mirror of
https://github.com/langchain-ai/langchain-benchmarks.git
synced 2026-07-01 22:34:02 -04:00
Compare commits
9 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
301837e303 | ||
|
|
4f1d922a6e | ||
|
|
e4e26a3b8e | ||
|
|
7f82761813 | ||
|
|
7e16b6daa6 | ||
|
|
22d279a25c | ||
|
|
357ada3867 | ||
|
|
ab2d93ac6d | ||
|
|
53f727af64 |
@@ -8,6 +8,7 @@ jobs:
|
||||
release:
|
||||
uses:
|
||||
./.github/workflows/_release.yml
|
||||
permissions: write-all
|
||||
with:
|
||||
working-directory: .
|
||||
secrets: inherit
|
||||
|
||||
@@ -0,0 +1,33 @@
|
||||
name: Weekly Tool Benchmarks
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
schedule:
|
||||
- cron: '0 0 * * 0' # Runs at midnight (00:00) every Sunday (UTC time)
|
||||
|
||||
jobs:
|
||||
run_tool_benchmarks:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
|
||||
- name: Set up Python 3.12 + Poetry ${{ env.POETRY_VERSION }}
|
||||
uses: "./.github/actions/poetry_setup"
|
||||
with:
|
||||
python-version: '3.12'
|
||||
poetry-version: ${{ env.POETRY_VERSION }}
|
||||
working-directory: .
|
||||
cache-key: benchmarks-all
|
||||
|
||||
- name: Install dependencies
|
||||
shell: bash
|
||||
run: |
|
||||
echo "Running tests, installing dependencies with poetry..."
|
||||
poetry install --with test,lint,typing,docs
|
||||
|
||||
- name: Multiverse math benchmark
|
||||
run: python scripts/multiverse_math_benchmark.py
|
||||
|
||||
- name: Query analysis benchmark
|
||||
run: python scripts/query_analysis_benchmark.py
|
||||
@@ -26,10 +26,24 @@ We have several goals in open sourcing this:
|
||||
|
||||
Read some of the articles about benchmarking results on our blog.
|
||||
|
||||
* Agent Tool Use: https://blog.langchain.dev/benchmarking-agent-tool-use/
|
||||
* Query Analysis in High Cardinality Situations: https://blog.langchain.dev/high-cardinality/
|
||||
* Rag on Tables: https://blog.langchain.dev/benchmarking-rag-on-tables/
|
||||
* Q&A over CSV data: https://blog.langchain.dev/benchmarking-question-answering-over-csv-data/
|
||||
* [Agent Tool Use](https://blog.langchain.dev/benchmarking-agent-tool-use/)
|
||||
* [Query Analysis in High Cardinality Situations](https://blog.langchain.dev/high-cardinality/)
|
||||
* [RAG on Tables](https://blog.langchain.dev/benchmarking-rag-on-tables/)
|
||||
* [Q&A over CSV data](https://blog.langchain.dev/benchmarking-question-answering-over-csv-data/)
|
||||
|
||||
|
||||
### Tool Usage (2024-04-18)
|
||||
|
||||
See [tool usage docs](https://langchain-ai.github.io/langchain-benchmarks/notebooks/tool_usage/benchmark_all_tasks.html) to recreate!
|
||||
|
||||
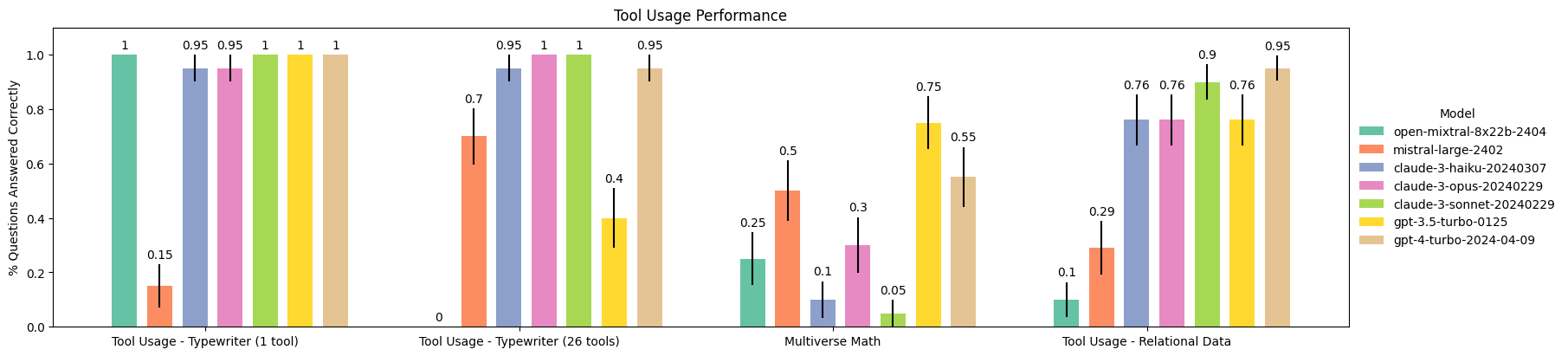
|
||||
|
||||
Explore Agent Traces on LangSmith:
|
||||
|
||||
* [Relational Data](https://smith.langchain.com/public/22721064-dcf6-4e42-be65-e7c46e6835e7/d)
|
||||
* [Tool Usage (1-tool)](https://smith.langchain.com/public/ac23cb40-e392-471f-b129-a893a77b6f62/d)
|
||||
* [Tool Usage (26-tools)](https://smith.langchain.com/public/366bddca-62b3-4b6e-849b-a478abab73db/d)
|
||||
* [Mutiverse Math](https://smith.langchain.com/public/983faff2-54b9-4875-9bf2-c16913e7d489/d)
|
||||
|
||||
## Installation
|
||||
|
||||
|
||||
@@ -3,12 +3,12 @@ from langchain.agents import AgentExecutor, OpenAIFunctionsAgent
|
||||
from langchain.agents.agent_toolkits.conversational_retrieval.tool import (
|
||||
create_retriever_tool,
|
||||
)
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.embeddings import OpenAIEmbeddings
|
||||
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain.tools import PythonAstREPLTool
|
||||
from langchain.vectorstores import FAISS
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
import pandas as pd
|
||||
from langchain.agents.agent_toolkits import create_pandas_dataframe_agent
|
||||
from langchain.agents.agent_types import AgentType
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
import pandas as pd
|
||||
from langchain.agents.agent_toolkits import create_pandas_dataframe_agent
|
||||
from langchain.agents.agent_types import AgentType
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
import pandas as pd
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.prompts import ChatPromptTemplate
|
||||
from langchain.schema.output_parser import StrOutputParser
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
from pandasai import PandasAI
|
||||
|
||||
|
||||
@@ -2,7 +2,7 @@ import pandas as pd
|
||||
import streamlit as st
|
||||
from langchain.agents.agent_toolkits import create_pandas_dataframe_agent
|
||||
from langchain.agents.agent_types import AgentType
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain_openai import ChatOpenAI
|
||||
|
||||
df = pd.read_csv("titanic.csv")
|
||||
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
import streamlit as st
|
||||
from langchain.chains import create_extraction_chain
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
|
||||
st.set_page_config(page_title="🦜🔗 Text-to-graph extraction")
