mirror of
https://github.com/langchain-ai/langchain-benchmarks.git
synced 2026-07-01 22:34:02 -04:00
Compare commits
19 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
12e9107edc | ||
|
|
a7879c10bb | ||
|
|
e2882258b0 | ||
|
|
be682101d8 | ||
|
|
611408d1d3 | ||
|
|
b10c099c7a | ||
|
|
94506e4726 | ||
|
|
ab16d66903 | ||
|
|
47382f82d9 | ||
|
|
17c7794130 | ||
|
|
9378a8d9ed | ||
|
|
84cca0a2ee | ||
|
|
a601b6de9c | ||
|
|
ea10c07358 | ||
|
|
3aae5da769 | ||
|
|
22d279a25c | ||
|
|
357ada3867 | ||
|
|
ab2d93ac6d | ||
|
|
53f727af64 |
@@ -0,0 +1,30 @@
|
||||
name: Weekly Tool Benchmarks
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
schedule:
|
||||
- cron: '0 0 * * 0' # Runs at midnight (00:00) every Sunday (UTC time)
|
||||
|
||||
jobs:
|
||||
run_tool_benchmarks:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
|
||||
- name: Set up Python 3.12 + Poetry ${{ env.POETRY_VERSION }}
|
||||
uses: "./.github/actions/poetry_setup"
|
||||
with:
|
||||
python-version: '3.12'
|
||||
poetry-version: ${{ env.POETRY_VERSION }}
|
||||
working-directory: .
|
||||
cache-key: benchmarks-all
|
||||
|
||||
- name: Install dependencies
|
||||
shell: bash
|
||||
run: |
|
||||
echo "Running tests, installing dependencies with poetry..."
|
||||
poetry install --with test,lint,typing,docs
|
||||
|
||||
- name: Execute Tool Benchmarks
|
||||
run: python scripts/tool_benchmarks.py
|
||||
@@ -10,6 +10,8 @@ lint format: PYTHON_FILES=.
|
||||
lint_diff format_diff: PYTHON_FILES=$(shell git diff --relative=. --name-only --diff-filter=d master | grep -E '\.py$$|\.ipynb$$')
|
||||
|
||||
lint lint_diff:
|
||||
# [ "$(PYTHON_FILES)" = "" ] || poetry run ruff check $(PYTHON_FILES)
|
||||
[ "$(PYTHON_FILES)" = "" ] || poetry run ruff check --select I $(PYTHON_FILES)
|
||||
[ "$(PYTHON_FILES)" = "" ] || poetry run ruff format $(PYTHON_FILES) --diff
|
||||
# [ "$(PYTHON_FILES)" = "" ] || poetry run mypy $(PYTHON_FILES)
|
||||
|
||||
|
||||
@@ -26,10 +26,24 @@ We have several goals in open sourcing this:
|
||||
|
||||
Read some of the articles about benchmarking results on our blog.
|
||||
|
||||
* Agent Tool Use: https://blog.langchain.dev/benchmarking-agent-tool-use/
|
||||
* Query Analysis in High Cardinality Situations: https://blog.langchain.dev/high-cardinality/
|
||||
* Rag on Tables: https://blog.langchain.dev/benchmarking-rag-on-tables/
|
||||
* Q&A over CSV data: https://blog.langchain.dev/benchmarking-question-answering-over-csv-data/
|
||||
* [Agent Tool Use](https://blog.langchain.dev/benchmarking-agent-tool-use/)
|
||||
* [Query Analysis in High Cardinality Situations](https://blog.langchain.dev/high-cardinality/)
|
||||
* [RAG on Tables](https://blog.langchain.dev/benchmarking-rag-on-tables/)
|
||||
* [Q&A over CSV data](https://blog.langchain.dev/benchmarking-question-answering-over-csv-data/)
|
||||
|
||||
|
||||
### Tool Usage (2024-04-18)
|
||||
|
||||
See [tool usage docs](https://langchain-ai.github.io/langchain-benchmarks/notebooks/tool_usage/benchmark_all_tasks.html) to recreate!
