||
"instructions": instructions,
|
||||
"few_shot_message_list": few_shot_prompt.invoke(
|
||||
{"question": example["question"][0]["content"]}
|
||||
).messages,
|
||||
}
|
||||
)
|
||||
}
|
||||
|
||||
return predict
|
||||
|
||||
def predict(example: dict):
|
||||
return {
|
||||
"response": chain.invoke(
|
||||
{
|
||||
"input": example["question"],
|
||||
"instructions": instructions,
|
||||
"few_shot_message_list": few_shot_message_list,
|
||||
}
|
||||
)
|
||||
}
|
||||
|
||||
return predict
|
||||
|
||||
|
||||
models = [
|
||||
(
|
||||
"claude-3-haiku-20240307",
|
||||
"anthropic",
|
||||
),
|
||||
(
|
||||
"claude-3-sonnet-20240229",
|
||||
"anthropic",
|
||||
),
|
||||
(
|
||||
"claude-3-opus-20240229",
|
||||
"anthropic",
|
||||
),
|
||||
(
|
||||
"claude-3-5-sonnet-20240620",
|
||||
"anthropic",
|
||||
),
|
||||
("gpt-3.5-turbo-0125", "openai"),
|
||||
("gpt-4o", "openai"),
|
||||
("gpt-4o-mini", "openai"),
|
||||
]
|
||||
|
||||
few_shot_methods = [
|
||||
"no-few-shot",
|
||||
"few-shot-string",
|
||||
"few-shot-messages",
|
||||
"few-shot-static-messages",
|
||||
"few-shot-dynamic-messages",
|
||||
]
|
||||
|
||||
from tqdm import tqdm
|
||||
|
||||
experiment_uuid = uuid.uuid4().hex[:4]
|
||||
for i in tqdm(range(3)):
|
||||
for model_name, model_provider in models:
|
||||
model = init_chat_model(
|
||||
model_name, model_provider=model_provider, temperature=0
|
||||
)
|
||||
for few_shot_method in few_shot_methods:
|
||||
evaluate(
|
||||
predict_for_model(
|
||||
model, QUERY_ANALYSIS_TASK.instructions, few_shot_method, model_name
|
||||
),
|
||||
data=QUERY_ANALYSIS_TASK.name,
|
||||
evaluators=[evaluate_run],
|
||||
experiment_prefix=f"{model_name}-TEST-{i+2}-{few_shot_method}",
|
||||
metadata={"id": experiment_uuid},
|
||||
)
|
||||
+61
@@ -0,0 +1,61 @@
|
||||
# Security Policy
|
||||
|
||||
## Reporting OSS Vulnerabilities
|
||||
|
||||
LangChain is partnered with [huntr by Protect AI](https://huntr.com/) to provide
|
||||
a bounty program for our open source projects.
|
||||
|
||||
Please report security vulnerabilities associated with the LangChain
|
||||
open source projects by visiting the following link:
|
||||
|
||||
[https://huntr.com/bounties/disclose/](https://huntr.com/bounties/disclose/?target=https%3A%2F%2Fgithub.com%2Flangchain-ai%2Flangchain&validSearch=true)
|
||||
|
||||
Before reporting a vulnerability, please review:
|
||||
|
||||
1) In-Scope Targets and Out-of-Scope Targets below.
|
||||
2) The [langchain-ai/langchain](https://python.langchain.com/docs/contributing/repo_structure) monorepo structure.
|
||||
3) LangChain [security guidelines](https://python.langchain.com/docs/security) to
|
||||
understand what we consider to be a security vulnerability vs. developer
|
||||
responsibility.
|
||||
|
||||
### In-Scope Targets
|
||||
|
||||
The following packages and repositories are eligible for bug bounties:
|
||||
|
||||
- langchain-core
|
||||
- langchain (see exceptions)
|
||||
- langchain-community (see exceptions)
|
||||
- langgraph
|
||||
- langserve
|
||||
|
||||
### Out of Scope Targets
|
||||
|
||||
All out of scope targets defined by huntr as well as:
|
||||
|
||||
- **langchain-experimental**: This repository is for experimental code and is not
|
||||
eligible for bug bounties, bug reports to it will be marked as interesting or waste of
|
||||
time and published with no bounty attached.
|
||||
- **tools**: Tools in either langchain or langchain-community are not eligible for bug
|
||||
bounties. This includes the following directories
|
||||
- langchain/tools
|
||||
- langchain-community/tools
|
||||
- Please review our [security guidelines](https://python.langchain.com/docs/security)
|
||||
for more details, but generally tools interact with the real world. Developers are
|
||||
expected to understand the security implications of their code and are responsible
|
||||
for the security of their tools.
|
||||
- Code documented with security notices. This will be decided done on a case by
|
||||
case basis, but likely will not be eligible for a bounty as the code is already
|
||||
documented with guidelines for developers that should be followed for making their
|
||||
application secure.
|
||||
- Any LangSmith related repositories or APIs see below.
