Compare commits
91 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
12e9107edc | ||
|
|
a7879c10bb | ||
|
|
e2882258b0 | ||
|
|
be682101d8 | ||
|
|
611408d1d3 | ||
|
|
b10c099c7a | ||
|
|
94506e4726 | ||
|
|
ab16d66903 | ||
|
|
47382f82d9 | ||
|
|
17c7794130 | ||
|
|
9378a8d9ed | ||
|
|
84cca0a2ee | ||
|
|
a601b6de9c | ||
|
|
ea10c07358 | ||
|
|
3aae5da769 | ||
|
|
22d279a25c | ||
|
|
357ada3867 | ||
|
|
ab2d93ac6d | ||
|
|
53f727af64 | ||
|
|
820af98418 | ||
|
|
857f41882f | ||
|
|
381ada5cbe | ||
|
|
32a532f269 | ||
|
|
d0acf0ee26 | ||
|
|
bec40d90ef | ||
|
|
c80e959b05 | ||
|
|
2007f68302 | ||
|
|
aad9045bcb | ||
|
|
3b86e9f0b5 | ||
|
|
c1c5585d3a | ||
|
|
c45993617b | ||
|
|
d13b33e956 | ||
|
|
20a4aee5c1 | ||
|
|
4139ac8632 | ||
|
|
89be01737d | ||
|
|
29e4e878a4 | ||
|
|
ffc2832088 | ||
|
|
8b5feab7b2 | ||
|
|
a805c985a6 | ||
|
|
c0ac497ed4 | ||
|
|
a0ea197b28 | ||
|
|
74b11de9ae | ||
|
|
c2b70436e5 | ||
|
|
af9a9800e5 | ||
|
|
e7bac2cbb8 | ||
|
|
d595394243 | ||
|
|
27efb7b53c | ||
|
|
0c1fe17417 | ||
|
|
3f308e7ae4 | ||
|
|
c85a17bac2 | ||
|
|
a91672f619 | ||
|
|
81daa09d05 | ||
|
|
07be2e4555 | ||
|
|
4a642d576a | ||
|
|
8ee7108302 | ||
|
|
a9461af96f | ||
|
|
4d42a32342 | ||
|
|
21add2715b | ||
|
|
3ded353c5a | ||
|
|
b619226480 | ||
|
|
612f9346c5 | ||
|
|
90bec45008 | ||
|
|
5157e30fe7 | ||
|
|
eb2d9e2b63 | ||
|
|
09d214522f | ||
|
|
8798735ea4 | ||
|
|
7ed859c068 | ||
|
|
417e6faccf | ||
|
|
aeae13ba63 | ||
|
|
825d8ec9bb | ||
|
|
44a5c3530a | ||
|
|
14de11a420 | ||
|
|
b15620ee9c | ||
|
|
13e7f2df0a | ||
|
|
888fce5060 | ||
|
|
148a3e4f89 | ||
|
|
0e10f3227f | ||
|
|
b0667043ea | ||
|
|
bd5eac5abd | ||
|
|
dbb85200ac | ||
|
|
c1023a14b8 | ||
|
|
8899acc989 | ||
|
|
c0e7f51626 | ||
|
|
9f827eaca5 | ||
|
|
d9fc08b05c | ||
|
|
8a5ba6d575 | ||
|
|
8204930f2b | ||
|
|
013fe6a153 | ||
|
|
01ffffd04c | ||
|
|
4ddbbc0ff8 | ||
|
|
5ffdbb5c4c |
@@ -0,0 +1,30 @@
|
||||
name: Weekly Tool Benchmarks
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
schedule:
|
||||
- cron: '0 0 * * 0' # Runs at midnight (00:00) every Sunday (UTC time)
|
||||
|
||||
jobs:
|
||||
run_tool_benchmarks:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
|
||||
- name: Set up Python 3.12 + Poetry ${{ env.POETRY_VERSION }}
|
||||
uses: "./.github/actions/poetry_setup"
|
||||
with:
|
||||
python-version: '3.12'
|
||||
poetry-version: ${{ env.POETRY_VERSION }}
|
||||
working-directory: .
|
||||
cache-key: benchmarks-all
|
||||
|
||||
- name: Install dependencies
|
||||
shell: bash
|
||||
run: |
|
||||
echo "Running tests, installing dependencies with poetry..."
|
||||
poetry install --with test,lint,typing,docs
|
||||
|
||||
- name: Execute Tool Benchmarks
|
||||
run: python scripts/tool_benchmarks.py
|
||||
@@ -39,7 +39,7 @@ jobs:
|
||||
|
||||
- name: Install dependencies
|
||||
shell: bash
|
||||
run: poetry install
|
||||
run: poetry install --with test
|
||||
|
||||
- name: Install the opposite major version of pydantic
|
||||
# If normal tests use pydantic v1, here we'll use v2, and vice versa.
|
||||
|
||||
@@ -114,7 +114,7 @@ jobs:
|
||||
shell: bash
|
||||
run: |
|
||||
echo "Attempting to build docs..."
|
||||
make build_docs
|
||||
make docs_build
|
||||
test_datasets:
|
||||
timeout-minutes: 5
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
@@ -34,7 +34,7 @@ jobs:
|
||||
- name: Sphinx build
|
||||
shell: bash
|
||||
run: |
|
||||
make build_docs
|
||||
make docs_build
|
||||
- name: Publish Docs
|
||||
uses: peaceiris/actions-gh-pages@v3
|
||||
with:
|
||||
|
||||
@@ -158,5 +158,5 @@ cython_debug/
|
||||
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
||||
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
||||
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
||||
#.idea/
|
||||
.idea/
|
||||
.DS_Store
|
||||
|
||||
@@ -3,38 +3,15 @@
|
||||
# Default target executed when no arguments are given to make.
|
||||
all: help
|
||||
|
||||
######################
|
||||
# TESTING AND COVERAGE
|
||||
######################
|
||||
|
||||
# Define a variable for the test file path.
|
||||
TEST_FILE ?= tests/unit_tests/
|
||||
|
||||
test:
|
||||
poetry run pytest --disable-socket --allow-unix-socket $(TEST_FILE)
|
||||
|
||||
test_watch:
|
||||
poetry run ptw . -- $(TEST_FILE)
|
||||
|
||||
build_docs:
|
||||
# Copy README.md to docs/index.md
|
||||
cp README.md ./docs/source/index.md
|
||||
# Append to the table of contents the contents of the file
|
||||
cat ./docs/source/toc.segment >> ./docs/source/index.md
|
||||
poetry run sphinx-build "./docs/source" "./docs/build"
|
||||
|
||||
clean_docs:
|
||||
rm -rf ./docs/build
|
||||
|
||||
######################
|
||||
# LINTING AND FORMATTING
|
||||
######################
|
||||
# LINTING AND FORMATTING:
|
||||
|
||||
# Define a variable for Python and notebook files.
|
||||
lint format: PYTHON_FILES=.