|
||||
|
||||
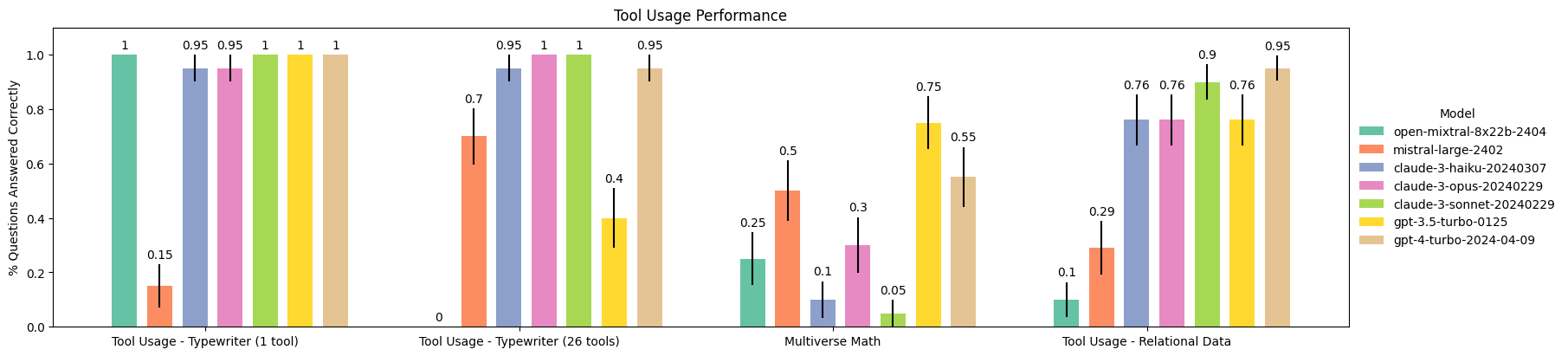
|
||||
|
||||
Explore Agent Traces on LangSmith:
|
||||
|
||||
* [Relational Data](https://smith.langchain.com/public/22721064-dcf6-4e42-be65-e7c46e6835e7/d)
|
||||
* [Tool Usage (1-tool)](https://smith.langchain.com/public/ac23cb40-e392-471f-b129-a893a77b6f62/d)
|
||||
* [Tool Usage (26-tools)](https://smith.langchain.com/public/366bddca-62b3-4b6e-849b-a478abab73db/d)
|
||||
* [Mutiverse Math](https://smith.langchain.com/public/983faff2-54b9-4875-9bf2-c16913e7d489/d)
|
||||
|
||||
## Installation
|
||||
|
||||
|
||||
@@ -3,12 +3,12 @@ from langchain.agents import AgentExecutor, OpenAIFunctionsAgent
|
||||
from langchain.agents.agent_toolkits.conversational_retrieval.tool import (
|
||||
create_retriever_tool,
|
||||
)
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.embeddings import OpenAIEmbeddings
|
||||
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain.tools import PythonAstREPLTool
|
||||
from langchain.vectorstores import FAISS
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
import pandas as pd
|
||||
from langchain.agents.agent_toolkits import create_pandas_dataframe_agent
|
||||
from langchain.agents.agent_types import AgentType
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
import pandas as pd
|
||||
from langchain.agents.agent_toolkits import create_pandas_dataframe_agent
|
||||
from langchain.agents.agent_types import AgentType
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
import pandas as pd
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.prompts import ChatPromptTemplate
|
||||
from langchain.schema.output_parser import StrOutputParser
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
from pandasai import PandasAI
|
||||
|
||||
|
||||
@@ -2,7 +2,7 @@ import pandas as pd
|
||||
import streamlit as st
|
||||
from langchain.agents.agent_toolkits import create_pandas_dataframe_agent
|
||||
from langchain.agents.agent_types import AgentType
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain_openai import ChatOpenAI
|
||||
|
||||
df = pd.read_csv("titanic.csv")
|
||||
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
import streamlit as st
|
||||
from langchain.chains import create_extraction_chain
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
|
||||
st.set_page_config(page_title="🦜🔗 Text-to-graph extraction")
