This change is symmetric with the one reviewed in
<https://reviews.llvm.org/D157452> and handles the exception handling
specific intrinsic, which slipped through the cracks, in the same way,
by inserting an address-space cast iff RTTI is in a non-default AS.
The size of .ARM.exidx may shrink across `assignAddress` calls. It is
possible
that the initial iteration has a larger location counter, causing
`__code_size =
__code_end - .; osec : { . += __code_size; }` to report an error, while
the error would
have been suppressed for subsequent `assignAddress` iterations.
Other sections like .relr.dyn may change sizes across `assignAddress`
calls as
well. However, their initial size is zero, so it is difficiult to
trigger a
similar error.
Similar to https://reviews.llvm.org/D152170, postpone the error
reporting.
Fix#66836. While here, add more information to the error message.
This avoids the need for a mutable member to implement deferred sorting,
and some bespoke code to maintain a SmallVector as a set.
The performance impact seems to be negligible in some small tests, and
so seems acceptable to greatly simplify the code.
An old FIXME and accompanying workaround are dropped. It is ostensibly
dead-code within the current codebase.
Print OpConstant floats as formatted decimal floating points, with
special case exceptions to print infinity and NaN as hexfloats.
This change follows from the fixes in
https://github.com/llvm/llvm-project/pull/66686 to correct how
constant values are printed generally.
Differential Revision: https://reviews.llvm.org/D159376
sync_source_lists_from_cmake.py checks that every unittest in CMake
also exists in the GN build. 4f330b7f75 added VETests, but the GN
build doesn't include the VE target. So add a dummy target for this
to placate the check.
This fixes 46b961f36b.
Prior to the SME changes the steps were:
* Invalidate all registers.
* Update value of VG and use that to reconfigure the registers.
* Invalidate all registers again.
With the changes for SME I removed the initial invalidate thinking
that it didn't make sense to do if we were going to invalidate them
all anyway after reconfiguring.
Well the reason it made sense was that it forced us to get the
latest value of vg which we needed to reconfigure properly.
Not doing so caused a test failure on our Graviton bot which has SVE
(https://lab.llvm.org/buildbot/#/builders/96/builds/45722). It was
flaky and looping it locally would always fail within a few minutes.
Presumably it was using an invalid value of vg, which caused some offsets
to be calculated incorrectly.
To fix this I've invalided vg in AArch64Reconfigure just before we read
it. This is the same as the fix I have in review for SME's svg register.
Pushing this directly to fix the ongoing test failure.
This revision pipes the fastmath attribute support through the
vector.reduction op. This seemingly simple first step already requires
quite some genuflexions, file and builder reorganization. In the
process, retire the boolean reassoc flag deep in the LLVM dialect
builders and just use the fastmath attribute.
During conversions, templated builders for predicated intrinsics are
partially cleaned up. In the future, to finalize the cleanups, one
should consider adding fastmath to the VPIntrinsic ops.
Auto summaries were only being used when non-pointer/reference variables
didn't have values nor summaries. Greg pointed out that it should be
better to simply use auto summaries when the variable doesn't have a
summary of its own, regardless of other conditions.
This led to code simplification and correct visualization of auto
summaries for pointer/reference types, as seen in this screenshot.
<img width="310" alt="Screenshot 2023-09-19 at 7 04 55 PM"
src="https://github.com/llvm/llvm-project/assets/1613874/d356d579-13f2-487b-ae3a-f3443dce778f">
This patch warns when an align directive with a non-zero fill value is
used in a virtual section. The fill value is also set to zero,
preventing an assertion in `MCAssembler::writeSectionData` for the case
of `MCFragment::FT_Align` from tripping.