|
||||
|
||||
+1
-1
@@ -3,13 +3,13 @@ from typing import List, Tuple
|
||||
from langchain.agents import AgentExecutor
|
||||
from langchain.agents.format_scratchpad import format_to_openai_functions
|
||||
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
|
||||
from langchain.pydantic_v1 import BaseModel, Field
|
||||
from langchain.schema.messages import AIMessage, HumanMessage
|
||||
from langchain.tools import tool
|
||||
from langchain.tools.render import format_tool_to_openai_function
|
||||
from langchain_docs_retriever.retriever import get_retriever
|
||||
from langchain_openai import ChatOpenAI
|
||||
|
||||
# This is used to tell the model how to best use the retriever.
|
||||
|
||||
|
||||
@@ -7,9 +7,9 @@ from typing import Callable, Optional
|
||||
|
||||
from anthropic_iterative_search.chain import chain as anthropic_agent_chain
|
||||
from chat_langchain.chain import create_chain
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.schema.runnable import Runnable
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
from oai_assistant.chain import agent_executor as openai_assistant_chain
|
||||
from openai_functions_agent import agent_executor as openai_functions_agent_chain
|
||||
|
||||
@@ -259,8 +259,8 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"llm = ChatOpenAI(model=\"gpt-4-1106-preview\", temperature=0).bind_functions(\n",
|
||||
" functions=[task.schema],\n",
|
||||
|
||||
@@ -232,8 +232,8 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"llm = ChatOpenAI(model=\"gpt-3.5-turbo-16k\", temperature=0).bind_functions(\n",
|
||||
" functions=[task.schema],\n",
|
||||
|
||||
@@ -97,7 +97,7 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"from langchain_benchmarks.extraction import get_eval_config\n",
|
||||
"\n",
|
||||
|
||||
@@ -75,6 +75,7 @@
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "7fb27b941602401d91542211134fc71a",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
@@ -728,12 +729,12 @@
|
||||
"from langchain.agents import AgentExecutor\n",
|
||||
"from langchain.agents.format_scratchpad import format_to_openai_functions\n",
|
||||
"from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder\n",
|
||||
"from langchain.pydantic_v1 import BaseModel, Field\n",
|
||||
"from langchain.schema.messages import AIMessage, HumanMessage\n",
|
||||
"from langchain.tools import tool\n",
|
||||
"from langchain.tools.render import format_tool_to_openai_function\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"# This is used to tell the model how to best use the retriever.\n",
|
||||
"\n",
|
||||
|
||||
@@ -508,8 +508,8 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.schema.messages import HumanMessage\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def image_summarize(img_base64, prompt):\n",
|
||||
|
||||
+1
-1
@@ -328,10 +328,10 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.prompts import ChatPromptTemplate\n",
|
||||
"from langchain.schema.output_parser import StrOutputParser\n",
|
||||
"from langchain.schema.runnable import RunnablePassthrough\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def rag_chain(retriever):\n",
|
||||
|
||||
@@ -451,11 +451,11 @@
|
||||
"source": [
|
||||
"from operator import itemgetter\n",
|
||||
"\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.prompts import ChatPromptTemplate\n",
|
||||
"from langchain.schema.document import Document\n",
|
||||
"from langchain.schema.output_parser import StrOutputParser\n",
|
||||
"from langchain.schema.runnable.passthrough import RunnableAssign\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"# Prompt\n",
|
||||
"prompt = ChatPromptTemplate.from_messages(\n",
|
||||
|
||||
+1
-1
@@ -126,7 +126,6 @@
|
||||
"source": [
|
||||
"import uuid\n",
|
||||
"\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.document_loaders import PyPDFLoader\n",
|
||||
"from langchain.embeddings import OpenAIEmbeddings\n",
|
||||
"from langchain.prompts import ChatPromptTemplate\n",
|
||||
@@ -138,6 +137,7 @@
|
||||
"from langchain.storage import InMemoryStore\n",
|
||||
"from langchain.text_splitter import RecursiveCharacterTextSplitter\n",
|
||||
"from langchain.vectorstores import Chroma\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def prepare_documents(docs):\n",
|
||||
|
||||
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
@@ -1,8 +1,8 @@
|
||||
from typing import Optional
|
||||
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.chat_models.base import BaseChatModel
|
||||
from langchain.smith import RunEvalConfig
|
||||
from langchain_openai import ChatOpenAI
|
||||
|
||||
|
||||
def get_eval_config(eval_llm: Optional[BaseChatModel] = None) -> RunEvalConfig:
|
||||
|
||||
@@ -2,10 +2,10 @@
|
||||
from typing import Any, Dict, List, Optional, Type
|
||||
|
||||
from langchain.chains.openai_functions import convert_to_openai_function
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
|
||||
from langchain.prompts import ChatPromptTemplate
|
||||
from langchain.schema.runnable import Runnable
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith.client import Client
|
||||
from pydantic import BaseModel
|
||||
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
from typing import Optional
|
||||
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.evaluation import load_evaluator
|
||||
from langchain.smith import RunEvalConfig
|
||||
from langchain_openai import ChatOpenAI
|
||||
|
||||
try:
|
||||
from langchain.schema.language_model import BaseLanguageModel
|
||||
|
||||
@@ -1,9 +1,9 @@
|
||||
from typing import Optional
|
||||
|
||||
from langchain.base_language import BaseLanguageModel
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.schema.retriever import BaseRetriever
|
||||
from langchain.schema.runnable import Runnable
|
||||
from langchain_openai import ChatOpenAI
|
||||
|
||||
from langchain_benchmarks.rag.tasks.langchain_docs.architectures.crqa import (
|
||||
create_response_chain,
|
||||
|
||||
@@ -3,7 +3,6 @@ import os
|
||||
from functools import partial
|
||||
from typing import Callable, Iterable, List, Optional
|
||||
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.indexes import SQLRecordManager, index
|
||||
from langchain.output_parsers.openai_functions import JsonKeyOutputFunctionsParser
|
||||
from langchain.prompts import ChatPromptTemplate
|
||||
@@ -18,6 +17,7 @@ from langchain.schema.storage import BaseStore
|
||||
from langchain.schema.vectorstore import VectorStore
|
||||
from langchain.storage import InMemoryStore
|
||||
from langchain.text_splitter import RecursiveCharacterTextSplitter, TextSplitter
|
||||
from langchain_openai import ChatOpenAI
|
||||
from tqdm.auto import tqdm
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
@@ -10,11 +10,11 @@ from typing import Any, Literal, Optional, Union
|
||||
|
||||
from langchain.callbacks.manager import collect_runs
|
||||
from langchain.chains import LLMChain
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.evaluation import EvaluatorType, StringEvaluator, load_evaluator
|
||||
from langchain.evaluation.schema import StringEvaluator
|
||||
from langchain.smith import RunEvalConfig
|
||||
from langchain_core.language_models import BaseChatModel, BaseLanguageModel
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith.evaluation.evaluator import (
|
||||
EvaluationResult,
|
||||
EvaluationResults,
|
||||
|
||||
@@ -33,7 +33,9 @@ INPUT_A: input_a here
|
||||
INPUT_B: input_b here
|
||||
COMPARISON: CORRECT or INCORRECT here
|
||||
|
||||
Ignore differences in punctuation and phrasing between the student answer and true answer.
