Remove unused code Issue: #I638QE Signed-off-by: qiuyu <qiuyu22@huawei.com> Change-Id: I33908e556a638806a5bb2a06e023ba449ba910ef
21 KiB
Panda Intermediate representation(IR) design
This document describes Panda IR design with the following goals
- Possibility to implement various optimizations and analyses
- Support all the features and instructions of Panda bytecode
- Focus on ARM64 architecture
- Compiler overhead about 100000 native instructions per a bytecode instruction(standard for JIT compilers)
- Be able to convert to other IR and back
Optimizations and analyses
In the development process, it is very important to have auxiliary functionality for various code transformations and analyses. The structure of the IR should be as clear as possible and make it possible to implement various algorithms. The panda IR should contribute to this.
Also in the compilation process, the order of execution of optimizations and analyses is very important. Firstly there are dependencies between different passes. Second, often some optimization creates a context for others.
The first goal of the Panda IR to be able to change the order of the passes, add and delete passes(If 2 passes have a dependency we must take this into account). We should be able to change the order of the passes by options.
Second, we need to support the transfer of information between optimizations.
List of the optimizations
- IrBuilder
- BranchElimination
- ChecksElimination
- Cleanup
- Constant Folding
- Inlining
- Inlining
- LICM
- Lowering
- Load Store Elimination (LSE)
- Memory Coalescing
- Peepholes
- Value Numbering
Analyses
- Alias Analysis
- Bounds Analysis
- Domtree
- Linear Order
- Liveness Analysis
- Monitor Analysis
- Reverse Post Order(RPO)
Potential optimizations
The benefits of some optimizations are not obvious or do need profiling information to implement them. We will have them in mind, but will make the implementation, after performance analyzing the code.
- Remove cold path
- MAW(Memory access widening)/Merge memory
- Block duplication
!NOTE It is possible to write other optimizations based on the specifics of the language and VM
The order of optimizations
We will try to make it possible to pass optimizations in an arbitrary order. Some restrictions will still be: register allocation and code generation at the end, inlining at the beginning. Some optimization(DCE, Peephole) will be called several times.
Features
- Using profile information for IFC and speculative optimizations
- Supporting side exits for de-optimizations and removing cold code.
- Converting to LLVM IR
- Independence from Runtime(all profile and runtime information will be contained in a special class with default values)
- Common properties will be introduced for the instructions, making it easier to add new instructions
Instruction set
Panda IR needs to combine the properties of high and low level IRs.
High level:
Panda bytecode has more than 200 instructions. We need to convert all Bytecode instructions in IR instructions with minimal overhead(ideally one to one).
The specifics and properties of instructions should be taken into account in optimizations and codegen.
Low level:
The main target is ARM64. So Panda IR should be able to do arm specific optimizations. For this, need to support ARMv8-M Instruction Set(only those instructions that are needed)
Proposal:
IR contains high- and low-level instructions with a single interface.
In the first step, Panda bytecode is converted to high level instruction and architecturally independent optimizations are made.
At the second step, the instructions will be split on several low level instructions(close to assembler instructions) for additional optimizations.
Overhead
Overhead is the time that requires for compile.
Typically, an overhead is considered to be the average number of 'native' instructions(ARM) that are spent compiling a single 'guest' instruction(from Bytecode).
The more and more complex optimizations we do, the more overhead we get. We need to find a balance between performance and the overhead needed to achieve it. For example, the optimization Unroll allows to remove unnecessary loop induction variables and dependencies between loop iterations, but it increases the size of the code that leads to increases overhead. We should apply this optimization only if the benefit from it exceeds the increase in overhead costs.
In Ahead-Of-Time(AOT) mode the overhead is less critical for us, so we can do more optimizations.
In Just-In-Time(JIT) mode need to strictly control the overhead to get the overall performance increase(time on compile + time on execution).
The goal is overhead about 100000 native instructions per guest (standard for JIT compilers)
Compatibility
To be able to integrate into existing compilers, as well as to compare efficiency, to need the ability to convert to Panda Ir and back.