|
||||
|
||||
## Reporting LangSmith Vulnerabilities
|
||||
|
||||
Please report security vulnerabilities associated with LangSmith by email to `security@langchain.dev`.
|
||||
|
||||
- LangSmith site: https://smith.langchain.com
|
||||
- SDK client: https://github.com/langchain-ai/langsmith-sdk
|
||||
|
||||
### Other Security Concerns
|
||||
|
||||
For any other security concerns, please contact us at `security@langchain.dev`.
|
||||
@@ -1,54 +0,0 @@
|
||||
import pytest
|
||||
from langchain_core.agents import AgentActionMessageLog, AgentFinish
|
||||
from langchain_core.exceptions import OutputParserException
|
||||
from langchain_core.messages import AIMessage
|
||||
|
||||
from langchain_benchmarks.tool_usage.agents.experimental.parser import (
|
||||
GenericAgentParser,
|
||||
)
|
||||
|
||||
|
||||
def test_parser() -> None:
|
||||
"""Test parser."""
|
||||
parser = GenericAgentParser(require_closing_tag=False, wrapping_xml_tag="tool")
|
||||
|
||||
# If <tool> tag not found then it's an agent finish
|
||||
assert isinstance(parser.invoke("goodbye"), AgentFinish)
|
||||
|
||||
with pytest.raises(OutputParserException):
|
||||
# Invocation content is missing tool name and arguments
|
||||
parser.invoke("<tool>'hello'</tool>")
|
||||
|
||||
with pytest.raises(OutputParserException):
|
||||
parser.invoke("<tool>hello")
|
||||
|
||||
# Full invocation
|
||||
text = (
|
||||
'<tool>{\n "tool_name": "type_letter",\n '
|
||||
'"arguments": {\n '
|
||||
'"letter": "h"\n }\n}</tool>\n'
|
||||
)
|
||||
|
||||
assert parser.invoke(text) == AgentActionMessageLog(
|
||||
tool="type_letter",
|
||||
tool_input={"letter": "h"},
|
||||
log="\nInvoking type_letter: {'letter': 'h'}\n\t",
|
||||
message_log=[AIMessage(content=text)],
|
||||
)
|
||||
|
||||
# Test more cases
|
||||
parsed = parser.invoke('<tool>{"tool_name": "hello"}</tool>')
|
||||
assert parsed.tool == "hello"
|
||||
# Assumes that it's a structured tool by default!
|
||||
assert parsed.tool_input == {}
|
||||
|
||||
with pytest.raises(OutputParserException):
|
||||
# Arguments need to be a dict
|
||||
parser.invoke('<tool>{"tool_name": "hello", "arguments": [1, 2]}</tool>')
|
||||
|
||||
parsed = parser.invoke(
|
||||
'<tool>{"tool_name": "hello", "arguments": {"a": "b"}}</tool>'
|
||||
)
|
||||
assert parsed.tool == "hello"
|
||||
# Assumes that it's a structured tool by default!
|
||||
assert parsed.tool_input == {"a": "b"}
|
||||
@@ -1,25 +0,0 @@
|
||||
"""Test typescript encoding."""
|
||||
from langchain_benchmarks.tool_usage.agents.experimental.encoder import (
|
||||
FunctionDefinition,
|
||||
TypeScriptEncoder,
|
||||
)
|
||||
|
||||
|
||||
def test_function_definition() -> None:
|
||||
"""Test encoding a function definition."""
|
||||
function_definition = FunctionDefinition(
|
||||
name="test_function",
|
||||
description="A test function",
|
||||
parameters=[
|
||||
{"name": "test_parameter", "type": "str", "description": "A test parameter"}
|
||||
],
|
||||
return_value={"type": "str", "description": "A test return value"},
|
||||
)
|
||||
encoder = TypeScriptEncoder()
|
||||
xml = encoder.visit_function_definition(function_definition)
|
||||
assert xml == (
|
||||
"// A test function\n"
|
||||
"// @param test_parameter A test parameter\n"
|
||||
"// @returns A test return value\n"
|
||||
"function test_function(test_parameter: str): str;"
|
||||
)
|
||||
@@ -1,90 +0,0 @@
|
||||
"""Test XML encoding and decoding of function definitions, invocation, and results."""
|
||||
from langchain_benchmarks.tool_usage.agents.experimental.encoder import (
|
||||
FunctionDefinition,
|
||||
FunctionInvocation,
|
||||
FunctionResult,
|
||||
XMLEncoder,
|
||||
)
|
||||
|
||||
|
||||
def test_function_definition_encoding() -> None:
|
||||
"""Test encoding a function definition."""