|
||||
Ignore differences in punctuation and phrasing between the student answer and true answer, please only compare the first 4 decimal digits.
|
||||
|
||||
For instance if INPUT_A = 123.6751345 and INPUT_B = 123.6751456 you should return CORRECT, since the first 4 decimal points match.
|
||||
|
||||
Begin!
|
||||
|
||||
|
||||
@@ -0,0 +1,996 @@
|
||||
from datetime import datetime
|
||||
from typing import List, Literal, Union, cast
|
||||
|
||||
from langchain.pydantic_v1 import BaseModel, Field
|
||||
from langchain.tools import BaseTool, tool
|
||||
from langchain_core.messages import HumanMessage
|
||||
from langsmith.client import Client
|
||||
|
||||
from langchain_benchmarks.schema import ToolUsageEnvironment, ToolUsageTask
|
||||
|
||||
|
||||
class DocQuery(BaseModel):
|
||||
"""Query against documentation"""
|
||||
|
||||
query: str = Field(..., description="The question to answer")
|
||||
source: Literal["langchain", "langsmith", "langgraph"] = Field(
|
||||
...,
|
||||
description="The documentation source to search against. Should be one of 'langchain', 'langsmith', or "
|
||||
"'langgraph' depending on which one product the user question pertains to",
|
||||
)
|
||||
|
||||
|
||||
class TweetQuery(BaseModel):
|
||||
"""Query against tweets"""
|
||||
|
||||
subject: str = Field(..., description="Subject to search for")
|
||||
min_likes: Union[int, None] = Field(
|
||||
None, description="Minimum amount of likes on the tweet"
|
||||
)
|
||||
max_likes: Union[int, None] = Field(
|
||||
None, description="Maximum amount of likes on the tweet"
|
||||
)
|
||||
start_date: Union[datetime, None] = Field(
|
||||
None, description="Earliest date to start pulling tweets from"
|
||||
)
|
||||
end_date: Union[datetime, None] = Field(
|
||||
None,
|
||||
description="Latest date to pull tweets from, None if pulling up to the present",
|
||||
)
|
||||
has_link: bool = Field(
|
||||
False, description="Whether to query for tweets that have a link."
|
||||
)
|
||||
|
||||
|
||||
class BlogQuery(BaseModel):
|
||||
"""Query against blog posts"""
|
||||
|
||||
subject: Union[str, None] = Field(..., description="Subject to search for")
|
||||
authors: List[str] = Field(
|
||||
None,
|
||||
description="Authors to search for. None if not searching for a speific author, list if searching for more than one.",
|
||||
)
|
||||
start_date: Union[datetime, None] = Field(
|
||||
None, description="Earliest date to start pulling blog posts from"
|
||||
)
|
||||
end_date: Union[datetime, None] = Field(
|
||||
None, description="Latest date to pull blog posts from"
|
||||
)
|
||||
|
||||
|
||||
def get_environment() -> ToolUsageEnvironment:
|
||||
"""Create an environment."""
|
||||
tools = cast(
|
||||
List[BaseTool],
|
||||
[tool(func) for func in [TweetQuery, DocQuery, BlogQuery]],
|
||||
)
|
||||
return ToolUsageEnvironment(
|
||||
tools=tools,
|
||||
read_state=None,
|
||||
)
|
||||
|
||||
|
||||
DOC_DATASET = [
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Can I use the send method to map-reduce the values of different branch points?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "send method map-reduce", "source": "langgraph"},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("where is olllama function calling mentioned?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "ollama function calling", "source": "langchain"},
|
||||
},
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "ollama function calling",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
"has_link": False,
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "ollama function calling",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage("Are pairwise evals supported for different models?")
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "pairwise evals different models",
|
||||
"source": "langsmith",
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("Can a user update state during a run?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "user update state", "source": "langgraph"},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("Can I change config after each AI response?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "update model config", "source": "langchain"},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"How can I build my own run rules? Can I set up a schedule for them?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "custom run rules", "source": "langsmith"},
|
||||
},
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "run rules schedule", "source": "langsmith"},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("Is there a page on routing functions?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "routing functions", "source": "langgraph"},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage("Is there information on using Pinecone as a vectorstore?")
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "Pinecone vectorstore",
|
||||
"source": "langchain",
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "Pinecone vectorstore",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("is it possible to prevent exposing personal data?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "personal data privacy", "source": "langsmith"},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("How do you use conditional entry?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "conditional entry", "source": "langgraph"},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"How do I extract text from PDF data using PyPDF? Can I combine image and text in a prompt?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "PDF extraction using PyPDF", "source": "langchain"},
|
||||
},
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "combine image and text in a prompt",
|
||||
"source": "langchain",
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"How do I setup automation rules for my chat model app? How do I view logs for those rules?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "automation rules for chat model app",
|
||||
"source": "langsmith",
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "automation rules logs", "source": "langsmith"},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage("where can I read about how use Chroma embeddings locally?")