The converter from LLVM IR and back will allow using different LLVM optimizations.
IR structure
Rationale
The most of used IR in compilers: classical CFG(Control Flow Graph) with SSA(Static Single Assignment) form(used in LLVM, WebKit, HHVM, CoreCLR, IonMonkey) and Sea-of-Nodes(Hotspot, V8 Turbofan). We decided to choose the CFG with SSA form for the following reasons:
- It is more common in compilers and easier to understand
- Sea-of-Nodes has a big overhead for IR constructing and scheduling phases, that makes impossible to make lightweight tier 1 (applying a small number of optimizations with minimal overhead for fast code generation)
Graph
The main class is a Graph. It contains all information for compiler such as:
- Information about the method for which transformations are made
- pointer to RuntimeInterface - class with all Runtime information
- Vector of pointers to BasicBlocks
- Information about the current status(constructerd or not RPO, DomTree e.t.c)
- Information to be transmitted between passes
- Pass manager
Class Graph allows creating new instructions, adding and removing blocks, constructing RPO, DomTree and e.t.c
BasicBlock
BasicBlock is a class that describes a linear part of executable code. BasicBlock contains:
- A double-linked list of instructions, which are contained in the block
- List of predecessors: vector of pointers to the BasicBlocks from which we can get into the current block
- List of successors: vector of pointers to the BasicBlocks in which we can get from the current block
- Information about DomTree
Class BasicBlock allows adding and removing instructions in the BasicBlock, adding and removing successors and predecessors, getting dominate block and dominated blocks e.t.c
The Graph always begins from start BasicBlock and finishes end BasicBlock.
Start BasicBlock doesn't have predecessors and have one successor. Only SafePoint, Constants and Parameter instructions can be contained in start BasicBlock.
End BasicBlock doesn't have successors and doesn't contain instructions.
BasicBlock can not have more than one incoming or outgoing edges into the same block. When control flow look like that, we must keep an empty block on the edge. Left graph can not be optimized to right one when block 3 have no instructions.
[1] [1]
| \ | \
| [3] -x-> | |
| / | /
[2] [2]
Empty blocks pass covers this situation and do not remove such an empty block when there are Phi instructions in block 2 with different inputs from those incoming edges. When there are no such Phis we can easily remove the second edge too.
Another solution may be to introduce Select instructions on early stage. Third solution is to keep special Mov instructions in block 3, but this contradicts to SSA form ideas and experiments show that this is less effective, as we keep to much Mov-only blocks.
| Bench | Empty Blocks | Mov-Blocks |
|---|---|---|
| access-fannkuch-c2p | 0 | 1 |
| math-spectral-norm-c2p | 0 | 1 |
| bitops-bitwise-and-c2p | 0 | 0 |
| bitops-bits-in-byte-c2p | 0 | 1 |
| bitops-3bit-bits-in-byte-c2p | 0 | 1 |
| access-nsieve-c2p | 0 | 1 |
| controlflow-recursive-c2p | 0 | 25 |
| 3d-morph-c2p | 0 | 3 |
| math-partial-sums | 1 | 1 |
| controlflow-recursive | 1 | 86 |
| bitops-nsieve-bits | 1 | 2 |
| access-binary-trees | 3 | 4 |
| access-nbody | 1 | 11 |
| 3d-morph | 1 | 3 |
| access-fannkuch | 1 | 2 |
| access-nsieve | 1 | 2 |
| bitops-3bit-bits-in-byte | 1 | 3 |
| bitops-bits-in-byte | 1 | 3 |
| math-spectral-norm | 1 | 4 |
| bitops-bitwise-and | 0 | 0 |
| math-cordic | 1 | 2 |
Instructions
Instructions are implemented by class inheritance.
Inst is a base class with main information about an instruction.