This extends `vector.constant_mask` so that mask dim sizes that
correspond to a scalable dimension are treated as if they're implicitly
multiplied by vscale. Currently this is limited to mask dim sizes of 0
or the size of the dim/vscale. This allows constant masks to represent
all true and all false scalable masks (and some variations):
```
// All true scalable mask
%mask = vector.constant_mask [8] : vector<[8]xi1>
// All false scalable mask
%mask = vector.constant_mask [0] : vector<[8]xi1>
// First two scalable rows
%mask = vector.constant_mask [2,4] : vector<4x[4]xi1>
```
This change makes callees with the __arm_preserves_za
type attribute comply with the dormant state requirements
when it's caller has the __arm_shared_za type attribute.
Several external SME functions also do not need to lazy
save.
5e67092434/aapcs64/aapcs64.rst (L1381)
Differential Revision: https://reviews.llvm.org/D159186
Previously, the SPIR-V instruction printer was always printing the first
operand of an `OpConstant`'s literal value as one of the fixed operands.
This is incorrect for 64-bit values, where the first operand is actually
the value's lower-order word and should be combined with the following
higher-order word before printing.
This change fixes that issue by waiting to print the last fixed operand
of `OpConstant` instructions until the variadic operands are ready to be
printed, then using `NumFixedOps - 1` as the starting operand index for
the literal value operands.
Depends on D156049
Matrix has been templated to Matrix (for MPInt and Fraction) with
explicit instantiation for both these types.
IntMatrix, inheriting from Matrix<MPInt>, has been created to allow for
integer-only methods.
makeMatrix has been duplicated to makeIntMatrix and makeFracMatrix.
This was already landed previously but was reverted in
98c994c8e2 due to build failure. This
fixes the failure.
Previously, post-visit state changes were indistinguishable from
ordinary
iterations, which could give a confusing picture of how many iterations
a block
needs to converge.
Now, post-visit state changes are marked with "post-visit" instead of an
iteration number:
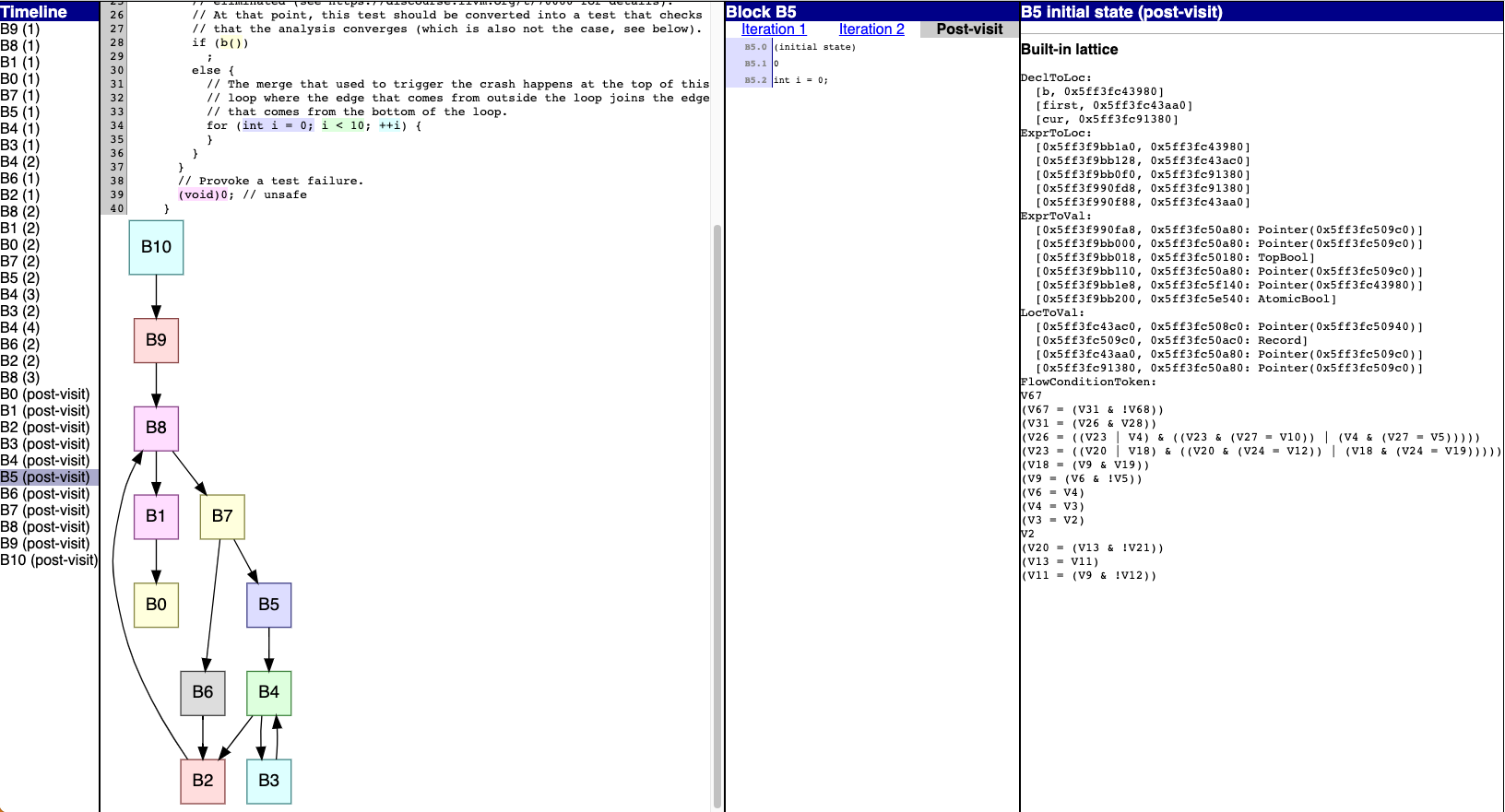)
This adds tests for fixed and scalable vectors where we have a binary op
on two splats that could be scalarized. Normally this would be