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "local Chroma embeddings", "source": "langchain"},
|
||||
},
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "local Chroma embeddings",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("how to index documents in a RAG app?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "index documents RAG app", "source": "langchain"},
|
||||
},
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "index documents RAG app", "source": "langgraph"},
|
||||
},
|
||||
],
|
||||
},
|
||||
]
|
||||
|
||||
TWEET_DATASET = [
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Did we have any announcements about agents with more than 1000 likes that also included a link?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "agents",
|
||||
"min_likes": 1000,
|
||||
"max_likes": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
"has_link": True,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Are there any posts about evaluators by langchain with less than 100 likes?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "evaluators",
|
||||
"min_likes": None,
|
||||
"max_likes": 100,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
"has_link": False,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Is there anywhere on socials where we link to the anthropic website in the last year?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "anthropic",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": datetime(2023, 1, 1),
|
||||
"end_date": None,
|
||||
"has_link": True,
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "anthropic",
|
||||
"authors": None,
|
||||
"start_date": datetime(2023, 1, 1),
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("In Q2 2023 what updates to LangSmith were made?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "LangSmith",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": datetime(2023, 4, 1),
|
||||
"end_date": datetime(2023, 6, 30),
|
||||
"has_link": False,
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "LangSmith",
|
||||
"authors": None,
|
||||
"start_date": datetime(2023, 4, 1),
|
||||
"end_date": datetime(2023, 6, 30),
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Were there any social media posts with triple digit likes about few shot prompting?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "few shot prompting",
|
||||
"min_likes": 100,
|
||||
"max_likes": 999,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
"has_link": False,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Are there any posts about LangServe before June 2023 that have more than 2000 likes and include a link?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "LangServe",
|
||||
"min_likes": 2000,
|
||||
"max_likes": None,
|
||||
"start_date": None,
|
||||
"end_date": datetime(2023, 5, 31),
|
||||
"has_link": True,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
]
|
||||
|
||||
BLOG_DATASET = [
|
||||
{
|
||||
"question": [
|
||||
HumanMessage("Have there been release notes in the past year about agents?")
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "agents",
|
||||
"authors": None,
|
||||
"start_date": datetime(2023, 1, 1),
|
||||
"end_date": None,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"how many press releases mentioned chat-gpt in the month after October 2023?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "chat-gpt",
|
||||
"authors": None,
|
||||
"start_date": datetime(2023, 11, 1),
|
||||
"end_date": datetime(2023, 11, 30),
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "chat-gpt",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": datetime(2023, 11, 1),
|
||||
"end_date": datetime(2023, 11, 30),
|
||||
"has_link": False,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage("what has been said about universal configurable models?")
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "universal configurable models",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "universal configurable models",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
"has_link": False,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"In the last week, Have Harrison or Bagatur written anything about passing in runnables as tools in LangChain?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "runnables as tools",
|
||||
"authors": ["Harrison", "Bagatur"],
|
||||
"start_date": datetime(2023, 12, 25),
|
||||
"end_date": None,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Are there any case studies of agents running on swe-benchmark?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "agents running on swe-benchmark",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("Why is using fewshot prompting helpful?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "fewshot prompting",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "few shot prompting", "source": "langchain"},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"i need to implement similarity search with filtering in FAISS. how can i do that in my app?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "similarity search with FAISS",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
] # Realease notes/announcements + Case studies +
|
||||
|
||||
AMBIGUOUS_DATASET = [
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"I want to migrate from agentexecutor to langgraph. What do I need to do?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "migrate agentexecutor", "source": "langchain"},
|
||||
},
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "migrate agentexecutor", "source": "langgraph"},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"In the last month, what are the latest updates to the openai partner package?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "openai partner package",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": datetime(2023, 12, 1),
|
||||
"end_date": None,
|
||||
"has_link": False,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"What are best practices for setting up a document loader for a RAG chain?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "document loader for RAG chain",
|
||||
"source": "langchain",
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "document loader best practies",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("case studies using langgraph last week?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "langgraph case studies",
|
||||
"authors": None,
|
||||
"start_date": datetime(2023, 12, 25),
|
||||
"end_date": None,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
]
|
||||
|
||||
DATASET = DOC_DATASET + TWEET_DATASET + BLOG_DATASET + AMBIGUOUS_DATASET
|
||||
|
||||
QUERY_ANALYSIS_TASK = ToolUsageTask(
|
||||
name="Extraction Task",
|
||||
dataset_id="https://smith.langchain.com/public/594f9f60-30a0-49bf-b075-f44beabf546a/d",
|
||||
create_environment=get_environment,
|
||||
instructions=(
|
||||
"""
|
||||
You are requested to generate queries for searching either through tweets, docs, or blog entries.
|
||||
Inside the docs there are three different sources that you may wish to query for: LangGraph, LangSmith, or LangChain.
|
||||
LangGraph is a library for building multi-actor applications with LLMs, used to create agent and multi-agent workflows.
|
||||
LangSmith is an all-in-one developer platform for every step of the LLM-powered application lifecycle.
|
||||
It helps you debug, evaluate, test, and monitor your LLM applications. LangChain is a framework to build with LLMs by chaining interoperable components.
|
||||
One last important thing to remember is that some queries will ask for date ranges, and you must remember that today is 2024-01-01. Also, remember that \
|
||||
each question should be answered by a single query. In addition, you can return multiple queries to answer one question. Do not generate text, just tool calls that \
|
||||
if executed would answer the users question. Do NOT pass the whole question as the query/subject, only extract key ideas/words.
|
||||
"""
|
||||
),
|
||||
description=(
|
||||
"""\
|
||||
An environment that contains three different mock query tools for searching through LangChain material.
|
||||
|
||||
The three tools are for querying LangChain documentation, tweets, and blogs respectively.
|
||||
|
||||
The objective of the task it to measure how well the agent can select the correct tool and \
|
||||
select the right parameters for the query. It is not a test of the actual querying process, \
|
||||
merely the process of constructing the query.
|
||||
"""
|
||||
),
|
||||
eval_params={
|
||||
"output_evaluation": "qa_math_without_question",
|
||||
},
|
||||
)
|
||||
|
||||
FEW_SHOT_DATASET = [
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"What are good rules to follow when using multi modal chat models?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "multi modal chat models", "source": "langchain"},
|
||||
},
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "multi modal chat models",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage("How do you build a RAG chain with a Postgres vectorstore?")
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "RAG chain with Postgres vectorstore",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "RAG chain with Postgres vectorstore",
|
||||
"source": "langchain",
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage("What case studies have we written about tool usage?")