- Opcode(name) of the instruction
- pc(address) instruction in bytecode/file
- Type of instruction(bool, uint8, uint32, float, double e.t.c)
- Pointers to next and previous Inst in the BasicBlock
- Array of inputs (instructions whose result this Inst uses)(class Inst has virtual method that returns empty array. Derived classes override this method and return non empty array)
- List of users (instructions which use result from the Inst)
- Properties
Class Inst allows adding and removing users and inputs
Class FixedInputsInst inherits from Inst for instruction with a fixed number of inputs(operands).
Class DynamicInputsInst inherits from Inst for instruction with a variable number of inputs(operands).
Class CompareInst inherits from Inst for instruction with predicate. It contain information about type of conditional code(EQ, NE, LT, LE and e.t.c).
Class ConstantInst inherits from Inst for constant instruction. It contains a constant and type of the constant. Constants are contained only in start block.
Class ParameterInst inherits from Inst for input parameter. It contains a type of parameter and parameter number. Parameters are contained only in start block.
Class UnaryOperation inherits from FixedInputsInst for instruction with a single input. The class is used for instructions NOT, NEG, ABS e.t.c.
Class BinaryOperation inherits from FixedInputsInst for instruction with two inputs. The class is used for instructions ADD, SUB, MUL e.t.c.
Class CallInst inherits from DynamicInputsInst for call instructions.
Class PhiInst inherits from DynamicInputsInst for phi instructions.
Mixin
Mixin are classes with properties or data which uses different instruction classes. For example:
ImmediateMixin is inherited in instruction classes with immediate(BinaryImmOperation, ReturnInstI and so on)
ConditionMixin is inherited in instruction classes with conditional code(CompareInst, SelectInst, IfInst and so on)
TypeIdMixin is inherited in instruction classes wich uses TypeId(LoadObjectInst, StoreObjectInst, NewObjectInst and so on)
Constant instruction
Constant instructions(ConstantInst) can have type FLOAT32, FLOAT64 and INT64. Constants all integer types and reference saves as INT64. All integer instructions can have constant input with INT64 type. All constants instruction are contaned in Start BasicBlock. There are not two equal constant(equal value and type) in Graph. The Graph function indOrCreateConstant is used for adding constant in Graph.
Parameter instruction
Parameter instruction(ParameterInst) contain a type of parameter and parameter number. Parameters are contained only in Start BasicBlock. The Graph function AddNewParameter is used for adding parameter in Graph.
instruction.yaml
instruction.yaml contains next information for each instruction:
- Opcode
- class
- signature(supported type of inputs and type of destination for the instruction)
- flags
- description
instruction.yaml is used for generating instructions and describing them.
!NOTE instruction.yaml isn't used for generating checks for instruction. We plan to support this.
Exceptions
Details: (../compiler/docs/try_catch_blocks_ir.md)
Reverse Post Order(RPO) tree
RPO builds blocks list for reverse post-order traversal. In RPO iteration, a BasicBlock is visited before any of its successor BasicBlocks has been visited, except when the successor is reached by a back edge. RPO is implemented as a separate class, which returns the vector of pointers to BasicBlocks for the Graph. There is an option to invalidate the vector. In this case, the vector will be built from scratch after the next request for it(if the option to invalidate isn't set, the current RPO vector is returned). RPO is invalidated after Control Flow transformations: removing or adding blocks or edges between blocks. Also, it provides methods for updating an existing tree.
Class RPO allows constructing RPO vector, adding or removing blocks to the vector.
DomTree building
A BasicBlock "A" dominates a BasicBlock "B" if every path from the "start" to "B" must go through "A". DomTree is implemented as a separate class, but it makes only constructing the tree. The Dominator tree itself is stored in class BasicBlock. Each BasicBlock has a pointer on dominate block and vector of pointers to blocks which he dominates. BasicBlock has function changing the dominate block and the vector(adding, removing). As in the case of RPO, class DomTree has an option to invalidate the tree, but unlike RPO, the tree rebuilding doesn't happen automatically, the developer has to monitor it himself and call the construct function if necessary.