scalarized in the middle-end by VectorCombine, but as noted in
https://reviews.llvm.org/D159190, this pattern can crop up during
CodeGen afterwards.
Note that a combine already exists for this, but on RISC-V currently it
only works on scalable vectors where the element type == XLEN. See
#65068 and #65072
For volatile atomic, this may result in a verifier errors, if the
new alloca type is not legal for atomic accesses.
I've opted to disable this special case for volatile accesses in
general, as changing the size of the volatile access seems
dubious in any case.
Fixes https://github.com/llvm/llvm-project/issues/64721.
Basically, the issue was that we should have unwrapped the
base region before we special handle temp object regions.
Fixes https://github.com/llvm/llvm-project/issues/66221
I also decided to add some extra range information to the diagnostics
to make it consistent with the other reporting path.
Addressing remarks after merge of D159257
* Add comment
* Remove irrelevant CHECKs from test
* Simplify function
* Use llvm::sort before setting target-features as it is done in
CodeGenModeule
If all the concatenated subvectors are targets shuffle nodes, then call combineX86ShufflesRecursively to attempt to combine them.
Unlike the existing shuffle concatenation in collectConcatOps, this isn't limited to splat cases and won't attempt to concat the source nodes prior to creating the larger shuffle node, so will usually only combine to create cross-lane shuffles.
This exposed a hidden issue in matchBinaryShuffle that wasn't limiting v64i8/v32i16 UNPACK nodes to AVX512BW targets.
This patch fixes a memory leak if Function::dropAllReferences() is followed by setHungoffOperand (e.g. setPersonality)
If NumUserOperands changes from 3 to 0 before calling allocHungoffUselist() to allocate memory,
the memory leaks which are allocated when NumUserOperands is changed from 0 to 3.
e.g.
```
llvm::Function* func = ...;
func->setPersonalityFn(foo); // (1). call allocHungoffUselist() to allocate memory for uses
func->deleteBody(); // (2). call dropAllReferences(), and it changes NumUserOperands from 3 to 0
// (3). at this point, NumUserOperands is 0, the next line will allocate memory by allocHungoffUselist()
func->setPersonalityFn(bar); // (4). call allocHungoffUselist(), so memory allocated in (1) leaks.