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "tool usage case study",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("How do I migrate from run_on_dataset to evaluate?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "migrate run_on_dataset to evaluate",
|
||||
"source": "langchain",
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "migrate run_on_dataset to evaluate",
|
||||
"source": "langsmith",
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Do any of our posts in the last 2 months about Anthropic have less than 100 likes?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "Anthropic",
|
||||
"min_likes": None,
|
||||
"max_likes": 100,
|
||||
"start_date": datetime(2023, 11, 1),
|
||||
"end_date": None,
|
||||
"has_link": True,
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Did we release any information about claude-3.5 in the last week?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "claude-3.5",
|
||||
"authors": None,
|
||||
"start_date": datetime(2023, 12, 25),
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "claude-3.5",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": datetime(2023, 12, 25),
|
||||
"end_date": None,
|
||||
"has_link": False,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Do we have press statements about filtering traces by metadata before October 2023?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "filtering traces by metadata",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": datetime(2023, 9, 30),
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "filtering traces by metadata",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": None,
|
||||
"end_date": datetime(2023, 9, 30),
|
||||
"has_link": False,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"What updates to mistral partner package were posted in the last year?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "mistral partner package",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": datetime(2023, 1, 1),
|
||||
"end_date": None,
|
||||
"has_link": False,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"Have there been updates to the best practices for initializing chat models in the past month?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "best practices for initializing chat models",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": datetime(2023, 12, 1),
|
||||
"end_date": None,
|
||||
"has_link": False,
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "best practices for initializing chat models",
|
||||
"authors": None,
|
||||
"start_date": datetime(2023, 12, 1),
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"How can I learn about the differences between chat agents and graphs"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "differences between chat agents and graphs",
|
||||
"source": "langchain",
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "differences between chat agents and graphs",
|
||||
"source": "langgraph",
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [
|
||||
HumanMessage(
|
||||
"What are good practices to follow for switching from legacy packages?"
|
||||
)
|
||||
],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "switching from legacy packages",
|
||||
"source": "langchain",
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "switching from legacy packages",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("What data is exposed when I run custom evals?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {
|
||||
"query": "data exposed running custom evaluation",
|
||||
"source": "langsmith",
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
"question": [HumanMessage("Where are document loaders talked about?")],
|
||||
"tool_calls": [
|
||||
{
|
||||
"name": "DocQuery",
|
||||
"args": {"query": "document loaders", "source": "langchain"},
|
||||
},
|
||||
{
|
||||
"name": "TweetQuery",
|
||||
"args": {
|
||||
"subject": "document loaders",
|
||||
"min_likes": None,
|
||||
"max_likes": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
"has_link": False,
|
||||
},
|
||||
},
|
||||
{
|
||||
"name": "BlogQuery",
|
||||
"args": {
|
||||
"subject": "document loaders",
|
||||
"authors": None,
|
||||
"start_date": None,
|
||||
"end_date": None,
|
||||
},
|
||||
},
|
||||
],
|
||||
},
|
||||
]
|
||||
|
||||
|
||||
def _create_dataset(examples: list, dataset_id: str) -> None:
|
||||
"""Create a dataset with the langsmith client."""
|
||||
|
||||
client = Client()
|
||||
for example in examples:
|
||||
client.create_example(
|
||||
inputs={"question": example["question"]},
|
||||
outputs={"reference": example["tool_calls"]},
|
||||
dataset_id=dataset_id,
|
||||
)
|
||||
Generated
+1311
-1915
File diff suppressed because it is too large
Load Diff
+8
-29
@@ -1,6 +1,6 @@
|
||||
[tool.poetry]
|
||||
name = "langchain-benchmarks"
|
||||
version = "0.0.12"
|
||||
version = "0.0.14"
|
||||
description = "🦜💪 Flex those feathers!"
|
||||
authors = ["LangChain AI"]
|
||||
license = "MIT"
|
||||
@@ -8,42 +8,25 @@ readme = "README.md"
|
||||
|
||||
[tool.poetry.dependencies]
|
||||
python = "^3.8.1"
|
||||
langchain = "^0.1.15"
|
||||
langchain = "^0.2.7"
|
||||
langchain-community = "^0.2"
|
||||
langsmith = ">=0.0.70"
|
||||
tqdm = "^4"
|
||||
ipywidgets = "^8"
|
||||
tabulate = ">=0.8.0"
|
||||
langchain-openai = "^0.1.14"
|
||||
|
||||
[tool.poetry.group.dev]
|
||||
optional = true
|
||||
|
||||
[tool.poetry.group.dev.dependencies]
|
||||
jupyter = "^1.0.0"
|
||||
langchain-core = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/core"}
|
||||
langchain = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/langchain"}
|
||||
langchain-anthropic = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/anthropic"}
|
||||
langchain-google-vertexai= {git = "https://github.com/langchain-ai/langchain-google.git", subdirectory = "libs/vertexai/"}
|
||||
langchain-fireworks = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/fireworks"}
|
||||
langchain-mistralai = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/mistralai"}
|
||||
langchain-cohere = {git = "https://github.com/langchain-ai/langchain-cohere.git", subdirectory="libs/cohere"}
|
||||
langchain-groq = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/groq"}
|