|
||||
|
||||
+1
-1
@@ -3,13 +3,13 @@ from typing import List, Tuple
|
||||
from langchain.agents import AgentExecutor
|
||||
from langchain.agents.format_scratchpad import format_to_openai_functions
|
||||
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
|
||||
from langchain.pydantic_v1 import BaseModel, Field
|
||||
from langchain.schema.messages import AIMessage, HumanMessage
|
||||
from langchain.tools import tool
|
||||
from langchain.tools.render import format_tool_to_openai_function
|
||||
from langchain_docs_retriever.retriever import get_retriever
|
||||
from langchain_openai import ChatOpenAI
|
||||
|
||||
# This is used to tell the model how to best use the retriever.
|
||||
|
||||
|
||||
@@ -7,9 +7,9 @@ from typing import Callable, Optional
|
||||
|
||||
from anthropic_iterative_search.chain import chain as anthropic_agent_chain
|
||||
from chat_langchain.chain import create_chain
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.schema.runnable import Runnable
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
from oai_assistant.chain import agent_executor as openai_assistant_chain
|
||||
from openai_functions_agent import agent_executor as openai_functions_agent_chain
|
||||
|
||||
@@ -259,8 +259,8 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"llm = ChatOpenAI(model=\"gpt-4-1106-preview\", temperature=0).bind_functions(\n",
|
||||
" functions=[task.schema],\n",
|
||||
|
||||
@@ -232,8 +232,8 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"llm = ChatOpenAI(model=\"gpt-3.5-turbo-16k\", temperature=0).bind_functions(\n",
|
||||
" functions=[task.schema],\n",
|
||||
|
||||
@@ -97,7 +97,7 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"from langchain_benchmarks.extraction import get_eval_config\n",
|
||||
"\n",
|
||||
|
||||
@@ -75,6 +75,7 @@
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "7fb27b941602401d91542211134fc71a",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
@@ -728,12 +729,12 @@
|
||||
"from langchain.agents import AgentExecutor\n",
|
||||
"from langchain.agents.format_scratchpad import format_to_openai_functions\n",
|
||||
"from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder\n",
|
||||
"from langchain.pydantic_v1 import BaseModel, Field\n",
|
||||
"from langchain.schema.messages import AIMessage, HumanMessage\n",
|
||||
"from langchain.tools import tool\n",
|
||||
"from langchain.tools.render import format_tool_to_openai_function\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"# This is used to tell the model how to best use the retriever.\n",
|
||||
"\n",
|
||||
|
||||
@@ -508,8 +508,8 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.schema.messages import HumanMessage\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def image_summarize(img_base64, prompt):\n",
|
||||
|
||||
+1
-1
@@ -328,10 +328,10 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.prompts import ChatPromptTemplate\n",
|
||||
"from langchain.schema.output_parser import StrOutputParser\n",
|
||||
"from langchain.schema.runnable import RunnablePassthrough\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def rag_chain(retriever):\n",
|
||||
|
||||
@@ -451,11 +451,11 @@
|
||||
"source": [
|
||||
"from operator import itemgetter\n",
|
||||
"\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.prompts import ChatPromptTemplate\n",
|
||||
"from langchain.schema.document import Document\n",
|
||||
"from langchain.schema.output_parser import StrOutputParser\n",
|
||||
"from langchain.schema.runnable.passthrough import RunnableAssign\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"# Prompt\n",
|
||||
"prompt = ChatPromptTemplate.from_messages(\n",
|
||||
|
||||
+1
-1
@@ -126,7 +126,6 @@
|
||||
"source": [
|
||||
"import uuid\n",
|
||||
"\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.document_loaders import PyPDFLoader\n",
|
||||
"from langchain.embeddings import OpenAIEmbeddings\n",
|
||||
"from langchain.prompts import ChatPromptTemplate\n",
|
||||
@@ -138,6 +137,7 @@
|
||||
"from langchain.storage import InMemoryStore\n",
|
||||
"from langchain.text_splitter import RecursiveCharacterTextSplitter\n",