|
||||
lint_diff format_diff: PYTHON_FILES=$(shell git diff --relative=. --name-only --diff-filter=d master | grep -E '\.py$$|\.ipynb$$')
|
||||
|
||||
lint lint_diff:
|
||||
# [ "$(PYTHON_FILES)" = "" ] || poetry run ruff check $(PYTHON_FILES)
|
||||
[ "$(PYTHON_FILES)" = "" ] || poetry run ruff check --select I $(PYTHON_FILES)
|
||||
[ "$(PYTHON_FILES)" = "" ] || poetry run ruff format $(PYTHON_FILES) --diff
|
||||
# [ "$(PYTHON_FILES)" = "" ] || poetry run mypy $(PYTHON_FILES)
|
||||
|
||||
@@ -48,19 +25,45 @@ spell_check:
|
||||
spell_fix:
|
||||
poetry run codespell --toml pyproject.toml -w
|
||||
|
||||
######################
|
||||
# HELP
|
||||
######################
|
||||
|
||||
# TESTING AND COVERAGE:
|
||||
|
||||
# Define a variable for the test file path.
|
||||
TEST_FILE ?= tests/unit_tests/
|
||||
|
||||
test:
|
||||
poetry run pytest --disable-socket --allow-unix-socket $(TEST_FILE)
|
||||
|
||||
test_watch:
|
||||
poetry run ptw . -- $(TEST_FILE)
|
||||
|
||||
|
||||
# DOCUMENTATION:
|
||||
|
||||
docs_clean:
|
||||
rm -rf ./docs/build
|
||||
|
||||
docs_build:
|
||||
# Copy README.md to docs/index.md
|
||||
cp README.md ./docs/source/index.md
|
||||
# Append to the table of contents the contents of the file
|
||||
cat ./docs/source/toc.segment >> ./docs/source/index.md
|
||||
poetry run sphinx-build "./docs/source" "./docs/build"
|
||||
|
||||
|
||||
# HELP:
|
||||
help:
|
||||
@echo '===================='
|
||||
@echo '-- LINTING --'
|
||||
@echo 'format - run code formatters'
|
||||
@echo 'lint - run linters'
|
||||
@echo 'spell_check - run codespell on the project'
|
||||
@echo 'spell_fix - run codespell on the project and fix the errors'
|
||||
@echo '-- TESTS --'
|
||||
@echo 'coverage - run unit tests and generate coverage report'
|
||||
@echo 'test - run unit tests'
|
||||
@echo 'test TEST_FILE=<test_file> - run all tests in file'
|
||||
@echo '-- DOCUMENTATION tasks are from the top-level Makefile --'
|
||||
@echo ''
|
||||
@echo 'LINTING:'
|
||||
@echo ' format - run code formatters'
|
||||
@echo ' lint - run linters'
|
||||
@echo ' spell_check - run codespell'
|
||||
@echo ' spell_fix - run codespell and fix the errors'
|
||||
@echo 'TESTS:'
|
||||
@echo ' test - run unit tests'
|
||||
@echo ' test TEST_FILE=<test_file> - run tests in <test_file>'
|
||||
@echo ' coverage - run unit tests and generate coverage report'
|
||||
@echo 'DOCUMENTATION:'
|
||||
@echo ' docs_clean - delete the docs/build directory'
|
||||
@echo ' docs_build - build the documentation'
|
||||
@echo ''
|
||||
|
||||
@@ -1,6 +1,4 @@
|
||||
🚧 Under Active Development 🚧
|
||||
|
||||
# 🦜💪 LangChain Benchmarks
|
||||
# 🦜💯 LangChain Benchmarks
|
||||
|
||||
[](https://github.com/langchain-ai/langchain-benchmarks/releases)
|
||||
[](https://github.com/langchain-ai/langchain-benchmarks/actions/workflows/ci.yml)
|
||||
@@ -24,6 +22,29 @@ We have several goals in open sourcing this:
|
||||
- Showing how we evaluate each task
|
||||
- Encouraging others to benchmark their solutions on these tasks (we are always looking for better ways of doing things!)
|
||||
|
||||
## Benchmarking Results
|
||||
|
||||
Read some of the articles about benchmarking results on our blog.
|
||||
|
||||
* [Agent Tool Use](https://blog.langchain.dev/benchmarking-agent-tool-use/)
|
||||
* [Query Analysis in High Cardinality Situations](https://blog.langchain.dev/high-cardinality/)
|
||||
* [RAG on Tables](https://blog.langchain.dev/benchmarking-rag-on-tables/)
|
||||
* [Q&A over CSV data](https://blog.langchain.dev/benchmarking-question-answering-over-csv-data/)
|
||||
|
||||
|
||||
### Tool Usage (2024-04-18)
|
||||
|
||||
See [tool usage docs](https://langchain-ai.github.io/langchain-benchmarks/notebooks/tool_usage/benchmark_all_tasks.html) to recreate!
|
||||
|
||||
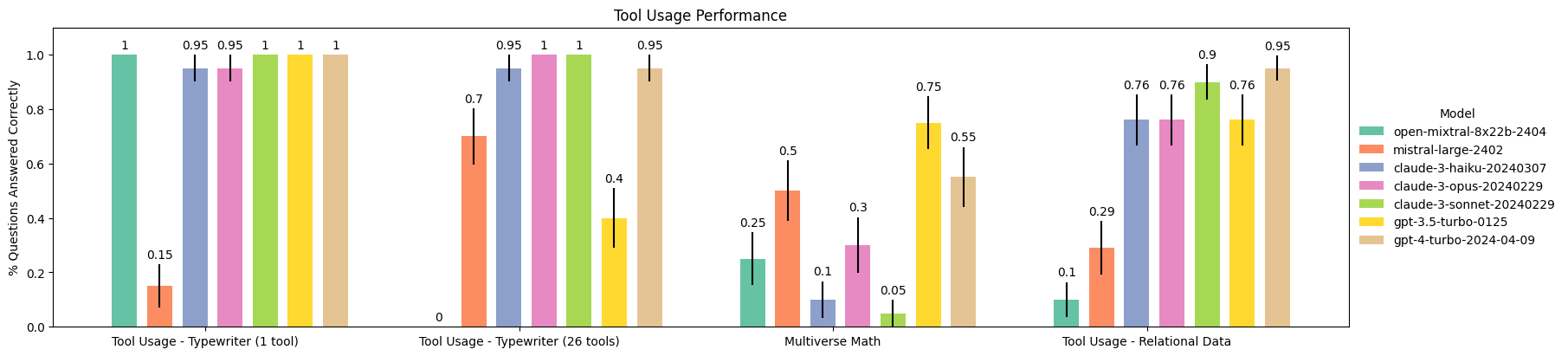
|
||||
|
||||
Explore Agent Traces on LangSmith:
|
||||
|
||||
* [Relational Data](https://smith.langchain.com/public/22721064-dcf6-4e42-be65-e7c46e6835e7/d)
|
||||
* [Tool Usage (1-tool)](https://smith.langchain.com/public/ac23cb40-e392-471f-b129-a893a77b6f62/d)
|
||||
* [Tool Usage (26-tools)](https://smith.langchain.com/public/366bddca-62b3-4b6e-849b-a478abab73db/d)
|
||||
* [Mutiverse Math](https://smith.langchain.com/public/983faff2-54b9-4875-9bf2-c16913e7d489/d)
|
||||
|
||||
## Installation
|
||||
|
||||
To install the packages, run the following command:
|
||||
@@ -35,7 +56,7 @@ pip install -U langchain-benchmarks
|
||||
All the benchmarks come with an associated benchmark dataset stored in [LangSmith](https://smith.langchain.com). To take advantage of the eval and debugging experience, [sign up](https://smith.langchain.com), and set your API key in your environment:
|
||||
|
||||
```bash
|
||||
export LANGCHAIN_API_KEY=sk-...