||||
langchain-openai = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/openai"}
|
||||
|
||||
|
||||
[tool.poetry.group.typing]
|
||||
optional = true
|
||||
|
||||
[tool.poetry.group.typing.dependencies]
|
||||
mypy = "^1.7.0"
|
||||
langchain-core = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/core"}
|
||||
langchain = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/langchain"}
|
||||
langchain-anthropic = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/anthropic"}
|
||||
langchain-fireworks = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/fireworks"}
|
||||
langchain-mistralai = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/mistralai"}
|
||||
langchain-cohere = {git = "https://github.com/langchain-ai/langchain-cohere.git", subdirectory="libs/cohere"}
|
||||
langchain-groq = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/groq"}
|
||||
langchain-openai = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/openai"}
|
||||
|
||||
[tool.poetry.group.lint]
|
||||
optional = true
|
||||
|
||||
@@ -74,14 +57,10 @@ pytest-socket = "^0.6.0"
|
||||
pytest-watch = "^4.2.0"
|
||||
pytest-timeout = "^2.2.0"
|
||||
freezegun = "^1.3.1"
|
||||
langchain-core = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/core"}
|
||||
langchain = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/langchain"}
|
||||
langchain-anthropic = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/anthropic"}
|
||||
langchain-fireworks = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/fireworks"}
|
||||
langchain-mistralai = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/mistralai"}
|
||||
langchain-cohere = {git = "https://github.com/langchain-ai/langchain-cohere.git", subdirectory="libs/cohere"}
|
||||
langchain-groq = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/groq"}
|
||||
langchain-openai = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/openai"}
|
||||
langchain-anthropic = "^0.1.19"
|
||||
langchain-fireworks = "^0.1.4"
|
||||
langchain-mistralai = "^0.1.9"
|
||||
langchain-groq = "^0.1.6"
|
||||
|
||||
[tool.ruff]
|
||||
select = [
|
||||
|
||||
@@ -0,0 +1,192 @@
|
||||
import datetime
|
||||
import sys
|
||||
import uuid
|
||||
|
||||
from langchain_core.messages import HumanMessage, SystemMessage, ToolMessage
|
||||
from langchain_core.messages.utils import convert_to_messages
|
||||
from langsmith.client import Client
|
||||
|
||||
from langchain_benchmarks import __version__
|
||||
|
||||
sys.path.append("./../langchain_benchmarks")
|
||||
from langchain.agents import AgentExecutor, create_tool_calling_agent
|
||||
from langchain.chat_models import init_chat_model
|
||||
from langsmith.evaluation import evaluate
|
||||
from tool_usage.tasks.multiverse_math import *
|
||||
|
||||
tests = [
|
||||
(
|
||||
"claude-3-haiku-20240307",
|
||||
"anthropic",
|
||||
),
|
||||
(
|
||||
"claude-3-sonnet-20240229",
|
||||
"anthropic",
|
||||
),
|
||||
(
|
||||
"claude-3-opus-20240229",
|
||||
"anthropic",
|
||||
),
|
||||
(
|
||||
"claude-3-5-sonnet-20240620",
|
||||
"anthropic",
|
||||
),
|
||||
("gpt-3.5-turbo-0125", "openai"),
|
||||
(
|
||||
"gpt-4o",
|
||||
"openai",
|
||||
),
|
||||
("gpt-4o-mini", "openai"),
|
||||
]
|
||||
|
||||
client = Client() # Launch langsmith client for cloning datasets
|
||||
|
||||
|
||||
def get_few_shot_messages(task_name):
|
||||
if task_name == "Multiverse Math":
|
||||
uncleaned_examples = [
|
||||
e
|
||||
for e in client.list_examples(
|
||||
dataset_name="multiverse-math-examples-for-few-shot"
|
||||
)
|
||||
]
|
||||
few_shot_messages = []
|
||||
few_shot_three_messages = []
|
||||
examples = []
|
||||
for i in range(len(uncleaned_examples)):
|
||||
converted_messages = convert_to_messages(
|
||||
uncleaned_examples[i].outputs["output"]
|
||||
)
|
||||
examples.append(
|
||||
# The message at index 1 is the human message asking the actual math question (0th message is system prompt)
|
||||
{
|
||||
"question": converted_messages[1].content,
|
||||
"messages": [
|
||||
m
|
||||
for m in converted_messages
|
||||
if isinstance(m, SystemMessage) == False
|
||||
],
|
||||
}
|
||||
)
|
||||
few_shot_messages += converted_messages
|
||||
if i < 3:
|
||||
few_shot_three_messages += converted_messages
|
||||
|
||||
return (
|
||||
examples,
|
||||
[m for m in few_shot_messages if not isinstance(m, SystemMessage)],
|
||||
[m for m in few_shot_three_messages if not isinstance(m, SystemMessage)],
|
||||
)
|
||||
else:
|
||||
raise ValueError("Few shot messages not supported for this dataset")
|
||||
|
||||
|
||||
def turn_messages_to_str(few_shot_messages):
|
||||
few_shot_str = ""
|
||||
for m in few_shot_messages:
|
||||
if isinstance(m.content, list):
|
||||
few_shot_str += "<|im_start|>assistant"
|
||||
for tool_use in m.content:
|
||||
if "name" in tool_use:
|
||||
few_shot_str += f"Use tool {tool_use['name']}, input: {', '.join(f'{k}:{v}' for k,v in tool_use['input'].items())}"
|
||||
else:
|
||||
few_shot_str += tool_use["text"]
|
||||
few_shot_str += "\n"
|
||||
few_shot_str += "\n<|im_end|>"
|
||||
else:
|
||||
if isinstance(m, HumanMessage):
|
||||
few_shot_str += f"<|im_start|>user\n{m.content}\n<|im_end|>"
|
||||
elif isinstance(m, ToolMessage):
|
||||
few_shot_str += f"<|im_start|>tool\n{m.content}\n<|im_end|>"
|
||||
else:
|
||||
few_shot_str += f"<|im_start|>assistant\n{m.content}\n<|im_end|>"
|
||||
|
||||
few_shot_str += "\n"
|
||||
return few_shot_str
|
||||
|
||||
|
||||
def get_few_shot_str_from_messages(few_shot_messages, few_shot_three_messages):
|
||||
few_shot_str = turn_messages_to_str(few_shot_messages)
|
||||
few_shot_three_str = turn_messages_to_str(few_shot_three_messages)
|
||||
return few_shot_str, few_shot_three_str
|
||||
|
||||
|
||||
def get_prompts(task_name, **kwargs):
|
||||
if task_name == "Multiverse Math":
|
||||
return [
|
||||
(
|
||||
client.pull_prompt("langchain-ai/multiverse-math-no-few-shot"),
|
||||
"no-few-shot",
|
||||
),
|
||||
(
|
||||
client.pull_prompt("langchain-ai/multiverse-math-few-shot-messages"),
|
||||
"few-shot-messages",
|
||||
),
|
||||
(
|
||||
client.pull_prompt("langchain-ai/multiverse-math-few-shot-str"),
|
||||
"few-shot-string",
|
||||
),
|
||||
(
|
||||
client.pull_prompt("langchain-ai/multiverse-math-few-shot-3-messages"),