|
||||
"from langchain.vectorstores import Chroma\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def prepare_documents(docs):\n",
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
from typing import Optional
|
||||
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.chat_models.base import BaseChatModel
|
||||
from langchain.smith import RunEvalConfig
|
||||
from langchain_openai import ChatOpenAI
|
||||
|
||||
|
||||
def get_eval_config(eval_llm: Optional[BaseChatModel] = None) -> RunEvalConfig:
|
||||
|
||||
@@ -2,10 +2,10 @@
|
||||
from typing import Any, Dict, List, Optional, Type
|
||||
|
||||
from langchain.chains.openai_functions import convert_to_openai_function
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
|
||||
from langchain.prompts import ChatPromptTemplate
|
||||
from langchain.schema.runnable import Runnable
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith.client import Client
|
||||
from pydantic import BaseModel
|
||||
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
from typing import Optional
|
||||
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.evaluation import load_evaluator
|
||||
from langchain.smith import RunEvalConfig
|
||||
from langchain_openai import ChatOpenAI
|
||||
|
||||
try:
|
||||
from langchain.schema.language_model import BaseLanguageModel
|
||||
|
||||
@@ -1,9 +1,9 @@
|
||||
from typing import Optional
|
||||
|
||||
from langchain.base_language import BaseLanguageModel
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.schema.retriever import BaseRetriever
|
||||
from langchain.schema.runnable import Runnable
|
||||
from langchain_openai import ChatOpenAI
|
||||
|
||||
from langchain_benchmarks.rag.tasks.langchain_docs.architectures.crqa import (
|
||||
create_response_chain,
|
||||
|
||||
@@ -3,7 +3,6 @@ import os
|
||||
from functools import partial
|
||||
from typing import Callable, Iterable, List, Optional
|
||||
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.indexes import SQLRecordManager, index
|
||||
from langchain.output_parsers.openai_functions import JsonKeyOutputFunctionsParser
|
||||
from langchain.prompts import ChatPromptTemplate
|
||||
@@ -18,6 +17,7 @@ from langchain.schema.storage import BaseStore
|
||||
from langchain.schema.vectorstore import VectorStore
|
||||
from langchain.storage import InMemoryStore
|
||||
from langchain.text_splitter import RecursiveCharacterTextSplitter, TextSplitter
|
||||
from langchain_openai import ChatOpenAI
|
||||
from tqdm.auto import tqdm
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
@@ -300,8 +300,8 @@ def _get_default_path(provider: str, type_: ModelType) -> str:
|
||||
"""Get the default path for a model."""
|
||||
paths = {
|
||||
("anthropic", "chat"): "langchain_anthropic.ChatAnthropic",
|
||||
("anyscale", "chat"): "langchain.chat_models.anyscale.ChatAnyscale",
|
||||
("anyscale", "llm"): "langchain.llms.anyscale.Anyscale",
|
||||
("anyscale", "chat"): "langchain_community.chat_models.anyscale.ChatAnyscale",
|
||||
("anyscale", "llm"): "langchain_community.llms.anyscale.Anyscale",
|
||||
("fireworks", "chat"): "langchain_fireworks.ChatFireworks",
|
||||
("fireworks", "llm"): "langchain_fireworks.Fireworks",
|
||||
("openai", "chat"): "langchain_openai.ChatOpenAI",
|
||||
|
||||
@@ -10,11 +10,11 @@ from typing import Any, Literal, Optional, Union
|
||||
|
||||
from langchain.callbacks.manager import collect_runs
|
||||
from langchain.chains import LLMChain
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.evaluation import EvaluatorType, StringEvaluator, load_evaluator
|
||||
from langchain.evaluation.schema import StringEvaluator
|
||||
from langchain.smith import RunEvalConfig
|
||||
from langchain_core.language_models import BaseChatModel, BaseLanguageModel
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith.evaluation.evaluator import (
|
||||
EvaluationResult,
|
||||
EvaluationResults,
|
||||
|
||||
@@ -47,7 +47,7 @@ from langchain_benchmarks.schema import ToolUsageEnvironment, ToolUsageTask
|
||||
|
||||
def multiply(a: float, b: float) -> float:
|
||||
"""Multiply two numbers; a * b."""