|
||||
export LANGCHAIN_API_KEY=ls-...
|
||||
```
|
||||
|
||||
## Repo Structure
|
||||
@@ -49,10 +70,10 @@ The other directories are legacy and may be moved in the future.
|
||||
|
||||
Below are archived benchmarks that require cloning this repo to run.
|
||||
|
||||
- [CSV Question Answering](https://github.com/langchain-ai/langchain-benchmarks/tree/main/csv-qa)
|
||||
- [Extraction](https://github.com/langchain-ai/langchain-benchmarks/tree/main/extraction)
|
||||
- [Q&A over the LangChain docs](https://github.com/langchain-ai/langchain-benchmarks/tree/main/langchain-docs-benchmarking)
|
||||
- [Meta-evaluation of 'correctness' evaluators](https://github.com/langchain-ai/langchain-benchmarks/tree/main/meta-evals)
|
||||
- [CSV Question Answering](https://github.com/langchain-ai/langchain-benchmarks/tree/main/archived/csv-qa)
|
||||
- [Extraction](https://github.com/langchain-ai/langchain-benchmarks/tree/main/archived/extraction)
|
||||
- [Q&A over the LangChain docs](https://github.com/langchain-ai/langchain-benchmarks/tree/main/archived/langchain-docs-benchmarking)
|
||||
- [Meta-evaluation of 'correctness' evaluators](https://github.com/langchain-ai/langchain-benchmarks/tree/main/archived/meta-evals)
|
||||
|
||||
|
||||
## Related
|
||||
|
||||
@@ -3,12 +3,12 @@ from langchain.agents import AgentExecutor, OpenAIFunctionsAgent
|
||||
from langchain.agents.agent_toolkits.conversational_retrieval.tool import (
|
||||
create_retriever_tool,
|
||||
)
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.embeddings import OpenAIEmbeddings
|
||||
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain.tools import PythonAstREPLTool
|
||||
from langchain.vectorstores import FAISS
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
import pandas as pd
|
||||
from langchain.agents.agent_toolkits import create_pandas_dataframe_agent
|
||||
from langchain.agents.agent_types import AgentType
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
|
||||
if __name__ == "__main__":
|
||||
@@ -1,8 +1,8 @@
|
||||
import pandas as pd
|
||||
from langchain.agents.agent_toolkits import create_pandas_dataframe_agent
|
||||
from langchain.agents.agent_types import AgentType
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
|
||||
if __name__ == "__main__":
|
||||
@@ -1,8 +1,8 @@
|
||||
import pandas as pd
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.prompts import ChatPromptTemplate
|
||||
from langchain.schema.output_parser import StrOutputParser
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
from pandasai import PandasAI
|
||||
|
||||
{kind=link}
|
Before Width: | Height: | Size: 12 KiB After Width: | Height: | Size: 12 KiB |
{kind=link}
|
Before Width: | Height: | Size: 12 KiB After Width: | Height: | Size: 12 KiB |
{kind=link}
|
Before Width: | Height: | Size: 9.7 KiB After Width: | Height: | Size: 9.7 KiB |
{kind=link}
|
Before Width: | Height: | Size: 11 KiB After Width: | Height: | Size: 11 KiB |
@@ -2,7 +2,7 @@ import pandas as pd
|
||||
import streamlit as st
|
||||
from langchain.agents.agent_toolkits import create_pandas_dataframe_agent
|
||||
from langchain.agents.agent_types import AgentType
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain_openai import ChatOpenAI
|
||||
|
||||
df = pd.read_csv("titanic.csv")
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
import streamlit as st
|
||||
from langchain.chains import create_extraction_chain
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
|
||||
st.set_page_config(page_title="🦜🔗 Text-to-graph extraction")
|
||||
@@ -1,8 +1,7 @@
|
||||
from chat_langchain.chain import chain
|
||||
from fastapi import FastAPI
|
||||
from openai_functions_agent import agent_executor as openai_functions_agent_chain
|
||||
|
||||
from langserve import add_routes
|
||||
from openai_functions_agent import agent_executor as openai_functions_agent_chain
|
||||
|
||||
app = FastAPI()
|
||||
|
||||
@@ -3,13 +3,13 @@ from typing import List, Tuple
|
||||
from langchain.agents import AgentExecutor
|
||||
from langchain.agents.format_scratchpad import format_to_openai_functions
|
||||
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
|
||||
from langchain.pydantic_v1 import BaseModel, Field
|
||||
from langchain.schema.messages import AIMessage, HumanMessage
|
||||
from langchain.tools import tool
|
||||
from langchain.tools.render import format_tool_to_openai_function
|
||||
from langchain_docs_retriever.retriever import get_retriever
|
||||
from langchain_openai import ChatOpenAI
|
||||
|
||||
# This is used to tell the model how to best use the retriever.
|
||||
|
||||
@@ -7,9 +7,9 @@ from typing import Callable, Optional
|
||||
|
||||
from anthropic_iterative_search.chain import chain as anthropic_agent_chain
|
||||
from chat_langchain.chain import create_chain
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
from langchain.schema.runnable import Runnable
|
||||
from langchain.smith import RunEvalConfig, run_on_dataset
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langsmith import Client
|
||||
from oai_assistant.chain import agent_executor as openai_assistant_chain
|
||||
from openai_functions_agent import agent_executor as openai_functions_agent_chain
|
||||
@@ -1 +1,3 @@
|
||||
chromadb/
|
||||
index.md
|
||||
Untitled.ipynb
|
||||
|
||||
@@ -1,225 +1,226 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "033684fb-65b2-4586-a959-68c614741ca2",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Datasets\n",
|
||||
"[](https://colab.research.google.com/github/langchain-ai/langchain-benchmarks/blob/main/docs/source/notebooks/datasets.ipynb)\n",
|
||||
"\n",
|
||||
"Here, we'll see how to work with LangSmith datasets."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -U langchain-benchmarks"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "6d272fbf-710e-4a49-a0da-67e010541905",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_benchmarks import clone_public_dataset, download_public_dataset"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "18ee0f96-e5c4-4ae9-aebf-7d8b88c51662",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Let's first download the dataset to the local file system"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "58b94f6d-0c91-4361-9b22-f758ffaa150a",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Fetching examples...\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"model_id": "5a2fad8c0c3549ec96a3b38fe8a002b0",
|
||||
"version_major": 2,
|
||||
"version_minor": 0
|
||||
},
|
||||
"text/plain": [
|
||||
" 0%| | 0/21 [00:00<?, ?it/s]"
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Done fetching examples.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"download_public_dataset(\n",
|
||||
" \"https://smith.langchain.com/public/452ccafc-18e1-4314-885b-edd735f17b9d/examples\"\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "841db832-b0d3-4fd1-8531-1154ec9b3caa",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"we can take a look at the first two examples"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "664e90fc-af84-4c5f-a3dd-5d9ffe649650",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[\n",
|
||||
" {\n",
|
||||
" \"created_at\": \"2023-11-15T15:26:53.511629\",\n",
|
||||
" \"dataset_id\": \"9f73165c-d333-4d14-8f59-bd7eede5db08\",\n",
|
||||
" \"id\": \"0703a989-2693-4039-a1f6-7281fc1b4cb0\",\n",
|
||||
" \"inputs\": {\n",
|
||||
" \"question\": \"do bob and alice live in the same city?\"\n",
|
||||
" },\n",
|
||||
" \"modified_at\": \"2023-11-15T15:26:53.511629\",\n",
|
||||