|
||||
"few-shot-three-messages",
|
||||
),
|
||||
(
|
||||
client.pull_prompt("langchain-ai/multiverse-math-few-shot-3-str"),
|
||||
"few-shot-three-strings",
|
||||
),
|
||||
]
|
||||
|
||||
|
||||
def predict_from_callable(callable, instructions):
|
||||
def predict(run):
|
||||
return callable.invoke(
|
||||
{"question": run["question"], "instructions": instructions}
|
||||
)
|
||||
|
||||
return predict
|
||||
|
||||
|
||||
experiment_uuid = uuid.uuid4().hex[:4]
|
||||
today = datetime.date.today().isoformat()
|
||||
|
||||
task = MULTIVERSE_MATH
|
||||
dataset_name = task.name
|
||||
examples, few_shot_messages, few_shot_three_messages = get_few_shot_messages(task.name)
|
||||
few_shot_str, few_shot_three_str = get_few_shot_str_from_messages(
|
||||
few_shot_messages, few_shot_three_messages
|
||||
)
|
||||
|
||||
prompts = get_prompts(
|
||||
task.name,
|
||||
examples=examples,
|
||||
few_shot_three_messages=few_shot_three_messages,
|
||||
few_shot_three_str=few_shot_three_str,
|
||||
)
|
||||
|
||||
for model_name, model_provider in tests:
|
||||
model = init_chat_model(model_name, model_provider=model_provider, temperature=0)
|
||||
|
||||
print(f"Benchmarking {task.name} with model: {model_name}")
|
||||
eval_config = task.get_eval_config()
|
||||
|
||||
for prompt, prompt_name in prompts:
|
||||
tools = task.create_environment().tools
|
||||
agent = create_tool_calling_agent(model, tools, prompt)
|
||||
agent_executor = AgentExecutor(
|
||||
agent=agent, tools=tools, return_intermediate_steps=True
|
||||
)
|
||||
|
||||
evaluate(
|
||||
predict_from_callable(agent_executor, task.instructions),
|
||||
data=dataset_name,
|
||||
evaluators=eval_config.custom_evaluators,
|
||||
max_concurrency=5,
|
||||
metadata={
|
||||
"model": model_name,
|
||||
"id": experiment_uuid,
|
||||
"task": task.name,
|
||||
"date": today,
|
||||
"langchain_benchmarks_version": __version__,
|
||||
},
|
||||
experiment_prefix=f"{model_name}-{task.name}-{prompt_name}",
|
||||
)
|
||||
@@ -0,0 +1,331 @@
|
||||
import uuid
|
||||
from collections import Counter
|
||||
from datetime import datetime
|
||||
from typing import Optional
|
||||
|
||||
from langchain.chat_models import init_chat_model
|
||||
from langchain_community.vectorstores import FAISS
|
||||
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
|
||||
from langchain_core.messages import AIMessage, HumanMessage, ToolMessage
|
||||
from langchain_core.output_parsers import StrOutputParser
|
||||
from langchain_core.prompts import (
|
||||
ChatPromptTemplate,
|
||||
FewShotChatMessagePromptTemplate,
|
||||
MessagesPlaceholder,
|
||||
)
|
||||
from langchain_openai import OpenAIEmbeddings
|
||||
from langsmith.client import Client
|
||||
from langsmith.evaluation import evaluate
|
||||
from langsmith.evaluation.evaluator import EvaluationResult, EvaluationResults
|
||||
from langsmith.schemas import Example, Run
|
||||
|
||||
from langchain_benchmarks.tool_usage.tasks.query_analysis import (
|
||||
QUERY_ANALYSIS_TASK,
|
||||
BlogQuery,
|
||||
DocQuery,
|
||||
TweetQuery,
|
||||
)
|
||||
|
||||
|
||||
def calculate_recall(A, B):
|
||||
# Count the occurrences of each element in A and B
|
||||
count_A = Counter(A)
|
||||
count_B = Counter(B)
|
||||
|
||||
# Calculate the number of true positives
|
||||
true_positives = sum(min(count_A[elem], count_B.get(elem, 0)) for elem in count_A)
|
||||
|
||||
# Calculate recall
|
||||
recall = true_positives / sum(count_A.values()) if count_A else 0
|
||||
|
||||
return recall
|
||||
|
||||
|
||||
client = Client()
|
||||
|
||||
|
||||
def is_iso_format(date_str):
|
||||
if not isinstance(date_str, str):
|
||||
return False
|
||||
try:
|
||||
# Try to parse the string with datetime.fromisoformat
|
||||
datetime.fromisoformat(date_str)
|
||||
return True
|
||||
except ValueError:
|
||||
return False
|
||||
|
||||
|
||||
llm_judge = init_chat_model("gpt-4o")
|
||||
|
||||
judge_prompt = ChatPromptTemplate.from_messages(
|
||||
[
|
||||
(
|
||||
"system",
|
||||
"You are an llm tasked with determining if the subject extracted by another LLM is an accurate "
|
||||
"representation of the correct answer. You are to check for general semantic similarity since the words might not "
|
||||
"match up perfectly but the meaning might still be the same. Return YES if the answers match, and NO otherwise. "
|
||||
"Never return anything other than YES or NO.",
|
||||
),
|
||||
(
|
||||
"human",
|
||||
"Is this query: {run_query} somewhat similar to this reference query: {reference_query}",
|
||||
),
|
||||
]
|
||||
)
|
||||
|
||||
judge_chain = judge_prompt | llm_judge | StrOutputParser()
|
||||
|
||||
tools = [DocQuery, TweetQuery, BlogQuery]
|
||||
|
||||
|
||||
def compare_outputs(run_outputs: dict, example_outputs: dict) -> EvaluationResults:
|
||||
if len(run_outputs["response"].tool_calls) == 0:
|
||||
correct_tool_score, deterministic_score, nondeterministic_score = 0, 0, 0
|
||||
else:
|
||||
# Chose the correct tool
|
||||
reference_tools = [tool["name"] for tool in example_outputs["reference"]]
|
||||
outputted_tools = [tool["name"] for tool in run_outputs["response"].tool_calls]
|
||||
correct_tool_score = calculate_recall(reference_tools, outputted_tools)
|
||||
|
||||
# Has the correct deterministic args
|
||||
deterministic_score = 0
|
||||
# Has the correct in-deterministic args
|
||||
nondeterministic_score = 0
|
||||
|
||||
if correct_tool_score == 1:
|
||||
deterministic_score, nondeterministic_score = 1, 1
|
||||
for tool in example_outputs["reference"]:
|
||||
corresponding_response_tool = [
|
||||
t
|
||||
for t in run_outputs["response"].tool_calls
|
||||
if t["name"] == tool["name"]
|
||||
][0]["args"]
|
||||
for arg in tool["args"]:
|
||||
if arg in ["query", "subject"]:
|
||||
ans = judge_chain.invoke(
|
||||
{
|
||||
"run_query": corresponding_response_tool[arg],
|
||||
"reference_query": tool["args"][arg],
|
||||
}
|
||||
)
|
||||
nondeterministic_score = 1 if ans == "YES" else 0
|
||||
else:
|
||||
if (
|
||||
tool["args"][arg] and arg not in corresponding_response_tool
|
||||
) or (
|
||||
tool["args"][arg]
|
||||
and not (
|
||||
tool["args"][arg] == corresponding_response_tool[arg]
|
||||
)
|
||||
and not (
|
||||
is_iso_format(tool["args"][arg])
|