Instruction Iterators
The block instructions form a doubly linked list. At the beginning are Phi instructions, and then all the rest. Iteration over instructions can be passed in direct/reverse order. ‘IterationType’ defines instructions that are iterated: phi-instructions, non-phi-instructions or all instructions. “SafeIterator“ is keeping the next instruction in case of removing current instruction. List of the iterators: PhiInstIter, InstIter, AllInstIter, InstReverseIter, PhiInstSafeIter, InstSafeIter, AllInstSafeIter, PhiInstSafeReverseIter, InstSafeReverseIter, AllInstSafeReverseIter
Data Flow Graph
Data flow graph is widely used by almost all optimizations, therefore it greatly affects overhead of the JIT. The most basic and frequent use is an iterating over inputs or users. One of the approaches to make iterating more effective is to store data in sequence container, such as array or vector, thereby elements much more likely will be in the processor cache.
User of the instruction is an object that points to the consumer instruction and its corresponding input.
Input is the object that describes which instruction defines value for corresponding operand of the owned instruction.
Instructions can have various count of users and this count doesn't depend on the instruction type. Therefore storing users in sequence container has one big drawback - frequent storage reallocation, that leads to memory fragmentation (IR uses arena allocator) and additional overhead.
On the other hand, inputs depend on instruction type and mostly have fixed count. Thus, they should be stored in sequence container.
Following scheme shows how Panda JIT organizes inputs and users in the memory:
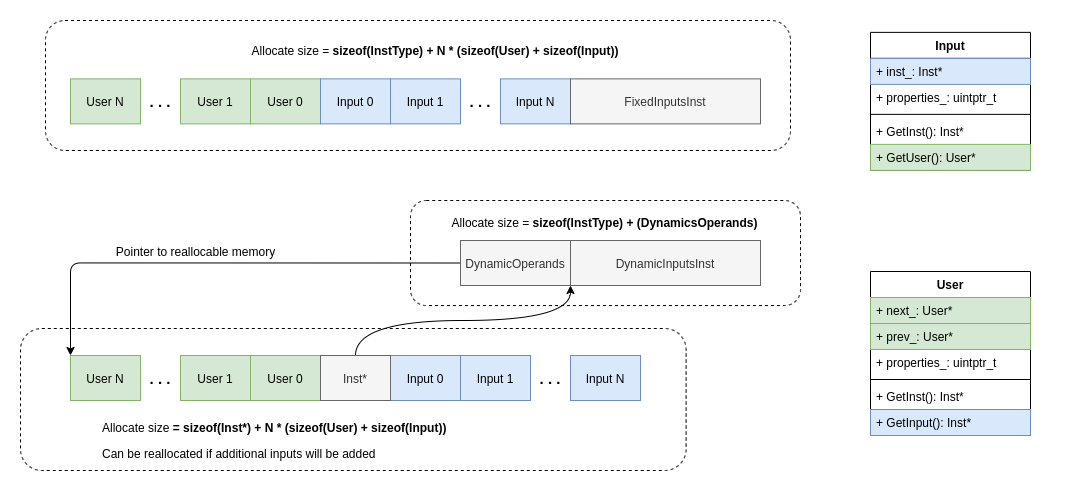
There are two types of def-use storage: in memory right before instruction class and in separate memory chunk.
- First case is used in instructions with fixed number of inputs. Storage is allocated right before instruction object and it is never reallocated. Most instructions belongs to this category.
- Second category is the instructions with dynamic number of inputs, such as Phi instructions. Its def-use storage is allocated separately from instruction object, both storage and instruction are coupled by pointers to each other. In case when new input is appended and the capacity of the storage is equal to its size, whole storage is reallocated. This behavior is exactly similar to classical vector implementations. This brings additional amortized complexity to this category.
Both, user and input have properties field that have following information:
- index of input/user
- overall number of inputs
- flag that shows whether storage is dynamic
- additional info about input:
- if instruction is SaveState: virtual register number
- if instruction is Phi: number of basic block predecessor edge
With this field it is possible to get instruction that owns given user or input.