|
||||
function_definition = FunctionDefinition(
|
||||
name="test_function",
|
||||
description="A test function",
|
||||
parameters=[
|
||||
{"name": "test_parameter", "type": "str", "description": "A test parameter"}
|
||||
],
|
||||
return_value={"type": "str", "description": "A test return value"},
|
||||
)
|
||||
encoder = XMLEncoder()
|
||||
xml = encoder.visit_function_definition(function_definition)
|
||||
assert xml == (
|
||||
"<function>\n"
|
||||
"<function_name>test_function</function_name>\n"
|
||||
"<description>\n"
|
||||
"A test function\n"
|
||||
"</description>\n"
|
||||
"<parameters>\n"
|
||||
"<parameter>\n"
|
||||
"<name>test_parameter</name>\n"
|
||||
"<type>str</type>\n"
|
||||
"<description>A test parameter</description>\n"
|
||||
"</parameter>\n"
|
||||
"</parameters>\n"
|
||||
"<return_value>\n"
|
||||
"<type>str</type>\n"
|
||||
"<description>A test return value</description>\n"
|
||||
"</return_value>\n"
|
||||
"</function>"
|
||||
)
|
||||
|
||||
|
||||
def test_function_result_encoding() -> None:
|
||||
"""Test encoding a function result."""
|
||||
encoder = XMLEncoder()
|
||||
function_result = FunctionResult(
|
||||
name="test_function",
|
||||
result="test_result",
|
||||
error=None,
|
||||
)
|
||||
xml = encoder.visit_function_result(function_result)
|
||||
assert xml == (
|
||||
"<function_result>\n"
|
||||
"<function_name>test_function</function_name>\n"
|
||||
"<result>test_result</result>\n"
|
||||
"</function_result>"
|
||||
)
|
||||
|
||||
function_result = FunctionResult(
|
||||
name="test_function",
|
||||
error="error",
|
||||
)
|
||||
xml = encoder.visit_function_result(function_result)
|
||||
assert xml == (
|
||||
"<function_result>\n"
|
||||
"<function_name>test_function</function_name>\n"
|
||||
"<error>error</error>\n"
|
||||
"</function_result>"
|
||||
)
|
||||
|
||||
|
||||
def test_function_invocation() -> None:
|
||||
"""Test function invocation."""
|
||||
function_invocation = FunctionInvocation(
|
||||
name="test_function",
|
||||
arguments=[{"name": "test_argument", "value": "test_value"}],
|
||||
)
|
||||
encoder = XMLEncoder()
|
||||
xml = encoder.visit_function_invocation(function_invocation)
|
||||
assert xml == (
|
||||
"<function_invocation>\n"
|
||||
"<function_name>test_function</function_name>\n"
|
||||
"<arguments>\n"
|
||||
"<argument>\n"
|
||||
"<name>test_argument</name>\n"
|
||||
"<value>test_value</value>\n"
|
||||
"</argument>\n"
|
||||
"</arguments>\n"
|
||||
"</function_invocation>"
|
||||
)
|
||||
@@ -1,59 +0,0 @@
|
||||
import pytest
|
||||
from langchain.tools import tool
|
||||
|
||||
from langchain_benchmarks.tool_usage.agents.experimental.tool_utils import (
|
||||
convert_tool_to_function_definition,
|
||||
)
|
||||
|
||||
|
||||
@tool
|
||||
def get_hello() -> str:
|
||||
"""Get hello."""
|
||||
return "hello"
|
||||
|
||||
|
||||
@tool
|
||||
def repeat(x: str) -> str:
|
||||
"""Repeat x.
|
||||
|
||||
Args:
|
||||
x: The string to repeat.
|
||||
|
||||
Returns:
|
||||
The repeated string.
|
||||
"""
|
||||
return x
|
||||
|
||||
|
||||
def test_parameterless_function() -> None:
|
||||
"""Test foo."""
|
||||
function_definition = convert_tool_to_function_definition(get_hello)
|
||||
assert function_definition == {
|
||||
"name": "get_hello",
|
||||
"description": "Get hello.",
|
||||
"parameters": [],
|
||||
"return_value": {
|
||||
"type": "Any",
|
||||
},
|
||||
}
|
||||
|
||||
|
||||
@pytest.mark.skip("Need to fix handling of leading whitespace")
|
||||
def test_function_with_parameters() -> None:
|
||||
import textwrap
|
||||
|
||||
doc = textwrap.dedent(repeat.func.__doc__)
|
||||
assert convert_tool_to_function_definition(repeat) == {
|
||||
"name": "repeat",
|
||||
"description": doc,
|
||||
"parameters": [
|
||||
{
|
||||
"name": "x",
|
||||
"type": "str",
|
||||
"description": "", # Need to fix this
|
||||
}
|
||||
],
|
||||
"return_value": {
|
||||
"type": "Any",
|
||||
},
|
||||
}
|
||||
@@ -6,5 +6,11 @@ def test_public_api() -> None:
|
||||
# This test will also fail if __all__ is not sorted.
|
||||
# Please keep it sorted!
|
||||
assert __all__ == sorted(
|
||||
["apply_agent_executor_adapter", "get_eval_config"], key=str.lower
|
||||
[
|
||||
"apply_agent_executor_adapter",
|
||||
"get_eval_config",
|
||||
"CustomRunnableAgentFactory",
|
||||
"StandardAgentFactory",
|
||||
],
|
||||
key=str.lower,
|
||||
)
|
||||
|
||||
Reference in New Issue
Block a user