|
||||
return 1.1 * a * b
|
||||
return round(1.1 * a * b, 5)
|
||||
|
||||
|
||||
def divide(a: float, b: float) -> float:
|
||||
@@ -140,7 +140,7 @@ DATASET_TINY = [
|
||||
"expected_steps": ["subtract"],
|
||||
},
|
||||
{
|
||||
"question": "What is -5 if evaluated using the negate function?",
|
||||
"question": "what is the value of the negate function evaluated on the argument -5",
|
||||
"answer": negate(-5),
|
||||
"expected_steps": ["negate"],
|
||||
},
|
||||
|
||||
Generated
+809
-1311
File diff suppressed because it is too large
Load Diff
+7
-28
@@ -8,42 +8,25 @@ readme = "README.md"
|
||||
|
||||
[tool.poetry.dependencies]
|
||||
python = "^3.8.1"
|
||||
langchain = "^0.1.15"
|
||||
langchain = "^0.2.7"
|
||||
langsmith = ">=0.0.70"
|
||||
tqdm = "^4"
|
||||
ipywidgets = "^8"
|
||||
tabulate = ">=0.8.0"
|
||||
langchain-openai = "^0.1.14"
|
||||
langchain-community = "^0.2.6"
|
||||
|
||||
[tool.poetry.group.dev]
|
||||
optional = true
|
||||
|
||||
[tool.poetry.group.dev.dependencies]
|
||||
jupyter = "^1.0.0"
|
||||
langchain-core = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/core"}
|
||||
langchain = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/langchain"}
|
||||
langchain-anthropic = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/anthropic"}
|
||||
langchain-google-vertexai= {git = "https://github.com/langchain-ai/langchain-google.git", subdirectory = "libs/vertexai/"}
|
||||
langchain-fireworks = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/fireworks"}
|
||||
langchain-mistralai = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/mistralai"}
|
||||
langchain-cohere = {git = "https://github.com/langchain-ai/langchain-cohere.git", subdirectory="libs/cohere"}
|
||||
langchain-groq = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/groq"}
|
||||
langchain-openai = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/openai"}
|
||||
|
||||
|
||||
[tool.poetry.group.typing]
|
||||
optional = true
|
||||
|
||||
[tool.poetry.group.typing.dependencies]
|
||||
mypy = "^1.7.0"
|
||||
langchain-core = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/core"}
|
||||
langchain = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/langchain"}
|
||||
langchain-anthropic = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/anthropic"}
|
||||
langchain-fireworks = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/fireworks"}
|
||||
langchain-mistralai = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/mistralai"}
|
||||
langchain-cohere = {git = "https://github.com/langchain-ai/langchain-cohere.git", subdirectory="libs/cohere"}
|
||||
langchain-groq = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/groq"}
|
||||
langchain-openai = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/openai"}
|
||||
|
||||
[tool.poetry.group.lint]
|
||||
optional = true
|
||||
|
||||
@@ -74,14 +57,10 @@ pytest-socket = "^0.6.0"
|
||||
pytest-watch = "^4.2.0"
|
||||
pytest-timeout = "^2.2.0"
|
||||
freezegun = "^1.3.1"
|
||||
langchain-core = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/core"}
|
||||
langchain = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/langchain"}
|
||||
langchain-anthropic = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/anthropic"}
|
||||
langchain-fireworks = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/fireworks"}
|
||||
langchain-mistralai = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/mistralai"}
|
||||
langchain-cohere = {git = "https://github.com/langchain-ai/langchain-cohere.git", subdirectory="libs/cohere"}
|
||||
langchain-groq = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/groq"}
|
||||
langchain-openai = {git = "https://github.com/langchain-ai/langchain.git", subdirectory = "libs/partners/openai"}
|
||||
langchain-anthropic = "^0.1.19"
|
||||
langchain-fireworks = "^0.1.4"
|
||||
langchain-mistralai = "^0.1.9"
|
||||
langchain-groq = "^0.1.6"
|
||||
|
||||
[tool.ruff]
|
||||
select = [
|
||||
|
||||
@@ -0,0 +1,228 @@
|
||||
import datetime
|
||||
import uuid
|
||||
|
||||
from langchain import hub
|
||||
from langchain_community.vectorstores import FAISS
|
||||
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
|
||||
from langchain_core.messages import HumanMessage, SystemMessage
|
||||
from langchain_core.messages.utils import convert_to_messages
|
||||
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
|
||||
from langchain_core.prompts.few_shot import FewShotChatMessagePromptTemplate
|
||||
from langchain_openai import OpenAIEmbeddings
|
||||
from langsmith.client import Client
|
||||
#from langchain_benchmarks import __version__, registry
|
||||
from langchain_benchmarks.rate_limiting import RateLimiter
|
||||
from langchain_benchmarks.tool_usage.agents import StandardAgentFactory
|
||||
import sys
|
||||
sys.path.append("./..")