" \"outputs\": {\n",
|
||||
" \"expected_steps\": [\n",
|
||||
" \"find_users_by_name\",\n",
|
||||
" \"get_user_location\",\n",
|
||||
" \"get_city_for_location\",\n",
|
||||
" \"get_user_location\",\n",
|
||||
" \"get_city_for_location\"\n",
|
||||
" ],\n",
|
||||
" \"order_matters\": false,\n",
|
||||
" \"reference\": \"no\"\n",
|
||||
" },\n",
|
||||
" \"runs\": []\n",
|
||||
" },\n",
|
||||
" {\n",
|
||||
" \"created_at\": \"2023-11-15T15:26:53.491359\",\n",
|
||||
" \"dataset_id\": \"9f73165c-d333-4d14-8f59-bd7eede5db08\",\n",
|
||||
" \"id\": \"b258b95a-9524-4da7-b758-c5481109322d\",\n",
|
||||
" \"inputs\": {\n",
|
||||
" \"question\": \"Is it likely that Donna is outside with an umbrella at this time?\"\n",
|
||||
" },\n",
|
||||
" \"modified_at\": \"2023-11-15T15:26:53.491359\",\n",
|
||||
" \"outputs\": {\n",
|
||||
" \"expected_steps\": [\n",
|
||||
" \"find_users_by_name\",\n",
|
||||
" \"get_user_location\",\n",
|
||||
" \"get_current_time_for_location\",\n",
|
||||
" \"get_current_weather_for_location\"\n",
|
||||
" ],\n",
|
||||
" \"order_matters\": false,\n",
|
||||
" \"reference\": \"yes\"\n",
|
||||
" },\n",
|
||||
" \"runs\": []\n",
|
||||
" }\n",
|
||||
"]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import json\n",
|
||||
"\n",
|
||||
"with open(\"./e95d45da-aaa3-44b3-ba2b-7c15ff6e46f5.json\", \"r\", encoding=\"utf-8\") as f:\n",
|
||||
" print(json.dumps(json.load(f)[:2], indent=2, sort_keys=True))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "2c6cf01f-466b-406d-b4c7-2395747780fd",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"We can also clone the dataset to our local tenant"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e4dea4df-2f1c-436b-a71c-49ffb2295ccc",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Executing this command will clone the dataset to your own LangSmith tenant. \n",
|
||||
"For this to work you must have a [LangSmith account](https://smith.langchain.com/) set up."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"\n",
|
||||
"# Get from https://smith.langchain.com/settings\n",
|
||||
"os.environ[\"LANGCHAIN_API_KEY\"] = \"ls_...\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "18d0b905-2a6a-4752-a7cb-8653bd9049e3",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"clone_public_dataset(\n",
|
||||
" \"https://smith.langchain.com/public/452ccafc-18e1-4314-885b-edd735f17b9d/examples\",\n",
|
||||
" dataset_name=\"Agent Dataset\",\n",
|
||||
")"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.2"
|
||||
}
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "033684fb-65b2-4586-a959-68c614741ca2",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Datasets\n",
|
||||
"\n",
|
||||
"Here, we'll see how to work with LangSmith datasets."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "474292e6",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -U langchain-benchmarks"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "6d272fbf-710e-4a49-a0da-67e010541905",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_benchmarks import clone_public_dataset, download_public_dataset"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "18ee0f96-e5c4-4ae9-aebf-7d8b88c51662",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Let's first download the dataset to the local file system"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "58b94f6d-0c91-4361-9b22-f758ffaa150a",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Fetching examples...\n"
|
||||
]
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
{
|
||||
"data": {
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"model_id": "5a2fad8c0c3549ec96a3b38fe8a002b0",
|
||||
"version_major": 2,
|
||||
"version_minor": 0
|
||||
},
|
||||
"text/plain": [
|
||||
" 0%| | 0/21 [00:00<?, ?it/s]"
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Done fetching examples.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"download_public_dataset(\n",
|
||||
" \"https://smith.langchain.com/public/452ccafc-18e1-4314-885b-edd735f17b9d/examples\"\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "841db832-b0d3-4fd1-8531-1154ec9b3caa",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"we can take a look at the first two examples"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "664e90fc-af84-4c5f-a3dd-5d9ffe649650",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[\n",
|
||||
" {\n",
|
||||
" \"created_at\": \"2023-11-15T15:26:53.511629\",\n",
|
||||
" \"dataset_id\": \"9f73165c-d333-4d14-8f59-bd7eede5db08\",\n",
|
||||
" \"id\": \"0703a989-2693-4039-a1f6-7281fc1b4cb0\",\n",
|
||||
" \"inputs\": {\n",
|
||||
" \"question\": \"do bob and alice live in the same city?\"\n",
|
||||
" },\n",
|
||||
" \"modified_at\": \"2023-11-15T15:26:53.511629\",\n",
|
||||
" \"outputs\": {\n",
|
||||
" \"expected_steps\": [\n",
|
||||
" \"find_users_by_name\",\n",
|
||||
" \"get_user_location\",\n",
|
||||
" \"get_city_for_location\",\n",
|
||||
" \"get_user_location\",\n",
|
||||
" \"get_city_for_location\"\n",
|
||||
" ],\n",
|
||||
" \"order_matters\": false,\n",
|
||||
" \"reference\": \"no\"\n",
|
||||
" },\n",
|
||||
" \"runs\": []\n",
|
||||
" },\n",
|
||||
" {\n",
|
||||
" \"created_at\": \"2023-11-15T15:26:53.491359\",\n",
|
||||
" \"dataset_id\": \"9f73165c-d333-4d14-8f59-bd7eede5db08\",\n",
|
||||
" \"id\": \"b258b95a-9524-4da7-b758-c5481109322d\",\n",
|
||||
" \"inputs\": {\n",
|
||||
" \"question\": \"Is it likely that Donna is outside with an umbrella at this time?\"\n",
|
||||
" },\n",
|
||||
" \"modified_at\": \"2023-11-15T15:26:53.491359\",\n",
|
||||
" \"outputs\": {\n",
|
||||
" \"expected_steps\": [\n",
|
||||
" \"find_users_by_name\",\n",
|
||||
" \"get_user_location\",\n",
|
||||
" \"get_current_time_for_location\",\n",
|
||||
" \"get_current_weather_for_location\"\n",
|
||||
" ],\n",
|
||||
" \"order_matters\": false,\n",
|
||||
" \"reference\": \"yes\"\n",
|
||||
" },\n",
|
||||
" \"runs\": []\n",
|
||||
" }\n",
|
||||
"]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import json\n",
|
||||
"\n",
|
||||
"with open(\"./e95d45da-aaa3-44b3-ba2b-7c15ff6e46f5.json\", \"r\", encoding=\"utf-8\") as f:\n",
|
||||
" print(json.dumps(json.load(f)[:2], indent=2, sort_keys=True))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "2c6cf01f-466b-406d-b4c7-2395747780fd",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"We can also clone the dataset to our local tenant"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e4dea4df-2f1c-436b-a71c-49ffb2295ccc",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Executing this command will clone the dataset to your own LangSmith tenant. \n",
|
||||
"For this to work you must have a [LangSmith account](https://smith.langchain.com/) set up."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "7eb38ea6",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"\n",
|
||||
"# Get from https://smith.langchain.com/settings\n",
|
||||
"os.environ[\"LANGCHAIN_API_KEY\"] = \"ls_...\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "18d0b905-2a6a-4752-a7cb-8653bd9049e3",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"clone_public_dataset(\n",
|
||||
" \"https://smith.langchain.com/public/452ccafc-18e1-4314-885b-edd735f17b9d/examples\",\n",
|
||||
" dataset_name=\"Agent Dataset\",\n",
|
||||
")"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.4"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
||||
@@ -232,8 +232,8 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"llm = ChatOpenAI(model=\"gpt-3.5-turbo-16k\", temperature=0).bind_functions(\n",
|