||||
and is_iso_format(corresponding_response_tool[arg])
|
||||
and datetime.fromisoformat(
|
||||
(corresponding_response_tool[arg])
|
||||
).replace(tzinfo=None)
|
||||
== datetime.fromisoformat(tool["args"][arg])
|
||||
)
|
||||
):
|
||||
deterministic_score = 0
|
||||
# Overall correctness
|
||||
overall_score = int(
|
||||
correct_tool_score == 1
|
||||
and bool(deterministic_score)
|
||||
and bool(nondeterministic_score)
|
||||
)
|
||||
results = [
|
||||
EvaluationResult(
|
||||
key="Correct tool",
|
||||
score=correct_tool_score,
|
||||
),
|
||||
EvaluationResult(
|
||||
key="Correct deterministic args",
|
||||
score=deterministic_score,
|
||||
),
|
||||
EvaluationResult(
|
||||
key="Correct nondeterministic args",
|
||||
score=nondeterministic_score,
|
||||
),
|
||||
EvaluationResult(
|
||||
key="Overall correctness",
|
||||
score=overall_score,
|
||||
),
|
||||
]
|
||||
|
||||
return {"results": results}
|
||||
|
||||
|
||||
def evaluate_run(run: Run, example: Optional[Example] = None) -> EvaluationResults:
|
||||
return compare_outputs(run.outputs, example.outputs)
|
||||
|
||||
|
||||
uncleaned_examples = [
|
||||
e for e in client.list_examples(dataset_name="Extraction Task Few Shot")
|
||||
]
|
||||
static_indices = [0, 2, 5]
|
||||
few_shot_messages, few_shot_str = [], ""
|
||||
few_shot_messages_by_index = {}
|
||||
examples_for_semantic_search = []
|
||||
|
||||
for j, example in enumerate(uncleaned_examples):
|
||||
few_shot_messages_for_example = []
|
||||
few_shot_messages_for_example.append(
|
||||
HumanMessage(
|
||||
name="example_human", content=example.inputs["question"][0]["content"]
|
||||
)
|
||||
)
|
||||
few_shot_messages_for_example.append(
|
||||
AIMessage(
|
||||
name="example_assistant",
|
||||
content="",
|
||||
tool_calls=[
|
||||
{
|
||||
"name": tc["name"],
|
||||
"args": tc["args"],
|
||||
"type": "tool_call",
|
||||
"id": f"{10*j+i}",
|
||||
}
|
||||
for i, tc in enumerate(example.outputs["reference"])
|
||||
],
|
||||
)
|
||||
)
|
||||
few_shot_str += (
|
||||
f"<|im_start|>user\n{example.inputs['question'][0]['content']}\n<|im_end|>"
|
||||
)
|
||||
few_shot_str += "\n<|im_start|>assistant\n"
|
||||
for i, tool_call in enumerate(example.outputs["reference"]):
|
||||
few_shot_messages_for_example.append(
|
||||
ToolMessage(
|
||||
"You have correctly called this tool",
|
||||
name=tool_call["name"],
|
||||
tool_call_id=f"{10*j+i}",
|
||||
)
|
||||
)
|
||||
few_shot_str += f"Tool Call: Name: {tool_call['name']} Args: {{{', '.join(f'{k}: {v}' for k,v in tool_call['args'].items())}}}"
|
||||
few_shot_str += "\n"
|
||||
few_shot_str += "<|im_end|>"
|
||||
|
||||
few_shot_messages += few_shot_messages_for_example
|
||||
few_shot_messages_by_index[j] = few_shot_messages_for_example
|
||||
examples_for_semantic_search.append(
|
||||
{
|
||||
"question": example.inputs["question"][0]["content"],
|
||||
"messages": few_shot_messages_for_example,
|
||||
}
|
||||
)
|
||||
|
||||
prompt = ChatPromptTemplate.from_messages(
|
||||
[
|
||||
("system", "{instructions}"),
|
||||
MessagesPlaceholder("few_shot_message_list"),
|
||||
("human", "{input}"),
|
||||
]
|
||||
)
|
||||
|
||||
|
||||
def predict_for_model(model, instructions, few_shot_method, model_name):
|
||||
few_shot_message_list = []
|
||||
chain = prompt | model.bind_tools(tools).with_retry(stop_after_attempt=5)
|
||||
if few_shot_method == "few-shot-string":
|
||||
instructions += f"\n Here are some examples: \n {few_shot_str}"
|
||||
elif few_shot_method == "few-shot-messages":
|
||||
few_shot_message_list = few_shot_messages
|
||||
elif few_shot_method == "few-shot-static-messages":
|
||||
few_shot_message_list = [
|
||||
message
|
||||
for index in static_indices
|
||||
for message in few_shot_messages_by_index[index]
|
||||
]
|
||||
elif few_shot_method == "few-shot-dynamic-messages":
|
||||
|
||||
def predict(example: dict):
|
||||
example_selector = SemanticSimilarityExampleSelector.from_examples(
|
||||
examples_for_semantic_search,
|
||||
OpenAIEmbeddings(model="text-embedding-3-large"),
|
||||
FAISS,
|
||||
k=3,
|
||||
input_keys=["question"],
|
||||
example_keys=["messages"],
|
||||
)
|
||||
|
||||
few_shot_prompt = FewShotChatMessagePromptTemplate(
|
||||
input_variables=[],
|
||||
example_selector=example_selector,
|
||||
example_prompt=MessagesPlaceholder("messages"),
|
||||
)
|
||||
return {
|
||||
"response": chain.invoke(
|
||||
{
|
||||
"input": example["question"],
|
||||
"instructions": instructions,
|
||||
"few_shot_message_list": few_shot_prompt.invoke(
|
||||
{"question": example["question"][0]["content"]}
|
||||
).messages,
|
||||
}
|
||||
)
|
||||
}
|
||||
|
||||
return predict
|
||||
|
||||
def predict(example: dict):
|
||||
return {
|
||||
"response": chain.invoke(
|
||||
{
|
||||
"input": example["question"],
|
||||
"instructions": instructions,
|
||||
"few_shot_message_list": few_shot_message_list,
|
||||
}
|
||||
)
|
||||
}
|
||||
|
||||
return predict
|
||||
|
||||
|
||||
models = [
|
||||
(
|
||||
"claude-3-haiku-20240307",
|
||||
"anthropic",
|
||||
),
|
||||
(
|
||||
"claude-3-sonnet-20240229",
|
||||
"anthropic",
|
||||
),
|
||||
(
|
||||
"claude-3-opus-20240229",
|
||||
"anthropic",
|
||||
),
|
||||
(
|
||||
"claude-3-5-sonnet-20240620",
|
||||
"anthropic",
|
||||
),
|
||||
("gpt-3.5-turbo-0125", "openai"),
|
||||
("gpt-4o", "openai"),
|
||||
("gpt-4o-mini", "openai"),
|
||||
]
|
||||
|
||||
few_shot_methods = [
|
||||
"no-few-shot",
|
||||
"few-shot-string",
|
||||
"few-shot-messages",
|
||||
"few-shot-static-messages",
|
||||
"few-shot-dynamic-messages",
|
||||
]
|
||||
|
||||
from tqdm import tqdm
|
||||
|
||||
experiment_uuid = uuid.uuid4().hex[:4]
|
||||
for i in tqdm(range(3)):
|
||||
for model_name, model_provider in models:
|
||||
model = init_chat_model(
|
||||
model_name, model_provider=model_provider, temperature=0
|
||||
)
|
||||
for few_shot_method in few_shot_methods:
|
||||
evaluate(
|
||||
predict_for_model(
|
||||
model, QUERY_ANALYSIS_TASK.instructions, few_shot_method, model_name
|
||||
),
|
||||
data=QUERY_ANALYSIS_TASK.name,
|
||||
evaluators=[evaluate_run],
|
||||
experiment_prefix=f"{model_name}-TEST-{i+2}-{few_shot_method}",
|
||||
metadata={"id": experiment_uuid},
|
||||
)
|
||||
Reference in New Issue
Block a user