|
||||
from langchain_benchmarks import __version__, registry
|
||||
from langchain_benchmarks.tool_usage.tasks.multiverse_math import *
|
||||
from langchain.chat_models import init_chat_model
|
||||
from langsmith.evaluation import evaluate
|
||||
from langchain.agents import AgentExecutor, create_tool_calling_agent
|
||||
from langchain.tools import tool
|
||||
|
||||
tests = [
|
||||
("claude-3-haiku-20240307","anthropic",),
|
||||
("claude-3-sonnet-20240229","anthropic",),
|
||||
("claude-3-opus-20240229","anthropic",),
|
||||
("claude-3-5-sonnet-20240620","anthropic",),
|
||||
("gpt-3.5-turbo-0125", "openai"),
|
||||
("gpt-4o","openai",),
|
||||
("gpt-4o-mini","openai"),
|
||||
("llama3-groq-70b-8192-tool-use-preview","groq"),
|
||||
("llama3-groq-8b-8192-tool-use-preview","groq"),
|
||||
("gemini-1.5-pro","google_genai"),
|
||||
("gemini-1.5-flash","google_genai")
|
||||
]
|
||||
|
||||
client = Client() # Launch langsmith client for cloning datasets
|
||||
|
||||
def get_few_shot_messages(task_name):
|
||||
if task_name == "Multiverse Math":
|
||||
uncleaned_examples = [
|
||||
e
|
||||
for e in client.list_examples(
|
||||
dataset_name="multiverse-math-examples-for-few-shot"
|
||||
)
|
||||
]
|
||||
few_shot_messages = []
|
||||
few_shot_three_messages = []
|
||||
examples = []
|
||||
for i in range(len(uncleaned_examples)):
|
||||
converted_messages = convert_to_messages(
|
||||
uncleaned_examples[i].outputs["output"]
|
||||
)
|
||||
examples.append(
|
||||
# The message at index 1 is the human message asking the actual math question (0th message is system prompt)
|
||||
{
|
||||
"question": converted_messages[1].content,
|
||||
"messages": [
|
||||
m
|
||||
for m in converted_messages
|
||||
if isinstance(m, SystemMessage) == False
|
||||
],
|
||||
}
|
||||
)
|
||||
few_shot_messages += converted_messages
|
||||
if i < 3:
|
||||
few_shot_three_messages += converted_messages
|
||||
|
||||
return examples, [
|
||||
m for m in few_shot_messages if not isinstance(m, SystemMessage)
|
||||
], [m for m in few_shot_three_messages if not isinstance(m, SystemMessage)]
|
||||
else:
|
||||
raise ValueError("Few shot messages not supported for this dataset")
|
||||
|
||||
def turn_messages_to_str(few_shot_messages):
|
||||
few_shot_str = ""
|
||||
for m in few_shot_messages:
|
||||
if isinstance(m.content, list):
|
||||
few_shot_str += "AI message: "
|
||||
for tool_use in m.content:
|
||||
if "name" in tool_use:
|
||||
few_shot_str += f"Use tool {tool_use['name']}, input: {', '.join(f'{k}:{v}' for k,v in tool_use['input'].items())}"
|
||||
else:
|
||||
few_shot_str += tool_use["text"]
|
||||
few_shot_str += "\n"
|
||||
else:
|
||||
if isinstance(m, HumanMessage):
|
||||
few_shot_str += f"Human message: {m.content}"
|
||||
else:
|
||||
few_shot_str += f"AI message: {m.content}"
|
||||
|
||||
few_shot_str += "\n"
|
||||
return few_shot_str
|
||||
|
||||
def get_few_shot_str_from_messages(few_shot_messages, few_shot_three_messages):
|
||||
few_shot_str = turn_messages_to_str(few_shot_messages)
|
||||
few_shot_three_str = turn_messages_to_str(few_shot_three_messages)
|
||||
return few_shot_str, few_shot_three_str
|
||||
|
||||
def get_prompts(task_name, **kwargs):
|
||||
if task_name == "Multiverse Math":
|
||||
example_selector = SemanticSimilarityExampleSelector.from_examples(
|
||||
kwargs['examples'],
|
||||
OpenAIEmbeddings(),
|
||||
FAISS,
|
||||
k=3,
|
||||
input_keys=["question"],
|
||||
example_keys=["messages"],
|
||||
)
|
||||
|
||||
few_shot_prompt = FewShotChatMessagePromptTemplate(
|
||||
input_variables=[],
|
||||
example_selector=example_selector,
|
||||
example_prompt=MessagesPlaceholder("messages"),
|
||||
)
|
||||
return [
|
||||
(
|
||||