||||
" functions=[task.schema],\n",
|
||||
@@ -688,8 +688,6 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import pandas as pd\n",
|
||||
"\n",
|
||||
"df = test_run.to_dataframe().join(claude_test_run.to_dataframe(), rsuffix=\"_claude\")"
|
||||
]
|
||||
},
|
||||
@@ -1196,7 +1194,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.2"
|
||||
"version": "3.11.4"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -0,0 +1,749 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e4d1cb60-6d32-4337-abee-1b6c794b7f4c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Extracting high-cardinality categoricals\n",
|
||||
"\n",
|
||||
"Suppose we built a book recommendation chatbot, and as part of it we want to extract and filter on author name if that's part of the user input. A user might ask a question like:\n",
|
||||
"\n",
|
||||
"> \"what are books about aliens by Steven King\"\n",
|
||||
"\n",
|
||||
"If we're not careful, our extraction system would most likely extract the author name \"Steven King\" from this input. This might cause us to miss all the most relevant book results, since the user was almost certainly looking for books by *Stephen King*.\n",
|
||||
"\n",
|
||||
"This is a case of having to extract a **high-cardinality categorical** value. Given a dataset of books and their respective authors, there's a large but finite number of valid author names, and we need some way of making sure our extraction system outputs valid and relevant author names even if the user input refers to invalid names. \n",
|
||||
"\n",
|
||||
"We've built a dataset to help benchmark different approaches for dealing with this challenge. The dataset is simple: it is a collection of 23 mispelled and corrected human names. To use it for high-cardinality categorical testing, we're going to generate a large set of valid names (~10,000) that includes the correct spellings of all the names in the dataset. Using this, we'll test the ability of various extraction systems to extract a corrected name from the user question:\n",
|
||||
"\n",
|
||||
"> \"what are books about aliens by {mispelled_name}\"\n",
|
||||
"\n",
|
||||
"where for each datapoint in our dataset, we'll use the mispelled name as the input and expect the corrected name as the extracted output."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "dbe58c19-c29d-41d8-844a-b03c6ee1e07a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Setup\n",
|
||||
"\n",
|
||||
"We need to install a few packages and set some env vars first:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "9a478941-ca99-40ee-b4f0-635f74d94a11",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install -qU langchain-benchmarks langchain-openai faker chromadb numpy scikit-learn"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "8c0aa002-c334-4c51-bdf9-ffe9ae7bd56f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import getpass\n",
|
||||
"import os\n",
|
||||
"\n",
|
||||
"os.environ[\"LANGCHAIN_API_KEY\"] = getpass.getpass()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "9c3dc147-2681-437e-8a26-204f10ed4d41",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from operator import attrgetter\n",
|
||||
"\n",
|
||||
"from langchain_core.prompts import ChatPromptTemplate\n",
|
||||
"from langchain_core.pydantic_v1 import BaseModel, Field\n",
|
||||
"from langchain_core.runnables import RunnablePassthrough\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"from langsmith import Client\n",
|
||||
"\n",
|
||||
"from langchain_benchmarks import registry"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "318e0ed7-1ab5-4219-9223-900b250066de",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"This is the `Name Correction` benchmark in langchain-benchmarket:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "3f2be995-b6a9-4c3d-a19f-001c0e05ac9c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"client = Client()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "cd3d005c-9b60-4bc6-a467-815e7e3bbc7c",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'https://smith.langchain.com/public/78df83ee-ba7f-41c6-832c-2b23327d4cf7/d'"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"task = registry[\"Name Correction\"]\n",
|
||||
"task.dataset_url"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "fc4d14ea-6a46-43b1-a0ac-8e632e1297d2",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"**NOTE**: If you are running this notebook for the first time, clone the public dataset into your LangSmith organization by uncommenting the below:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "dca18a40-85f1-4911-9e41-936975fbddf8",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# client.clone_public_dataset(task.dataset_url)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "3f9ad08e-69cc-436e-94f9-b0e1e2c4a9d1",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"{'name': 'Tracy Cook'} {'name': 'Traci Cook'}\n",
|
||||
"{'name': 'Dan Klein'} {'name': 'Daniel Klein'}\n",
|
||||
"{'name': 'Jen Mcintosh'} {'name': 'Jennifer Mcintosh'}\n",
|
||||
"{'name': 'Cassie Hull'} {'name': 'Cassandra Hull'}\n",
|
||||
"{'name': 'Andy Williams'} {'name': 'Andrew Williams'}\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"examples = list(client.list_examples(dataset_name=task.dataset_name))\n",
|
||||
"for example in examples[:5]:\n",
|
||||
" print(example.inputs, example.outputs)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"id": "35c85a6f-5d8d-4018-9b83-b6cab0587c1c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def run_on_dataset(chain, run_name):\n",
|
||||
" client.run_on_dataset(\n",
|
||||
" dataset_name=task.dataset_name,\n",
|
||||
" llm_or_chain_factory=chain,\n",
|
||||
" evaluation=task.eval_config,\n",
|
||||
" project_name=run_name,\n",
|
||||
" )"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4fd7318a-4195-4da8-94d7-34ee6b7c2097",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Augmenting with more fake names\n",
|
||||
"\n",
|
||||
"For our tests we'll create a list of 10,000 names that represent all the possible values for this category. This will include our target names from the dataset."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "06098983-f5cf-4de3-ae07-4cdbe091522c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from faker import Faker\n",
|
||||
"\n",
|
||||
"Faker.seed(42)\n",
|
||||
"fake = Faker()\n",
|
||||
"fake.seed_instance(0)\n",
|
||||
"\n",
|
||||
"incorrect_names = [example.inputs[\"name\"] for example in examples]\n",
|
||||
"correct_names = [example.outputs[\"name\"] for example in examples]\n",
|
||||
"\n",
|
||||
"# We'll make sure that our list of valid names contains the correct spellings\n",
|
||||
"# and not the incorrect spellings from our dataset\n",
|
||||
"valid_names = list(\n",
|
||||
" set([fake.name() for _ in range(10_000)] + correct_names).difference(\n",
|
||||
" incorrect_names\n",
|
||||
" )\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "ab6d9b4b-717b-4947-ac17-a100a0ced088",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"9382"
|
||||
]
|
||||
},
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"len(valid_names)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "6e7d27bf-c82c-43e1-961a-ea67733b1dec",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"['Debra Lee', 'Kevin Harper', 'Donald Anderson']"
|
||||
]
|
||||
},
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"valid_names[:3]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "bd801ab5-b2a4-49bc-9c11-698dc760eb28",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Chain 1: Baseline\n",