```
Reviewed By: dexonsmith, MaskRay
Differential Revision: https://reviews.llvm.org/D156618
evalIntegralCast was using makeIntVal, and when _BitInt() types were
introduced this exposed a crash in evalIntegralCast as a result.
This is a reapply of a previous patch that failed post merge on the arm
buildbots, because arm cannot handle large
BitInts. Pinning the triple for the testcase solves that problem.
Improve evalIntegralCast to use makeIntVal more efficiently to avoid the
crash exposed by use of _BitInt.
This was caught with our internal randomized testing.
<src-root>/llvm/include/llvm/ADT/APInt.h:1510:
int64_t llvm::APInt::getSExtValue() const: Assertion
`getSignificantBits() <= 64 && "Too many bits for int64_t"' failed.a
...
#9 <address> llvm::APInt::getSExtValue() const
<src-root>/llvm/include/llvm/ADT/APInt.h:1510:5
llvm::IntrusiveRefCntPtr<clang::ento::ProgramState const>,
clang::ento::SVal, clang::QualType, clang::QualType)
<src-root>/clang/lib/StaticAnalyzer/Core/SValBuilder.cpp:607:24
clang::Expr const*, clang::ento::ExplodedNode*,
clang::ento::ExplodedNodeSet&)
<src-root>/clang/lib/StaticAnalyzer/Core/ExprEngineC.cpp:413:61
...
Fixes: https://github.com/llvm/llvm-project/issues/61960
Reviewed By: donat.nagy
This is necessary to support deallocation of IR with gpu.launch
operations because it does not implement the RegionBranchOpInterface.
Implementing the interface would require it to support regions with
unstructured control flow and produced arguments/results.
As part of preparing for the switch to HLFIR lowering, all OpenMP FIR
lowering tests are moved to a subdirectory in the OpenMP directory.
Copies of these tests that work with HLFIR will be created during this
week. After the switch the FIR lowering tests will be removed.
All new tests should be added with the HLFIR flow.
This crash was exposed recently in our randomized testing. _BitInts were
not being handled properly during IntegerLiteral visitation. This patch
addresses the problem for now.
The BitIntType has no getKind() method, so the FoldingSetID is taken
from the APInt value representing the _BitInt(), similar to other
methods in StmtProfile.cpp.
Crash seen (summary form):
clang-tidy: <src-root>/llvm/include/llvm/Support/Casting.h:566:
decltype(auto) llvm::cast(const From&) [with To = clang::BuiltinType;
From = clang::QualType]: Assertion `isa<To>(Val) && "cast<Ty>() argument
of incompatible type!"' failed
```
#9 <address> decltype(auto) llvm::cast<clang::BuiltinType,
clang::QualType>(clang::QualType const&)
<src-root>/llvm/include/llvm/Support/Casting.h:566:3
#10 <address> clang::BuiltinType const* clang::Type::castAs<clang::BuiltinType>() const
<bin-root>/tools/clang/include/clang/AST/TypeNodes.inc:86:1
#11 <address> (anonymous namespace)::StmtProfiler::VisitIntegerLiteral(
clang::IntegerLiteral const*)
<src-root>/clang/lib/AST/StmtProfile.cpp:1362:64
#12 <address> clang::StmtVisitorBase<llvm::make_const_ptr,
(anonymous namespace)::StmtProfiler, void>::Visit(clang::Stmt const*)
<src-root>/clang/include/clang/AST/StmtNodes.inc:1225:1
```
Reviewed By: donat.nagy
The entry and loop intrinsics for convergence control cannot be preceded
by convergent operations in their respective basic blocks. To check
that, the verifier needs to reset its state at the start of the block.
This was missed in the previous commit
fa6dd7a24af2b02f236ec3b980d9407e86c2c4aa.