client.pull_prompt("langchain-ai/multiverse-math-no-few-shot"),
|
||||
"no-few-shot",
|
||||
),
|
||||
(
|
||||
client.pull_prompt("langchain-ai/multiverse-math-few-shot-messages"),
|
||||
"few-shot-messages",
|
||||
),
|
||||
(
|
||||
client.pull_prompt("langchain-ai/multiverse-math-few-shot-str"),
|
||||
"few-shot-string",
|
||||
),
|
||||
(
|
||||
client.pull_prompt("langchain-ai/multiverse-math-few-shot-3-messages"),
|
||||
"few-shot-three-messages",
|
||||
),
|
||||
(
|
||||
client.pull_prompt("langchain-ai/multiverse-math-few-shot-3-str"),
|
||||
"few-shot-three-strings",
|
||||
),
|
||||
(
|
||||
ChatPromptTemplate.from_messages(
|
||||
[
|
||||
(
|
||||
"system",
|
||||
"{instructions} Here are some example conversations of the user interacting with the AI until the correct answer is reached: ",
|
||||
),
|
||||
few_shot_prompt,
|
||||
("human", "{question}"),
|
||||
MessagesPlaceholder("agent_scratchpad"),
|
||||
]
|
||||
),
|
||||
"few-shot-semantic-openai-embeddinga",
|
||||
),
|
||||
]
|
||||
|
||||
def predict_from_callable(callable,instructions):
|
||||
def predict(run):
|
||||
return callable.invoke({"question":run['question'],"instructions":instructions})
|
||||
return predict
|
||||
|
||||
def pi(a: float) -> float:
|
||||
"""Returns a precise value of PI for this alternate universe."""
|
||||
return math.e
|
||||
|
||||
experiment_uuid = uuid.uuid4().hex[:4]
|
||||
today = datetime.date.today().isoformat()
|
||||
for task in registry.tasks:
|
||||
if task.type != "ToolUsageTask" or task.name != "Multiverse Math":
|
||||
continue
|
||||
|
||||
dataset_name = task.name
|
||||
|
||||
examples, few_shot_messages, few_shot_three_messages = get_few_shot_messages(task.name)
|
||||
few_shot_str, few_shot_three_str = get_few_shot_str_from_messages(few_shot_messages,few_shot_three_messages)
|
||||
prompts = get_prompts(task.name,examples=examples,few_shot_three_messages=few_shot_three_messages,few_shot_three_str=few_shot_three_str)
|
||||
|
||||
for model_name, model_provider in tests[9:]:
|
||||
model = init_chat_model(model_name,model_provider=model_provider)
|
||||
rate_limiter = RateLimiter(requests_per_second=1)
|
||||
|
||||
print(f"Benchmarking {task.name} with model: {model_name}")
|
||||
eval_config = task.get_eval_config()
|
||||
|
||||
for prompt, prompt_name in prompts[:-1]:
|
||||
|
||||
tools = task.create_environment().tools
|
||||
if "google" in model_provider:
|
||||
tools[9] = tool(pi)
|
||||
agent = create_tool_calling_agent(model, tools, prompt)
|
||||
agent_executor = AgentExecutor(agent=agent, tools=tools, return_intermediate_steps=True)
|
||||
|
||||
|
||||
'''
|
||||
# Legacy way of running, migrate to evaluate
|
||||
agent_factory = StandardAgentFactory(
|
||||
task, model, prompt, rate_limiter=rate_limiter
|
||||
)
|
||||
client.run_on_dataset(
|
||||
dataset_name=dataset_name,
|
||||
llm_or_chain_factory=agent_factory,
|
||||
evaluation=eval_config,
|
||||
verbose=False,
|
||||
project_name=f"{model_name}-{task.name}-{prompt_name}-{experiment_uuid}",
|
||||
concurrency_level=5,
|
||||
project_metadata={
|
||||
"model": model_name,
|
||||
"id": experiment_uuid,
|
||||
"task": task.name,
|
||||
"date": today,
|
||||
"langchain_benchmarks_version": __version__,
|
||||
},
|
||||
)
|
||||
'''
|
||||
evaluate(
|
||||
predict_from_callable(agent_executor,task.instructions),
|
||||
data=dataset_name,
|
||||
evaluators=eval_config.custom_evaluators,
|
||||
max_concurrency=5,
|
||||
metadata={
|
||||
"model": model_name,
|
||||
"id": experiment_uuid,
|
||||
"task": task.name,
|
||||
"date": today,
|
||||
"langchain_benchmarks_version": __version__,
|
||||
},
|
||||
experiment_prefix=f"{model_name}-{task.name}-{prompt_name}"
|
||||
)
|
||||
|
||||
|
||||
Reference in New Issue
Block a user