|
||||
"\n",
|
||||
"As a baseline we'll create a function-calling chain that has no information about the set of valid names."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"id": "1e0694d9-d67d-4f90-b40c-f8373389f5c4",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"class Search(BaseModel):\n",
|
||||
" query: str\n",
|
||||
" author: str\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"system = \"\"\"Generate a relevant search query for a library system\"\"\"\n",
|
||||
"prompt = ChatPromptTemplate.from_messages(\n",
|
||||
" [\n",
|
||||
" (\"system\", \"{system}\"),\n",
|
||||
" (\"human\", \"what are books about aliens by {name}\"),\n",
|
||||
" ]\n",
|
||||
")\n",
|
||||
"llm = ChatOpenAI(model=\"gpt-3.5-turbo-0125\", temperature=0)\n",
|
||||
"structured_llm = llm.with_structured_output(Search)\n",
|
||||
"\n",
|
||||
"query_analyzer_1 = (\n",
|
||||
" prompt.partial(system=system) | structured_llm | {\"name\": attrgetter(\"author\")}\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"id": "f4a4d81f-532a-4efb-86cb-cc0555dbc4e7",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"View the evaluation results for project 'GPT-3.5' at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6/compare?selectedSessions=f429ec84-b879-4e66-b7fb-ef7be69d1acd\n",
|
||||
"\n",
|
||||
"View all tests for Dataset Extracting Corrected Names at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6\n",
|
||||
"[------------------------------------------------->] 23/23"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"run_on_dataset(query_analyzer_1, \"GPT-3.5\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b4f42968-069f-450b-a03b-f47934956f89",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"As we might have expected, this gives us a `Correct rate: 0%`. Let's see if we can do better :)\n",
|
||||
"\n",
|
||||
"See the test run in LangSmith [here](https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d/compare?selectedSessions=f429ec84-b879-4e66-b7fb-ef7be69d1acd)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "08ef2fc6-0ad9-4a3e-a306-bd7100f7b1fb",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Chain 2: All candidates in prompt\n",
|
||||
"\n",
|
||||
"Next, let's dump the full list of valid names in the system prompt. We'll need a model with a longer context window than the 16k token window of gpt-3.5-turbo-0125 so we'll use gpt-4-0125-preview."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"id": "d0f65f4f-5461-43b1-9c7b-5fcdaf48c2ce",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"valid_names_str = \"\\n\".join(valid_names)\n",
|
||||
"\n",
|
||||
"system_2 = \"\"\"Generate a relevant search query for a library system.\n",
|
||||
"\n",
|
||||
"`author` attribute MUST be one of:\n",
|
||||
"\n",
|
||||
"{valid_names_str}\n",
|
||||
"\n",
|
||||
"Do NOT hallucinate author name!\"\"\"\n",
|
||||
"\n",
|
||||
"formatted_system = system_2.format(valid_names_str=valid_names_str)\n",
|
||||
"structured_llm_2 = ChatOpenAI(\n",
|
||||
" model=\"gpt-4-0125-preview\", temperature=0\n",
|
||||
").with_structured_output(Search)\n",
|
||||
"query_analyzer_2 = (\n",
|
||||
" prompt.partial(system=formatted_system)\n",
|
||||
" | structured_llm_2\n",
|
||||
" | {\"name\": attrgetter(\"author\")}\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"id": "de679906-c69d-4ceb-bc5e-73a291b21cdc",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"View the evaluation results for project 'GPT-4, all names in prompt' at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6/compare?selectedSessions=8c4cfdfc-3646-438e-be47-43a40d66292a\n",
|
||||
"\n",
|
||||
"View all tests for Dataset Extracting Corrected Names at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6\n",
|
||||
"[------------------------------------------------->] 23/23"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"run_on_dataset(query_analyzer_2, \"GPT-4, all names in prompt\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "eb678fdd-0e57-4063-adea-56248aea11e5",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"This gets us up to `Correct rate: 26%`.\n",
|
||||
"\n",
|
||||
"See the test run in LangSmith [here](https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d/compare?selectedSessions=8c4cfdfc-3646-438e-be47-43a40d66292a)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "0aa394b5-a665-4f4c-809d-c0d756c9b23e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Chain 3: Top k candidates from vectorstore in prompt\n",
|
||||
"\n",
|
||||
"10,000 names is a lot to have in the prompt. Perhaps we could get better performance by shortening the list using vector search first to only include names that have the highest similarity to the user question. We can return to using GPT-3.5 as a result:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "f9439e3f-5aa2-45b7-ab1f-149060744e03",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_community.vectorstores import Chroma\n",
|
||||
"from langchain_core.prompts import PromptTemplate\n",
|
||||
"from langchain_openai import OpenAIEmbeddings\n",
|
||||
"\n",
|
||||
"k = 10\n",
|
||||
"embeddings = OpenAIEmbeddings(model=\"text-embedding-3-small\")\n",
|
||||
"vectorstore = Chroma.from_texts(valid_names, embeddings, collection_name=\"author_names\")\n",
|
||||
"retriever = vectorstore.as_retriever(search_kwargs={\"k\": k})"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 20,
|
||||
"id": "04018b30-2378-4c96-8515-39d66c554459",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"system_chain = (\n",
|
||||
" (lambda name: f\"what are books about aliens by {name}\")\n",
|
||||
" | retriever\n",
|
||||
" | (\n",
|
||||
" lambda docs: system_2.format(\n",
|
||||
" valid_names_str=\"\\n\".join(d.page_content for d in docs)\n",
|
||||
" )\n",
|
||||
" )\n",
|
||||
")\n",
|
||||
"query_analyzer_3 = (\n",
|
||||
" RunnablePassthrough.assign(system=system_chain)\n",
|
||||
" | prompt\n",
|
||||
" | structured_llm\n",
|
||||
" | {\"name\": attrgetter(\"author\")}\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 22,
|
||||
"id": "fd5af75e-41fa-42ee-b9ac-62eb13e21022",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"View the evaluation results for project 'GPT-3.5, top 10 names in prompt, vecstore' at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6/compare?selectedSessions=af93ec50-ccbb-4b3c-908a-70c75e5516ea\n",
|
||||
"\n",
|
||||
"View all tests for Dataset Extracting Corrected Names at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6\n",
|
||||
"[------------------------------------------------->] 23/23"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"run_on_dataset(query_analyzer_3, f\"GPT-3.5, top {k} names in prompt, vecstore\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b7e0f097-7432-4728-a60b-b980046c1275",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"This gets us up to `Correct rate: 57%`\n",
|
||||
"\n",
|
||||
"See the test run in LangSmith [here](https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d/compare?selectedSessions=af93ec50-ccbb-4b3c-908a-70c75e5516ea)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "20aaa33a-d475-41a1-8f1a-53e18382b3d7",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Chain 4: Top k candidates by ngram overlap in prompt\n",
|
||||
"\n",
|
||||
"Instead of using vector search, which requires embeddings and vector stores, a cheaper and faster approach would be to compare ngram overlap between the user question and the list of valid names:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 23,