This kind of storage have been chosen because it avoids usage of virtual methods and dynamic containers for all instruction. Instead, each access to def-use structures is just checking whether storage is dynamic and further processing of the corresponding type of def-use storage. Instead of indirect call we have one condition branch which has good branch prediction, because of most instructions have fixed number of inputs.
Visitor
Class GraphVisitor allows to go through the blocks of the graph in RPO order and then all the instructions of the block. At the same time Visit functions are called by the opcode of the instruction or by its group affiliation.
Pass manager
!TODO Sherstennikov Mikhail add description
Lowering
Lowering pass makes low level instructions(which are more close to machine code).
Some instructions may not appear before this pass. But at the moment we do not have any checks on this
Register allocation
Register allocation is a process of assigning CPU registers to instructions.
There are 2 based algorithm: Graph-coloring allocation(by Gregory John Chaitin) and Linear Scan(by Massimiliano Poletto)
We use "Linear Scan" algorithm because it has less overhead(the graph coloring algorithm having a quadratic cost).
In the future, we plan to implement Graph-coloring algorithm, because it gives better code, and select the type of allocator depending on the context.
Code generator
Code generation is a complex process that converts IR code into the machine code.
At the moment, we consider Arm64 as the main architecture.
We chose the standard vixl library for сode generation to make implementation faster and avoid possible errors.
The vixl-library created by ARM-developers for easy implement assembly-generation and emulation.
It is used in HHVM, IonMonkey, DartVM and proved its reliability.
In the future, we plan to make fully own implementation for more optimal code generation(in terms of overhead and performance).
!TODO Gorban Igor update description
Example of use
Create Graph
Graph* graph = new (allocator) Graph(&allocator_, panda_file_, /*method_idx*/ -1, /*is_arm64*/ true);
Create blocks and CFG
BasicBlock* start = graph->CreateStartBlock();
BasicBlock* end = graph->CreateEndBlock();
BasicBlock* block = graph->CreateEmptyBlock();
start->AddSucc(block);
block->AddSucc(end);
block->AddSucc(block);
Create instruction and add in a block
ConstantInst* constant = graph->FindOrCreateConstant(value);
ParameterInst* param = graph->AddNewParameter(slot_num, type);
Inst* phi1 = graph->CreateInst(Opcode::Phi);
Inst* ph2 = graph->CreateInst(Opcode::Phi);
Inst* compare = graph->CreateInst(Opcode::Compare);
Inst* add = graph->CreateInst(Opcode::Add);
block->AppendPhi(phi1);
block->AppendInst(compare);
block->InsertAfter(phi2, phi1);
block->InsertBefore(add, compare);
for (auto inst : block->PhiInsts()) {
ASSERT(inst->GetOpcode() == Opcode::Phi)
......
}
for (auto inst : block->Insts()) {
ASSERT(inst->GetOpcode() != Opcode::Phi)
......
}
for (auto inst : block->AllInsts()) {
......
}
for (auto inst : block->InstsSafe()) {
if (inst->GetOpcode() == Opcode::Add) {
block->EraseInst(inst);
}
}
Visitors:
struct ExampleVisitor: public GraphVisitor {
using GraphVisitor::GraphVisitor;
// Specify blocks to visit and their order
const ArenaVector<BasicBlock *> &GetBlocksToVisit() const override
{
return GetGraph()->GetBlocksRPO();
}
// Print special message for Mul instruction
static void VisitMul(GraphVisitor* v, Inst* inst) {
std::cerr << "Multiply instruction\n";
}
// For all other instructions print its opcode
void VisitDefault(Inst* inst) override {
std::cerr << OPCODE_NAMES[(int)inst->GetOpcode()] << std::endl;
}
// Visitor for all instructions which are the instance of the BinaryOperation
void VisitInst(BinaryOperation* inst) override {
std::cerr << "Visit binary operation\n";
}
#include "visitor.inc"
};
....
ExampleVisitor visitor(graph);
visitor.VisitGraph();