|
||||
"id": "05b2fc1c-0f61-4638-bbf5-fed5b634db51",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import numpy as np\n",
|
||||
"from sklearn.feature_extraction.text import TfidfVectorizer\n",
|
||||
"from sklearn.metrics.pairwise import cosine_similarity\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# Function to generate character n-grams\n",
|
||||
"def ngrams(string, n=3):\n",
|
||||
" string = \"START\" + string.replace(\" \", \"\").lower() + \"END\"\n",
|
||||
" ngrams = zip(*[string[i:] for i in range(n)])\n",
|
||||
" return [\"\".join(ngram) for ngram in ngrams]\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# Vectorize documents using TfidfVectorizer with the custom n-grams function\n",
|
||||
"vectorizer = TfidfVectorizer(analyzer=ngrams)\n",
|
||||
"tfidf_matrix = vectorizer.fit_transform(valid_names)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 24,
|
||||
"id": "2994aff8-4bfd-4cf3-9b73-2bda7c470ba4",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def get_names(query):\n",
|
||||
" # Vectorize query\n",
|
||||
" query_tfidf = vectorizer.transform([query])\n",
|
||||
"\n",
|
||||
" # Compute cosine similarity\n",
|
||||
" cosine_similarities = cosine_similarity(query_tfidf, tfidf_matrix).flatten()\n",
|
||||
"\n",
|
||||
" # Find the index of the most similar document\n",
|
||||
" most_similar_document_indexes = np.argsort(-cosine_similarities)\n",
|
||||
"\n",
|
||||
" return \"\\n\".join([valid_names[i] for i in most_similar_document_indexes[:k]])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 25,
|
||||
"id": "a549a347-1449-4ae2-a30d-e8f0b917d50e",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def get_system_prompt(input):\n",
|
||||
" name = input[\"name\"]\n",
|
||||
" valid_names_str = get_names(f\"what are books about aliens by {name}\")\n",
|
||||
" return system_2.format(valid_names_str=valid_names_str)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"query_analyzer_4 = (\n",
|
||||
" RunnablePassthrough.assign(system=get_system_prompt)\n",
|
||||
" | prompt\n",
|
||||
" | structured_llm\n",
|
||||
" | {\"name\": attrgetter(\"author\")}\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 27,
|
||||
"id": "dd1b69a8-5ca6-4a2d-9ad3-567d0105b672",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"View the evaluation results for project 'GPT-3.5, top 10 names in prompt, ngram' at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6/compare?selectedSessions=bc28b761-2ac9-4391-8df1-758f0a4d5100\n",
|
||||
"\n",
|
||||
"View all tests for Dataset Extracting Corrected Names at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6\n",
|
||||
"[------------------------------------------------->] 23/23"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"run_on_dataset(query_analyzer_4, f\"GPT-3.5, top {k} names in prompt, ngram\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b4e16c1b-33d5-4ca1-932b-8234ffc668bf",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"This gets us up to `Correct rate: 65%`\n",
|
||||
"\n",
|
||||
"See the test run in LangSmith [here](https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d/compare?selectedSessions=bc28b761-2ac9-4391-8df1-758f0a4d5100)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "d3045376-e102-4ec6-877a-91448677f3f3",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Chain 5: Replace with top candidate from vectorstore\n",
|
||||
"\n",
|
||||
"Instead of (or in addition to) searching for similar candidates before extraction, we can also compare and correct the extracted value after-the-fact a search over the valid names. With Pydantic classes this is easy using a validator:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 28,
|
||||
"id": "ac719651-0775-4fa4-bd22-9fddebcc6918",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain_core.pydantic_v1 import validator\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"class Search(BaseModel):\n",
|
||||
" query: str\n",
|
||||
" author: str\n",
|
||||
"\n",
|
||||
" @validator(\"author\")\n",
|
||||
" def double(cls, v: str) -> str:\n",
|
||||
" return vectorstore.similarity_search(v, k=1)[0].page_content\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"structured_llm_3 = llm.with_structured_output(Search)\n",
|
||||
"query_analyzer_5 = (\n",
|
||||
" prompt.partial(system=system) | structured_llm_3 | {\"name\": attrgetter(\"author\")}\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 29,
|
||||
"id": "fc1cfdcb-47fb-40c4-898d-f290cd53a37d",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"View the evaluation results for project 'GPT-3.5, correct name, vecstore' at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6/compare?selectedSessions=e3eda1e1-bc25-46e8-a4fb-db324cefd1c9\n",
|
||||
"\n",
|
||||
"View all tests for Dataset Extracting Corrected Names at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6\n",
|
||||
"[------------------------------------------------->] 23/23"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"run_on_dataset(query_analyzer_5, f\"GPT-3.5, correct name, vecstore\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e6e96a2c-506e-461f-bd05-cb88fe0ea3aa",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"This gets us up to `Correct rate: 83%`\n",
|
||||
"\n",
|
||||
"See the test run in LangSmith [here](https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d/compare?selectedSessions=e3eda1e1-bc25-46e8-a4fb-db324cefd1c9)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "f1f8ce77-01a3-41d1-a047-103cb2e552f9",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Chain 6: Replace with top candidate by ngram overlap\n",
|
||||
"\n",
|
||||
"We can do the same with ngram overlap search instead of vector search:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 30,
|
||||
"id": "21ffa8c9-907b-453a-9b32-01a981bca5ec",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"class Search(BaseModel):\n",
|
||||
" query: str\n",
|
||||
" author: str\n",
|
||||
"\n",
|
||||
" @validator(\"author\")\n",
|
||||
" def double(cls, v: str) -> str:\n",
|
||||
" return get_names(v).split(\"\\n\")[0]\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"structured_llm_4 = llm.with_structured_output(Search)\n",
|
||||
"query_analyzer_6 = (\n",
|
||||
" prompt.partial(system=system) | structured_llm_4 | {\"name\": attrgetter(\"author\")}\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 31,
|
||||
"id": "126354dd-c54e-4391-8a5e-5e200d006a18",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"View the evaluation results for project 'GPT-3.5, correct name, ngram' at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6/compare?selectedSessions=8f8846c8-2ada-41bc-8d2c-e1d56e7c92ce\n",
|
||||
"\n",
|
||||
"View all tests for Dataset Extracting Corrected Names at:\n",
|
||||
"https://smith.langchain.com/o/43ae1439-dbb7-53b8-bef4-155154d3f962/datasets/1765d6b2-aa2e-46ec-9158-9f4ca8f228c6\n",
|
||||
"[------------------------------------------------->] 23/23"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"run_on_dataset(query_analyzer_6, f\"GPT-3.5, correct name, ngram\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b8c8cd81-61d0-4c1f-957d-1910be7706e7",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"This gets us up to `Correct rate: 74%`, slightly worse than Chain 5 (same thing using vector search insteadf of ngram).\n",
|
||||
"\n",
|
||||
"See the test run in LangSmith [here](https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d/compare?selectedSessions=8f8846c8-2ada-41bc-8d2c-e1d56e7c92ce)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4d7f7ab4-466d-434c-98bd-ebe1906599a9",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## See all results in LangSmith\n",
|
||||
"\n",
|
||||
"To see the full dataset and all the test results, head to LangSmith: https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "benchmarks-venv",
|
||||
"language": "python",
|
||||
"name": "benchmarks-venv"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.4"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -14,7 +14,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"execution_count": 1,
|
||||
"id": "86912590-a90a-4351-8ab4-89192cdee1e7",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -26,19 +26,24 @@
|
||||
"<tr><th>Name </th><th>Type </th><th>Dataset ID </th><th>Description </th></tr>\n",
|
||||
"</thead>\n",
|
||||
"<tbody>\n",
|
||||
"<tr><td>Email Extraction</td><td>ExtractionTask</td><td><a href=\"https://smith.langchain.com/public/36bdfe7d-3cd1-4b36-b957-d12d95810a2b/d\" target=\"_blank\" rel=\"noopener\">36bdfe7d-3cd1-4b36-b957-d12d95810a2b</a></td><td>A dataset of 42 real emails deduped from a spam folder, with semantic HTML tags removed, as well as a script for initial extraction and formatting of other emails from an arbitrary .mbox file like the one exported by Gmail.\n",
|
||||
"<tr><td>Email Extraction</td><td>ExtractionTask</td><td><a href=\"https://smith.langchain.com/public/a1742786-bde5-4f51-a1d8-e148e5251ddb/d\" target=\"_blank\" rel=\"noopener\">a1742786-bde5-4f51-a1d8-e148e5251ddb</a></td><td>A dataset of 42 real emails deduped from a spam folder, with semantic HTML tags removed, as well as a script for initial extraction and formatting of other emails from an arbitrary .mbox file like the one exported by Gmail.\n",
|
||||
"\n",
|
||||
"Some additional cleanup of the data was done by hand after the initial pass.\n",
|
||||
"\n",
|
||||
"See https://github.com/jacoblee93/oss-model-extraction-evals. </td></tr>\n",
|
||||
"<tr><td>Chat Extraction </td><td>ExtractionTask</td><td><a href=\"https://smith.langchain.com/public/00f4444c-9460-4a82-b87a-f50096f1cfef/d\" target=\"_blank\" rel=\"noopener\">00f4444c-9460-4a82-b87a-f50096f1cfef</a></td><td>A dataset meant to test the ability of an LLM to extract and infer\n",
|
||||
"structured information from a dialogue. The dialogue is between a user and a support\n",
|
||||
"engineer. Outputs should be structured as a JSON object and test both the ability\n",
|
||||
"of the LLM to correctly structure the information and its ability to perform simple \n",
|
||||
"classification tasks. </td></tr>\n",
|
||||
"</tbody>\n",
|
||||
"</table>"
|
||||
],
|
||||
"text/plain": [
|
||||
"Registry(tasks=[ExtractionTask(name='Email Extraction', dataset_id='https://smith.langchain.com/public/36bdfe7d-3cd1-4b36-b957-d12d95810a2b/d', description='A dataset of 42 real emails deduped from a spam folder, with semantic HTML tags removed, as well as a script for initial extraction and formatting of other emails from an arbitrary .mbox file like the one exported by Gmail.\\n\\nSome additional cleanup of the data was done by hand after the initial pass.\\n\\nSee https://github.com/jacoblee93/oss-model-extraction-evals.\\n ', schema=<class 'langchain_benchmarks.extraction.tasks.email_task.Email'>, instructions=ChatPromptTemplate(input_variables=['email'], messages=[SystemMessagePromptTemplate(prompt=PromptTemplate(input_variables=[], template='You are an expert researcher.')), HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['email'], template='What can you tell me about the following email? Make sure to extract the question in the correct format. Here is the email:\\n ```\\n{email}\\n```'))]))])"
|
||||
"Registry(tasks=[ExtractionTask(name='Email Extraction', dataset_id='https://smith.langchain.com/public/a1742786-bde5-4f51-a1d8-e148e5251ddb/d', description='A dataset of 42 real emails deduped from a spam folder, with semantic HTML tags removed, as well as a script for initial extraction and formatting of other emails from an arbitrary .mbox file like the one exported by Gmail.\\n\\nSome additional cleanup of the data was done by hand after the initial pass.\\n\\nSee https://github.com/jacoblee93/oss-model-extraction-evals.\\n ', schema=<class 'langchain_benchmarks.extraction.tasks.email_task.Email'>, instructions=ChatPromptTemplate(input_variables=['input'], messages=[SystemMessagePromptTemplate(prompt=PromptTemplate(input_variables=[], template='You are an expert researcher.')), HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['input'], template='What can you tell me about the following email? Make sure to extract the question in the correct format. Here is the email:\\n ```\\n{input}\\n```'))])), ExtractionTask(name='Chat Extraction', dataset_id='https://smith.langchain.com/public/00f4444c-9460-4a82-b87a-f50096f1cfef/d', description='A dataset meant to test the ability of an LLM to extract and infer\\nstructured information from a dialogue. The dialogue is between a user and a support\\nengineer. Outputs should be structured as a JSON object and test both the ability\\nof the LLM to correctly structure the information and its ability to perform simple \\nclassification tasks.', schema=<class 'langchain_benchmarks.extraction.tasks.chat_extraction.schema.GenerateTicket'>, instructions=ChatPromptTemplate(input_variables=['dialogue'], messages=[SystemMessagePromptTemplate(prompt=PromptTemplate(input_variables=[], template='You are a helpdesk assistant responsible with extracting information and generating tickets. Dialogues are between a user and a support engineer.')), HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['dialogue'], template='Generate a ticket for the following question-response pair:\\n<Dialogue>\\n{dialogue}\\n</Dialogue>'))]))])"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"execution_count": 1,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -85,12 +90,14 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"execution_count": 2,
|
||||
"id": "9c7865bd-8251-4579-85a3-f9085d96f497",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"from langchain_benchmarks.extraction import get_eval_config\n",
|
||||
"\n",
|
||||
@@ -115,7 +122,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.6"
|
||||
"version": "3.11.4"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
@@ -75,6 +75,7 @@
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "7fb27b941602401d91542211134fc71a",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
@@ -311,7 +312,7 @@
|
||||
"\n",
|
||||
"## Customizing Chunking\n",
|
||||
"\n",
|
||||
"The simplest change you can make to the index is configure how you split the "
|
||||
"The simplest change you can make to the index is configure how you split the documents."
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -728,12 +729,12 @@
|
||||
"from langchain.agents import AgentExecutor\n",
|
||||
"from langchain.agents.format_scratchpad import format_to_openai_functions\n",
|
||||
"from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder\n",
|
||||
"from langchain.pydantic_v1 import BaseModel, Field\n",
|
||||
"from langchain.schema.messages import AIMessage, HumanMessage\n",
|
||||
"from langchain.tools import tool\n",
|
||||
"from langchain.tools.render import format_tool_to_openai_function\n",
|
||||
"from langchain_openai import ChatOpenAI\n",
|
||||
"\n",
|
||||
"# This is used to tell the model how to best use the retriever.\n",
|
||||
"\n",
|
||||
|
||||